本专栏包含信息论与编码的核心知识,按知识点组织,可作为教学或学习的参考。markdown版本已归档至【Github仓库:information-theory】,需要的朋友们自取。或者公众号【AIShareLab】回复 信息论 也可获取。
文章目录
- 霍夫曼编码
- 最佳变长编码
- 霍夫曼编码
- 霍夫曼编码的步骤
- 例 单符号离散无记忆信源
- L-Z编码
- 总结
霍夫曼编码
最佳变长编码
- 最佳码: 对于某一信源和某一码符号集来说,若有一唯一可译码,其平均码长小于所有其他唯一可译码的平均长度。
- 紧致码
- 香农(Shannon)
- 费诺(Fano)
- 霍夫曼(Huffma )
霍夫曼编码
在霍夫曼编码算法中, 固定长度的信源输出分组将映射成可变长度的二进制分组。该过程称为定长到变长编码。
其思想是将频繁出现的固定长度序列映射成较短的二进制序列, 而将出现频率较低的固定长度序列映射成较长的二进制序列。
平均码长
K ‾ = E [ L ] = ∑ x ∈ Ξ p ( x ) l ( x ) \overline{\boldsymbol{K}}=E[L]=\sum_{x \in \Xi} p(x) l(x) K=E[L]=x∈Ξ∑p(x)l(x)
一种最优的信源编码方法是信源的平均码长接近或者等于信源的信息熵H(X) 。
霍夫曼编码的步骤
- 将信源消息符号按其出现的概率大小依次排列 p ( x 1 ) ≥ p ( x 2 ) ≥ … ≥ p ( x n ) p(x_{1}) \geq p(x_{2}) \geq \ldots \geq p(x_{n}) p(x1)≥p(x2)≥…≥p(xn)
- 取两个概率最小的字母分别配以 0 和 1 两码元, 并将这两个概率相加作为一个新字母的概率, 与未分配的二进 符号的字母重新排队。
- 对重排后的两个概率最小符号重复步骤(2)的过程。
- 不断继续上述过程,直到最后两个符号配以 0 和 1 为止
- 从最后一级开始,向前返回得到各个信源符号所对应的码元序列, 即相应的码字。
Example:试为如下信源设计霍夫曼编码
[ A P ] = [ A 1 A 2 A 3 A 4 A 5 1 / 2 1 / 4 1 / 8 1 / 16 1 / 16 ] \left[\begin{array}{l} \mathrm{A} \\ P \end{array}\right]=\left[\begin{array}{ccccc} A 1 & A 2 & A 3 & A 4 & A 5 \\ 1 / 2 & 1 / 4 & 1 / 8 & 1 / 16 & 1 / 16 \end{array}\right] [AP]=[A11/2A21/4A31/8A41/16A51/16]
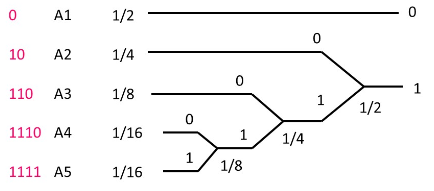
上例中, 平均码长为
K ˉ = E ( L ) = 1 × 1 / 2 + 2 × 1 / 4 + 3 × 1 / 8 + 2 × 4 × 1 / 16 = 1.875 H ( X ) = 1.875 = E ( L ) . \begin{array}{l} \bar{K}=E(L)=1 \times 1 / 2+2 \times 1 / 4+3 \times 1 / 8+2 \times 4 \times 1 / 16 \\ =1.875 \\ H(X)=1.875=E(L) . \end{array} Kˉ=E(L)=1×1/2+2×1/4+3×1/8+2×4×1/16=1.875H(X)=1.875=E(L).
