1 HDFS基本介绍
一些基本概念:
在Hadoop中,HDFS是存储层,YARN是调度层,MapReduce是应用层
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)
分布式文件系统有大容量、高可靠和低成本的特点。其中Client端通过协议访问层与Server端通讯
分布式存储系统有对象存储、文件存储、块存储和数据库
HDFS功能特性:
- 分布式:受GFS启发,用Java实现的开源系统,没有实现完整的POSIX文件系统语义
- 容错:自动处理、规避多种错误场景,例如常见的网络错误、机器宕机等。
- 高可用:一主多备模式实现元数据高可用,数据多副本实现用户数据的高可用
- 高吞吐:Client直接从DataNode读取用户数据,服务端支持海量client并发读写
- 可扩展:支持联邦集群模式,DataNode数量可达10w级别
- 廉价:只需要通用硬件,不需要定制高端的昂贵硬件设备
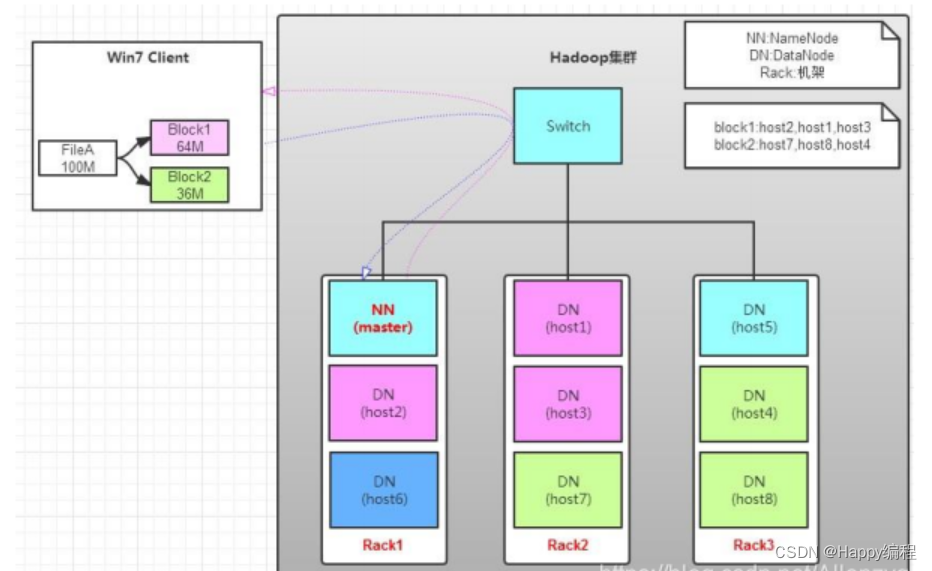
2 架构原理
HDFS组件:
Client/SDK <-> NameNode(Active/Standby) <-> DataNode
