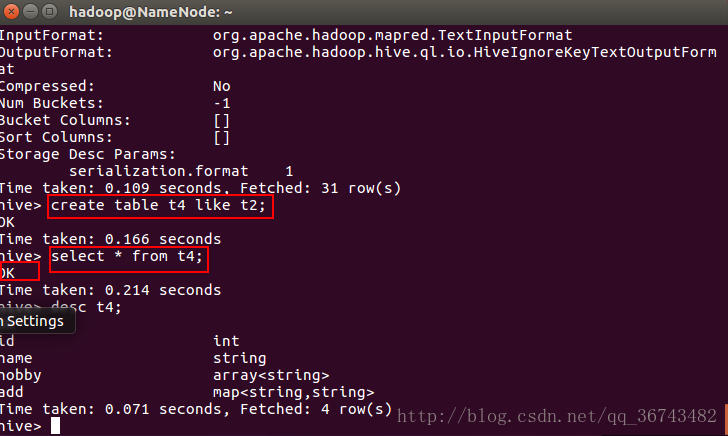
我们先认识一下SVM:
(1)支持向量机(Support Vector Machine, SVM)是一种对数据进行二分类的广义线性分类器,其分类边界是对学习样本求解的最大间隔超平面。
(2)SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器 。
(3)SVM可以通过引入核函数进行非线性分类。
关于SVM的阐述,我们发现SVM有三宝,分别是最大间隔、对偶问题以及核函数。
1、最大间隔超平面
在说明最大间隔超平面问题之前,先说明一下什么是线性可分。
线性可分:假设有猪狗两类样本,若在特征空间中存在一个超平面将猪狗完全准确分开,那么就称这个猪狗样本集线性可分。在二维空间时,超平面就是一条直线。
对于一个线性可分样本集,可能存在多个超平面(line1,line2)都可以将其线性可分,那么怎么选择超平面呢?假设现在有一只冒充猪的小狗来搞破坏,是否存在一个超平面,无论来了多少只小狗或者小猪,依然可以将其阴谋识破?SVM解决的就是这个,找出一个最佳超平面正确划分样本。
那最佳超平面长什么样的呢?我们认为最佳超平面必须具有更好的泛化能力,对噪声更为不敏感,即更好的鲁棒性。从几何角度来说,两样本到超平面的间隔越大,抗干扰能力越强,所以最佳超平面就是以最大间隔把样本分开的超平面,也称之为最大间隔超平面。
间隔是两侧样本到超平面的距离之和,即margin = d1+d2,多个样本就有多个间隔值,那是不是每个间隔对超平面的贡献都一样的呢?答案是否定的,离超平面越近的样本越容易划分错误,因此离超平面越近的样本对超平面的影响越大,所以为了找到最大间隔超平面,首先要找到两侧离超平面最近的样本点,求出其到超平面的距离之和,即margin = min(d1+d2)。然后不同超平面,margin不同,为了找到最佳超平面,我们需要最大化margin,可以理解为泛化能力最大的那个超平面,即max margin。
转为数学表达,即max margin = max min(d1+d2)
点到直线的距离d:点W(Xw,Yw)到直线AX+BY+C=0的距离等于
现在假设在样本集中,存在一个超平面WTX+b=0,使得样本集线性可分,那么样本到超平面的距离d为:
答案是否定的,因为无论k值取多少,都是 WTX+b=0移k个单位,因此为了方便后面的计算,使|WTX+b|=1,那么:
就这样,将寻找最大间隔超平面的问题转化为数学优化问题,但这里有一个前提,就是这个超平面能把样本正确分类,这个大前提的数学表达式为:
另外求优化问题时,我们更喜欢转为凸优化,因为:
且||W||是个带根号的值,为了方便运算,将||W||等同于||W||的平方, 且乘上系数1/2方便求导,因此最终优化问题表达式为:
2、对偶问题:
那么怎么求解呢?对于高维数据、样本量非常大的时候,无法通过简单运算求解,这时候就会通过对偶、核技巧等方法求解。在求解之前先简单介绍一下带约束与不带约束的凸优化问题都是怎么求解的?
