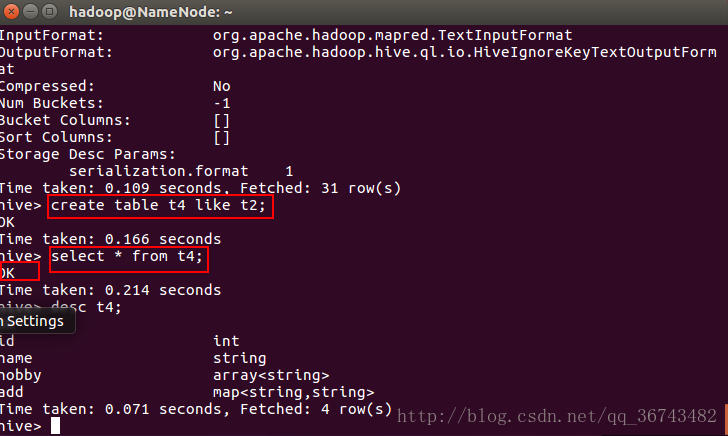
目录
1、SVM概念描述
2、SVM数学表达及相关计算
3、SVM优化问题定义
附:证明区
【证明1】
【计算1】
1、SVM概念描述
如图一所示,存在两个数据集,我们希望通过一个超平面将两个数据集分割开,并且我们希望这个超平面离两个数据集越远越好,某种意义上,这代表两个数据集分的更开。即图中的margin可以越大越好。

因为margin越大,对于新的数据点,错误分类的可能就越小。
如图二所示。可以看到,图中有两个可以选择的hyperplane,其中绿色的hyperplane的margin比较小,而黄色的比较大。对于一个新的点,图中用紫色圆形块标注,如果使用绿色的hyperplane将会把这个点归到第二个数据集中,而使用黄色的hyperplane则会归到第一个数据集,显然,如果去掉这两个hyperplane,单纯靠人为判断,我们也会将新的点归到第一个数据集,也就是说,此时margin比较小的绿色hyperplane对新的点的归类是错误的。这也就是我们说的,margin越大错误分类可能性越小。

2、SVM数学表达及相关计算
目标:找到一个超平面 来区分两个数据集,且超平面距离两个数据集的距离要最大。
其中yi是第i个点的标签,+1表示属于第一个数据集,-1表示属于第二个数据集。
这样对于新的点x,我们就可以通过的值判断x属于哪个数据集。
但是还需要注意到,中有两个未知变量,分别是
,这两个未知量需要通过原先有的带标签数据集来决定。
为了严格起见以及方便运算(更好确定margin大小),我们做一点小小的调整。
通过选取新的,更新y的定义如下:
改变前后示意图如图三所示。

但要注意的是,这是等价的转换,因为图三左边的
和右边的
,生成新的
,也不满足
的话(既不在黄色区域也不在蓝色区域),在第二张图中,也不会有点的
具体证明过程写在文末证明区【证明1】,自行食用~
通过改变定义,我们可以得到margin的距离,从图三的右图也可以发现,这个距离就是与
之间的距离。
这个距离通过计算可以知道是
计算过程同样写在文末证明区【计算1】,感兴趣的自行查看~
3、SVM优化问题定义
通过以上对目标的阐述以及相关计算,我们可以对SVM问题进行定义:
其中第一项中用来衡量距离大小,
用来衡量错误分类情况,其中
为预测的标签,
是真实标签。
则是用来确定这两项的比重,
越大,追求更大的margin就成了主要目标,否则,追求更小的错误分类成为主要目标。
然而这还是基础版本的SVM,因为这个函数第二项是不平滑项,而优化问题中不平滑项通常需要转换成平滑项,可以通过使用Huber函数将后一项平滑化。也有其他处理方式,这里不过多介绍。
附:证明区
【证明1】

【计算1】