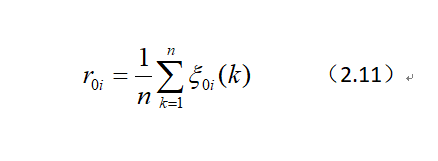这一篇就简单介绍一下灰色关联分析吧。灰色关联分析主要有两个作用,一是进行系统分析,判断影响系统发展的因素的重要性。第二个作用就是用于综合评价问题,给出研究对象或者方案的优劣排名。
不过这里我只能简单介绍一下,更加深入的原理,可能需要我专门学习之后才能清楚地表达出来。不过应用起来倒不是很难,部分原理理解不清晰应该也不影响使用,就当作了解一个新方法吧。
事实上越往后学,例如多元回归分析、运筹学相关、时间序列分析、各类预测模型、聚类分类等等,都涉及到很多有难度的数学推导。我自己即使有所理解和学习,但想要比较简单易懂地表达出来,还是需要更长时间沉淀的。所以目前写学习笔记,就只能简单说明一下原理,然后讲一下傻瓜式应用了。等我理解得更加深入了,再回头把写得不够深入清晰的文章翻新一下吧。
好的,言归正传,讲一讲灰色关联分析吧~
灰色关联分析
“在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。”
以上内容摘自百度,大概就是这么回事。灰色关联分析的研究对象往往是一个系统。系统的发展会受到多个因素的影响。我们常常想知道,在众多的影响因素中,哪些是主要因素,哪些是次要因素;哪些因素影响大,哪些因素影响小;哪些具有促进作用,哪些具有抑制作用等等。
数理统计中常常使用回归分析、方差分析、主成分分析等来探究这个问题。但上述的方法有一些共同的不足之处。例如这些方法都要求大量的数据,数据小则结果没有太大意义;有时候还会要求样本服从某个特殊分布,或者出现量化结果与定性分析不符合的情况。而灰色关联分析则可以较好地应对这种问题。
灰色关联分析对样本量的多少和样本有无规律并没有要求(当然样本量也不能太少,就两、三个样本还分析什么),量化结果基本上与定性分析相符合。灰色关联分析的基本思想是,根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线形状越接近,相应序列之间的关联度就越大,反之就越小。
嗯,对于上述原理,简单翻译一下,就是研究两个或多个序列(序列可以理解为系统中的因素或者指标)构成的曲线的几何相似程度。越相似,越说明他们的变化具有某种紧密的联系,也就是关联度高。所以这个方法也几乎是从纯数据的角度去研究关联性,如果两个没啥关系的指标,在曲线形状上表现得极为相似,那灰色关联分析就会认为二者关联程度很高。当然这只是一个比较极端的例子,对于一般的数据或者系统,用曲线形状来衡量关联度,也是有一定的道理的。
进行系统分析
我们首先来介绍一下第一个应用,也是它的基本应用,系统分析。其分析的主要内容,就是给“影响系统发展的各因素”在重要程度或者说影响程度方面排序。用灰色关联分析的说法,就是给出各个因素与系统总体的关联度排序。关联度越高,说明相应因素对系统发展的影响越大。至于关联度,就是上文提到的曲线形状的近似程度了。嗯,其实模模糊糊还是可以理解灰色关联分析的,就是感觉上有一点儿不靠谱hhh
下面直接举个例子来讲解应用灰色关联分析的方法。(原理已经讲过了呀)
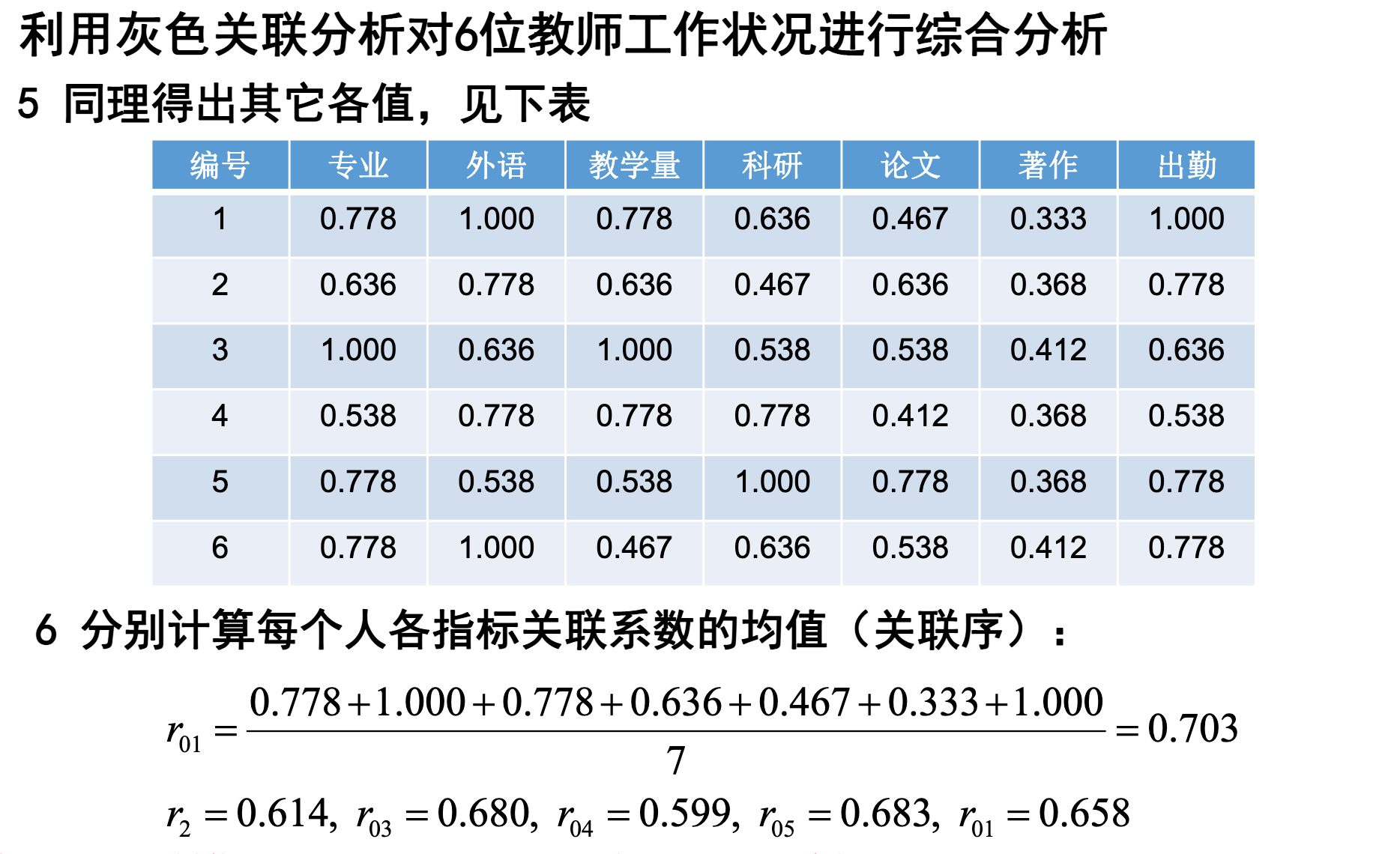
下表为某一地区国内生产总值的统计数据(单位:百万元),问该地区从2000年到2005年之间哪一种产业对GDP总量影响最大。