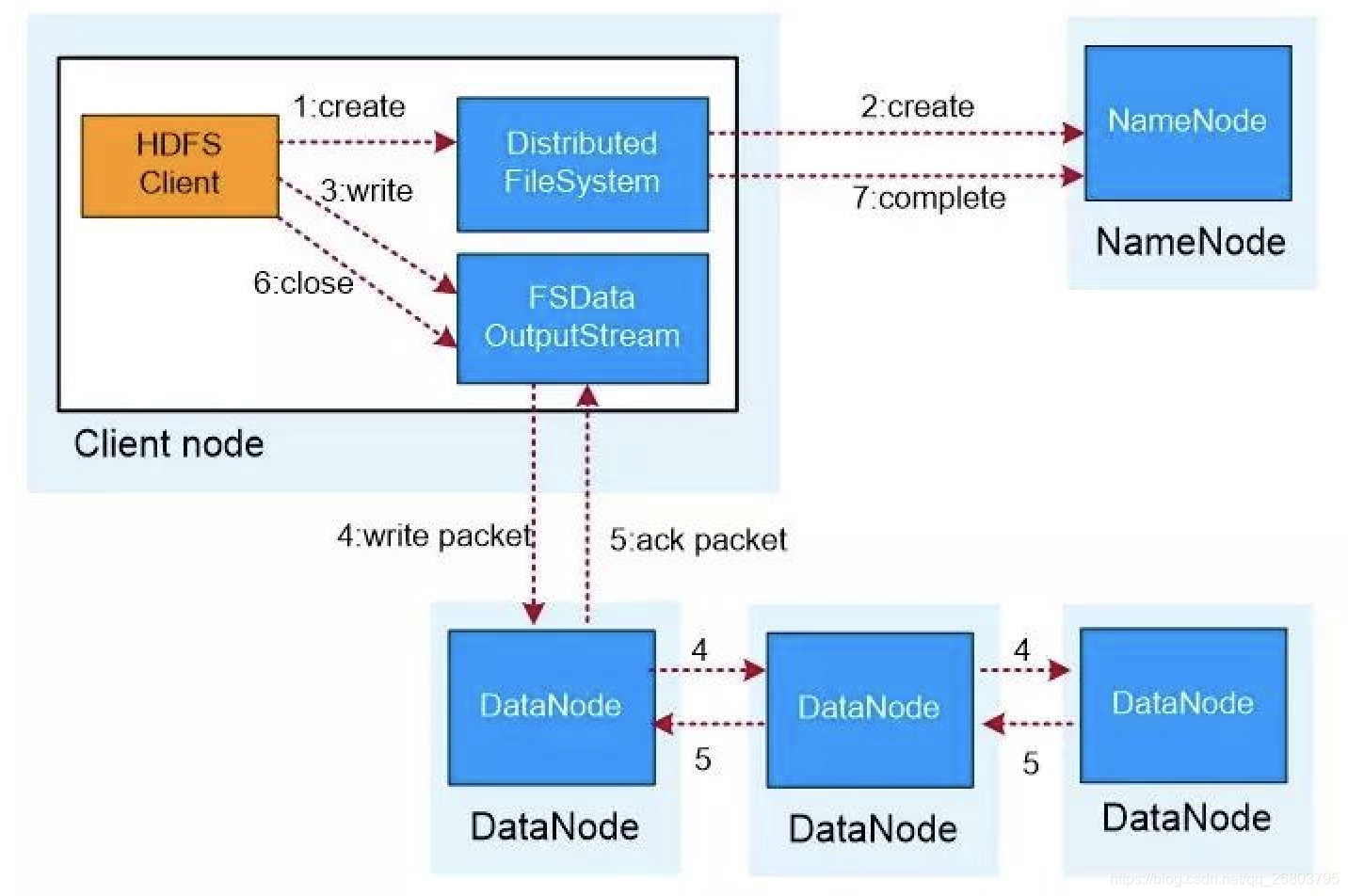
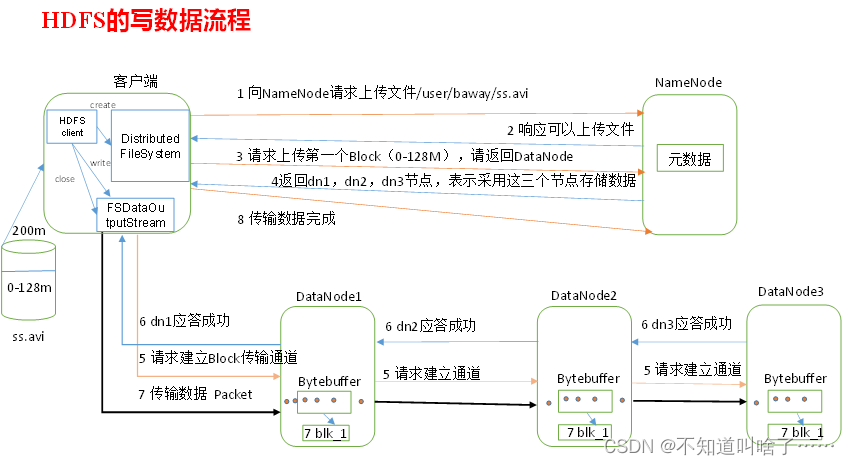
Client写流程: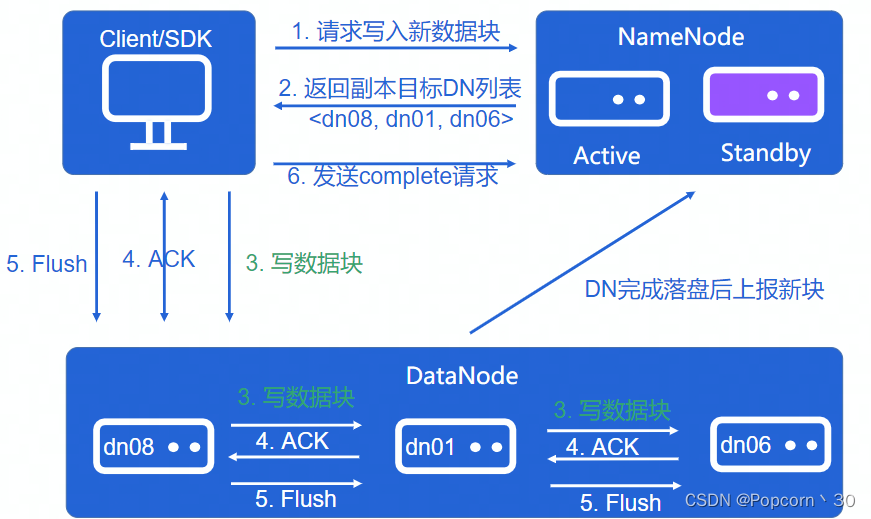
- Client向NameNode请求写入新的数据块
- NameNode接收到后,给Client返回要写入的DataNode位置
- Client向指定DataNode写入数据
- DataNode写完毕返回给Client端ACK标识
- Client接着对DataNode发送Flush刷新指令,并发送complete完成请求
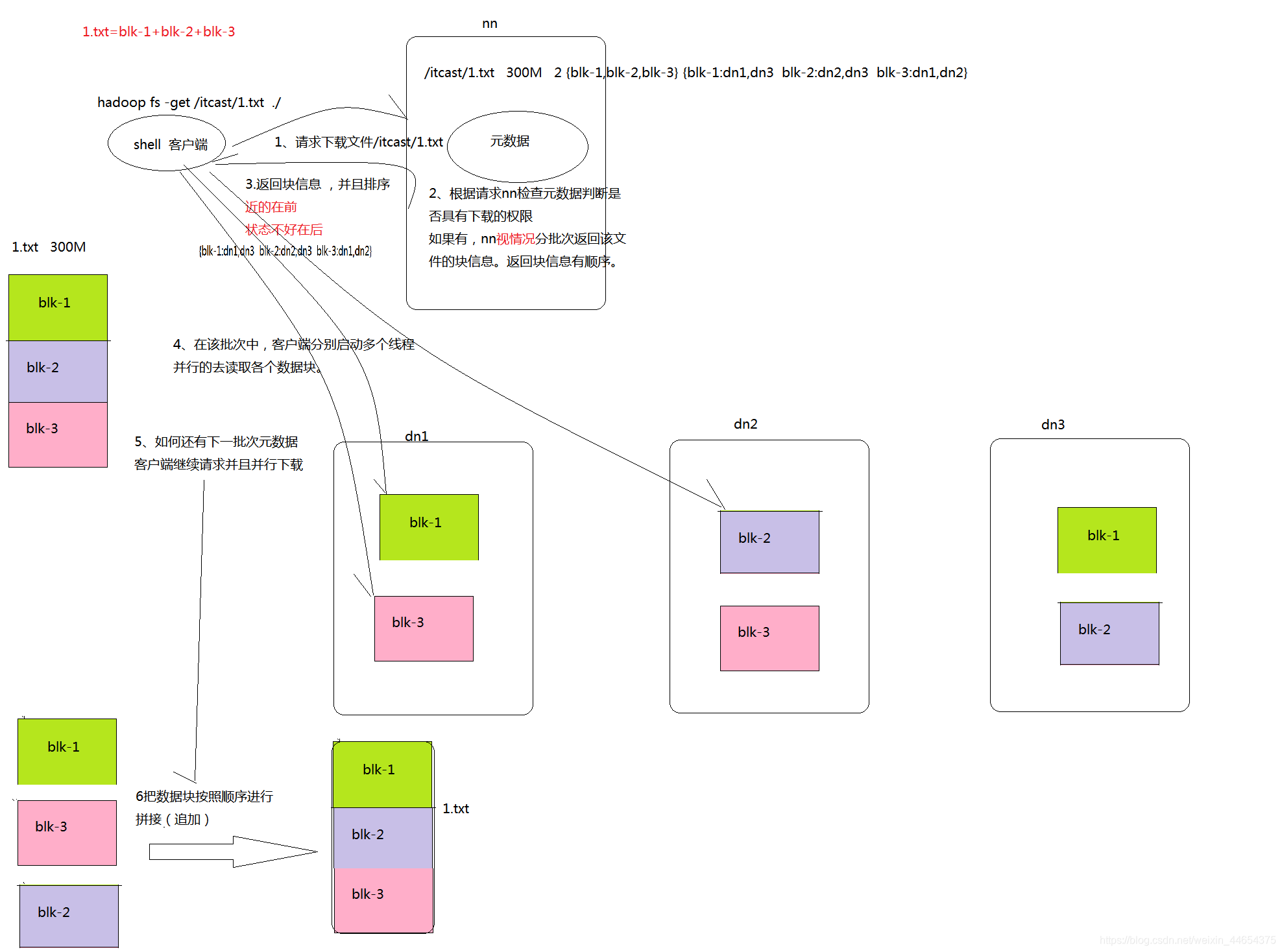
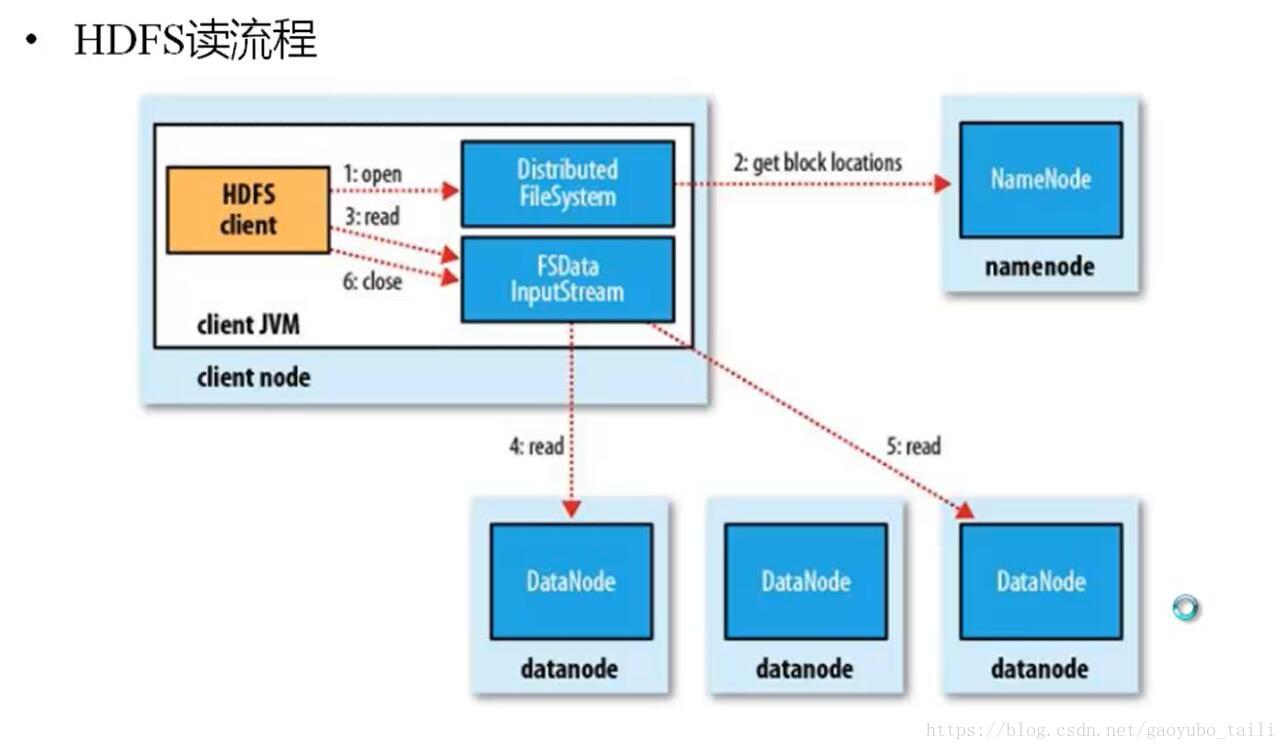
Client读流程:
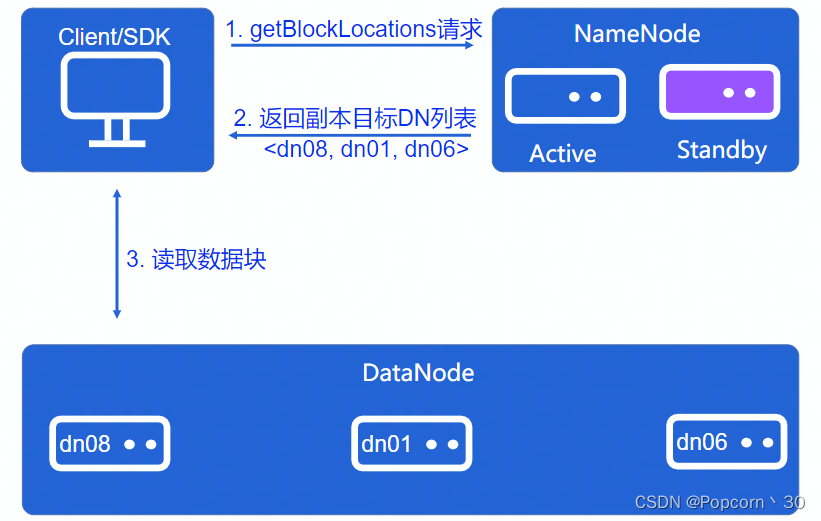
- Client向NameNode发送getBlockLocation请求
- NameNode返回给Client关于要读文件Datanode的位置信息
- Client根据信息向DataNode读数据块
元数据节点NameNode:
