文章目录
- 在test_refine_w_mask_two_path.py上加载playingviolin数据集的结果
- 输入参数的调整
- 修改地址
- 在test_refine上复现
- 修改:
- 使用list文件生成工具产生测试帧目录
- class UCF101
- 跑test_refine.py
在test_refine_w_mask_two_path.py上加载playingviolin数据集的结果

参数不匹配,应该是预训练模型没有使用区分前景和背景的语义分割图,即下面这个结构没有被使用。
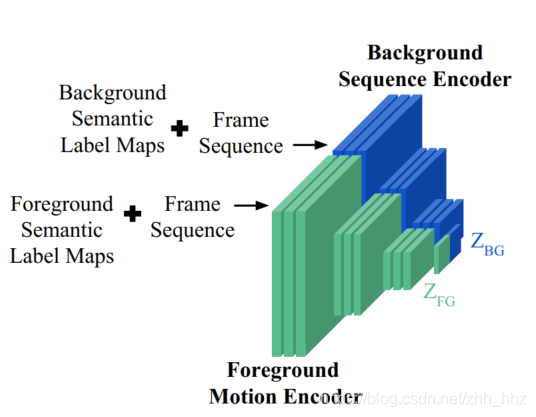
看来作者应该只是在cityscapes数据集上进行了消融实验,要跑ucf 101的数据集应该在test_refine_w_mask.py上进行。
输入参数的调整
本节使用pythontest_refine_w_mask.py进行测试
num_frames = 15
num_predicted_frames = 14
input_channel = 1
mask_channel = 2上面参数会影响:
self.motion_net = motion_net(opt, int(opt.num_frames*opt.input_channel)+20, 1024)
self.zconv = convbase(256 + 64, 16*self.opt.num_predicted_frames, 3, 1, 1)
self.refine_net = RefineNet(num_channels=opt.input_channel)更改参数后的报错信息:
RuntimeError: Error(s) in loading state_dict for VAE:size mismatch for motion_net.main.0.weight: copying a param of torch.Size([32, 35, 4, 4]) from checkpoint, where the shape is torch.Size([32, 15, 4, 4]) in current model.size mismatch for zconv.main.0.weight: copying a param of torch.Size([224, 320, 3, 3]) from checkpoint, where the shape is torch.Size([64, 320, 3, 3]) in current model.size mismatch for zconv.main.0.bias: copying a param of torch.Size([224]) from checkpoint, where the shape is torch.Size([64]) in current model.size mismatch for refine_net.image_encoder.c1.0.main.0.weight: copying a param of torch.Size([64, 1, 3, 3]) from checkpoint, where the shape is torch.Size([64, 3, 3, 3]) in current model.size mismatch for refine_net.image_decoder.upc6.1.weight: copying a param of torch.Size([64, 1, 3, 3]) from checkpoint, where the shape is torch.Size([64, 3, 3, 3]) in current model.size mismatch for refine_net.image_decoder.upc6.1.bias: copying a param of torch.Size([1]) from checkpoint, where the shape is torch.Size([3]) in current model.
计算得出结论:
num_frames = 5
num_predicted_frames = 4
input_channel = 3
mask_channel = 20 #这个不确定,先定为初始值20注解:
checkpoint指的是程序中的检查点,current model 指的是预训练模型
新的报错信息:
RuntimeError: Error(s) in loading state_dict for VAE:size mismatch for motion_net.main.0.weight: copying a param of torch.Size([32, 35, 4, 4]) from checkpoint, where the shape is torch.Size([32, 15, 4, 4]) in current model.size mismatch for encoder.econv1.main.0.weight: copying a param of torch.Size([32, 23, 4, 4]) from checkpoint, where the shape is torch.Size([32, 3, 4, 4]) in current model.
