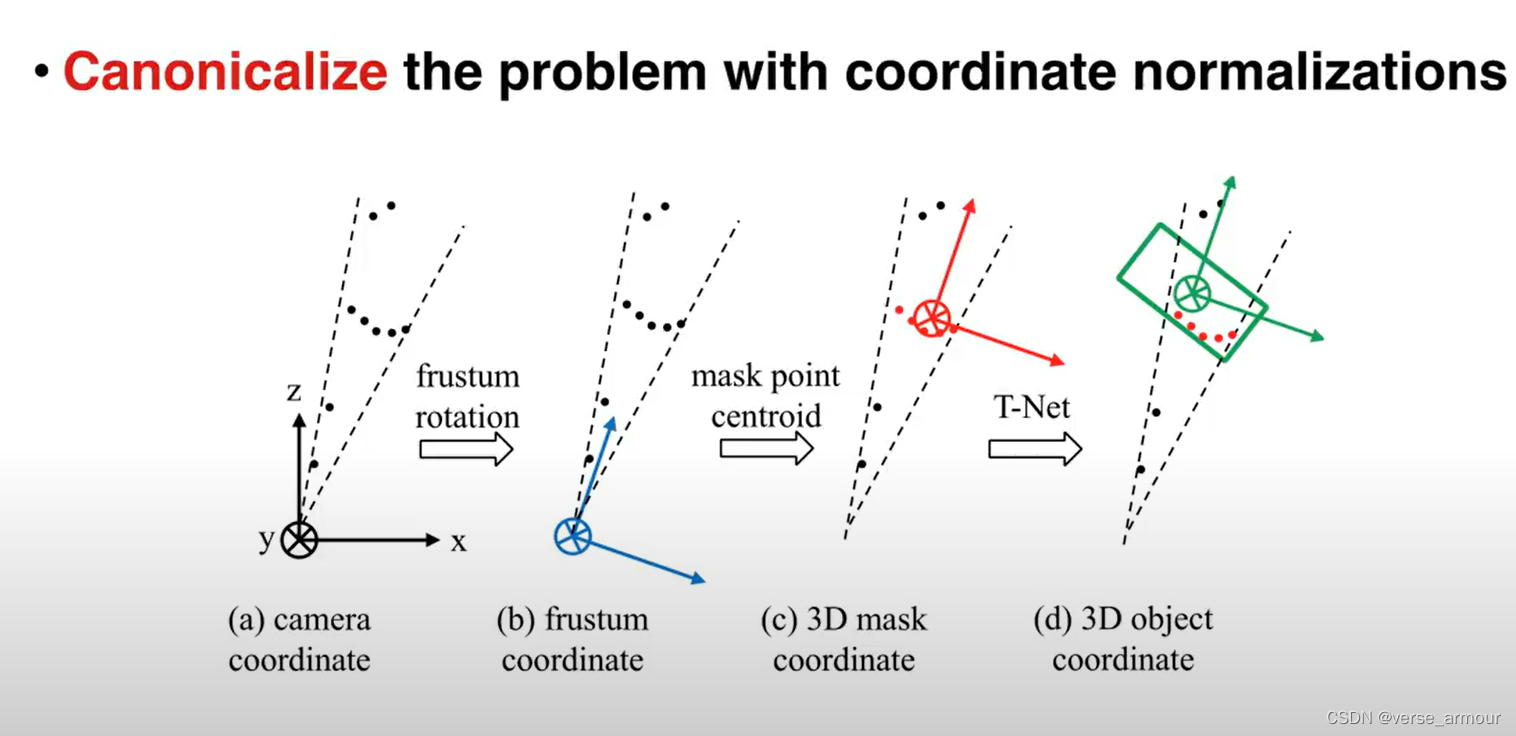
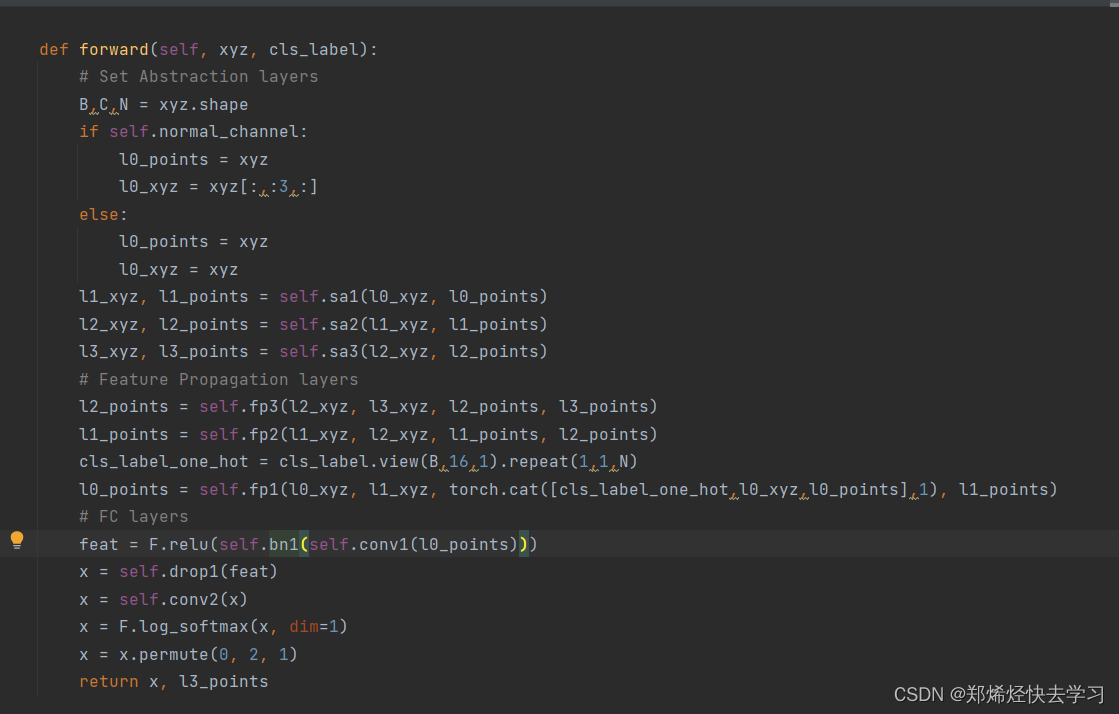
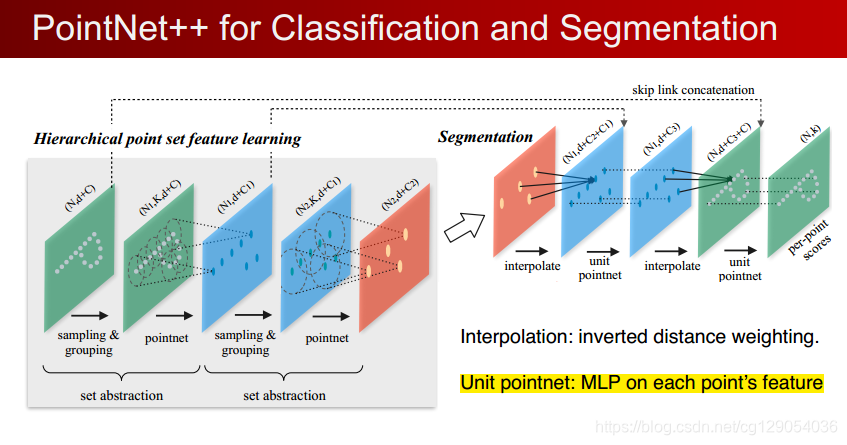
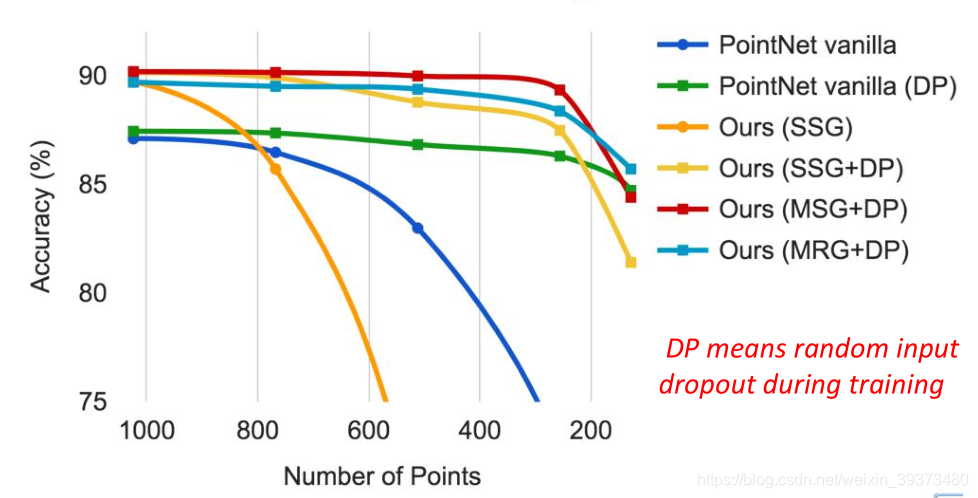