诺,这就是一个典型的系统分析问题,找出对GDP发展影响最大的一个因素。那我们需要怎么做呢?想想看,灰色关联分析的原理是,比较序列曲线几何形状的相似性,那当然要先把序列曲线给画出来呀。嗯,第一步就是画出序列曲线啦。
这里需要注意,我们想要研究各因素对系统总体的关联度,就需要找出一个可以代表系统总体发展的指标,这里就是GDP。类似的,我们想要反映教育发达程度,就可以使用国民平均接受教育的年数来代表;我们想要反映社会治安面貌,就可以使用刑事案件的发生率来表达;想要反映国民健康水平,就可以使用医院挂号次数来表达。不管怎样,总是需要找到一个指标,对系统整体的发展进行刻画。
别的不说,只看曲线形状,我就觉得第一产业对GDP的影响最小了。GDP一直往高处走,而第一产业曲线的形状几乎就是平着的。而单看相似性,好像第二产业,也就是灰色曲线与GDP曲线最为相似。不过画出图像只是为了给出一个直观的感受和分析,曲线形状的近似程度,还是需要计算的。
第二步是确定分析序列。分析序列分为两类,一类称之为母序列,也就是反映系统整体行为特征或发展的数据序列,可以理解为回归分析中的因变量,这里就是GDP这一列。另一类称之为子序列,也就是影响系统发展的因素组成的数据序列,可以理解为回归分析中的自变量,这里就分别是第一产业,第二产业,第三产业的生产总值数据。
第三步是对数据进行预处理。预处理我们讲到许多了,例如正向化,标准化,归一化等等。这里预处理的目的就是去除量纲的影响,以及缩小数据范围方便计算。数据标准化往往就是这个作用。数据标准化有多种方法,例如 z − s c o r e z-score z−score标准化,就是原数据减去均值除以方差,随机变量往往使用这种方法;再比如 m i n − m a x min-max min−max标准化,就是 x − m i n m a x − m i n \frac {x-min}{max-min} max−minx−min。这两个方法之前都提到过。
那在这里,我们使用的标准化方法是每一个元素除以对应指标的均值,也就是 x i j 1 n ∑ i = 1 n x i j \frac {x_{ij}}{\frac 1n\sum_{i=1}^nx_{ij}} n1∑i=1nxijxij。嗯,我们展示一下处理之后的数据。用excel处理就可以了,比较方便。
第四步,计算处理后的子序列中各个元素与母序列相应元素的关联程度。记母序列为 x 0 = { x 0 ( 1 ) , x 0 ( 2 ) , . . . , x 0 ( n ) } x_0=\{x_0(1),x_0(2),...,x_0(n)\} x0={x0(1),x0(2),...,x0(n)},子序列为 x 1 = { x 1 ( 1 ) , x 1 ( 2 ) , . . . , x 1 ( n ) } x_1=\{x_1(1),x_1(2),...,x_1(n)\} x1={x1(1),x1(2),...,x1(n)}, x 2 = { x 2 ( 1 ) , x 2 ( 2 ) , . . . , x 2 ( n ) } x_2=\{x_2(1),x_2(2),...,x_2(n)\} x2={x2(1),x2(2),...,x2(n)}, x 3 = { x 3 ( 1 ) , x 3 ( 2 ) , . . . , x 3 ( n ) } x_3=\{x_3(1),x_3(2),...,x_3(n)\} x3={x3(1),x3(2),...,x3(n)}。