摘要:使用图像-文本对的对比语言图像预训练模型(CLIP)在零样本和迁移学习环境下的图像分类方面都取得了令人印象深刻的结果。但直接应用CLIP模型识别图像区域进行对象检测效果并不好,这是因为CLIP被训练为将图像作为一个整体与文本描述相匹配,而没有进行图像区域和文本之间的细粒度对齐。为了缓解这个问题,我们提出了一种称为RegionCLIP的新方法,该方法显著扩展了CLIP以学习区域级视觉特征,从而实现图像区域和文本概念之间的细粒度对齐。我们的方法利用剪辑模型将图像区域与模板标题匹配,然后预训练我们的模型以在特征空间中对齐这些区域文本对。项目链接:https://github.com/microsoft/RegionCLIP
介绍:CLIP,ALIGN等工作取得了令人印象深刻的结果。继他们在图像分类方面取得成功之后,一个自然的问题是这些模型是否可以用于对图像进行推理?
为了回答这个问题,我们使用预训练CLIP模型构建了一个简单的R-CNN式对象检测器。该检测器从输入图像中裁剪候选对象区域,并通过将裁剪区域的视觉特征匹配到对象类别的文本嵌入来应用剪辑模型进行检测。结果当将预训练CLIP模型应用于对象检测时,性能会严重下降。原因有二,第一,CLIP训练时并不需要将局部图像区域和文本标记之间对齐。因此,模型无法将文本概念精确地定位到图像区域。第二,裁剪图像区域并将其与文本标记匹配在很大程度上忽略了对对象识别至关重要的背景环境。
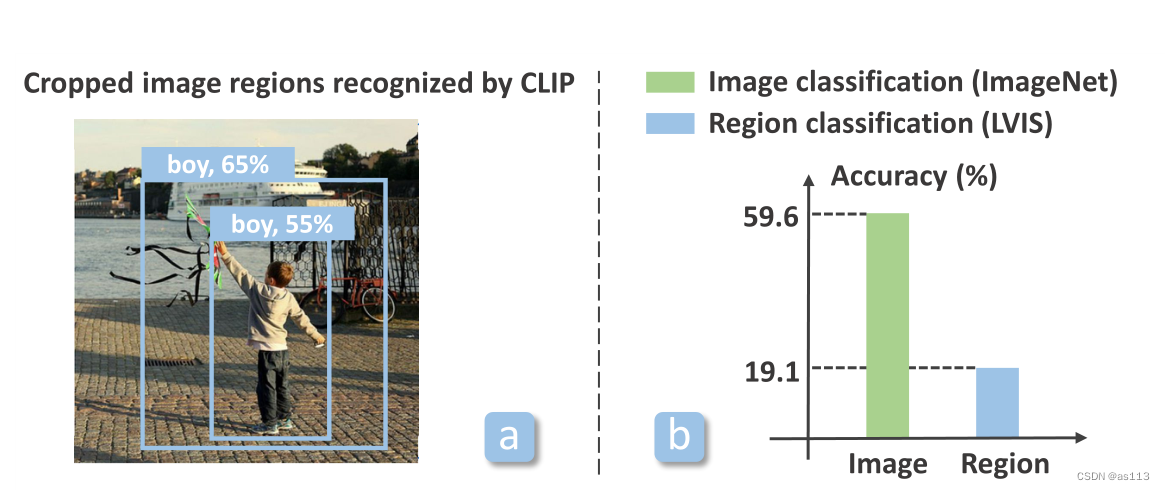
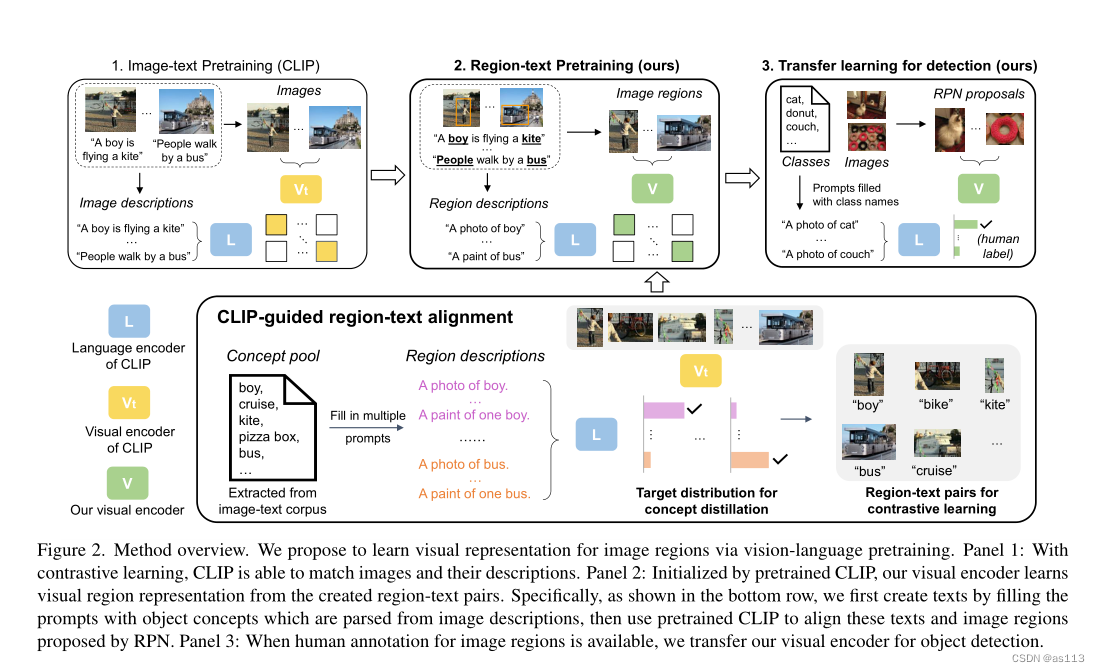
在本文中,我们探索了通过视觉语言预训练实现目标检测。我们的关键思想是在预训练期间显式对齐图像区域和文本标记。然而,出现了两个关键挑战。首先,图像区域和文本标记之间的细粒度对齐在图像-文本对中并不可靠。其次,图像的文本描述通常不完整,即许多图像区域不由文本描述。为了解决这些挑战,我们建议从预训练的视觉语言模型中进行引导,以对齐图像区域和文本标记,并填充缺失的区域描述。

具体来说,我们的方法从文本语料库解析的对象概念池开始,并通过将这些概念填充到预定义模板中来合成区域描述。给定来自对象建议或密集滑动窗口的输入图像及其候选区域,使用预训练CLIP模型对齐区域描述和图像区域,为区域文本对齐创建“伪”标签。此外,我们使用“伪”区域文本对和地面真实图像文本对,通过对比学习和知识提炼来预训练我们的视觉语言模型。虽然“伪”区域文本对是有噪声的,但它们仍然为学习区域表示提供了有用的信息,从而弥补了与对象检测之间的差距,我们的实验验证了这一点。
方法(使用RPN划定感兴趣区,再创建文本概念库,进行区域图像-文本特征比较):
1 问题描述:
我们的目标是学习涵盖丰富对象概念的区域视觉语义空间,以便用于开放词汇对象检测。定义图像I中区域r的内容对应的文本描述为t。在视觉语义空间中,从r中提取的视觉区域特征应与文本特征