- 维护目录树:维护目录树的增删改查操作,保证所有修改都能持久化,以便机器掉电不会造成数据丢失或不一致。
- 维护文件和数据块的关系:文件被切分成多个块,文件以数据块为单位进行多副本存放
- 维护文件块存放节点信息:通过接收DataNode的心跳汇报信息,维护集群节点的拓扑结构和每个文件块所有副本所在的DataNode类表。
- 分配新文件存放节点:Client创建新的文件时候,需要有NameNode来确定分配目标DataNode
数据节点DataNode: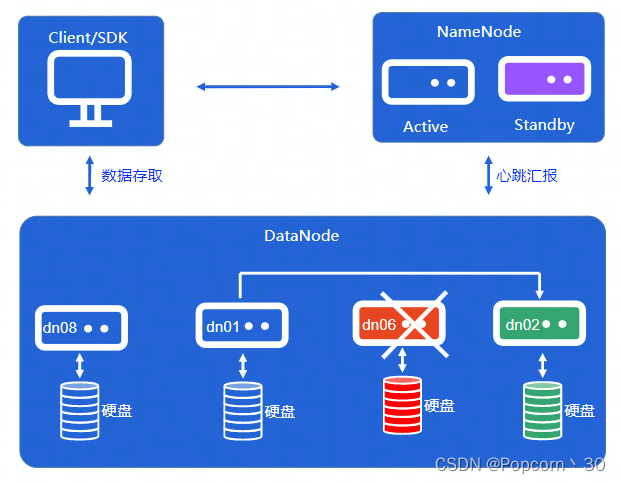
- 数据块存取:DataNode需要高效实现对数据块在硬盘上的存取
- 心跳汇报:把存放在本机的数据块列表发送给NameNode,以便NameNode能维护数据块的位置信息,同时让 NameNode确定该节点处于正常存活状态
- 副本复制:1.数据写入时Pipeline IO操作 2.机器故障时补全副本
3 关键设计
分布式存储系统基本概念:容错能力、一致性模型、可扩展性、节点体系、数据放置、单机存储引擎
NameNode目录树设计:
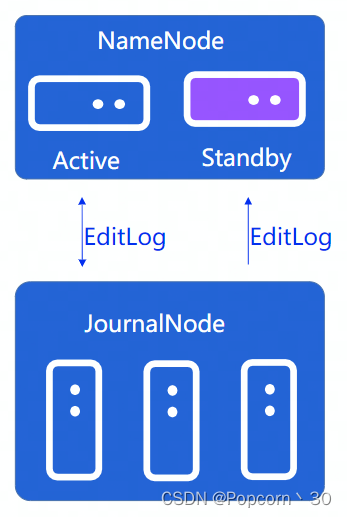
- fsimage:文件系统目录树。完整的存放在内存中,定时存放到硬盘上,修改是只会修改内存中的目录树
