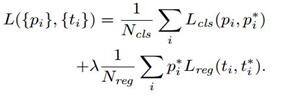参考http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
这是我看过的讲faster rcnn最好的一篇博客了,花了一下午时间看得差不多了,不过他也有些小细节没讲,我这里总结补充一下
另外还有一文读懂Faster RCNN - 白裳的文章 - 知乎
https://zhuanlan.zhihu.com/p/31426458
本文中的图片均来自这两篇博客
先说明anchor是怎么回事:
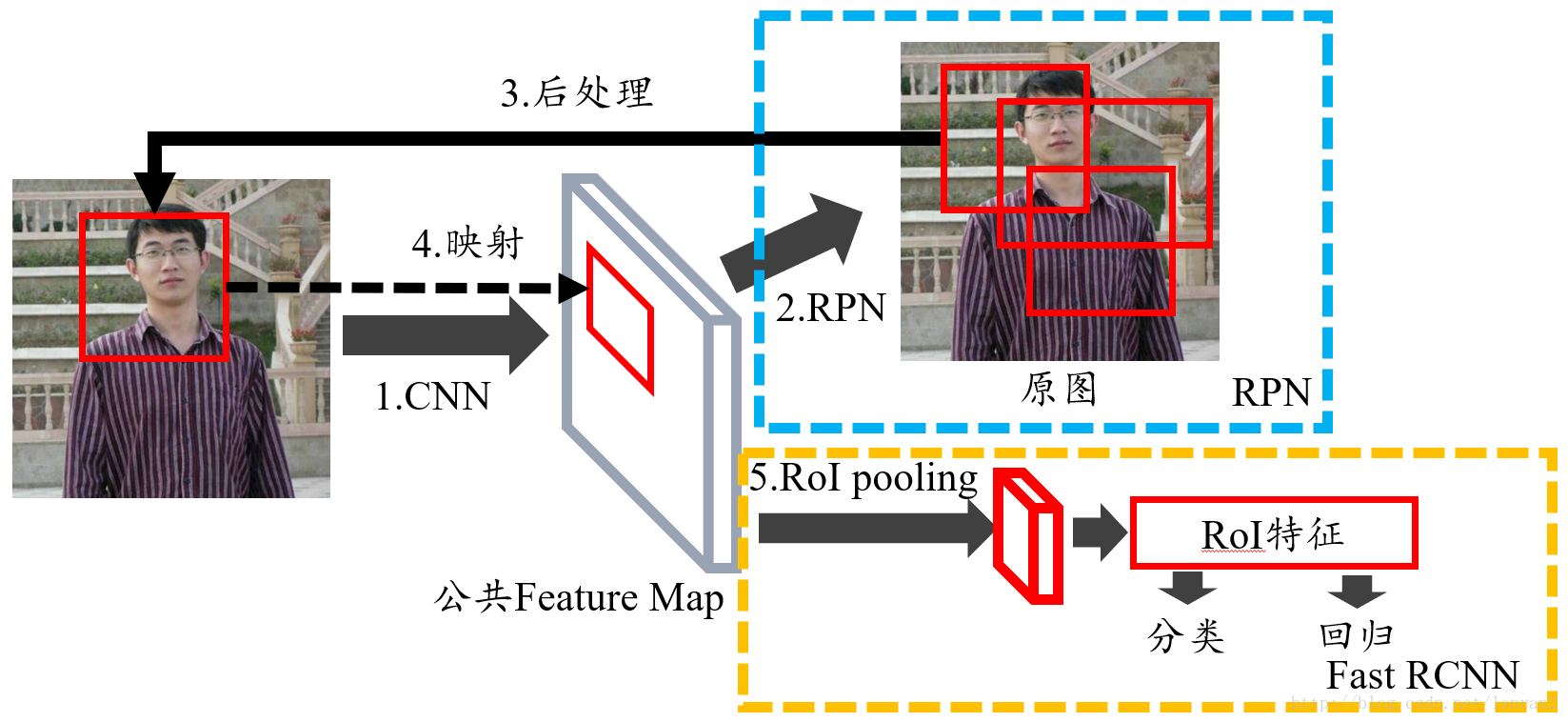
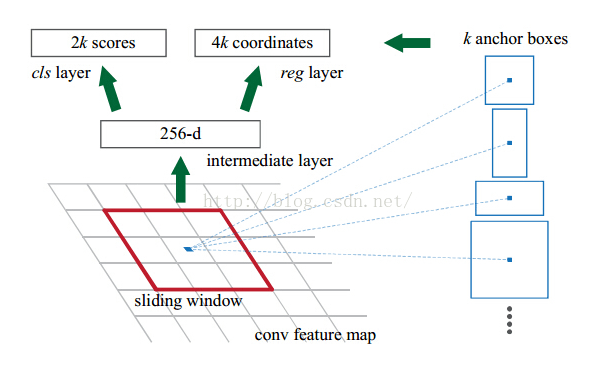