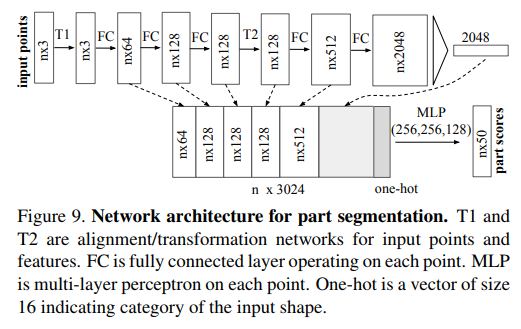
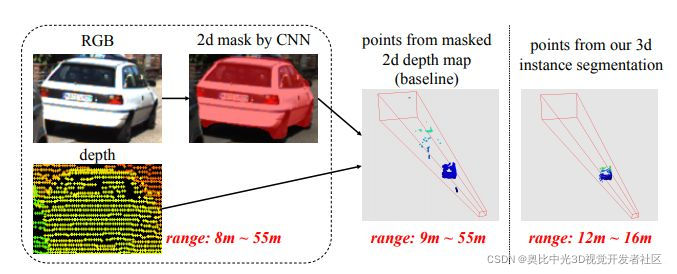
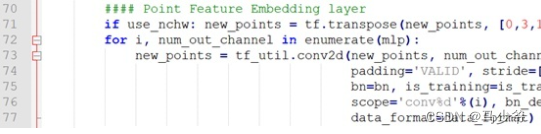
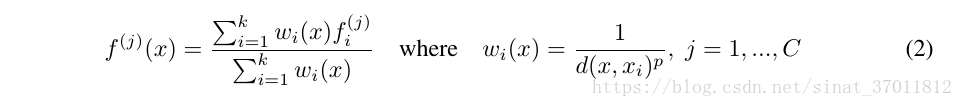想尽快入门点云,因此就从这个经典的点云处理神经网络开始。源码已经有了中文注释,但在一些对于自己不理解的地方添加了一些注释。欢迎大家一起讨论。
代码是来自github:GitHub - yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS.