霍夫曼编码的平均码长满足如下不等式
H ( X ) ≤ K ‾ < H ( X ) + 1 H(X) \leq \overline{\boldsymbol{K}}<H(X)+1 H(X)≤K<H(X)+1
如果对长度为n的信源字符序列进行霍夫曼编码(信源的 n 次扩展信源) 而不是对单信源字符的编码, 则有
H ( X n ) ≤ K ‾ n < H ( X n ) + 1 H(X^{n}) \leq \overline{\boldsymbol{K}}_{n}<H(X^{n})+1 H(Xn)≤Kn<H(Xn)+1
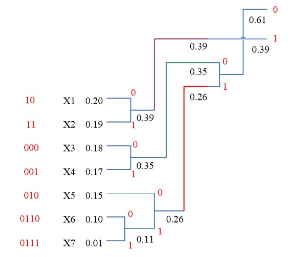
例 设单符号离散无记忆信源如下. 要求对信源编二进制霍夫曼码。
[ X p ( x ) ] = [ x l x 2 x 3 x 4 x 5 x 6 x 7 0.20 0.19 0.18 0.17 0.15 0.10 0.01 ] \left[\begin{array}{l} X \\ p(x) \end{array}\right]=\left[\begin{array}{ccccccc} x_{l} & x_{2} & x_{3} & x_{4} & x_{5} & x_{6} & x_{7} \\ 0.20 & 0.19 & 0.18 & 0.17 & 0.15 & 0.10 & 0.01 \end{array}\right] [Xp(x)]=[xl0.20x20.19x30.18x40.17x50.15x60.10x70.01]
熵
H ( X ) = − 0.2 log 0.2 − 0.19 log 0.19 − 0.18 log 0.18 − 0.17 log 0.17 − 0.15 log 0.15 − 0.10 log 0.10 − 0.01 log 0.01 = 2.61 \begin{array}{l} H(X) \\ \begin{aligned} =-0.2 & \log 0.2-0.19 \log 0.19-0.18 \log 0.18-0.17 \log 0.17 \\ & -0.15 \log 0.15-0.10 \log 0.10-0.01 \log 0.01 \\ = & 2.61 \end{aligned} \end{array} H(X)=−0.2=log0.2−0.19log0.19−0.18log0.18−0.17log0.17−0.15log0.15−0.10log0.10−0.01log0.012.61
平均码长为
K ˉ = ∑ i = 1 7 p ( x i ) K i = 0.2 × 2 + 0.19 × 2 + 0.18 × 3 + 0.17 × 3 + 0.15 × 3 + 0.10 × 4 + 0.01 × 4 = 2.72 \begin{array}{l} \bar{K}=\sum_{i=1}^{7} p\left(x_{i}\right) K_{i} \\ =0.2 \times 2+0.19 \times 2+0.18 \times 3+0.17 \times 3+0.15 \times 3+0.10 \times 4 +0.01 \times 4=2.72 \end{array} Kˉ=∑i=17p(xi)Ki=0.2×2+0.19×2+0.18×3+0.17×3+0.15×3+0.10×4+0.01×4=2.72
编码效率
η = H ( X ) R = H ( X ) K ˉ = 2.61 2.72 = 96 % \eta=\frac{H(X)}{R}=\frac{H(X)}{\bar{K}}=\frac{2.61}{2.72}=96 \% η=RH(X)=KˉH(X)=2.722.61=96%
霍夫曼的编法并不唯一。每次对缩减信源两个概率最小的符号分配“0”和“1”码元是任意的,所以可得到不同的码字。只要在各次缩减信源中保持码元分配的一致性,即能得到可分离码字。不同的码元分配,得到的具体码字不同,但码长 K i K_i Ki不变,平均码长也不变,所以没有本质区别;
缩减信源时,若合并后的新符号概率与其他符号概率相等,从编码方法上来说,这几个符号的次序可任意排列,编出的码都是正确的,但得到的码字不相同。
不同的编法得到的码字长度 K i K_i Ki也不尽相同。
例 单符号离散无记忆信源
