点击上方,选择星标或置顶,不定期资源大放送!
阅读大概需要15分钟
Follow小博主,每天更新前沿干货
作者:张墨一
知乎链接:https://zhuanlan.zhihu.com/p/58248608
本文仅作学术分享,若侵权,请联系后台删文处理
1 任务背景:
本次实验拟设计一个智能问答系统,并应当保证该智能问答系统可以回答5个及其以上的问题。由于本实验室目前正在使用知识图谱搭建问答系统,故而这里将使用知识图谱的方式构建该智能问答系统。这里将构建一个关于歌曲信息的问答系统。以“晴天”为例,本系统应当能够回答晴天的歌词是什么,晴天是哪首专辑的歌曲,该专辑是哪一年发行的,该专辑对应的歌手是谁,该歌手的的基本信息是什么。
本系统的环境配置过程以及全部代码均已上传Github。下面的文章主要介绍的是系统总体结构以及部分代码解析。
Github地址:https://github.com/zhangtao-seu/Jay_KG
2 系统总体工作流程图
在搭建系统之前,第一步的任务是准备数据。这里的准备的数据包括周杰伦的姓名,个人简介,出生日期,以及发行的所有专辑名字,《叶惠美》专辑的名字,简介以及发行日期,《以父之名》、《晴天》的歌曲名和歌词。
准备好数据之后,将数据整理成RDF文档的格式。这里采用手工的方式在protégé中构建本体以及知识图谱。本体作为模式层,这里声明了三个类,包括歌手类、专辑类和歌曲类;声明了四种关系,也叫objectProperty,包括include,include_by,release和release_by。其中include和include_by声明为inverseOf关系,表示专辑和歌曲之间的包含和被包含的关系。Release和release_by声明为inverseOf关系表示歌手和专辑之间的发行和被发行的关系;声明了8种数据属性,也叫DataProperty,分别为singer_name,singer_birthday,singer_introduction,album_name,album_introduction,album_release_date,song_name和song_content。将上述准备好的数据以individual和dataProperty的形式写进知识图谱。至此,就准备好了我们的RDF/OWL文件了。
接着,为了使用RDF查询语言SPARQL做后续的查询操作,这里使用Apache Jena的TDB和Fuseki组件。TDB是Jena用于存储RDF的组件,是属于存储层面的技术。Fuseki是Jena提供的SPARQL服务器,也就是SPARQL endpoint。这一步中,首先利用Jena将RDF文件转换为tdb数据。接着对fuseki进行配置并打开SPARQL服务器,就可以通过查询语句完成对知识图谱的查询。
最后,将自然语言问题转换成SPARQL查询语句。首先使用结巴分词将自然语言问题进行分词以及词性标注。这里将专辑名字和歌曲名字作为外部词典以保证正确的分词和词性标注。以“叶惠美”为例,结巴分词将“叶惠美”标注为nr,即人名,这里“叶惠美”作为专辑名字应该标注为nz,即专有名词。对于不同类型的问题,我们将问题匹配给不同的查询语句生成函数从而得到正确的查询语句。将查询语句作为请求参数和Fuseki服务器通信就能得到相应的问题结果。上述工作流程图如图2-1所示。
图2-1 系统工作流程图
3 系统实现
3.1 系统实现工具和环境
使用protégé构建知识库的本体和知识图谱。首先是定义模式层,包括class,objectProperty和dataProperty。以歌曲类为例,其RDF代码为:
<!-- http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#歌曲 -->