PointNet系列代码复现详解(2)—PointNet++part_seg_葭月甘九的博客-CSDN博客
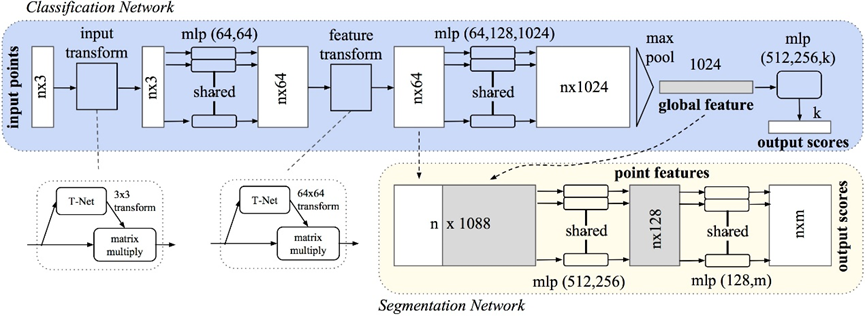
先学习的是分类部分代码
train_classification.py
下面代码就是获取当前文件所在的路径,赋值给BASE_DIR。ROOT_DIR被赋值为BASE_DIR,表示当前文件所在的目录为根目录。将models目录添加到根目录下,并使用sys.path.append()将该路径添加到Python解释器的搜索路径中,以便于在程序中导入models目录下的模块和类。
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))下面就是一些命令行参数,设置一些训练网络的基本参数
比如是否使用GPU,训练批次大小,模型,训练总轮数,以及优化器,训练日志保存路径等等。具体看代码后。
def parse_args():'''PARAMETERS'''parser = argparse.ArgumentParser('training')parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')parser.add_argument('--num_category', default=40, type=int, choices=[10, 40], help='training on ModelNet10/40')parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')parser.add_argument('--num_point', type=int, default=1024, help='Point Number')parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')parser.add_argument('--log_dir', type=str, default=None, help='experiment root')parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')return parser.parse_args()
--use_cpu:是否使用CPU模式。--gpu:指定GPU设备的编号。--batch_size:训练时的批大小。--model:指定使用的模型名称。--num_category:指定数据集的类别数,可选值为10和40。--epoch:训练的轮数。--learning_rate:学习率。--num_point:点云中的点数。--optimizer:优化器类型,默认为Adam。--log_dir:实验的根目录。--decay_rate:衰减率。--use_normals:是否使用法向量。--process_data:是否将数据离线保存。--use_uniform_sample:是否使用均匀采样策略
下面就是主函数里网络训练的设置
1.log_string(str)用于记录训练数据,然后是读取命令行参数,调用gpu
def log_string(str):logger.info(str)print(str)'''调用显卡 gpu'''os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu下面就是创建训练记录文件夹,记录训练过程的信息
'''CREATE DIR'''# 创建文件夹 记录信息timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M')) # 获取当前时间并转换为标准字符串(年-月-日-时-分)exp_dir = Path('./log/') # 使用 Path 类创建一个路径对象 exp_dir,指定日志文件存储的根目录为 './log/'exp_dir.mkdir(exist_ok=True) # 目录存在正常返回,不存在创建exp_dir = exp_dir.joinpath('classification') # 在 exp_dir 变量所代表的目录路径下创建一个名为 'classification' 的子目录exp_dir.mkdir(exist_ok=True)if args.log_dir is None:exp_dir = exp_dir.joinpath(timestr)else:exp_dir = exp_dir.joinpath(args.log_dir)exp_dir.mkdir(exist_ok=True)checkpoints_dir = exp_dir.joinpath('checkpoints/')checkpoints_dir.mkdir(exist_ok=True)log_dir = exp_dir.joinpath('logs/')log_dir.mkdir(exist_ok=True)'''LOG 日志记录'''args = parse_args()logger = logging.getLogger("Model") # 创建了一个名为 "Model" 的日志记录器 loggerlogger.setLevel(logging.INFO) # 设置了日志记录器 logger 的日志级别为 INFO,即只记录 INFO 级别及以上的日志信息。formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 日志格式化器 设置日志记录的格式。 时间-记录器名称-日志级别-内容file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model)) # 文件处理器,用于将日志信息写入到文件中file_handler.setLevel(logging.INFO)file_handler.setFormatter(formatter)logger.addHandler(file_handler)log_string('PARAMETER ...')log_string(args)数据读取