[ X P ( X ) ] = { x 1 , x 2 , x 3 , x 4 , x 5 0.4 0.2 0.2 0.1 0.1 } [\begin{array}{c} X \\ P(X) \end{array}]=\{\begin{array}{lllll} x_{1}, & x_{2}, & x_{3}, & x_{4}, & x_{5} \\ 0.4 & 0.2 & 0.2 & 0.1 & 0.1 \end{array}\} [XP(X)]={x1,0.4x2,0.2x3,0.2x4,0.1x50.1}
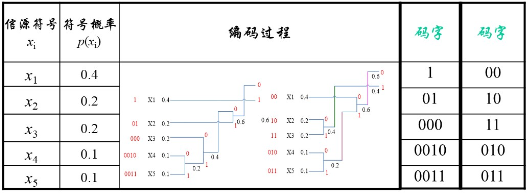
单符号信源编二进制哈夫曼码,编码效率主要决定于信源熵和平均码长之比。
对相同的信源编码, 其熵是一样的, 采用不同的编法, 得到的平均码长可能不同。
平均码长越短,编码效率就越高。
编法一的平均码长为
K 1 ‾ = ∑ i = 1 5 p ( x i ) K i = 0.4 × 1 + 0.2 × 2 + 0.2 × 3 + 0.1 × 4 × 2 = 2.2 \overline{K_{1}}=\sum_{i=1}^{5} p\left(x_{i}\right) K_{i}=0.4 \times 1+0.2 \times 2+0.2 \times 3+0.1 \times 4 \times 2=2.2 K1=i=1∑5p(xi)Ki=0.4×1+0.2×2+0.2×3+0.1×4×2=2.2
编法二的平均码长为
K 2 ‾ = ∑ i = 1 5 p ( x i ) K i = 0.4 × 2 + 0.2 × 2 × 2 + 0.1 × 3 × 2 = 2.2 \overline{K_{2}}=\sum_{i=1}^{5} p\left(x_{i}\right) K_{i}=0.4 \times 2+0.2 \times 2 \times 2+0.1 \times 3 \times 2=2.2 K2=i=1∑5p(xi)Ki=0.4×2+0.2×2×2+0.1×3×2=2.2
两种编法的平均码长相同,所以编码效率相同。
哪种方法更好?
定义码字长度的方差 σ 2 \sigma^{2} σ2 :
σ 2 = E [ ( K i − K ˉ ) 2 ] = ∑ i = 1 5 p ( x i ) ( K i − K ˉ ) 2 σ 1 2 = 0.4 ( 1 − 2.2 ) 2 + 0.2 ( 2 − 2.2 ) 2 + 0.2 ( 3 − 2.2 ) 2 + 0.1 ( 4 − 2.2 ) 2 × 2 = 1.36 σ 2 2 = 0.4 ( 2 − 2.2 ) 2 + 0.2 ( 2 − 2.2 ) 2 × 2 + 0.1 ( 3 − 2.2 ) 2 × 2 = 0.16 \begin{array}{c} \sigma^{2}=E\left[\left(K_{i}-\bar{K}\right)^{2}\right]=\sum_{i=1}^{5} p\left(x_{i}\right)\left(K_{i}-\bar{K}\right)^{2} \\ \sigma_{1}^{2}=0.4(1-2.2)^{2}+0.2(2-2.2)^{2}+0.2(3-2.2)^{2}+0.1(4-2.2)^{2} \times 2 =1.36 \\ \sigma_{2}^{2}=0.4(2-2.2)^{2}+0.2(2-2.2)^{2} \times 2+0.1(3-2.2)^{2} \times 2=0.16 \end{array} σ2=E[(Ki−Kˉ)2]=∑i=15p(xi)(Ki−Kˉ)2σ12=0.4(1−2.2)2+0.2(2−2.2)2+0.2(3−2.2)2+0.1(4−2.2)2×2=1.36σ22=0.4(2−2.2)2+0.2(2−2.2)2×2+0.1(3−2.2)2×2=0.16
第二种编码方法的码长方差要小许多。第二种编码方法的码长变化较小, 比较接近于平均码长。
第一种方法编出的5个码字有4种不同的码长;第二种方法编出的码长只有两种不同的码长;第二种编码方法更简单、更容易实现,所以更好。
结论:
在霍夫曼编码过程中,对缩减信源符号按概率由大到小的顺序重新排列时,应使合并后的新符号尽可能排在靠前的位置, 这样可使合并后的新符号重复编码次数减少,使短码得到充分利用。
例: 一信源模型如下, 试对信源符号进行 Huffman编码, 并计算平均码长和编码效率 。若对其2次扩展信源进行编码, 结果如何