<owl:Class rdf:about="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#歌曲"><rdfs:subClassOf><owl:Restriction><owl:onProperty rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#song_content"/><owl:allValuesFrom rdf:resource="http://www.w3.org/2001/XMLSchema#string"/></owl:Restriction></rdfs:subClassOf><rdfs:subClassOf><owl:Restriction><owl:onProperty rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#song_name"/><owl:allValuesFrom rdf:resource="http://www.w3.org/2001/XMLSchema#string"/></owl:Restriction></rdfs:subClassOf>
</owl:Class>可以看出class “歌曲”包含了song_name和song_content两个dataProperty。以include的关系为例,其RDF代码如下:
<!-- http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#include -->
<owl:ObjectProperty rdf:about="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#include">
<owl:inverseOf rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#include_by"/>
<rdfs:domain rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#专辑"/>
<rdfs:range rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#歌曲"/>
</owl:ObjectProperty>可以看出该关系和include_by是inverseOf的关系,其关系主语是专辑,宾语是歌曲。以singer_introduction的dataProperty为例,其RDF代码如下:
<!-- http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#singer_introduction -->
<owl:DatatypeProperty rdf:about="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#singer_introduction">
<rdfs:domain rdf:resource="http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#歌手"/>
<rdfs:range rdf:resource="http://www.w3.org/2001/XMLSchema#string"/>
</owl:DatatypeProperty>可以看出其主语是歌手类,其宾语是字符串。
接着是数据层。图3-1和图3-2是系统的知识图谱可视化的结果。可以看出,“七里香”是一个专辑,“东风破”是一首歌曲。
图3-1专辑知识图谱可视化
图3-2 歌曲知识图谱可视化
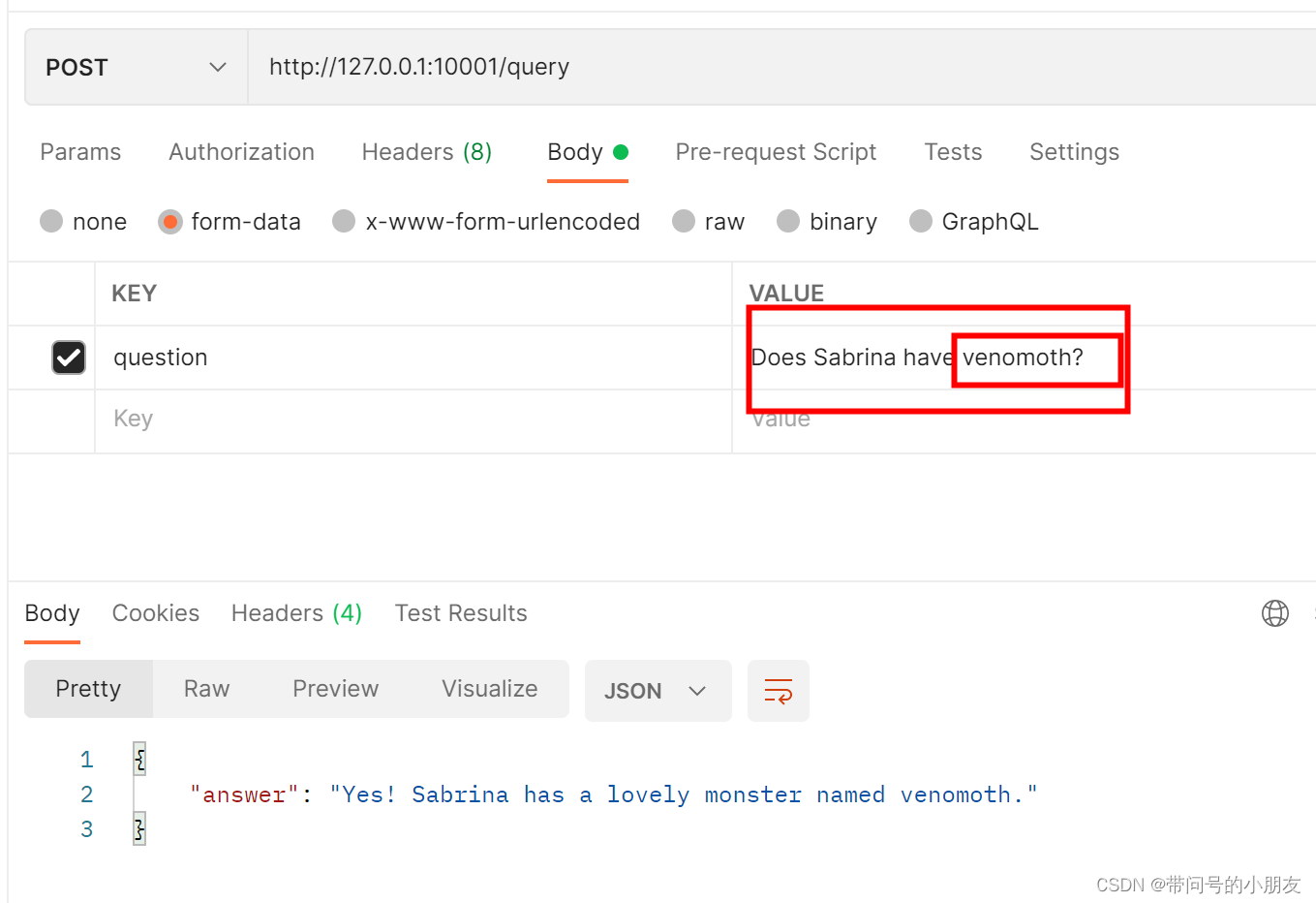
使用Feseki启动SPARQL服务器,可以在localhost:3030中实现数据的查询。以查询“以父之名”的专辑为例,图3-3展示其查询代码和查询结果,可以看出如下语句可以得到查询结果“叶惠美”。
图3-3 Feseki平台的查询情况
3.2 自然语言处理核心代码分析
使用结巴分词将自然语言句子实现分词和词性标注。其核心代码如下:
import jieba
import jieba.posseg as pseg
class Word(object):
def __init__(self, token, pos):self.token = tokenself.pos = pos