经过backbone后,在提取的特征图feature map上,每个点对应9个anchor,假设feature map是(w/16,h/16,Channel_num)的大小那么就有w/16*h/16个点,对应w/16*h/16*9个anchor,而feature map上的一个点可以映射到原图上的一个点(存疑,是对应的kernel卷积时的中心点?),anchor也就映射到原图上的一块区域。
放上两张图
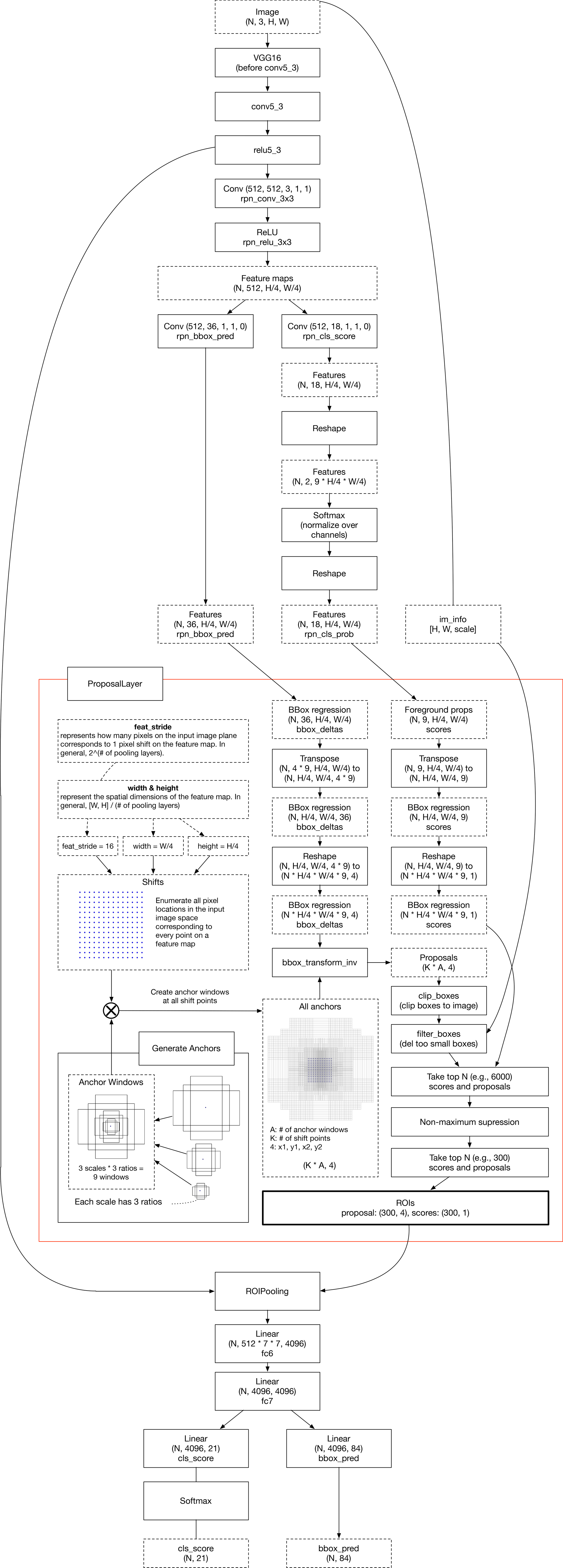
faster r-cnn的整体结构
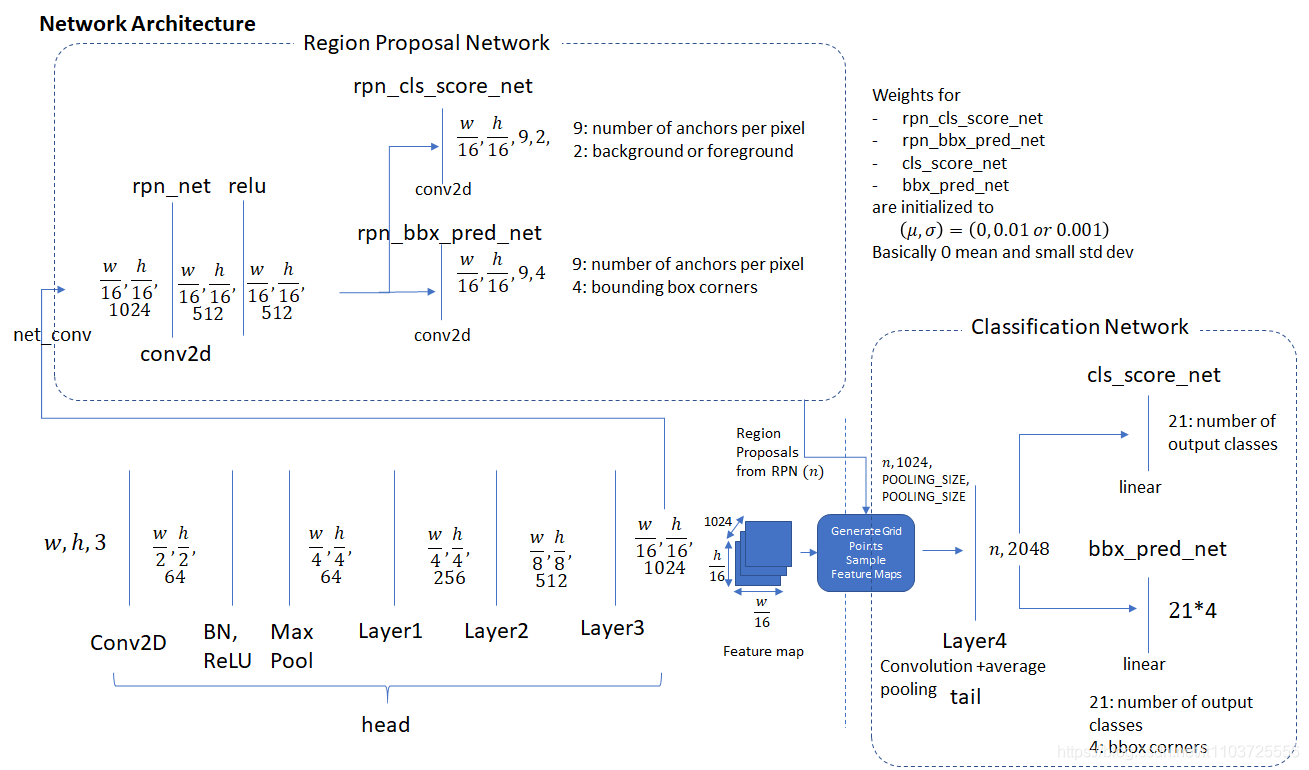
RPN的结构
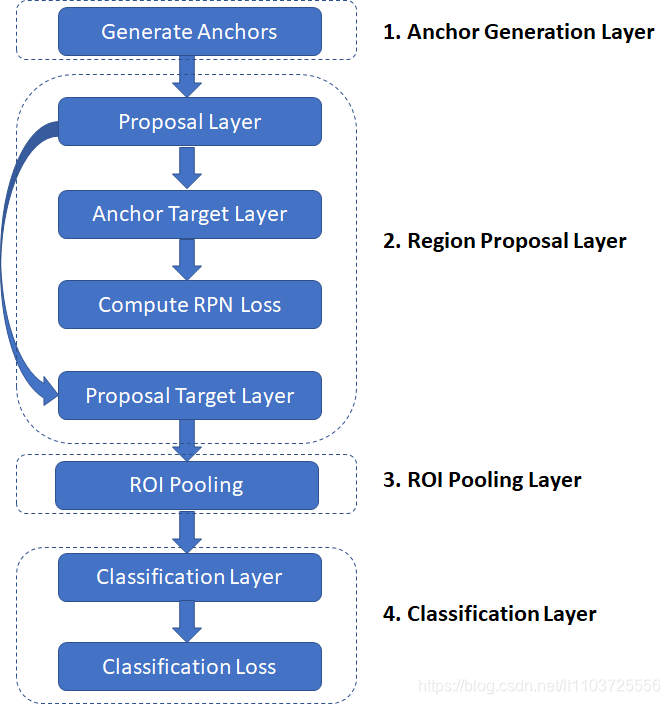
