欢迎关注WX公众号:【程序员管小亮】
文章目录
- 欢迎关注WX公众号:【程序员管小亮】
- 一、介绍
- 二、代码实现
- 1_数据加载
- 2_归一化
- 3_定义网络结构
- 4_设置优化器和退火函数
- 5_数据增强
- 6_拟合数据
- 7_训练轮数和批大小
- 8_准确率和损失
- 三、总结
一、介绍
最近发现了一个比较不错的竞赛平台,很适合练手,也就是很多人熟知的 FlyAi。
为什么觉得它好呢?
直观上两点很吸引我:1. 有奖金!!!2. 难度适中0-0
话不多说,直接正题,MNIST手写数字识别练习赛。
-
【MNIST手写数字识别练习赛】比赛页面:https://www.flyai.com/d/MNIST
-
GitHub 代码地址:https://github.com/TeFuirnever/Kaggle-Digit-Recognizer
-
Kaggle竞赛实战系列(一):手写数字识别器(Digit Recognizer)得分99.53%、99.91%和100%
MNIST 是计算机视觉领域的 hello world 数据集。自从1999年发布以来,这个经典的手写数字识别数据集就成为分类算法的基础,即使新的机器学习技术在不停地出现,但 MNIST 仍然是研究人员和学习者的可靠资源。这里选择用 keras API(Tensorflow backend)来构建它,这会使得整个过程非常直观且便于理解,这也是 Keras 唯一的优势,因为其他方面它真的不如 TensorFlow 和 pytorch。
简单跑了一次,没怎么认真调参,跑了四十五轮(感觉三十多轮就收敛的很好了),结果还马马虎虎,99.55%。

注:如果多跑几次,很大可能上会出一个更好的结果,因为初始化和其他的原因,每次的结果稍稍带有一些偶然性,如果有兴致,可以多跑几次选一个最佳结果。
FlyAi的一个优势在于它并不需要多少代码的实际编写,因为会有代码示例,只需要填写或者改动网络结构和超参数即可。
二、代码实现
正常的一个流程应该是如下:
- 数据加载
- 归一化
- 定义网络结构
- 设置优化器和退火函数
- 数据增强
- 拟合数据
不过 FlyAi 较为简单一些,很多都帮你弄好了。
1_数据加载
在 FlyAI 的项目中封装了 Dataset 类,可以实现对数据的一些基本操作,比如加载批量训练数据,示例中已经写好。
from flyai.dataset import Dataset
...
...
dataset = Dataset(epochs=args.EPOCHS, batch=args.BATCH)
...
...
processor.py 完成了对单张图片的读取。
# -*- coding: utf-8 -*
import numpy as np
import cv2
from flyai.processor.base import Base
from path import DATA_PATH
import osclass Processor(Base):def input_x(self, image_path):# 获取图片路径path = os.path.join(DATA_PATH, image_path)# 读取图片img = cv2.imread(path)# 将图片BGR格式转换成RGB格式img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 对图片进行归一化操作img = img / 255.0# 将图片转换成 [28, 28, 1]img = img[:, :, 0]img = img.reshape(28, 28, 1)return imgdef input_y(self, label):# 对标签进行onehot化one_hot_label = np.zeros([10])# 生成全0矩阵one_hot_label[label] = 1# 相应标签位置置return one_hot_labeldef output_y(self, data):return np.argmax(data)
该数据集中的数字图片是由 250 个不同职业的人手写绘制的,其中训练集数据一共 60000 张图片,测试集数据一共 10000 张图片。每张手写数字图片大小都是 28*28,每张图片代表的是从 0 到 9 中的每个数字。

官网在此:http://yann.lecun.com/exdb/mnist/
2_归一化
归一化的目的就是使得预处理的数据被限定在一定的范围内(比如 [0,1] 或者 [-1,1]),从而消除奇异样本数据导致的不良影响。
...
...
# 将图片BGR格式转换成RGB格式
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 对图片进行归一化操作
img = img / 255.0
# 将图片转换成 [28, 28, 1]
img = img[:, :, 0]
img = img.reshape(28, 28, 1)
...
...