(1) 不带约束条件:
不带约束条件的求解是很容易得到的,直接求导求最小值就可以了。
(2) 带等式约束条件:
带等式约束条件的一般会先通过拉格朗日乘子法转化为无约束后,再通过求导求解。如:给定约束条件h(x)=0,求minf(x) 的问题,可以先定义如下拉格朗日函数(λ为拉格朗日乘子):L(x,λ) = f(x)+λh(x),即将等式约束转为无约束了,求解时分别对x,λ求导即可。
(3) 带不等式的约束条件:
带不等式的约束条件的优化问题,一般会先转化为带等式约束,再通过拉格朗日乘子法求解。如:给定约束条件 g(x)<=0,求min f(x) 的问题,首先定义一个k值,使得h(x,k) =g(x)+k^2。接着定义如下拉格朗日函数(λ为拉格朗日乘子): L(x,λ,k) = f(x)+λh(x)=f(x)+λg(x)+λk^2 即将不等式约束转为无约束了,最后分别对各个参数求导即可。
这里以我们的优化问题为例,讲讲带不等式的约束条件时怎么求解的。
最终得到的条件也称为不等式约束优化问题的KKT条件,也是强对偶的必要条件。另外,从上图星号的公式也可以知道,当λi=0时,约束条件是不起约束作用,只有当λi>0时,约束条件才起约束作用,此时点(xi,yi)称为支持向量。这也是为什么这个算法叫支持向量机的原因,真正对最佳超平面起作用的点只有支持向量,因此大大降低了的运算消耗。
那么强对偶能解决什么问题呢?强对偶可以根据计算的难度、复杂度在minmax与 maxmin之间转换。
Ok,对偶问题讲到这里,那么对偶问题是怎么应用到我们的优化问题当中的呢?现在我们的优化问题可以写成:
公式推导到这里 :
:
可以看出来其实这是个二次规划问题,常用SMO算法求解,最终得出最佳参数λ。
在已知最优W (KKT条件),最优λ的前提下,因为对最佳超平面起作用的只有支持向量,那么设点(xk,yk)是一个支持向量,则,求得最优b。最终最佳超平面的表达式为:
可以看到,最佳参数W,b都是关于数据的线性组合,到这里SVM的任务就完成了。
3、核函数:
百度百科:支持向量机通过某非线性变换 φ( x) ,将输入空间映射到高维特征空间。特征空间的维数可能非常高。如果支持向量机的求解只用到内积运算,而在低维输入空间又存在某个函数 K(x, x′) ,它恰好等于在高维空间中这个内积,即K( x, x′) =<φ( x) ⋅φ( x′) > 。那么支持向量机就不用计算复杂的非线性变换,而由这个函数 K(x, x′) 直接得到非线性变换的内积,大大简化了计算。这样的函数 K(x, x′) 称为核函数。
这里提取一下知识点,非线性变换、内积运算、核函数
(1) 非线性变化
这里有一个定理,高维空间比低维空间更容易线性可分。
前面提到当数据样本完全线性可分时,可以得到一个最佳超平面,那么当数据样本不是线性可分时,还可以得到一个最佳超平面吗?根据定理,在当前维度不能线性可分时,把样本通过非线性变化映射到更高维度,是有可能线性可分的。举个例子:
(2) 内积运算
经过上述的推导,我们知道SVM最终的优化问题是:
(xi ⋅ xj)是内积运算,当有n个样本点时,会构成n*n的矩阵。当x经过非线性变换后为 φ( x),优化问题转为:
当 φ( x)维度高到一定程度甚至无限维时,计算量会随着维度的增大而增大,而且计算完φ( x)后,还需要计算φ( x)的内积,这时可能会因为计算量过大而出现无法计算的情况,这时候就需要核函数拯救世界了。
(3) 核函数
核函数是指在低维输入空间中存在一个函数 K(x, x′) ,它恰好等于在高维空间中这个内积,即K( x, x′) =<φ( x) ⋅φ( x′) >,此时将会大大减小计算消耗,这就是为什么很多人将核函数也称为核技巧的原因,因为其相当于是一个计算技巧。
常见的核函数有线性核函数、多项式核函数、高斯核函数等。
4、软间隔:
完全线性可分在现实中是很少的,大部分都并不是完全线性可分,有两种情况,一是需要通过非线性变化后才可能线性可分,二是在低维空间可以线性可分,但有一定量的错误。对于第二种情况,我们会使用软间隔划分,说白了就是没那么苛刻的硬间隔。
这里引入一个松弛变量,优化问题:
看到上述式子是不是有点像加入了正则化的感觉呢?没错,这里是对错误划分样本的惩罚。
当松弛变量=0时,点落在最大间隔边上,点划分正确;
当 1>松弛变量>0 时,点落在最大间隔内,点划分正确;
当 松弛变量=1 时,点落在超平面上,点划分正确;
当 松弛变量>1时,点划分错误;
接下来的求解过程跟上述类似,先构建拉格朗日乘子函数:
可能有朋会问为啥最后那一项是减而不是加,这里提醒一下,拉格朗日乘子法的约束条件是小于等于0的。然后还是强对偶转换,求导代入,最后得到:
对比一下硬间隔和软间隔,最终得到的优化问题是一致的,不同的地方在于软间隔增加了一个约束条件 。
5、实例:
已知一个训练集,现在有正例(3,3)T,(4,3)T ,负例(1,1)T ,试求最大间隔分离超平面。
答:按照上述算法,构建训练集约束最优化问题: