声明:本实验环境是Apache hadoop-2.2.0,zookeeper-3.4.5,mysql Server version: 5.1.73作为元数据库,hive版本是apache-hive-0.9.0-bin,都是apache,不是CDH和其他。本实验集群3台,一个主节点(hadoop1),三个从节点(hadoop1,hadoop2,hadoop3),zk在三个节点中都安装。本实验的数据都是自己设计和添加的。
- 启动zk:zkServer.sh start
- 启动hdfs:start-dfs.sh
- 启动yarn:start-yarn.sh
- 启动mysql:service mysqld start
- jps
[root@hadoop1 host]# jps
4388 RunJar
3435 NameNode
3693 SecondaryNameNode
3550 DataNode
4576 Jps
3843 ResourceManager
2076 QuorumPeerMain
3943 NodeManager
6.进入hive的命令行模式:
[root@hadoop1 host]# hive
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Logging initialized using configuration in jar:file:/usr/host/hive/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/root/hive_job_log_root_201606011756_819925906.txt
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/host/hadoop/hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/host/hive/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
可能是hive版本较老了,出现以上warning警告忽略就可以了,不是error。
7. 进入default数据库
hive> show databases;
OK
default
Time taken: 4.34 seconds
hive> use default;
OK
Time taken: 0.057 seconds
hive> show tables;
OK
testtable
Time taken: 0.32 seconds
----------
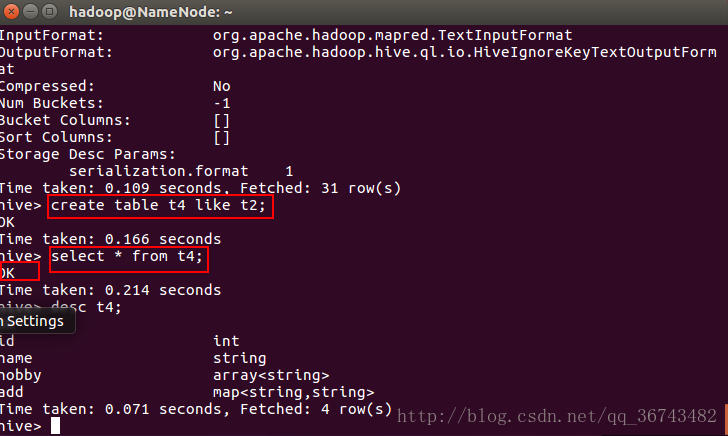
目前有一个testable表,我先删除,然后再看看是怎么创建的。8.删除testable表
hive> drop table testable;
OK
Time taken: 4.373 seconds
9.创建表testable,注意一定要在语句后面加分号“;”,否则会出错。
hive> create table testtable(name string comment 'name value',addr string comment 'addr value');
OK
Time taken: 0.262 seconds
10.看看表的描述信息
hive> desc testtable;
OK
name string name value
addr string addr value
Time taken: 0.215 seconds
#这里面有两个字段name和addr,都是string类型的,描述信息comment分别是“name value”和“addr value”。
#也可以看拓展的描述信息
hive> desc formatted testtable;
OK
# col_name data_type comment name string name value
addr string addr value # Detailed Table Information
Database: default
Owner: root
CreateTime: Wed Jun 01 18:20:24 PDT 2016
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/user/hive/warehouse/testtable
Table Type: MANAGED_TABLE
Table Parameters: transient_lastDdlTime 1464830424 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: serialization.format 1
Time taken: 0.249 seconds注意以上的两个地方:Location: hdfs://hadoop1:9000/user/hive/warehouse/testtable
Table Type: MANAGED_TABLE
Location表示数据的存储位置,Table Type表示这是一个内部表。除了内部表之外还会有外部表。
11.我们来建立一个外部表看看长什么样。
hive> create external table testtext(name string comment 'name value',addr string comment 'addr value');
OK
Time taken: 0.08 seconds
hive>
12 输入desc formatted testtext;
hive> desc formatted testtext;
OK
# col_name data_type comment name string name value
addr string addr value # Detailed Table Information
Database: default
Owner: root
CreateTime: Wed Jun 01 18:34:19 PDT 2016
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/user/hive/warehouse/testtext
Table Type: EXTERNAL_TABLE
Table Parameters: EXTERNAL TRUE transient_lastDdlTime 1464831259 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: serialization.format 1
Time taken: 0.2 seconds
hive>
现在加了关键字external后,可以看到Table Type变为了EXTERNAL_TABLE,有没有觉得很神奇?hah
13.接下来我们先把testtext表删除,再重新建立,但是【子段】之间的空格符和【行】之间的空格符
hive> drop table testtext;
OK
Time taken: 0.19 seconds
hive> create table if not exists testtext(> name string comment 'name value',> addr string comment 'addr value')> row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
OK
Time taken: 0.059 seconds