3_定义网络结构
重头戏到了!!!
这里使用了 Keras Sequential API,从输入开始,每次只需添加一个层。
-
卷积(
conv2d)层就像一组可学习的过滤器:前三个conv2d层设置32个过滤器,后三个层设置64个过滤器。 -
池化(
maxpool2d)层是一个下采样滤波器:它着眼于2个相邻像素,并选择最大值。这些都是用来减少计算成本,并在一定程度上也减少了过拟合。 -
归一化层(
BN)是一种正则化方法,可以加快收敛速度,控制并减少过拟合,同时还允许网络使用较大的学习率。 -
Dropout是一种正则化方法,其中某些层的部分节点被随机忽略(将其wieghts设置为零)。这将随机丢弃网络的一个属性,并强制网络以分布式方式学习特性。该方法还提高了泛化能力,减少了过拟合。
解决过拟合的方法可以看这个博客——深度学习100问之神经网络中解决过拟合的几种方法
-
relu是线性整流函数,又称修正线性单元,也就是俗称的激活函数,公式是max(0,x)。relu的主要作用就是向网络中添加非线性,故也称为非线性激活函数。 -
Flatten层用于将最终特征映射转换为一个一维向量,展开之后可以在某些卷积/maxpool层之后使用全连接层,它结合了以前卷积层提取的所有局部特征。 -
全连接(稠密)层是用于实现分类,即人工神经网络分类器,在最后一层(
Dense(10, activation='softmax')),网络输出每个类别的概率分布。
# 构建网络
sqeue = Sequential()# 设置CNN模型
sqeue.add(Conv2D(32, kernel_size = 3, activation='relu', input_shape = (28, 28, 1)))
sqeue.add(BatchNormalization())
sqeue.add(Conv2D(32, kernel_size = 3, activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Conv2D(32, kernel_size = 5, strides=2, padding='same', activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Dropout(0.4))sqeue.add(Conv2D(64, kernel_size = 3, activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Conv2D(64, kernel_size = 3, activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Conv2D(64, kernel_size = 5, strides=2, padding='same', activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Dropout(0.4))sqeue.add(Conv2D(128, kernel_size = 4, activation='relu'))
sqeue.add(BatchNormalization())
sqeue.add(Flatten())
sqeue.add(Dropout(0.4))
sqeue.add(Dense(10, activation='softmax'))
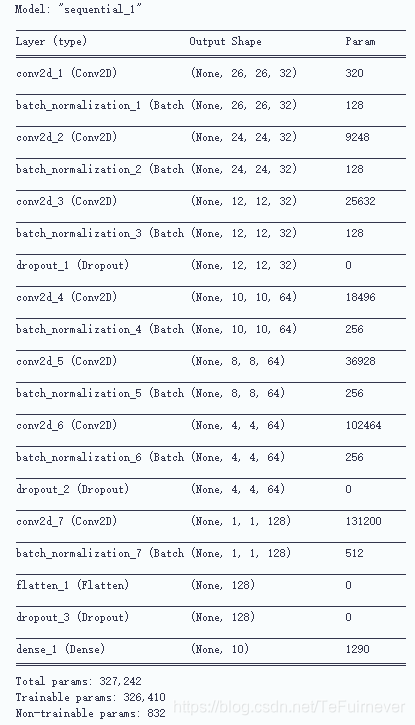
如果算不清楚各个行的参数,可以可视化一下。
# 输出模型各层的参数状况
sqeue.summary()
如果对于 CNN 的一些知识不知道的话,可以看一下这个高赞博客——大话卷积神经网络CNN(干货满满)。
4_设置优化器和退火函数
一旦网络模型构建成功,就需要有一个损失函数和一个优化算法。
-
损失函数用来衡量模型在带有已知标签的图像数据集上的性能有多差,它是目标标签和预测标签之间的错误率。使用最多的是交叉熵损失函数,即
categorical_crossentropy loss。 -
优化器是最重要的功能,它将迭代地改进参数(
filters kernel values, weights and bias of neurons ...),以最小化损失函数。- 可以选择
rmsprop,它是一个非常有效的优化器,以一种非常简单的方式调整adagrad方法,试图降低其攻击性强、单调下降的学习率。 - 还可以使用
adam; - 也可以使用
sgd优化器,但它比rmsprop慢。
- 可以选择
...
sqeue.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
...
为了使优化器更快地收敛,并且最接近全局最小损失函数, 这里使用了一种学习率(lr)的退火方法。lr 是学习率,它越高,步长越大,收敛速度越快。然而,由于 lr 较高,采样非常差,优化器可能会陷入局部极小值。所以可以在训练过程中降低学习率,以有效地达到损失函数的全局最小。为了保持计算速度快、lr 值高的优点,根据需要(在精度没有提高的情况下)每 x 步动态地减少 lr 值。
...
# 设置一个学习率衰减
annealer = LearningRateScheduler(lambda x: 1e-3 * 0.95 ** x)
...
...
history = sqeue.fit(x, y, batch_size=args.BATCH, verbose=0, validation_data=(x_val, y_val),callbacks=[annealer])
...
记得要在拟合中填写学习率衰减!!!
5_数据增强
又称数据扩充/数据增广。
为了避免过拟合问题,需要对手写数字数据集进行人工扩充,它可以让你现有的数据集变得更大。这个想法最初是来源于用小的转换来改变训练数据,以重现某人在写一个数字时发生的变化,尤其适用于数据量较小的情况。以改变数组表示的方式改变训练数据,同时保持标签不变的方法称为数据增强技术。一些常用增强是灰度、水平翻转、垂直翻转、随机裁剪、颜色抖动、平移、旋转还有缩放等等。
通过数据增强可以轻松地将训练集的数量增加一倍或多倍,从而可以创建一个非常健壮的模型,因此这个改进很重要!!!
#数据增强
data_augment = ImageDataGenerator(featurewise_center=False, # 在数据集上将输入平均值设置为0samplewise_center=False, # 将每个样本的平均值设置为0featurewise_std_normalization=False, # 将输入除以数据集的stdsamplewise_std_normalization=False, # 将每个输入除以它的stdzca_whitening=False, # 使用ZCA白化rotation_range=10, # 在范围内随机旋转图像(0到180度)zoom_range = 0.1, # 随机缩放图像width_shift_range=0.1, # 水平随机移动图像(总宽度的一部分)height_shift_range=0.1, # 垂直随机移动图像(总高度的一部分)horizontal_flip=False, # 随机翻转图像vertical_flip=False) # 随机翻转图像
为了增加数据选择了:
- 训练图像随机旋转
10度; - 随机缩放
10%一些训练图像; - 将图像水平移动
10%的宽度; - 将图像垂直移动
10%的高度; - 没有应用垂直翻转或水平翻转,因为它可能导致错误分类对称数字,如
6和9。
6_拟合数据
示例中写好了,直接用就可以了,不要忘记了前面说的学习率衰减即可。
history = sqeue.fit(x, y, batch_size=args.BATCH, verbose=0, validation_data=(x_val, y_val),callbacks=[annealer])

7_训练轮数和批大小
在调交运行时会有提示,真的方便!!!
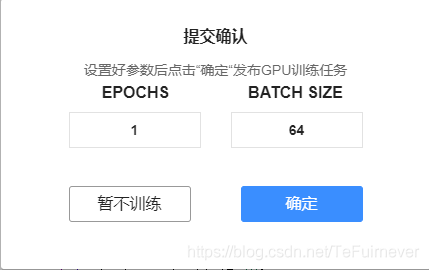
EPOCHS 45 BATCH SIZE 64
-
EPOCHS 就是训练轮数,需要尝试才能找到最佳,但是尝试太多又会浪费时间,我一般会首先尝试
30,然后尝试45和15,像第一名的1000轮,不建议。 -
BATCH SIZE 就是批大小,即每一次读入到网络中的数据数量,太小的话会导致数据随机性过大,极其影像网络的收敛;太大的话会导致显卡 爆炸,因为数据会预先读入到显存中(极其不准确的说法,但是大概是这个意思),所以你的显存大小决定了你的最大批大小,一般适度即可,或者可以尝试调节看看结果。
8_准确率和损失
示例中自带的代码,直接提交即可,😃
...