class Tagger:
def __init__(self, dict_paths):# TODO 加载外部词典for p in dict_paths:jieba.load_userdict(p)
@staticmethod
def get_word_objects(sentence):# 把自然语言转为Word对象return [Word(word.encode('utf-8'), tag) for word, tag in pseg.cut(sentence)]这段代码可以将句子作为一个输入,输出句子的分子和词性,以“叶惠美是什么发布的?”为例,可以得到以下结果:
图3-4 结巴分词示意图
将句子作为参数传递给Rule对象,根据关键字匹配相一致的查询语句的生成函数,Rule对象和关键字匹配的代码如下:
from refo import finditer, Predicate, Star, Any, Disjunction
import reclass W(Predicate):def __init__(self, token=".*", pos=".*"):self.token = re.compile(token + "$")self.pos = re.compile(pos + "$")super(W, self).__init__(self.match)def match(self, word):m1 = self.token.match(word.token.decode("utf-8"))m2 = self.pos.match(word.pos)return m1 and m2class Rule(object):def __init__(self, condition_num, condition=None, action=None):assert condition and actionself.condition = conditionself.action = actionself.condition_num = condition_numdef apply(self, sentence):matches = []for m in finditer(self.condition, sentence):i, j = m.span()matches.extend(sentence[i:j])return self.action(matches), self.condition_num
# TODO 定义关键词
pos_person = "nr"
pos_song = "nz"
pos_album = "nz"
person_entity = (W(pos=pos_person))
song_entity = (W(pos=pos_song))
album_entity = (W(pos=pos_album))
singer = (W("歌手") | W("歌唱家") | W("艺术家") | W("艺人") | W("歌星"))
album = (W("专辑") | W("合辑") | W("唱片"))
song = (W("歌") | W("歌曲"))
birth = (W("生日") | W("出生") + W("日期") | W("出生"))
english_name = (W("英文名") | W("英文") + W("名字"))
introduction = (W("介绍") | W("是") + W("谁") | W("简介"))
song_content = (W("歌词") | W("歌") | W("内容"))
release = (W("发行") | W("发布") | W("发表") | W("出"))
when = (W("何时") | W("时候"))
where = (W("哪里") | W("哪儿") | W("何地") | W("何处") | W("在") + W("哪"))# TODO 问题模板/匹配规则
"""
1.周杰伦的专辑都有什么?
2.晴天的歌词是什么?
3.周杰伦的生日是哪天?