我们首先计算出母子序列最小差 a = m i n ∣ x 0 ( k ) − x i ( k ) ∣ , ∀ i , k a=min|x_0(k)-x_i(k)|,\forall i,k a=min∣x0(k)−xi(k)∣,∀i,k,之后再计算一下母子序列最大差 b = m a x ∣ x 0 ( k ) − x i ( k ) ∣ , ∀ i , k b=max|x_0(k)-x_i(k)|,\forall i,k b=max∣x0(k)−xi(k)∣,∀i,k。计算如下表。
嗯,可以发现, a = 0.0007 a=0.0007 a=0.0007就是上表中最小的元素, b = 0.1861 b=0.1861 b=0.1861就是上表最大的元素。然后我们就可以计算子序列中每个元素与母序列相应元素的关联度啦。
灰色关联分析中,定义 γ ( x 0 ( k ) , x i ( k ) ) = a + ρ b ∣ x 0 ( k ) − x i ( k ) ∣ + ρ b , ∀ i , k \gamma(x_0(k),x_i(k))=\frac {a+\rho b}{|x_0(k)-x_i(k)|+\rho b},\forall i,k γ(x0(k),xi(k))=∣x0(k)−xi(k)∣+ρba+ρb,∀i,k,其中 ρ \rho ρ是分辨系数,一般位于 [ 0 , 1 ] [0,1] [0,1]之间,往往取 0.5 0.5 0.5。至于为什么要用这样一个公式定义子序列某元素与母序列相应元素的关联度呢?我就不晓得了……嗯,自行查阅,如果知道了请留言告诉我,谢谢!
第五步,计算各个序列,也就是指标与系统总体的关联程度。我们定义 γ ( x 0 , x i ) = ∑ k = 1 n γ ( x 0 ( k ) , x i ( k ) ) n \gamma(x_0,x_i)=\frac {\sum_{k=1}^n\gamma(x_0(k),x_i(k))}{n} γ(x0,xi)=n∑k=1nγ(x0(k),xi(k)),用它来表达某个指标与系统总体发展的关联度。
嗯,其实就是第四步,求出了指标内部各个元素与母序列对应元素的关联度,把他们求个平均值,就可以看作该指标与系统总体的关联度了。如果你可以接受上文中的关联度计算公式,想来接受这个关联度均值,应该不是太难。
上图就是该题的最终计算结果了,计算证明,取分辨系数为0.5时,第三产业对国内生产总值的影响最大。好像跟那个图片不是很符合……毕竟从图片上直观感受,应该是第二产业的曲线形状与GDP的曲线形状最为相近,结果计算出的是第三产业。那,我们换一下 ρ \rho ρ试试。
一番操作,还是第三产业对GDP影响最大。不过再次提醒,实际使用时, ρ = 0.5 \rho=0.5 ρ=0.5是最常用的。
如果要强行解释一波,大概就是GDP的增长率是有起伏的,2002-2005之间每一段折线的斜率是不同的,而第二产业2002-2005之间,基本是一条直线过去,相比之下,第三产业的增长变化,更像GDP的变化……好吧就是强行解释一下啦
上图是每一年的增量情况……嗯,好像也是灰色和蓝色更像,不过2003-2005的增量,也就是2002-2005这四年来看,第三产业和GDP的增长更加相似。而第二产业只有一两年比较相似,所以综合来看,可能还是第三产业对GDP的影响更大吧。
嗯,强行解释完毕。
最后对于系统分析问题,还有两个问题。
-
什么时候多元回归分析,什么时候使用灰色关联分析?