这个图跟论文里的图不太一样,不过本质应该是一样的,这里只是按照实现的时候分的模块来命名的
主要讲RPN的实现过程,分模块讲
RPN
按照博客里的说法,RPN只是图2的“Proposal Layer”的一半
训练时以上层都会用到,测试时Anchor Target Layer和Compute RPN Loss全都用不到
(1)backbone网络提取特征作为head

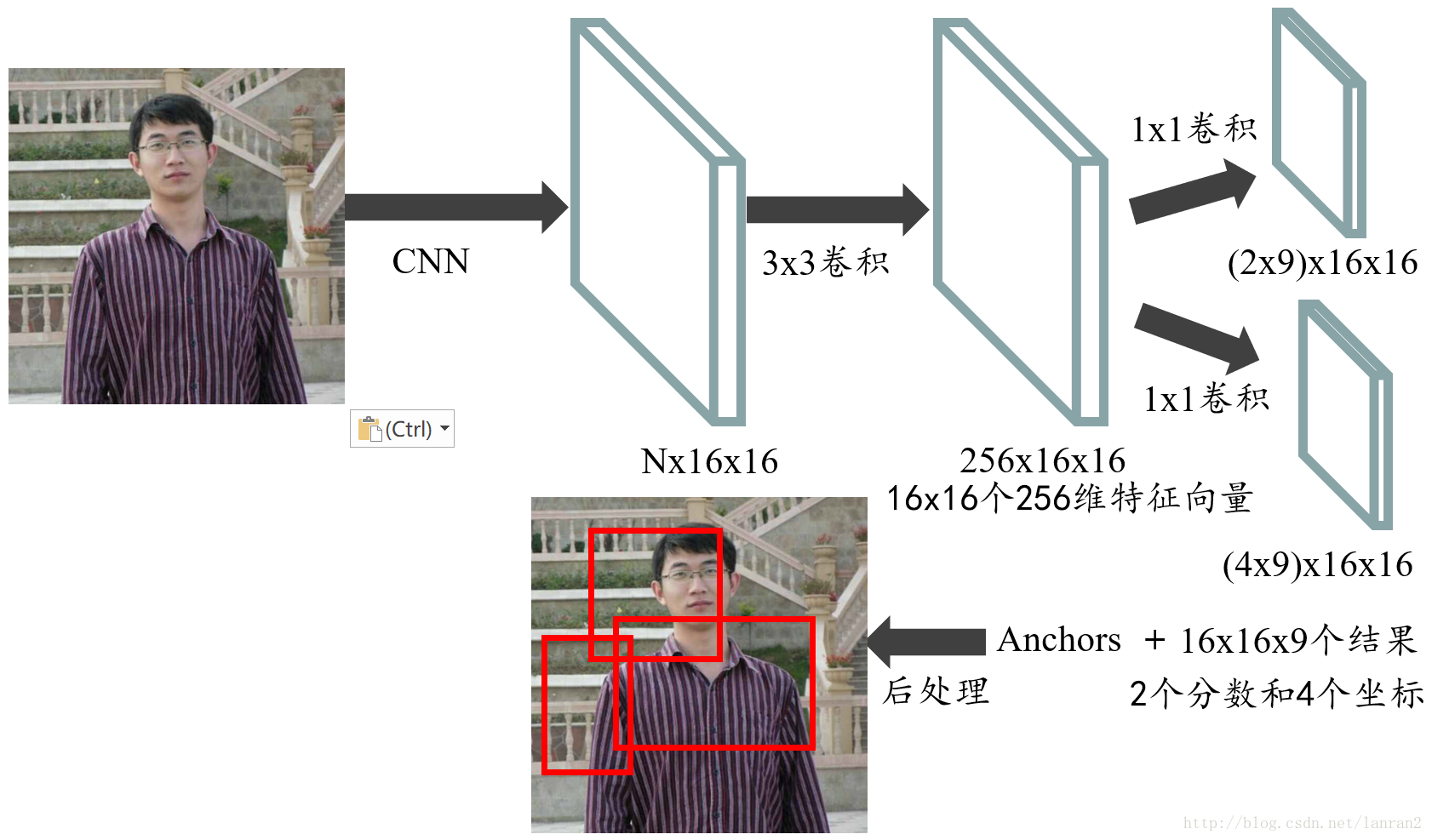
原图shape=(w,h,3),经过backbone后变成了(w/16,h/16,1024)
(2)rpn
backbone提取出的feature map再经过3*3的卷积后再做处理,有两种图,第一种提示了每个操作后feature map的维度,第二个图比较简明
