文章目录
- 1 概述
- 1.1 HDFS的优缺点
- 1.2 HDFS组成架构
- 2 HDFS 读写流程
- 2.1 写数据流程
- 2.2 读数据流程
- 3 NameNode和SecondaryNameNode原理
- 4 DataNode原理
- 5 HDFS生产调优
- 5.1 HDFS核心参数配置
- 5.2 HDFS集群压测
- 5.3 HDFS白名单与黑名单
- 5.4 HDFS集群扩容及缩容
- 5.5 HDFS存储优化
- 5.6 HDFS故障排除
- 5.7 HDFS多目录与数据均衡
- 5.8 HDFS集群迁移
- 6 HDFS的shell操作与API操作

两万字长文希望能详尽的介绍了HDFS入门中涉及到的知识点,希望能帮自己和初学者理清思路,为之后大数据学习打好基础。
1 概述
HDFS的分布式是沿着文件的长度把它分为许多定长的数据块(64MB或者128MB),把不同数据块存在不同的节点,这样,就可以实现“数据在哪,计算就在哪里”。因此也就不允许随机写入,只允许在文件末尾添加内容。
HDFS的容错机制是把每个数据都复制三份并存在不同的节点上,这样如果其中之一发生错误了,就使用其他两份,并且再复制一份以维持三份,过一会儿如果发生故障的节点恢复了,就删除一个复份,一直维持3个复份。主节点namenode并不储存数据备份,而是储存着文件和目录的“元数据”,主节点的容错通过Secondary NameNode实现。
1.1 HDFS的优缺点
优点:
- 高容错性:数据保存多个副本、数据丢失可以自动恢复。
- 兼容廉价的硬件设备
- 强大的跨平台兼容性
- 适合处理大数据集
缺点:
- 不适合低延迟数据访问
- 无法高效存储小文件。(容易占用nameNode的内存,寻址时间可能超过读取时间)
- 不支持并发写入和文件随机修改。
1.2 HDFS组成架构

这个框架图见(跳转)
HDFS 具有主/从架构。HDFS 集群由单个 NameNode 组成,NameNode 是一个主服务器,用于管理文件系统命名空间并管理客户端对文件的访问。此外,还有许多 DataNode,通常集群中的每个节点一个,用于管理连接到它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读写请求。DataNode 还执行块的创建、删除操作。具体细分的话可以分为以下几个部分:
1)NameNode:
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块的映射信息
- 处理客户端的读写请求
2)DataNode:
- 储存实际的数据块
- 执行数据块的读/写操作
3)Client:客户端
- 文件切分上传(注意,客户端提交文件目录,程序遍历目录下的每一个文件,使用不同切片机制进行切片(在mapreduce部分详解),然后上传数据)
- 与NameNode进行交互,获取文件上的位置
- 与DataNode进行交互,读取或者写入数据
- Client提供一些命令与HDFS交互:格式化、增删改查。
4)Secondary NameNode:
- 辅助NameNode,分担其工作量(定期合并Fsimage和Edits)并推送给NameNode
- 辅助恢复NameNode
上述这些内容看起来空泛,但是后续看完整体流程之后会发现总结的很清晰。
2 HDFS 读写流程
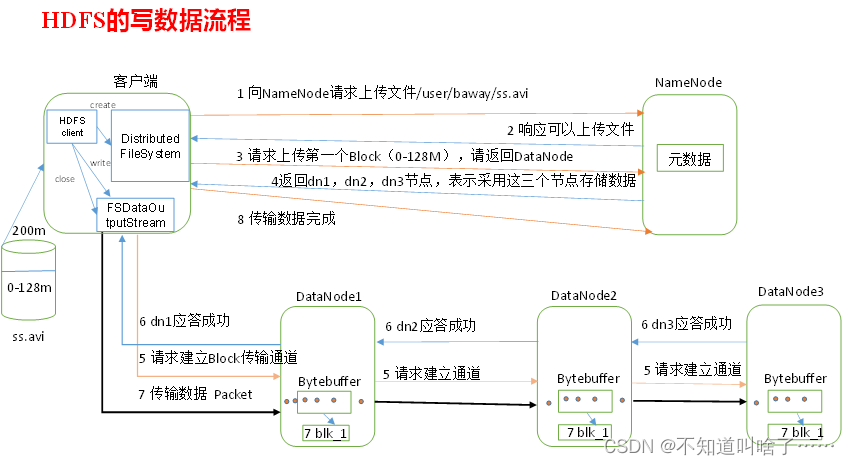
2.1 写数据流程