...
for _ in range(dataset.get_step()):step += 1first_time = int(time.time())x_train, y_train = dataset.next_train_batch()x_val, y_val = dataset.next_validation_batch()# 数据增强batch_gen = data_augment.flow(x_train, y=y_train, batch_size=args.BATCH)x, y = next(batch_gen)history = sqeue.fit(x, y, batch_size=args.BATCH, verbose=0, validation_data=(x_val, y_val),callbacks=[annealer])print(str(step) + "/" + str(dataset.get_step()))train_log(train_loss=history.history['loss'][0], train_acc=history.history['accuracy'][0],val_loss=history.history['val_loss'][0], val_acc=history.history['val_accuracy'][0])val_acc = history.history['val_accuracy'][0]# 用 val_acc_list 保存最新的 10 个 val_accif len(val_acc_list) >= 10:val_acc_list.pop(0)val_acc_list.append(val_acc)else:val_acc_list.append(val_acc)# 每隔10步进行一次比较,用来保存最优结果if step % 10 == 0 and np.mean(val_acc_list) >= best_score:best_score = np.mean(val_acc_list)model.save_model(sqeue, MODEL_PATH, overwrite=True)print("******************** step %d, best accuracy %g" % (step, best_score))
这个部分相当于可视化了整个训练过程,FlyAi 提供了这个过程的实现,只需要观察即可。
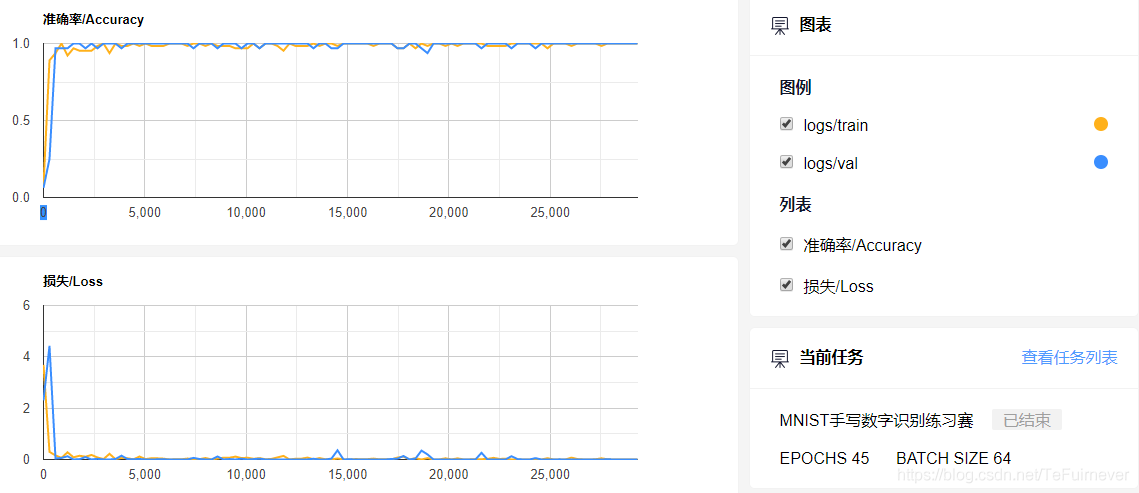
如图,蓝色是验证集,可以看到蓝色曲线收敛的非常好,浮动很小,这就是一个健康的曲线。
三、总结
整体来说,
Keras的上手难度很低,很多层不需要像TensorFlow那样一点点去写,只要调整网络结构和超参数即可实现学习过程;- FlyAi 的初体验也是不错的,减少了上手的学习成本,但是还是需要你去读懂代码,这样才不算是浪费了一次学习的机会;
- MNIST 作为计算机视觉的 Hello,World 固然有很多借鉴意义,但是还是过于简单的 CNN 模型,建议不要投入过多精力,要放眼宇宙星辰,去做更多的比赛!!!
最后的警告,不要直接把开头的 GitHub 代码 fork 一下就算了,还是要自己手敲一下,改一改参数去体会每个参数的意义!!!