[ S p ] = [ s 1 s 2 s 3 s 4 s 5 0.4 0.2 0.2 0.1 0.1 ] \left[\begin{array}{l} S \\ p \end{array}\right]=\left[\begin{array}{ccccc} s_{1} & s_{2} & s_{3} & s_{4} & s_{5} \\ 0.4 & 0.2 & 0.2 & 0.1 & 0.1 \end{array}\right] [Sp]=[s10.4s20.2s30.2s40.1s50.1]
解: (1) 不做扩展, 进行单符号Huffuman编码时 编码结果为:
s 1 1 s 2 01 H ( S ) = 2.122 b i t / s y m s 3 000 l ˉ = 2.2 码元 / sym s 4 0010 η = H ( S ) / l ˉ = 0.965 s 5 0011 \begin{array}{ccc}s_{1} & 1 & \\ s_{2} & 01 & H(S)=2.122 b i t / s y m \\ s_{3} & 000 & \bar{l}=2.2 \text { 码元 } / \text { sym } \\ s_{4} & 0010 & \eta=H(S) / \bar{l}=0.965 \\ s_{5} & 0011 & \end{array} s1s2s3s4s510100000100011H(S)=2.122bit/symlˉ=2.2 码元 / sym η=H(S)/lˉ=0.965
(2)二次扩展信源 S 2 \mathrm{S}^{2} S2 , 共有 5 2 = 25 5^{2}=25 52=25 个信源符号, 为
s 1 s 1 , s 1 s 2 , s 1 s 3 , s 1 s 4 , s 1 s 5 , s 2 s 1 , s 2 s 2 , s 2 s 3 , s 2 s 4 , s 2 s 5 s 3 s 1 , s 3 s 2 , s 3 s 3 , s 3 s 4 , s 3 s 5 , s 4 s 1 , s 4 s 2 , s 4 s 3 , s 4 s 4 , s 4 s 5 s 5 s 1 , s 5 s 2 , s 5 s 3 , s 5 s 4 , s 1 s 5 \begin{array}{l} s_{1} s_{1}, s_{1} s_{2}, s_{1} s_{3}, s_{1} s_{4}, s_{1} s_{5}, s_{2} s_{1}, s_{2} s_{2}, s_{2} s_{3}, s_{2} s_{4}, s_{2} s_{5} \\ s_{3} s_{1}, s_{3} s_{2}, s_{3} s_{3}, s_{3} s_{4}, s_{3} s_{5}, s_{4} s_{1}, s_{4} s_{2}, s_{4} s_{3}, s_{4} s_{4}, s_{4} s_{5} \\ s_{5} s_{1}, s_{5} s_{2}, s_{5} s_{3}, s_{5} s_{4}, s_{1} s_{5} \end{array} s1s1,s1s2,s1s3,s1s4,s1s5,s2s1,s2s2,s2s3,s2s4,s2s5s3s1,s3s2,s3s3,s3s4,s3s5,s4s1,s4s2,s4s3,s4s4,s4s5s5s1,s5s2,s5s3,s5s4,s1s5
双应的概率为: 0.16 , 0.08 , 0.08 , 0.04 , 0.04 ⋯ 0.01 0.16,0.08,0.08,0.04,0.04 \cdots 0.01 0.16,0.08,0.08,0.04,0.04⋯0.01 可得编码结果为
s 1 s 1 ( 01 ) , s 4 s 2 ( 001 ) , s 1 s 3 ( 1001 ) , s 1 s 4 ( 0001 ) , s 4 s 5 ( 10111 ) , s 2 s 1 ( 1000 ) , s 2 s 2 ( 11001 ) , s 2 s 3 ( 11010 ) , s 2 s 4 ( 111010 ) , s 2 s 5 ( 111011 ) s 3 s 1 ( 1010 ) , s 3 s 2 ( 11011 ) , s 3 s 3 ( 11100 ) , s 3 s 4 ( 111110 ) , s 3 s 5 ( 111111 ) , s 4 s 1 ( 10110 ) , s 4 s 2 ( 111100 ) , s 4 s 3 ( 000000 ) , s 4 s 4 ( 