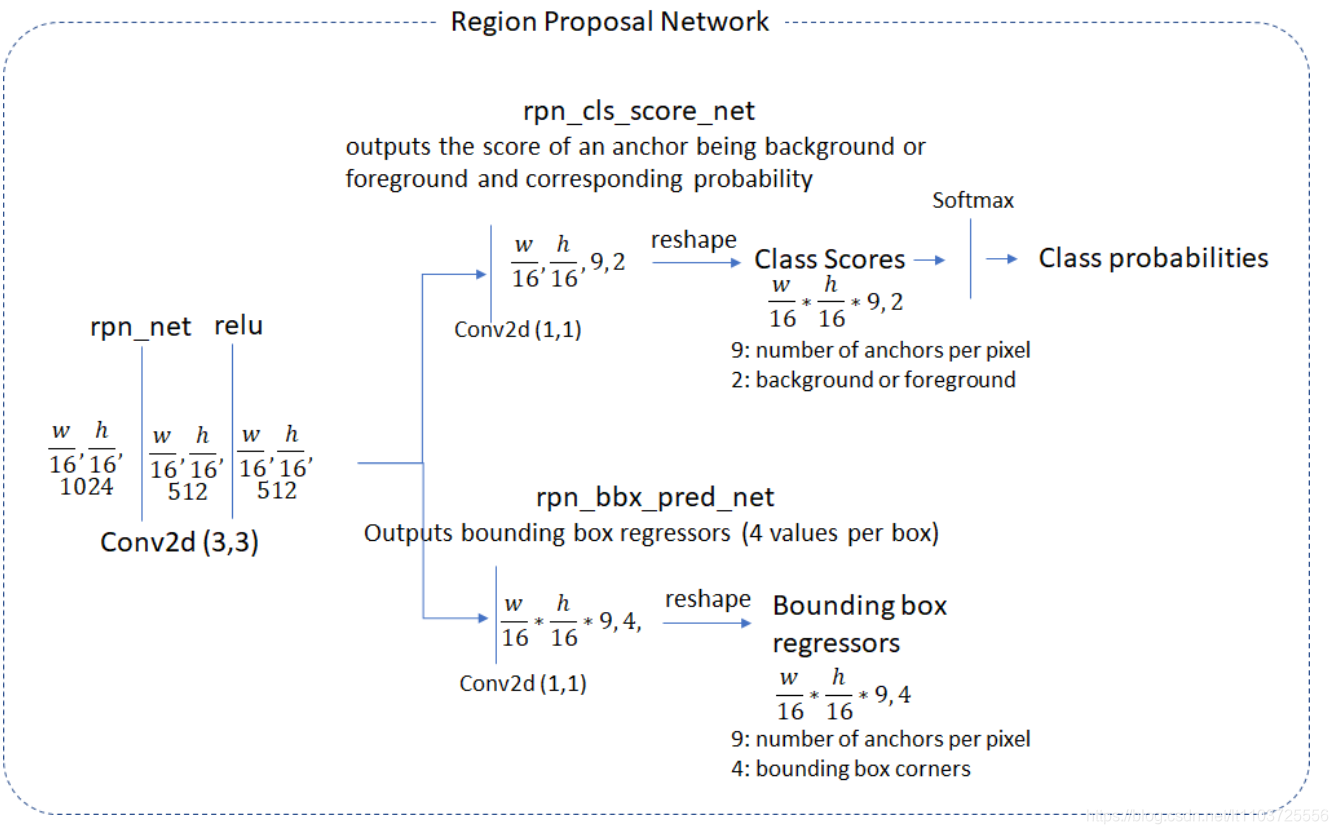

主要看第一张图,其实RPN就只是对特征图分两条线做卷积
分类
(1)feature map经过1*1的卷积,大小不变,channel变为18=》(w/16,h/16,18)
(2)然后做reshape,将3维的feature map拉到2维=》把前两个维度拉直,即18层特征图,每层先拉成一个向量,变成(w/16*h/16,18),变成了一个2维矩阵,再把前9行连接在一起,后9行连接在一起,变成(2,w/16*h/16*9)的矩阵(两个轴的顺序不重要,我这里取2行的矩阵)
至此,已经得到了每个anchor的前、背景分数:
feature map有w/16*h/16个像素点,每个像素点对应9个anchor,每个anchor有两个分数(前/背景)
具体reshape是不是这么实现的有待考证,目前先这么认为
(3)2维矩阵做softmax,即每列单独套softmax公式,使得第一行为前景概率,第二行为背景概率
具体哪一行是前景概率有待考证
回归
feature map做1*1的卷积,大小不变,channel变为36,再reshape到(w/16*h/16*9,4),4为边框回归的四个偏移系数,另一轴乘起来正好是anchor个数
经过以上两条线,即得到图1最右边的两个结果:每个anchor的前景/背景概率与四个边框回归系数
note:为什么会有两个分数?一个前景一个背景,而背景分数其实一直没用到?