(1)客户端通过Distributed FileSystem向NameNode上传文件,NameNode检查文件是否存在,父目录是否存在,是否有文件上传的权限。
(2)NameNode返回是否可以上传
(3)客户端请求删除第一个Block
(4)NameNode返回三个DataNode节点
(5)客户端通过FSDataOutputStream请求dn1上传数据,dn1收到请求调用dn2,然后dn2调用dn3建立通信管道。(问题:dn1怎么知道该去找dn2呢?dn2又怎么知道去找dn3呢?在与HDFS Client建立好TCP毗连后从HDFS Client获得的DataNode信息)
(6)dn1、dn2、dn3逐级应答客户端
(7)客户端往dn1上传第一个block(已经切片了吗?是的)。从磁盘读取一个Packet单位数据(64k),以packet为单位传给dn2,dn2传给dn3。每传一个packet就会放入一个dataqueue队列等待应答。
(8)当一个Block 传输完成之后,客户端再次请求NameNode 上传第二个Block 的服务器。(重复执行3-7 步)
关于文件块传输的解释:
在DFSClient写HDFS的过程中,有三个需要搞清楚的单位:block、packet与chunk;
1、block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是64M;注:这个参数由客户端配置决定;
2、packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
3、chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;写过程中的三层buffer 写过程中会以chunk、packet及packet queue三个粒度做三层缓存;
首先,当数据流入DFSOutputStream时,DFSOutputStream内会有一个chunk大小的buf,当数据写满这个buf(或遇到强制flush),会计算checksum值,然后填塞进packet;
当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
进入dataqueue队列的packet会被另一线程按序取出发送到datanode;(注:生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限)
以上解读来源

存储节点的选择——节点距离计算与机架感知:
HDFS写数据,NameNode会选择距离与上传数据距离最近的DataNode接受数据。
节点距离:两个节点到达最近的共通祖先的距离总和。
祖先关系:root–>机房–>集群–>机架–>机器。看图就能懂,简单的加法,目的是为了从空闲的其他机器扎到一台与上传数据的机器最近的,可以减少IO时间。

机架感知与副本节点的选择:

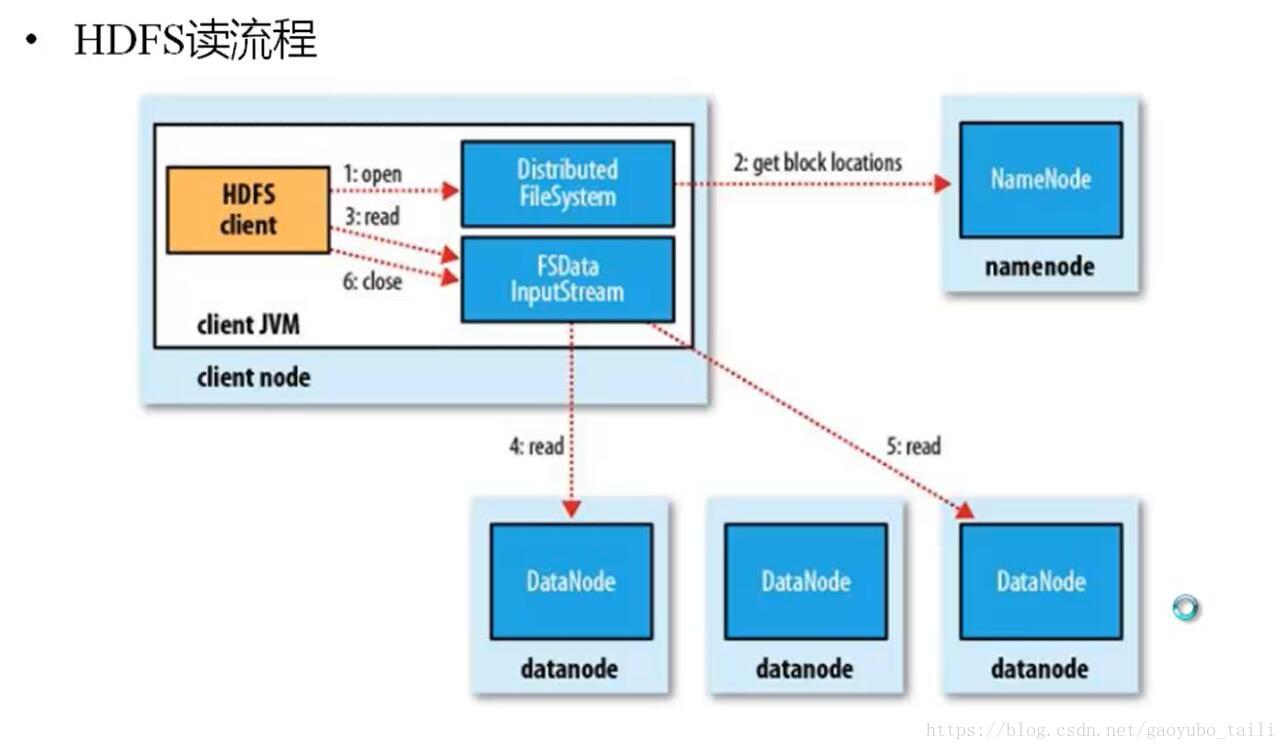
2.2 读数据流程

读数据就简单很多,主要是与NameNode进行交互,找到一台最近的读数据就好了。
3 NameNode和SecondaryNameNode原理

NameNode存储了元数据,并且将元数据保存在内存中,保存了block、datanode之间的映射关系。NameNode中有两个核心的数据结构,即FsImage和EditLog
- FsImage用于维护文件系统树以及文件树中的文件和文件夹数据
- 操作日志文件EditLog中记录了所有针对文件创建、删除、重命名等操作
FsImage文件包含文件系统中所有目录和文件inode的序列化形式。每个inode是一个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据。FsImage文件没有记录每个块存储在哪个数据节点。而是由名称节点把这些映射信息保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
NameNode启动的时候:
①首先,namenode会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,此时进入安全模式。②一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。③NameNode启动之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。
当由于操作数过多,EditLog就变得比较大,启动就很慢,而且启动时由于进入安全模式,用户不能操作。所以需要定期将FsImage和Edits进行合并,这个操作由NameNode完成的话效率太低,因此引入Secondary NameNode来进行这个操作。
SecondaryNameNode的工作情况:
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别。这个定期的时间被叫做checkPoint,通常设定为1小时执行一次或者操作数达到100万次时执行一次(1分钟检查一次执行了多少次)。具体设置在hdfs-default.xml这个文件中设置;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5)NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
4 DataNode原理

(1)一个数据块在DataNode上以文件形式存在磁盘上,主要有两个文件,一个是数据本身,一个是元数据(包括数据块长度、数据块校验和以及时间戳)。
(2)DataNode启动后向NameNode注册,通过后,周期性(6h)向NameNode上报告所有块。
(3)心跳是每3 秒一次,心跳返回结果带有NameNode 给该DataNode 的命令如复制块 数据到另一台机器,或删除某个数据块 如果超过10 分钟没有收到某个DataNode 的心跳, 则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。

5 HDFS生产调优
5.1 HDFS核心参数配置
(1)NameNode内存生产配置
这里主要介绍NameNode实际生产环境下该配置多大的运行内存。
- Hadoop2.x:系统默认配置2000m,如果服务器内存为4G,可以配置为3G。在hadoop-env.sh中配置
HADOOP_NAMENODE_OPTS= Xmx 3072 m - Hadoop3.x:系统自动按照机器的内存来配置,JVM的内存和NameNode的内存配置为一样。
自己配置NameNode内存的经验值:
namenode最小值为1G,每增加100万个block增加1G的内存。与之类似,DataNode内存最小值配置为4G,一个dataNode上副本低于400万调为4G,超过400万每增加100万,增加1G
具体操作:修改hadoop-env.sh,分发文件之后重启集群。
export HDFS_NAMENODE_OPTS=" Dhadoop.security.logger=INFO,RFAS Xmx 1024 m"
export HDFS_DATANODE_OPTS=" Dhadoop.security.logger=ERROR,RFAS Xmx 1024 m"
查看NameNode用了多少内存:
jps查看nameNode进程号
jmap -heap 进程号会显示MaxHeapSize,显示单位为字节
(2)NameNode心跳并发配置
dataNode每隔3s向NameNode发一个心跳说明自己还活着,如果10分钟加10次心跳没反应,那证明这个dataNode就当做宕机了。那么NameNode该使用多少的线程来接收dataNode的心跳呢?
公式: d f s . n a m e n o d e . h a n d l e r . c o u n t = 20 ∗ l o g e C l u s t e r S i z e dfs.namenode.handler.count =20*log_e^{Cluster Size} dfs.namenode.handler.count=20∗logeClusterSize
其中Cluster Size指的是集群规模,就是有多少个dataNode。然后配置hdfs-site.xml
<property><name>dfs.namenode.handler.count</name><value>21</value>
</property>
(3)开启回收站配置
与windows回收站含义相同。