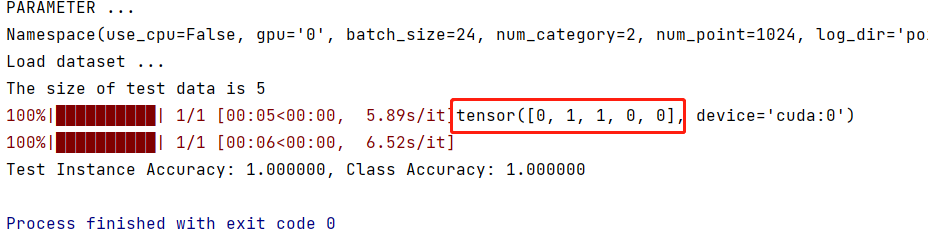
'''DATA LOADING'''log_string('Load dataset ...')data_path = 'data/modelnet40_normal_resampled/'train_dataset = ModelNetDataLoader(root=data_path, args=args, split='train', process_data=args.process_data)test_dataset = ModelNetDataLoader(root=data_path, args=args, split='test', process_data=args.process_data)# 分批训练数据 打乱输入的数据 开4线程 可丢弃一些数据trainDataLoader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True,num_workers=4, drop_last=True)# 分批测试数据 不打乱输入的数据 开4线程testDataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False,num_workers=4)下面代码就是把训练的模型复制到对应的目录下,以便以后查看和对比,然后就获取对应的分类模型以及损失函数,激活函数。
'''MODEL LOADING '''num_class = args.num_categorymodel = importlib.import_module(args.model)shutil.copy('./models/%s.py' % args.model, str(exp_dir))shutil.copy('models/pointnet2_utils.py', str(exp_dir))shutil.copy('./train_classification.py', str(exp_dir))# 定义了模型、损失函数和激活函数。classifier = model.get_model(num_class, normal_channel=args.use_normals)criterion = model.get_loss()classifier.apply(inplace_relu)使用gpu训练,并且查看是否有预训练模型。
# gpu训练if not args.use_cpu:classifier = classifier.cuda()criterion = criterion.cuda()try:checkpoint = torch.load(str(exp_dir) + '/checkpoints/best_model.pth')start_epoch = checkpoint['epoch']classifier.load_state_dict(checkpoint['model_state_dict']) # 将模型的参数设置为加载的状态字典log_string('Use pretrain model')except:log_string('No existing model, starting training from scratch...') # 无预训模型start_epoch = 0这里就是优化器选择,以及一些优化器参数的设置
# 优化器if args.optimizer == 'Adam':optimizer = torch.optim.Adam(classifier.parameters(),lr=args.learning_rate,betas=(0.9, 0.999),eps=1e-08,weight_decay=args.decay_rate)else:optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)# 调度器 防止陷入训练循环
# 将 optimizer 设置为之前定义的 Adam 优化器,step_size 设置为 20,gamma 设置为 0.7,表示每隔 20 个 epoch,将学习率乘以 0.7 进行调整。
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
global_epoch = 0
global_step = 0
best_instance_acc = 0.0
best_class_acc = 0.0下面就是主要训练网络片段 ,可以查看注释。上面一些基本工作准备完成后,开始训练。主要就是先记录一下训练轮次等基本信息,开启训练模式,更新学习率,然后开始一轮训练,优化器清零,然后数据增强,然后进行训练,一轮训练结束后会进行一次检测,最后检测结果与以前训练数据进行比较,保存最好的那个。