比之前的多了row format delimited fields terminated by ‘\t’ lines terminated by ‘\n’ stored as textfile; 这句话的意思是说字段之间以制表符(Tab)隔开,行之间以换行符隔开,format delimited意思是格式界定,格式包括字段之间的格式和行之间的格式,terminated 是结束的意思。
我们再来看一下具体的描述信息:
hive> desc formatted testtext;
OK
# col_name data_type comment name string name value
addr string addr value # Detailed Table Information
Database: default
Owner: root
CreateTime: Wed Jun 01 18:41:03 PDT 2016
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/user/hive/warehouse/testtext
Table Type: MANAGED_TABLE
Table Parameters: transient_lastDdlTime 1464831663 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: field.delim \t line.delim \n serialization.format \t
Time taken: 0.314 seconds
hive>
信息上说,这是一个内部表,因为没有加关键字external嘛。另外看最后面的Storage Desc Params: field.delim 是\t,line.delim 是\n ;serialization.format 是\t,简单吧~
14.现在我们有两个表了testtable和testtext吧,我们插入点数据来玩玩吧。我是在本地的/usr/host 目录下建立data文件,里面的数据如下。当心:
[root@hadoop1 host]# vi data
test table
test table1
15 把linux上的/usr/host/data文件加载到testtable上。
hive> load data local inpath '/usr/host/data' overwrite into table testtable;
Copying data from file:/usr/host/data
Copying file: file:/usr/host/data
Loading data to table default.testtable
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted /user/hive/warehouse/testtable
OK
Time taken: 0.981 seconds
hive> select * from testtable;
OK
test table NULL
test table1 NULL
Time taken: 0.328 seconds
hive>
哎?我select * from testtable,为啥后面多了NULL?出现这样的情况很正常,当初建立testtable的时候我就没有指定字段之间用什么分割的对吧,hive就把“test tabel”当做一个字段了,那后面还有一个字段怎么办?用NULL来表示咯,这个NULL地球人都知道的吧?
那再来插入数据一次,看看什么情况:
hive> load data local inpath '/usr/host/data' into table testtable;
Copying data from file:/usr/host/data
Copying file: file:/usr/host/data
Loading data to table default.testtable
OK
Time taken: 0.215 seconds
hive> select * from testtable;
OK
test table NULL
test table1 NULL
test table NULL
test table1 NULL
Time taken: 0.159 seconds
hive>
嘿嘿,又追加了数据了吧,注意哦,overwrite是覆盖,把overwrite换成into是追加。
16 好了,砸门再来建一个表xielaoshi
hive> drop table if exists xielaoshi;
OK
Time taken: 0.042 seconds
hive> create external table if not exists xielaoshi(> name string,> salary float,> meinv array<string>,> haoche map<string,float>,> haoza struct<street:string,city:string,state:string, zip:int>)> row format delimited fields terminated by '\t'> collection items terminated by ','> map keys terminated by ':'> lines terminated by '\n'> stored as textfile> location '/data/';
OK
Time taken: 0.137 seconds
hive>
这里的字段有五个,name,salary,meinv,haoche,haoza.其中meinv所对应的数据类型是数组型的array,haoche对应的是map键值对型的,haoza对应的是struct结构体。
问题又来啦!stored as textfile是什么鬼?其实就是文件格式啦!文件格式在hive中主要是三种:textfile、Sequencefile(序列化文件,学hadoop的都会知道啦)、Rcfile。
17 来来来,看看描述信息
hive> desc formatted xielaoshi;
OK
# col_name data_type comment name string None
salary float None
meinv array<string> None
haoche map<string,float> None
haoza struct<street:string,city:string,state:string,zip:int> None # Detailed Table Information
Database: default
Owner: root
CreateTime: Wed Jun 01 19:15:27 PDT 2016
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop1:9000/data
Table Type: EXTERNAL_TABLE
Table Parameters: EXTERNAL TRUE transient_lastDdlTime 1464833727 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params: colelction.delim , field.delim \t line.delim \n mapkey.delim : serialization.format \t
Time taken: 0.163 seconds
hive>
看到那个Location木有啊?这是什么情况呢?其实很简单得,就是指定了数据位置在哪里,为毛要指定?其实这是外部表的一个特点,砸门慢慢观察。
18 看看表谢老师里面的数据吧!