5.2 HDFS集群压测
影响HDFS性能的主要有网络和磁盘。网络是配置副本和拉取数据网络传输的瓶颈,磁盘读取速度是直接影响HDFS的读和写。集群压力测试就是测试HDFS的读写速度,看看能不能满足任务要求,另外看看影响集群速度的瓶颈点是啥?是网络还是磁盘质量不行。
(1)测试HDFS写性能
网络带宽100Mbps单位是bit。100Mbps/8=12.5M/s.

就使用上面这个命令就好了:
nrFiles指定的是生成mapTask的数量,一般设置为(CPU核数 - 1),CPU核数可以通过hadoop103:8088进行查看。Total MBytes processed:单个 map处理的文件大小Throughput mb/sec:单个 mapTak的吞吐量
计算方式:
处理的总文件大小 /每一个 mapTask写数据的时间累加
集群整体吞吐量:生成 mapTask数量 *单个 mapTak的吞吐量Average IO rate mb/sec:平均 mapTak的吞吐量
计算方式:每个mapTask处理文件大小 /每一个 mapTask写数据的时间全部相加除以 task数量IO rate std deviation:方差 反映各个 mapTask处理的差值,越小越均衡
如果测试过程中出现异常
在yarn-site.xml设置虚拟内存检测为false,分发配置Yarn集群。
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true-->
<property><name>yarn.nodemanager.vmem check enabled</name><value>false</value>
</property>
查看实测的速度,如果实测速度远远小于网络,说明网络不是瓶颈,可以考虑固态硬盘或者增加磁盘个数。

(2)测试HDFS读性能
测试读取的速度
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read nrFiles 10 -fileSize 128MB
删除数据
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
5.3 HDFS白名单与黑名单
(1)白名单:表示在白名单的主机IP地址可以用来存储数据,企业中配置这玩意是为了防止黑客恶意攻击

1)在NameNode节点的/opt/module/hadoop-3.1.3/etc/hadoop目录下分别创建whitelist和blacklist文件。在白名单里面添加白名单内容。
2)在hdfs-site.xml配置文件中增加dfs.hosts配置参数

3)分发配置whitelist、hdfs-site.xml
4)第一次添加白名单需要重启集群,不是第一次只要刷新NameNode节点即可。
刷新集群的代码:
hdfs dfsadmin -refreshNodes
查看NameNode的web端:http://hadoop102:9870/dfshealth.html#tab-datanode
在非白名单的集群节点并不能上传和存储文件。
(2)黑名单:表示在黑名单的主机IP地址不可以用来存储数据,企业中配置黑名单是为了退役服务器。
黑名单配置与白名单相同。用于退役节点,按下不表,下文有。
5.4 HDFS集群扩容及缩容
(1)服役新数据节点
添加新的节点,可以分为两步:
1)环境准备
- 修改IP地址和主机名称
- 拷贝opt/module目录(hadoop和java安装目录)和/etc/profile.d/my_env.sh(全局变量)到新的机器上
- 删除hadoop的历史数据(data和log目录)
- 配置hadoop中NameNode节点到新节点的SSH无密登录(方便操作)
2)服役新节点
①直接启动DataNode
hdfs --daemon start datanode
yarn --daemon start nodemanager
②如果添加了白名单,需要在白名单上添加该节点
③在该节点上传文件
hadoop fs -put 文件路径
(2)节点间数据均衡
企业开发中,由于数据本地性原则,容易导致有些节点数据很多,有些节点数据很少,需要执行集群均衡命令。