'''TRANING'''logger.info('Start training...')for epoch in range(start_epoch, args.epoch):log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))mean_correct = [] # 存储每个 batch 中预测正确的样本数classifier = classifier.train() # 训练模式# 更新当前的学习率。在每个 epoch 结束时,调用 scheduler.step() 方法,将当前 epoch 的信息传递给学习率调度器,从而更新当前的学习率。scheduler.step()# tqdm进度条for batch_id, (points, target) in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader),smoothing=0.9):# 优化器清零optimizer.zero_grad()# 数据增强points = points.data.numpy()points = provider.random_point_dropout(points) # 随机点丢失points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3]) # 随机缩放points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3]) # 随机偏移points = torch.Tensor(points) # 将 points 转换为 Tensorpoints = points.transpose(2, 1) # (24,1024,4)->(24,3,1024) 转置# 用于检查是否使用CPU模式,如果没有指定使用CPU模式,则将点云数据和目标值加载到GPU上进行训练。if not args.use_cpu:points, target = points.cuda(), target.cuda()pred, trans_feat = classifier(points)loss = criterion(pred, target.long(), trans_feat)pred_choice = pred.data.max(1)[1]# 准确率 可以使用sklearncorrect = pred_choice.eq(target.long().data).cpu().sum()mean_correct.append(correct.item() / float(points.size()[0]))loss.backward()optimizer.step()global_step += 1train_instance_acc = np.mean(mean_correct)log_string('Train Instance Accuracy: %f' % train_instance_acc)# 模式测试 classifier.eval()用于将模型设置为评估模式with torch.no_grad():instance_acc, class_acc = test(classifier.eval(), testDataLoader, num_class=num_class)# 保存训练参数 通用写法if (instance_acc >= best_instance_acc):best_instance_acc = instance_accbest_epoch = epoch + 1if (class_acc >= best_class_acc):best_class_acc = class_acclog_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))log_string('Best Instance Accuracy: %f, Class Accuracy: %f' % (best_instance_acc, best_class_acc))if (instance_acc >= best_instance_acc):logger.info('Save model...')savepath = str(checkpoints_dir) + '/best_model.pth'log_string('Saving at %s' % savepath)state = {'epoch': best_epoch,'instance_acc': instance_acc,'class_acc': class_acc,'model_state_dict': classifier.state_dict(),'optimizer_state_dict': optimizer.state_dict(),}torch.save(state, savepath)global_epoch += 1然后这是测试部分,部分代码解释见后面:
def test(model, loader, num_class=40):mean_correct = []class_acc = np.zeros((num_class, 3))classifier = model.eval() # 模型设置为评估模式for j, (points, target) in tqdm(enumerate(loader), total=len(loader)):if not args.use_cpu:points, target = points.cuda(), target.cuda()points = points.transpose(2, 1) # 将点云数据的坐标轴从(x,y,z)转换为(x,z,y)的顺序,这是因为在点云数据处理中,通常将y轴作为垂直方向pred, _ = classifier(points)pred_choice = pred.data.max(1)[1]for cat in np.unique(target.cpu()):classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])class_acc[cat, 1] += 1correct = pred_choice.eq(target.long().data).cpu().sum()mean_correct.append(correct.item() / float(points.size()[0]))class_acc[:, 2] = class_acc[:, 0] / class_acc[:, 1]class_acc = np.mean(class_acc[:, 2])instance_acc = np.mean(mean_correct)return instance_acc, class_acc代码首先使用np.unique()方法获取目标值中的不同类别。代码先通过target == cat选出该类别对应的样本,然后使用pred_choice[target == cat]获取分类器在该类别上的预测结果,target[target == cat].long().data获取该类别中所有样本的目标值,并使用eq()方法比较分类器的预测结果和目标值是否相等。接着,使用cpu().sum()方法计算分类正确的样本数,再除以该类别中的总样本数,即可得到分类器在该类别上的准确率。最后,将该类别的准确率和样本数量保存到class_acc数组中。其中,class_acc是一个二维数组,其形状为(num_class, 2),表示每个类别的准确率和样本数量。第一列表示每个类别的准确率,第二列表示每个类别中的总样本数。
for cat in np.unique(target.cpu()):classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])class_acc[cat, 1] += 1unqiue()示例:
arr = np.array([1, 2, 3, 2, 4, 5, 4, 6])
unique_arr = np.unique(arr)
print(unique_arr)结果:[1 2 3 4 5 6]pointnet_cls.py
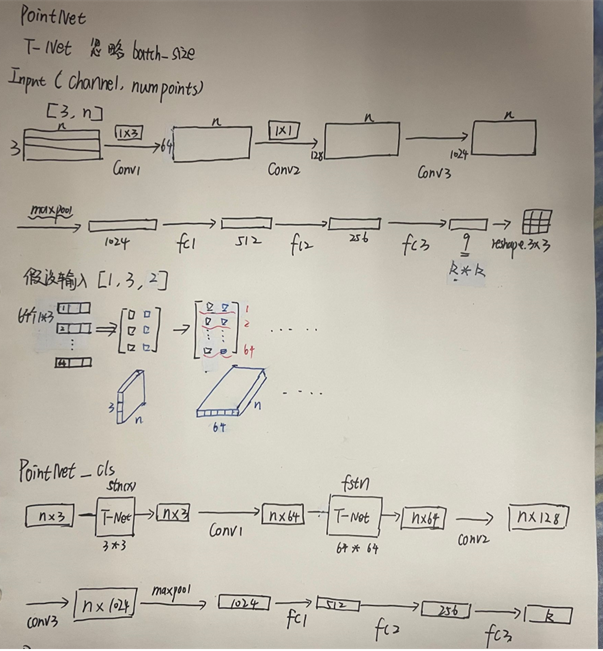
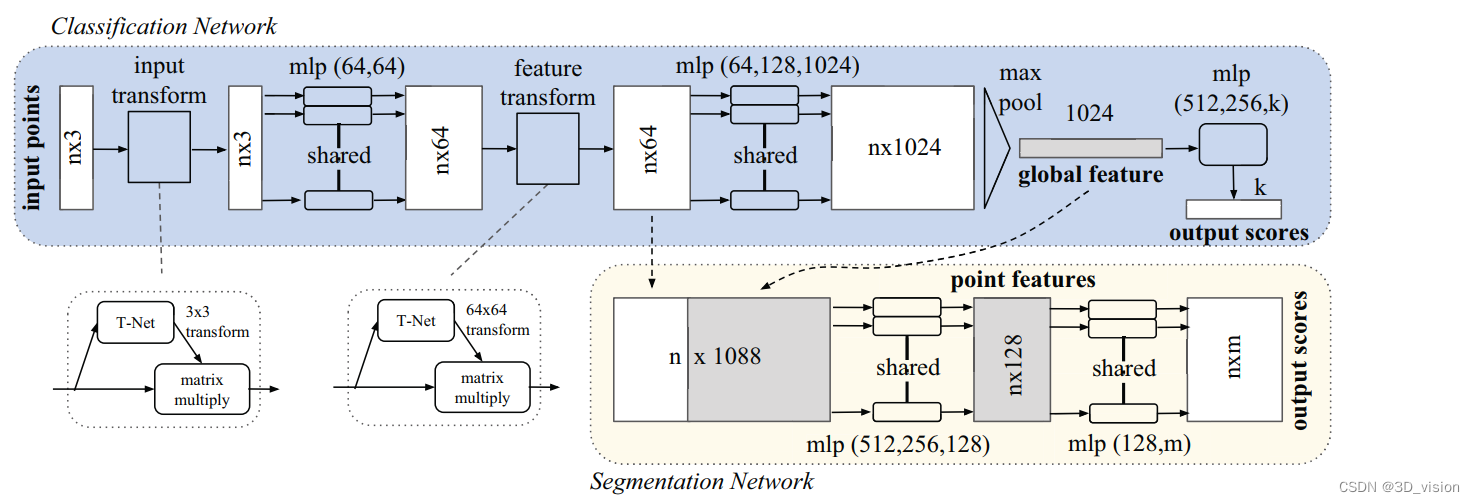
下面就是分类的整个网络,第一个if判断用于根据是否包含法向量信息来确定输入数据的通道数。具体而言,如果normal_channel为True,则输入数据包含法向量信息,通道数为6;否则,输入数据不包含法向量信息,通道数为3。之后就是一些基本网络组成块。在前向传播中,首先先进行从输入点云数据中提取特征,其中通过global_feat=True指定输出全局特征,即对输入点云数据进行全局特征池化;通过feature_transform=True指定使用特征变换模块,即对提取出的特征进行空间变换,增强模型的鲁棒性;通过channel=channel指定输入数据的通道数,即根据输入数据是否包含法向量信息来确定通道数。获取到特征后就是全连接层,最后输出的是类别。
class get_model(nn.Module):def __init__(self, k=40, normal_channel=True):super(get_model, self).__init__()if normal_channel:channel = 6else:channel = 3self.feat = PointNetEncoder(global_feat=True, feature_transform=True, channel=channel)self.fc1 = nn.Linear(1024, 512)self.fc2 = nn.Linear(512, 256)self.fc3 = nn.Linear(256, k)self.dropout = nn.Dropout(p=0.4)self.bn1 = nn.BatchNorm1d(512)self.bn2 = nn.BatchNorm1d(256)self.relu = nn.ReLU()def forward(self, x):x, trans, trans_feat = self.feat(x)x = F.relu(self.bn1(self.fc1(x)))x = F.relu(self.bn2(self.dropout(self.fc2(x))))x = self.fc3(x)x = F.log_softmax(x, dim=1)return x, trans_feat损失函数 交叉熵损失+正交化规范处理的损失
class get_loss(torch.nn.Module):def __init__(self, mat_diff_loss_scale=0.001):super(get_loss, self).__init__()self.mat_diff_loss_scale = mat_diff_loss_scaledef forward(self, pred, target, trans_feat):loss = F.nll_loss(pred, target)mat_diff_loss = feature_transform_reguliarzer(trans_feat)total_loss = loss + mat_diff_loss * self.mat_diff_loss_scalereturn total_losspointnet_utils.py