hive> select * from xielaoshi;
OK
wang 123.0 ["a1","a2","a3"] {"k1":1.0,"k2":2.0,"k3":3.0} {"street":"s1","city":"s2","state":"s3","zip":4}
liu 456.0 ["a4","a5","a6"] {"k4":4.0,"k5":5.0,"k6":6.0} {"street":"s4","city":"s5","state":"s6","zip":6}
zhang 789.0 ["a7","a8","a9"] {"k7":7.0,"k8":8.0,"k9":9.0} {"street":"s7","city":"s8","state":"s9","zip":9}
Time taken: 0.183 seconds
hive>

如果你是初学者你又会疑惑这数据怎么搞的呀?
其实就两步:
[root@hadoop1 host]# vi xielaoshi
wang 123 a1,a2,a3 k1:1,k2:2,k3:3 s1,s2,s3,4
liu 456 a4,a5,a6 k4:4,k5:5,k6:6 s4,s5,s6,6
zhang 789 a7,a8,a9 k7:7,k8:8,k9:9 s7,s8,s9,9[root@hadoop1 host]# hadoop fs -put xielaoshi /data/
[root@hadoop1 host]# hadoop fs -text /data/xielaoshi
wang 123 a1,a2,a3 k1:1,k2:2,k3:3 s1,s2,s3,4
liu 456 a4,a5,a6 k4:4,k5:5,k6:6 s4,s5,s6,6
zhang 789 a7,a8,a9 k7:7,k8:8,k9:9 s7,s8,s9,9`
搞定了吧,所以接下来实验的数据其实都是这么弄来的,现在linux上编辑,需要上传到hdfs上就执行hadoop fs -put [local 文件] [目标目录]
19 hive的功能是啥?除了存储就查找嘛,当然我们要来玩玩怎么查找啊!
上代码!!!
hive> select meinv[1] from xielaoshi;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
16/06/01 19:34:48 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/06/01 19:34:48 INFO Configuration.deprecation: mapred.system.dir is deprecated. Instead, use mapreduce.jobtracker.system.dir
16/06/01 19:34:48 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Execution log at: /tmp/root/root_20160601193434_f64326c5-c901-47b8-b0b6-163aa3ccd4ce.log
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/host/hadoop/hadoop-2.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/host/hive/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 19:35:10,267 null map = 0%, reduce = 0%
2016-06-01 19:35:24,814 null map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
2016-06-01 19:35:25,943 null map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
2016-06-01 19:35:27,205 null map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
MapReduce Total cumulative CPU time: 800 msec
Ended Job = job_1464828076391_0001
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
a2
a5
a8
Time taken: 45.655 seconds
哎哟!这屎长屎长的代码,走的是啥呀?MapReduce 啊!其实很多是警告信息,怪我咯!Total MapReduce jobs = 1,Hadoop job information for null: number of mappers: 1; number of reducers: 0。看到没,reducers是0个,这没啥奇怪的!
继续:
hive>select haoche["k2"] from xielaoshi;
Total MapReduce jobs = 1
Launching Job 1 out of 1
警告信息省略
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 19:38:21,377 null map = 0%, reduce = 0%
2016-06-01 19:38:32,483 null map = 100%, reduce = 0%, Cumulative CPU 0.71 sec
2016-06-01 19:38:33,560 null map = 100%, reduce = 0%, Cumulative CPU 0.71 sec
MapReduce Total cumulative CPU time: 710 msec
Ended Job = job_1464828076391_0002
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
2.0
NULL
NULL
Time taken: 31.13 seconds
为啥后面出来两个NULL?你猜~
继续:
hive> select haoza.city from xielaoshi;
Total MapReduce jobs = 1
Launching Job 1 out of 1
警告信息省略
Job running in-process (local Hadoop)
Hadoop job information for null: number of mappers: 1; number of reducers: 0
2016-06-01 19:41:14,958 null map = 0%, reduce = 0%
2016-06-01 19:41:25,138 null map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
2016-06-01 19:41:26,255 null map = 100%, reduce = 0%, Cumulative CPU 0.8 sec
MapReduce Total cumulative CPU time: 800 msec
Ended Job = job_1464828076391_0003
Execution completed successfully
Mapred Local Task Succeeded . Convert the Join into MapJoin
OK
s2
s5
s8
Time taken: 28.25 seconds
hive>
有点累了,休息一下。如果你看到此文,想进一步学习或者和我沟通,加我微信公众号:名字:谢华东

蟹蟹你啊!