(3)退役数据节点
在黑名单上添加IP地址或者主机名称映射,分发文件,刷新NameNode或者重启集群。

5.5 HDFS存储优化
(1)纠删码
纠删码用途:hadoop文件基于副本实现数据的备份,但是带来了冗余开销,为了节省空间,采用了纠删码策略。
纠删码策略:
| 策略 | 解释 |
|---|---|
| RS-3-3-1024K | 使用RS编码,每3个数据单元生成2个校验单元共5个单元,只要任意的3个单元存在,就可以得到原始数据。每个单元的大小是1024kb |
| RS-10-4-1024K | 使用RS编码,每10个数据单元生成4个校验单元共14个单元,只要任意的10个单元存在,就可以得到原始数据。每个单元的大小是1024kb |
| RS-6-3-1024K | 使用RS编码,每6个数据单元生成3个校验单元共9个单元,只要任意的9个单元存在,就可以得到原始数据。每个单元的大小是1024kb |
| RS-LEGACY-6-3-1024K | 使用RS-LEGACY编码,每6个数据单元生成3个校验单元共9个单元,只要任意的9个单元存在,就可以得到原始数据。每个单元的大小是1024kb |
| XOR-2-1-1024K | 使用XOR编码(速度比RS快),每2个数据单元生成1个校验单元共3个单元,只要任意的2个单元存在,就可以得到原始数据。每个单元的大小是1024kb |
纠删码是给一个具体的路径设置,所有此路径下的文件都会设置为此策略,默认的是开启RS-6-3-1024K的策略支持。
纠删码实操:
1)开启对RS-3-2-1024k策略的支持。
hdfs ec -enablePolicy -policy RS-3-2-1024k
2)在HDFS创建目录,并设置RS-3-2-1024K策略
hdfs dfs -mkdir /input
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
3)上传文件。
hdfs dfs -put web.log /input
注意上传的文件大于2M才能看到效果(低于2M,只有一个数据单元和两个校验单元)
(2)异构存储
异构存储作用:我们希望不同类型的数据存储在不同类型的电脑硬盘中,正在使用的存在内存中,经常使用的存在固态硬盘中,不经常使用的存在机械硬盘中,永久保存的存在破旧的硬盘中,使得计算机集群能够高效的被使用。

异构存储的shell操作
1)查看哪些策略可以用
hdfs storagepolicies -listPolicies
2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
4)取消存储策略:执行命令之后该目录或者文件,以其上级目录为准,如果是根目录,那就是HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
5)查看文件块的分布
bin/hdfs fsck xxx -files -blocks -locations
6)查看集群节点
hadoop dfsadmin -report
测试:

5.6 HDFS故障排除
(1)NameNode故障处理

(2)集群安全模式与磁盘修复
1)安全模式:文件系统只接受数据请求,不接受删除、修改等变更要求。
2)进入安全模式
- NameNode在加载镜像文件和编辑日志期间处于安全模式
- NameNode在接受DataNode注册时处于安全模式
3)退出安全模式:
- dfs.namenode.safemode.min.datanodes:最小可用datanode数量,默认0
- dfs.namenode.safemode.threshold-pct:副本数达到最小要求的block,占系统总block数的百分比,默认0.999f(只允许丢1个块)
- dfs.namenode.safenode.extension:稳定时间,默认值是300000毫秒。
安全模式下的shell相关操作:

安全模式应用:
1)磁盘出现问题,进入安全模式,如何处理?

只能删掉先退掉安全模式删除元数据,然后系统恢复正常,或者自己去找磁盘修复。
2)模拟等待安全模式

(3)慢磁盘监控
有些磁盘读写很慢,影响集群的运算速度,该怎么把这些集群找出来修复呢?
1)通过观察心跳,超过3s说明有问题
2)通过fio命令测试磁盘读写性能。


(4)小文件归档
HDFS存档文件或 HAR文件,是一个更高效的文件存档工具, 它将文件存入 HDFS块, 在减少 NameNode内存使用的同时,允许对文件进行透明的访问 具体说来, 允许对文件进行透明的访问 具体说来,HDFS存档文 件对内还是一个一个独立文件,对 NameNode而言却是一个整体,减少了 NameNode的内存。