源码定义:
self.motion_net = motion_net(opt, int(opt.num_frames*opt.input_channel)+20, 1024) # line 200
self.econv1 = convbase(opt.input_channel + opt.mask_channel, 32, 4, 2, 1) # 32,64,64结论:
mask_channel = 0
# self.motion_net改为如下(删去+20)
self.motion_net = motion_net(opt, int(opt.num_frames*opt.input_channel), 1024)注解:mask_channel = 0 的话,貌似使用不带segment mask的测试文件test_refine.py比较好?这个作为下一步计划,目前先试试能不能跑通test_refine_w_mask.py
修改地址
新的报错:
ValueError: Traceback (most recent call last):File "/home/zhouhh/anaconda3/envs/python35/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 106, in _worker_loopsamples = collate_fn([dataset[i] for i in batch_indices])File "/home/zhouhh/anaconda3/envs/python35/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 106, in <listcomp>samples = collate_fn([dataset[i] for i in batch_indices])File "/home/zhouhh/seg2vid/src/datasets/cityscapes_dataset_w_mask_two_path.py", line 74, in __getitem__sample = imagetoframe(image_dir, self.size, self.num_frame)File "/home/zhouhh/seg2vid/src/datasets/cityscapes_dataset_w_mask_two_path.py", line 47, in imagetoframesamples = [replace_index_and_read(image_dir, indx, size) for indx in range(num_frame)]File "/home/zhouhh/seg2vid/src/datasets/cityscapes_dataset_w_mask_two_path.py", line 47, in <listcomp>samples = [replace_index_and_read(image_dir, indx, size) for indx in range(num_frame)]File "/home/zhouhh/seg2vid/src/datasets/cityscapes_dataset_w_mask_two_path.py", line 21, in replace_index_and_readnew_dir = image_dir[0:-22] + str(int(image_dir[-22:-16]) + indx).zfill(6) + image_dir[-16::]
ValueError: invalid literal for int() with base 10: '1_c01/'
分析:
地址不对,new_dir是按照cityscapes数据集的文件名字来定的
修改:
# 首先修改opts.py
parser.add_argument('--dataset',default='ucf101',# default='cityscapes_two_path',type=str,help='Used dataset (cityscpes | cityscapes_two_path | kth | ucf101).'
)
报错:
FileNotFoundError: Traceback (most recent call last):File "/home/zhouhh/anaconda3/envs/python35/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 106, in _worker_loopsamples = collate_fn([dataset[i] for i in batch_indices])File "/home/zhouhh/anaconda3/envs/python35/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 106, in <listcomp>samples = collate_fn([dataset[i] for i in batch_indices])File "/home/zhouhh/seg2vid/src/datasets/ucf_dataset.py", line 34, in __getitem__item = np.load(os.path.join(self.datapath, self.datalist[idx].split(' ')[0]).strip())File "/home/zhouhh/anaconda3/envs/python35/lib/python3.5/site-packages/numpy/lib/npyio.py", line 384, in loadfid = open(file, "rb")
FileNotFoundError: [Errno 2] No such file or directory: '/home/zhouhh/pytorch-deeplab-xception/frames/v_PlayingViolin_g01_c01/frame0000000.jpg'
修改:
playingviolin.txt文件中frame后面多写了一个0
新报错:
np.load无法加载.jpg文件
分析:
可能是使用test_refine_w_mask.py这个文件测试的时候,使用的数据不是用的.jpg格式的,要使np.load可以读取的话,应是.npz。这里作者也没有特别说明,暂且搁下吧。且结合之前的推论预训练模型中对应mask_channel为0,显然是不使用segment_mask的,用test_refine_w_mask.py这个文件测试无法得到正确的结果。
结论:
想在ucf-101数据集上得到使用mask情况下的预测结果,必须重新训练。
在test_refine上复现
不使用mask。
修改:
opt.py:
--dataset ucf101dataset.py get_test_set():
# line 74
datalist=os.path.join(UCF_101_DATA_LIST, 'test_%s.txt' % (opt.category.lower()))使用list文件生成工具产生测试帧目录
utils.ucf101_gen_list.py:
# line 13
listfile = open("../file_list/test_playingviolin.txt", 'a')注:视频转帧由项目pytorch-deeplab-xception的video2frame.py实现:
import numpy as np
import cv2
import torch
from torch.autograd import Variablefrom os.path import join
from glob import globimport torch
from torchvision import transforms, models
from PIL import Image
import os.pathimport multiprocessing
multiprocessing.set_start_method('spawn', True)'''