00001000 ) , s 4 s 5 ( 0000101 ) , s 5 s 1 ( 11000 ) , s 5 s 2 ( 111101 ) , s 5 s 3 ( 000001 ) , s 5 s 4 ( 0000110 ) , s 5 s 5 ( 0000111 ) l ˉ = 2.16 码无/sym η = 0.982 \begin{array}{l} s_{1} s_{1}(01), s_{4} s_{2}(001), s_{1} s_{3}(1001), s_{1} s_{4}(0001), s_{4} s_{5}(10111), \\ s_{2} s_{1}(1000), s_{2} s_{2}(11001), s_{2} s_{3}(11010), s_{2} s_{4}(111010), s_{2} s_{5}(111011) \\ s_{3} s_{1}(1010), s_{3} s_{2}(11011), s_{3} s_{3}(11100), s_{3} s_{4}(111110), s_{3} s_{5}(111111), \\ s_{4} s_{1}(10110), s_{4} s_{2}(111100), s_{4} s_{3}(000000), s_{4} s_{4}(00001000), s_{4} s_{5}(0000101), \\ s_{5} s_{1}(11000), s_{5} s_{2}(111101), s_{5} s_{3}(000001), s_{5} s_{4}(0000110), s_{5} s_{5}(0000111) \\ \bar{l}=2.16 \text { 码无/sym } \\ \eta=0.982 \end{array} s1s1(01),s4s2(001),s1s3(1001),s1s4(0001),s4s5(10111),s2s1(1000),s2s2(11001),s2s3(11010),s2s4(111010),s2s5(111011)s3s1(1010),s3s2(11011),s3s3(11100),s3s4(111110),s3s5(111111),s4s1(10110),s4s2(111100),s4s3(000000),s4s4(00001000),s4s5(0000101),s5s1(11000),s5s2(111101),s5s3(000001),s5s4(0000110),s5s5(0000111)lˉ=2.16 码无/sym η=0.982
结论:N 越大, 编码效率越大。
某DMS信源如式: [ X P ] = [ x 1 x 2 x 3 1 / 2 1 / 3 1 / 6 ] \left[\begin{array}{l}\mathrm{X} \\ \mathrm{P}\end{array}\right]=\left[\begin{array}{ccc}x_{1} & x_{2} & x_{3} \\ 1 / 2 & 1 / 3 & 1 / 6\end{array}\right] [XP]=[x11/2x21/3x31/6] , 则其二次扩展信源为
[ X 2 P ] = [ x 1 x 1 x 1 x 2 x 1 x 3 x 2 x 1 x 2 x 2 x 2 x 3 x 3 x 1 x 3 x 2 x 3 x 3 1 / 4 1 / 6 1 / 12 1 / 6 1 / 9 1 / 18 1 / 12 1 / 18 1 / 36 ] \begin{array}{l} {\left[\begin{array}{c} X^{2} \\ P \end{array}\right]} =\left[\begin{array}{ccccccccc} x_{1} x_{1} & x_{1} x_{2} & x_{1} x_{3} & x_{2} x_{1} & x_{2} x_{2} & x_{2} x_{3} & x_{3} x_{1} & x_{3} x_{2} & x_{3} x_{3} \\ 1 / 4 & 1 / 6 & 1 / 12 & 1 / 6 & 1 / 9 & 1 / 18 & 1 / 12 & 1 / 18 & 1 / 36 \end{array}\right] \end{array} [X2P]=[x1x11/4x1x21/6x1x31/12x2x11/6x2x21/9x2x31/18x3x11/12x3x21/18x3x31/36]