5.7 HDFS多目录与数据均衡
(1)NameNode多目录配置
NameNode的目录可以配置为多个,每个目录存放的内容相同,增加了可靠性。
具体配置:


(2)DataNode多目录配置

(3)磁盘间数据均衡
增加硬盘之后的操作,与节点间的数据均衡不同。
5.8 HDFS集群迁移

6 HDFS的shell操作与API操作
(1)shell操作
上传:
-moveFromLocal从本地剪切粘贴到HDFS-copyFromLocal从本地文件系统拷贝文件到HDFS-put等同于copyFromLocal,生产环境更习惯用put-appendToFile追加一个文件到已经存在的文件末尾
下载:
copyToLocal从HDFS拷贝到本地get等同于copyToLocal,生产环境下更习惯用get
HDFS中文件操作,以下命令和linux系统中的命令无差别,只要用hadoop fs 命令 参数的格式就可以完成。
lscat-chgrp、chmod、chownmkdircpmvtailrmdu统计文件夹大小信息
(2)API操作
环境安装:
1) 下载 hadoop-3.1.0 (windows版)到非中文路径 (比如E:\Sofware)。想让我们的windows能够连接上远程的Hadoop集群,windows里面也得有相关的环境变量。
2 ) 配置 HADOOP_HOME 环境变量。
HADOOP_HOME = 下载的路径
3)配置Path环境变量
%HADOOP_HOME%bin
Maven导包
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency>
</dependencies>
配置输出log的文件
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
新建代码:
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;/*** 客户端代码常用套路* 1、获取一个客户端对象* 2、执行相关的操作命令* 3、关闭资源*/
public class HdfsClient {private FileSystem fs;@Beforepublic void init() throws IOException, URISyntaxException, InterruptedException {//连接集群的nn地址URI uri = new URI("hdfs://hadoop102:8020");//创建一个配置文件Configuration configuration = new Configuration();//用户String user = "leokadia";// 1 获取客户端对象fs = FileSystem.get(uri, configuration, user);}@Afterpublic void close() throws IOException {// 3 关闭资源fs.close();}@Testpublic void testmkdir() throws URISyntaxException,IOException,InterruptedException {// 2 创建一个文件夹fs.mkdirs(new Path("/Marvel/Avengers"));}
}看到上面的代码其实逻辑很简单:建立连接,操作,关闭资源。
其他的操作还有
// 上传@Testpublic void testPut() throws IOException {//参数解读:参数一:表示删除原数据;参数二:是否允许覆盖;参数三:原数据路径;参数四:目的地路径fs.copyFromLocalFile(false,false,new Path("D:\\Iron_Man.txt"),new Path("hdfs://hadoop102/Marvel/Avengers"));}
@Test
// 文件下载@Testpublic void testGet() throws IOException {//参数解读:参数一: boolean delSrc 指是否将原文件删除;参数二:Path src 指要下载的原文件路径// 参数三:Path dst 指将文件下载到的目标地址路径;参数四:boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("hdfs://hadoop102/Marvel/Avengers/Iron_Man.txt"), new Path("D:\\Robert.txt"), false);} // 删除@Testpublic void testRm() throws IOException {// 参数解读:参数1:要删除的路径; 参数2 : 是否递归删除// 删除文件(不再演示了)fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);// 删除空目录fs.delete(new Path("/delete_test_empty"), false);// 删除非空目录fs.delete(new Path("/Marvel"), true);}
// 文件的更名和移动@Testpublic void testmv() throws IOException {// 参数解读:参数1 :原文件路径; 参数2 :目标文件路径// 对文件名称的修改fs.rename(new Path("/move/from.txt"), new Path("/move/new.txt"));// 文件的移动和更名fs.rename(new Path("/move/new.txt"),new Path("/to.txt"));// 目录更名fs.rename(new Path("/move"), new Path("/shift"));}
// 获取文件详细信息@Testpublic void fileDetail() throws IOException {// 获取所有文件信息RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);// 遍历文件while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();System.out.println("==========" + fileStatus.getPath() + "=========");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getGroup());System.out.println(fileStatus.getLen());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockSize());System.out.println(fileStatus.getPath().getName());// 获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}
// 判断是文件夹还是文件@Testpublic void testFile() throws IOException {FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus status : listStatus) {if (status.isFile()) {System.out.println("文件:" + status.getPath().getName());} else {System.out.println("目录:" + status.getPath().getName());}}}