4.以父之名是哪个专辑里的歌曲?
5.叶惠美是哪一年发行的?
"""
rules = [Rule(condition_num=2, condition=person_entity + Star(Any(), greedy=False) + album + Star(Any(), greedy=False), action=QuestionSet.has_album),Rule(condition_num=2, condition=song_entity + Star(Any(), greedy=False) + song_content + Star(Any(), greedy=False),action=QuestionSet.has_content),Rule(condition_num=2, condition=person_entity + Star(Any(), greedy=False) + introduction + Star(Any(), greedy=False),action=QuestionSet.person_inroduction),Rule(condition_num=2, condition=song_entity + Star(Any(), greedy=False) + album + Star(Any(), greedy=False),action=QuestionSet.stay_album),Rule(condition_num=2, condition=song_entity + Star(Any(), greedy=False) + release + Star(Any(), greedy=False),action=QuestionSet.release_album),
]匹配成功后,通过action动作出发相对应的函数能够生成相对应的查询语句。以查询“以父之名是哪个专辑的歌曲?”为例,其生成查询语句的代码如下:
# TODO SPARQL前缀和模板
SPARQL_PREXIX = u"""
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX : <http://www.semanticweb.org/张涛/ontologies/2019/1/untitled-ontology-32#>
"""
SPARQL_SELECT_TEM = u"{prefix}\n" + \u"SELECT {select} WHERE {{\n" + \u"{expression}\n" + \u"}}\n"
class QuestionSet:
@staticmethoddef stay_album(word_object):# 以父之名是哪个专辑的歌曲select = u"?x"sparql = Nonefor w in word_object:if w.pos == pos_song:e = u" :{song} :include_by ?o."\u" ?o :album_name ?x.".format(song=w.token.decode('utf-8'))sparql = SPARQL_SELECT_TEM.format(prefix=SPARQL_PREXIX,select=select,expression=e)breakreturn sparql
最后,将得到的查询语句作为请求参数和SPARQL服务器进行通信并对得到的结果进行解析就能得到我们想要的答案,其核心代码如下:
from SPARQLWrapper import SPARQLWrapper, JSON
from collections import OrderedDictclass JenaFuseki:def __init__(self, endpoint_url='http://localhost:3030/jay_kbqa/sparql'):self.sparql_conn = SPARQLWrapper(endpoint_url)def get_sparql_result(self, query):self.sparql_conn.setQuery(query)self.sparql_conn.setReturnFormat(JSON)return self.sparql_conn.query().convert()@staticmethoddef parse_result(query_result):"""解析返回的结果:param query_result::return:"""try:query_head = query_result['head']['vars']query_results = list()for r in query_result['results']['bindings']:temp_dict = OrderedDict()for h in query_head:temp_dict[h] = r[h]['value']query_results.append(temp_dict)return query_head, query_resultsexcept KeyError:return None, query_result['boolean']以上就是将自然语言转换成SPARQL查询语言并与Feseki进行通信的核心代码。
3.3 代码运行结果
这里分别从歌手的简介,专辑的发行时间,歌手的所有专辑,歌曲属于哪个专辑以及歌曲的歌词等5类问题做问答,均能达到良好的表现效果。其问答情况如图3-5所示。
图3-5 问答系统运行结果实例
最后:
代码部分参考了:https://zhuanlan.zhihu.com/knowledgegraph
配置部分参考了:https://blog.csdn.net/keyue123/article/details/85266355
重磅!自然语言处理技术交流群已成立!
欢迎各位NLPer加入自然语言处理技术交流群,目前群内已有上百人!本群旨在交流文本分类、知识图谱、语音识别、阅读理解、机器翻译、情感分析、信息检索、问答系统等自然语言处理领域内容。自然语言处理领域前沿信息将会第一时间在群里发布!欢迎大家进群一起交流学习!
麻烦大家进群后请备注:研究方向+学校/公司+昵称(如文本分类+浙大+小民)
广告商、博主请绕道!
???? 长按识别添加,邀请您入群!