Func name: video2frame
Description: clip video to frames with setted interval
Author: Wei Wei, zhouhongh
Input param: video_src_path: 视频存放路径frame_save_path: 保存路径frame_width: 保存帧宽frame_height: 保存帧高interval: 保存帧间隔
Time: 2019.9
'''
def video2frame(video_src_path, frame_save_path, frame_width, frame_height, interval):videos = os.listdir(video_src_path)formats = [".mp4", ".avi"]def filter_format(x, all_formats):if x[-4:] in all_formats:return Trueelse:return Falsevideos = filter(lambda x: filter_format(x, formats), videos)for each_video in videos:print ("正在读取视频:", each_video)each_video_name = each_video[:-4]each_video_save_full_path = os.path.join(frame_save_path, each_video_name)if not os.path.exists(each_video_save_full_path):os.makedirs(each_video_save_full_path)each_video_full_path = os.path.join(video_src_path, each_video)cap = cv2.VideoCapture(each_video_full_path)frame_index = 0frame_count = 0if not cap.isOpened():print("读取视频失败!")while(1):success, frame = cap.read()if not success:print("---> 已保存%d帧至%s." % (frame_count, each_video_save_full_path))breakif frame_index % interval == 0:resize_frame = cv2.resize(frame, (frame_width, frame_height), interpolation=cv2.INTER_AREA)cv2.imwrite(each_video_save_full_path + "/" + each_video_name +"_" + ("%d.jpg" % frame_count).zfill(10), resize_frame)frame_count += 1frame_index += 1cap.release()video2frame("/home/zhouhh/DATAshare/UCF-101/PlayingViolin/", "/home/zhouhh/DATAshare/UCF-101/PlayingViolin/", 128, 128, 2)class UCF101
理解
作者对于ucf101数据集使用了和cityscapes不同的处理策略。
cityscapes的.txt中存放的是视频帧的文件名。而ucf101的.txt中存放的应该是一个个的.npy文件名,每个.npy代表一个视频,.npy文件里面是一个个数组,用空格隔开,每个数组代表一帧的数据。这里没找到作者将.avi处理为.npy的程序,因此按照cityscapes数据集下加载数据的方式,迁移到ucf101中使用,使得仍然可以在ucf101数据集上使用直接读取图片的方式加载数据。
更改
datasets.ucf_datasets中定义了加载ucf101数据的类,名为UCF101,在dataset.get_test_set函数中被调用。
调用时赋值如下:
# UCF_101_DATA_PATH = '/home/zhouhh/DATAshare/UCF-101/PlayingViolin/'
# UCF_101_DATA_LIST = '/home/zhouhh/seg2vid/src/file_list'
test_Dataset = UCF101(datapath=UCF_101_DATA_PATH,datalist=os.path.join(UCF_101_DATA_LIST, 'test_%s.txt' % (opt.category.lower())),returnpath=True)将 cityscapes_dataset_w_mssk.py的__getitem__及其用到的函数复制到ucf_dataset.py中。
更改replace_index_and_read的new_dir
new_dir = image_dir[0:-10] + str(int(image_dir[-10:-4]) + indx).zfill(6) + image_dir[-4::]
更改complete_full_list的dir_list
dir_list = [image_dir[0:-10] + str(int(image_dir[-10:-4]) + i).zfill(6) + '_' + output_name for i inrange(num_frames)]更改__getitem__使得其不返回mask
if self.returnPath:return sample, complete_full_list(self.datalist[idx].strip(), self.num_frame, 'pred.jpg')
else:return sample使用如下代码进行测试:
if __name__ == '__main__':start_time = time.time()# v_IceDancing_g06_c01.npyUCF_101_DATA_PATH = '/home/zhouhh/DATAshare/UCF-101/PlayingViolin/'UCF_101_DATA_LIST = '/home/zhouhh/seg2vid/src/file_list'# train_Dataset = UCF101(datapath=os.path.join(Path, 'IceDancing'),# datalist=os.path.join(Path, 'list/trainicedancing.txt'))test_Dataset = UCF101(datapath=UCF_101_DATA_PATH,datalist=os.path.join(UCF_101_DATA_LIST, 'test_playingviolin.txt'), returnpath=True)dataloader = DataLoader(test_Dataset, batch_size=32, shuffle=True, num_workers=8)sample= iter(dataloader).next()print(sample.shape)根据提示更改一些变量名,将size改成和cityscapes一样的数组形式即可。
跑test_refine.py
问题:RuntimeError: CUDA error: out of memory
解决:减少batch_size ,在opts.py中将其设置为4
问题:保存的路径不存在
解决:在test_refine.py中改写 make_save_dir函数
def make_save_dir(output_image_dir):val_video = 'v_PlayingViolin_g01_c01'pathOutputImages = os.path.join(output_image_dir, val_video)if not os.path.isdir(pathOutputImages):os.makedirs(pathOutputImages)然后删除原来生成的ucf101_results文件夹