前/背景分数是由softmax得到的,而softmax至少得有两类才能计算分数
本来到这里rpn就结束了,测试的时候把做nms与anchor矫正的 “(3)Proposal Layer后半部” 的结果交给后面的网络就行了,但是训练的时候需要把rpn训练好,使得rpn能正确地对所有anchor进行分类和回归,所以才需要后面的 进一步选出合适的正/负例去算Loss的“Anchor Target Layer”和用于监督的“Compute RPN Loss”
(3)Proposal Layer的后半部分
接收PRN的两个output
(1)对所有anchor根据RPN算出来的回归系数进行矫正
(2)对所有anchor根据前景得分排序
(3)对矫正后的anchor,根据前景得分排序的结果,选前PRE_NMS_TOP_N(超参)个anchor做NMS
(4)将结果送入下一层
(4)Anchor Target Layer
根据(3)的结果,进一步筛选,选出一定数量的正/负例去计算Loss
正例的要求:
1、对于所有gt,选一个和它overlap最大的(为了防止有的gt没有超过阈值的anchor)
2、选和任意gt的overlap超过阈值的(文中为0.7)
负例:
和所有gt的overlap小于另一阈值的,文中为0.3
另外还有两个阈值用于控制正/负例数量
超过阈值的部分随机丢弃
(5)Compute RPN Loss
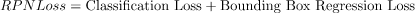
分类Loss为交叉熵Loss,边框回归Loss为L1_smooth Loss,这两种Loss后面单独再说
计算出Loss后,即可反向传播,去监督RPN,使得rpn能正确地对所有anchor进行分类和回归
细节部分
(1)9种尺寸的anchor是如何与RPN得到的(w/16*h/16*9,2k or 4k)对应的?
以下为我的猜想:
这个映射关系是自定义的,“自然形成的”。定了ratio和scale,按照固定的计算方式,那么每种比例的anchor的存储顺序都是固定的,1*1*18卷积后reshape到(1*1*9,2),这里的9就对应9种anchor,由于这些计算过程一直都不变的,这样就可以自然与9种固定顺序的anchor一一对应,通过loss反向传播让它自己去学习每种尺寸的anchor需要的参数就行了
(2)什么时候用全部的2W个anchor,什么时候用Anchor Target Layer得到的256个anchor?
注:为方便讨论,这里用的数字均为论文中的具体值
答:
在RPN开始的时候就用的是全部的2W个anchor,无论训练还是测试
后面经过筛选,Anchor Target Layer筛选出128个正anchorh和128个负anchor,只是为了去计算anchor loss,因为这256个anchor就是RPN网络认为的“置信度较高的正anchor和负anchor”,用这些anchor去监督,反向传播,就能达成使rpn学会正确鉴别与矫正anchor的目的
补充一下anchor的ratio,scale是什么意思
ratio就是anchor的长宽比
而scale是指缩放的尺度(倍数):
eg.首先设定一个base anchor比如(16,16),这样根据ratio改变其长宽比则能得到3个anchor,然后根据scale将这3个anchor分别缩放三次,就能得到9个不同的anchor