当样本个数较大时,使用正常的回归分析可能更好一点儿,当样本个数较少时,使用灰色关联分析可能更好一点儿。以及对于这一题,我们知道GDP=第一产业+第二产业+第三产业,如果使用多元回归分析,最后得到的表达式很可能就是 y = x 1 + x 2 + x 3 y=x_1+x_2+x_3 y=x1+x2+x3。这时候系数是一样大的,就看不出那个产业对于GDP影响更大了。所以,如果已知系统与各个指标存在这样的线性关系,多元回归的结果往往是找出这个线性关系,相当于做了无用功。不过一般也不会这样出题吧,这个算是特例了。 -
如果存在多个母序列?
我是还没有碰到过,如果真的有了,可以分开计算每个母序列与子序列的关联度,之后再进行进一步处理。
嗯,系统分析讲到这里。
进行综合评价
灰色关联分析用于综合评价的核心是,通过指标的关联度确定每个指标的权重,之后加权求和打分。
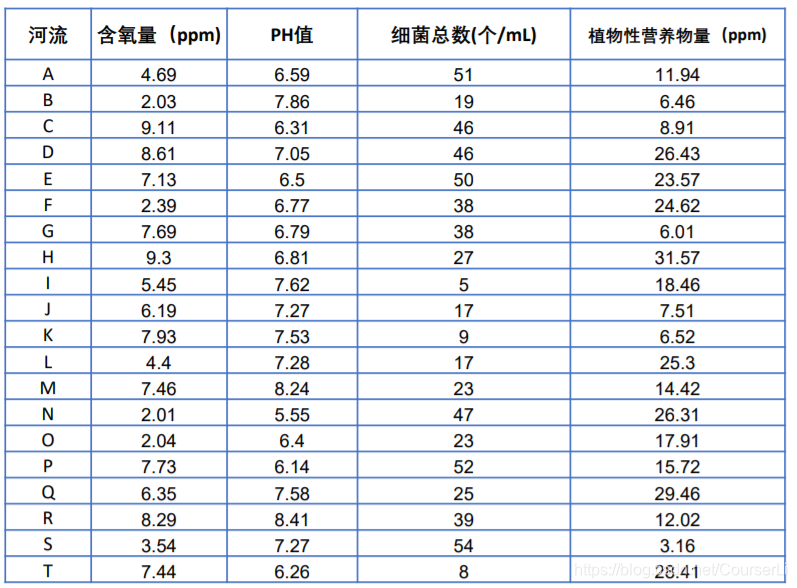
还是这二十条河流。评价水质,我们用灰色关联分析怎么做呢?