请分别对DMS信源: [ X p ] = [ x 1 x 2 x 3 1 / 2 1 / 3 1 / 6 ] \left[\begin{array}{l}\mathrm{X} \\ \mathrm{p}\end{array}\right]=\left[\begin{array}{ccc}x_{1} & x_{2} & x_{3} \\ 1 / 2 & 1 / 3 & 1 / 6\end{array}\right] [Xp]=[x11/2x21/3x31/6] , 及其二次扩展信源进行二进制霍夫曼编码,并计算平均码长。DMS信源: x 1 − 1 ; x 2 − 01 ; x 3 − 00 x_1-1 ; x_2-01 ; x_3-00 x1−1;x2−01;x3−00 。平均码长 =1.5
扩展信源:
x 1 x 1 x 1 x 2 x 1 x 3 x 2 x 1 x 2 x 2 x 2 x 3 x 3 x 1 x 3 x 2 x 3 x 3 1 / 4 1 / 6 1 / 12 1 / 6 1 / 9 1 / 18 1 / 12 1 / 18 1 / 36 01 111 001 110 100 1000 1011 0011 0010 \begin{array}{ccccccccc}x_1 x_1 & x_1 x_2 & x_1 x_3 & x_2 x_1 & x_2 x_2 & x_2 x_3 & x_3 x_1 & x_3 x_2 & x_3 x_3 \\ 1 / 4 & 1 / 6 & 1 / 12 & 1 / 6 & 1 / 9 & 1 / 18 & 1 / 12 & 1 / 18 & 1 / 36 \\ 01 & 111 & 001 & 110 & 100 & 1000 & 1011 & 0011 & 0010\end{array} x1x11/401x1x21/6111x1x31/12001x2x11/6110x2x21/9100x2x31/181000x3x11/121011x3x21/180011x3x31/360010
平均码长 =107 / 36; 平均每符号码长 =107 / 72=1.486;
该信源信息熵 =1.459 bit/sym。
L-Z编码
将信源序列分成一系列以前未出现而且最短的字符串或词组。如,将信源序列列1011010100010…分成1,0,11,01,010,00,10,…注意,每个词组具有如下性质:
- 每个词组有一个前缀在前面出现过;
- 每个词组的长度比其前缀长一个字符。
- 对词组进行如下编码:给出前缀在词组序列中的位置号和最后一个字符的值。L-Z编码先将信源分成不等长的词组然后编码。
设c(n)为信源序列所分成的词组的个数,那么描述词组的前缀的位置需要logc(n) bit, 而词组的最后一个符号需要1bit。上例中,词组的个数为7,那么描述词组的前缀的位置需要3bit。所对应的编码序列为(000,1),(000,0)(001,1) , (010,1) ,(100,0) , (010,0),(001,0)。其中每个括号内的第一个数字表示该词组的前缀的位置序号,第二个数字是该词组的最后一个符号。
L-Z算法主要包括两步:
- 将序列分组,计算词组个数c(n)和描述前缀的位置需要的比特数logc(n);
- 对每个词组,计算前缀位置,构成码字。前缀位置的编码可以是等长码,也可以是变长码。通常在起始位置需要的位数少,而随着词组序号的增长,前缀位置的编码的位数也不断增加。L-Z编码一般用在信源序列长度较大是才有效。
总结
- 编码的基本概念
- 无失真信源编码:译码错误概率任意小。
- 香农无失真信源编码定理:存在压缩编码的极限。
- 霍夫曼编码:是一种最优的信源编码,某些信源概率分布条件下,可以达到香农信源编码的极限。
参考文献:
- Proakis, John G., et al. Communication systems engineering. Vol. 2. New Jersey: Prentice Hall, 1994.
- Proakis, John G., et al. SOLUTIONS MANUAL Communication Systems Engineering. Vol. 2. New Jersey: Prentice Hall, 1994.
- 周炯槃. 通信原理(第3版)[M]. 北京:北京邮电大学出版社, 2008.
- 樊昌信, 曹丽娜. 通信原理(第7版) [M]. 北京:国防工业出版社, 2012.