下面就是特征提取的代码
class PointNetEncoder(nn.Module):def __init__(self, global_feat=True, feature_transform=False, channel=3):super(PointNetEncoder, self).__init__()self.stn = STN3d(channel)self.conv1 = torch.nn.Conv1d(channel, 64, 1)self.conv2 = torch.nn.Conv1d(64, 128, 1)self.conv3 = torch.nn.Conv1d(128, 1024, 1)self.bn1 = nn.BatchNorm1d(64)self.bn2 = nn.BatchNorm1d(128)self.bn3 = nn.BatchNorm1d(1024)self.global_feat = global_featself.feature_transform = feature_transformif self.feature_transform:self.fstn = STNkd(k=64)def forward(self, x):B, D, N = x.size()trans = self.stn(x)x = x.transpose(2, 1) # 交换2,3维# 判断D的大小是因为在使用空间变换网络(STN)对输入图像进行变换时,只需要对图像的空间维度进行变换,而不需要对通道维度进行变换。# 因此,如果输入图像的通道数大于3,则需要将通道数超过3的部分分离出来,并在变换后再次拼接回去,以保持通道数不变。# 因此,如果输入图像的通道数小于等于3,则不需要进行通道数的分离和拼接操作,否则需要进行相应的操作,以保证空间变换网络的正确性。if D > 3:feature = x[:, :, 3:]x = x[:, :, :3]x = torch.bmm(x, trans)if D > 3:x = torch.cat([x, feature], dim=2)x = x.transpose(2, 1)x = F.relu(self.bn1(self.conv1(x)))if self.feature_transform:trans_feat = self.fstn(x)x = x.transpose(2, 1)x = torch.bmm(x, trans_feat)x = x.transpose(2, 1)else:trans_feat = Nonepointfeat = xx = F.relu(self.bn2(self.conv2(x)))x = self.bn3(self.conv3(x))x = torch.max(x, 2, keepdim=True)[0]x = x.view(-1, 1024)if self.global_feat:return x, trans, trans_featelse:x = x.view(-1, 1024, 1).repeat(1, 1, N)return torch.cat([x, pointfeat], 1), trans, trans_feat下面就是特征提取当中第一个T-Net网络,第二天T-Net网络大同小异,只是改变了输入和输出。
class STN3d(nn.Module):def __init__(self, channel):super(STN3d, self).__init__()self.conv1 = torch.nn.Conv1d(channel, 64, 1)self.conv2 = torch.nn.Conv1d(64, 128, 1)self.conv3 = torch.nn.Conv1d(128, 1024, 1)self.fc1 = nn.Linear(1024, 512)self.fc2 = nn.Linear(512, 256)self.fc3 = nn.Linear(256, 9)self.relu = nn.ReLU()self.bn1 = nn.BatchNorm1d(64)self.bn2 = nn.BatchNorm1d(128)self.bn3 = nn.BatchNorm1d(1024)self.bn4 = nn.BatchNorm1d(512)self.bn5 = nn.BatchNorm1d(256)def forward(self, x):batchsize = x.size()[0]x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))x = torch.max(x, 2, keepdim=True)[0]x = x.view(-1, 1024)x = F.relu(self.bn4(self.fc1(x)))x = F.relu(self.bn5(self.fc2(x)))x = self.fc3(x)iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(batchsize, 1)if x.is_cuda:iden = iden.cuda()x = x + idenx = x.view(-1, 3, 3)return xtest_classification.py 这个测试文件里的就是加载刚刚训练的最好模型,与训练的代码大同小异,就没有看,如果有时间看了再更新吧。
下面是分类网络鉴于个人理解画的图,如有错误,欢迎指正。