- editlog:目录树的修改日志。client更新目录树需要持久化editLog后才能表示更新成功,editLog可存放在本地文件系统,也可存放在专用系统上,NameNode HA方案一个关键点就是如何实现EditLog共享
NameNode副本放置:
- 数据块信息维护:目录树保存每个文件的块id,NameNode维护了每个数据块所在的节点信息,NameNode根据DataNode汇报的信息动态维护位置信息,NameNode不会持久化数据块位置信息
- 数据放置策略:新数据存放到哪写节点,数据均衡需要怎么合理搬迁数据,3个副本怎么合理放置
DataNode设计:
- 数据块的硬盘存放:文件在NameNode已分割成block,DataNode以block为单位对数据进行存取
- 启动扫盘:DataNode需要知道本机存放了哪些数据块,启动时把本机硬盘上的数据块列表加载在内存中
Client读写流程异常处理:租约:Client要修改一个文件时,需要通过NameNode上锁,这个锁就是租约(Lease)
- Lease Recovery:解决 文件写了一半Client自己挂掉了(副本不一致、 Lease无法释放)
- Pipeline Recovery:解决 文件写入过程中(创建连接时、数据传输时、complete阶段),DataNode侧出现异常挂掉了
- 节点Failover:读取文件的过程,DataNode侧出现异常挂掉了
HDFS旁路系统:
- Balancer:均衡DataNode的容量(DataNode节点数据存储不均匀或相差较大)
- Mover:确保副本放置符合策略要求(存放在DataNode数据的机架位置决定存储位置)
HDFS控制面建设:
- 可观测性设施:指标埋点、数据采集、访问日志、数据分析
- 运维体系建设:运维操作需要平台化、NameNode操作复杂、DataNode机器规模庞大、组件控制面API
心跳机制
1.NameNode全权管理数据块的复制,它周期性从集群中的每个DataNode接收心跳信号和块状态报告(blockReport),接收到心跳信号意味着该DataNode节点工作正常,块状态报告包含了该DataNode上所有数据块的列表
2.DataNode启动时向NameNode注册,通过后周期性地向NameNode上报blockReport,每3秒向NameNode发送一次心跳,NameNode返回对该DataNode的指令,如将数据块复制到另一台机器,或删除某个数据块等···而当某一个DataNode超过10min还没向NameNode发送心跳,此时NameNode就会判定该DataNode不可用,此时客户端的读写操作就不会再传达到该DataNode上
3.hadoop集群刚开始启动时会进入安全模式(99.99%),就用到了心跳机制,其实就是在集群刚启动的时候,每一个DataNode都会向NameNode发送blockReport,NameNode会统计它们上报的总block数,除以一开始知道的总个数total,当 block/total < 99.99% 时,会触发安全模式,安全模式下客户端就没法向HDFS写数据,只能进行读数据。
为什么说HDFS适合存储大文件而不适合存储小文件?
metaData的大小:文件,block,目录占用大概150byte字节的元数据,可想而知存储一个大文件就只有一份150byte的元数据,存储N多个小文件就会伴随存在N份150Byte字节的元数据文件,这就非常地不划算
4 应用场景
ETL(数据清洗):Extract,Transform,Load
机器学习:TensorFlow支持HDFS,Pytorch通过Alluxio访问DHFS或修改源码
可以使用HDFS通用存储有:对象存储、消息队列、冷数据层、海量日志、备份数据