匹配。
是获取图像I和区域位置r并输出该区域的视觉特征的视觉编码器。
是一种语言编码器,它将自然语言中的文本转换为语义特征。
图像理解的识别与定位:图像区域理解有两个关键组成部分:定位和识别。我们将这两个组成部分分离开来,使用现有的区域定位器,并通过学习区域视觉语义空间来专注于区域识别,而无需大量人工注释。
方法概述。如图所示,我们将和
表示为经过预训练的教师视觉和语言编码器,以将图像与其描述(如CLIP)相匹配。我们的目标是训练视觉编码器
,使其能够对图像区域进行编码,并将其与语言编码器
编码的区域描述相匹配。为了解决缺乏大规模区域描述的挑战,如图底部所示,我们构建了一个对象概念池,通过将概念填充到提示中来创建区域描述,并利用教师编码器
将这些文本描述与图像区域定位器提出的图像区域对齐。给定创建的区域文本对,我们的视觉编码器V通过对比学习和概念提炼学习匹配这些对。
2 基于区域的语言图像预训练
2.1 视觉和语义区域特征
视觉区域特征。图像区域可以由现成的对象定位器(如RPN)或密集滑动窗口(如随机区域)提取。默认情况下,我们使用一个RPN,该RPN在没有手工制作标签的边界框上进行预训练。我们使用RPN将所有图像提取出包含目标的图像区域,最后总共获得N个图像区域。(这里使用的是RoIAlign池化,其使用插值从完整图像的特征图中汇集区域视觉特征。)
语义区域特征。单个图像通常包含丰富的语义,涵盖数千个类别中的一个或多个对象。在大规模图像文本数据集中注释所有这些类别的成本很高。为此,我们首先构建一个大型概念库,以详尽地涵盖区域概念,而不考虑单个完整图像。我们创建了一个对象概念池,通过使用现成的语言解析器从文本语料库(例如,从互联网收集的图像描述)中解析这些概念。区域的语义表示通过两个步骤创建:(1)通过填充提示模板(例如CLIP的提示),为每个概念创建一个短句。例如,“风筝”概念将转换为“风筝照片”。(2) 我们使用预训练语言编码器L将所创建的文本描述编码为语义表示。
2.2 区域的视觉-文本语义对齐
区域文本图像对的对齐。我们利用教师视觉编码器Vt来创建图像区域和我们创建的文本(表示为语义嵌入)之间的对应关系。我们计算区域图像特征每个之前创建的概念特征之间的匹配分数。匹配分数由下式给出:
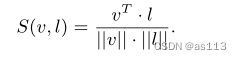
预训练策略。我们的预训练利用了创建的区域文本对和来自互联网的图像文本对。给定对齐的区域文本对(由{vi,lm}表示),我们基于不同图像的图像区域,使用对比损失和蒸馏损失预训练视觉编码器。损失函数如下:
1 对比损失
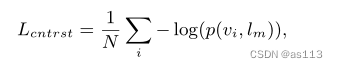
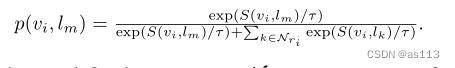
2 蒸馏损失
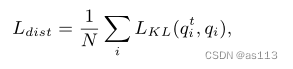
3 总损失函数