第一步、把所有指标进行正向化处理。正向化处理知道是什么吧,就是把极小型,中间型,区间型指标,全部转化为极大型指标。也就是要求数据值越大,最后得分越高。
第二步、对正向化的矩阵进行标准化。这里的标准化跟上面系统分析的标准化是一个东西。也就是用每一个元素除以对应指标的均值, x i j 1 n ∑ i = 1 n x i j \frac {x_{ij}}{\frac 1n\sum_{i=1}^nx_{ij}} n1∑i=1nxijxij,把数据的范围缩小,消除量纲影响。将经过了上述两步处理的矩阵记为 Z n × m = ( z i j ) n × m Z_{n×m}=(z_{ij})_{n×m} Zn×m=(zij)n×m
第三步、将正向化、预处理之后的矩阵,每一行取出一个最大值,作为母序列。嗯,这里就是灰色关联分析用于综合评价问题需要注意的点了,也就是人为的构造出这么一个母序列。
第四步、按之前提到的方法,计算各个指标与母序列的灰色关联度,记为 r 1 , r 2 , r 3 , . . . , r m r_1,r_2,r_3,...,r_m r1,r2,r3,...,rm。
第五步、计算各个指标的权重。每个指标的权重 w i = r i ∑ j = 1 m r j w_i=\frac {r_i}{\sum_{j=1}^mr_j} wi=∑j=1mrjri。也就是关联度占总体关联度之和的比重。
第六步、我们求出每个评价对象的得分。对于第 k k k个评价对象,其得分 S k = ∑ i = 1 m z k i w i S_k=\sum_{i=1}^mz_{ki}w_i Sk=∑i=1mzkiwi。这里的 z k i z_{ki} zki,也就是上面提到的经过正向化和标准化的矩阵 Z Z Z。 Z Z Z中的每一个指标都是极大型指标,数值越大分数应该越高,同时消除了量纲的影响。因此我们直接把 Z Z Z中的元素作为每个指标下对每个评价对象的打分,然后对指标的分数进行加权求和。权重就是我们上面使用灰色关联度求得的权重。这样子,我们就求出了最终的分数。
第七步、对分数进行归一化处理。 S i ∗ = S i ∑ j = 1 n S j S_i^*=\frac {S_i}{\sum_{j=1}^n Sj} Si∗=∑j=1nSjSi,这样子可以把分数全部放在0-1之间。归一化的好处就是,此时的分数可以解释成相应的研究对象在总体研究对象中“水某平”的百分比,也就是所处的位置。在水质题目中,也就是某河流水质情况在所有河流中所处的位置。嗯,用一个更通俗的说法,就类似于“您的成绩超越了百分之xx的同学”。这就是归一化的目的。
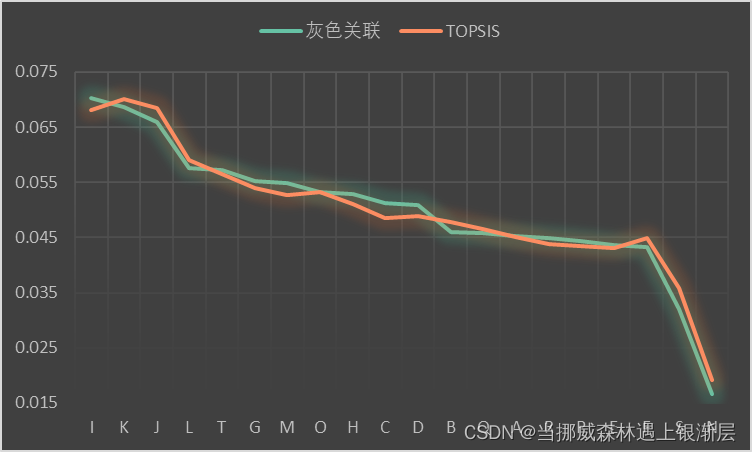
下图展示了对于水质情况的评价,使用TOPSIS方法与灰色关联分析的结果。
可以看到,这两种方法对于该问题最后的排序是不同的。第一名的取法就不一样,中间一部分顺序也比较不同,不过总体上还是比较相近的。hhh,不如再使用一个层次分析法,把三种方法得出的归一化后的分数,再取个平均,作为最终排序的依据。嗯,你看这个模型,是不是一下子就复杂了。
好的,本文就到这里,其实还是有几个迷惑的问题没有解决。
- 灰色关联分析中灰色关联度计算公式,其实际意义是什么?
- 灰色关联分析用于评价问题时,为什么要那样子构造母序列?
- 为什么使用关联度来衡量权重?
后两个好像可以强行解释,因为我们把正向化以及标准化后的矩阵当成分数矩阵了,所以取每一行的最大值,用来构造系统的最优得分序列,每一项方案就相当于系统的一次发展。之后计算关联度,就是看指标对系统最优序列的影响程度,影响程度越大,我们就赋给它更大的权重……嗯,强行解释
上面这三个问题,如果谁有比较好的想法,希望可以留个言告诉我,现在这里谢过!如果我以后慢慢理解了,也会在文章中更新。(不过发在微信公众号上可能是无法更新了,知乎和简书都可以)
灰色关联分析,我能分享的也就这么多了。如果想要继续了解,可以阅读《灰色系统理论及其应用》,刘思峰等著。嗯,灰色系统还有灰色系统预测,灰色组合模型,灰色决策,灰色聚类评估等应用,没事儿可以看看。
这两天知乎给我推送了一些数学建模相关的问答,其中一个是数学建模相关书籍。我把高赞回答推荐的书的电子版找了一下,如果需要的话,在微信公众号“我是陈小白”后台回复“数学建模书籍”即可。(其实回复文章名字也有东西的)
以上