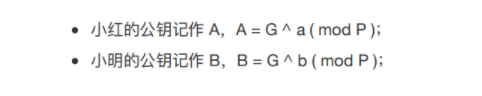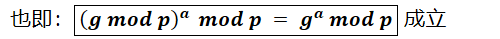DH 算法是 Diffie和Hellman于1976年提出了一种的密钥交换协议。这种加密算法主要用于密钥的交换,可以在非安全信道下为双方创建通信密钥,通讯双方可以使用这个密钥进行消息的加密、解密,并且能够保证通讯的安全。
换而言之,算法希望实现这样的一个效果:
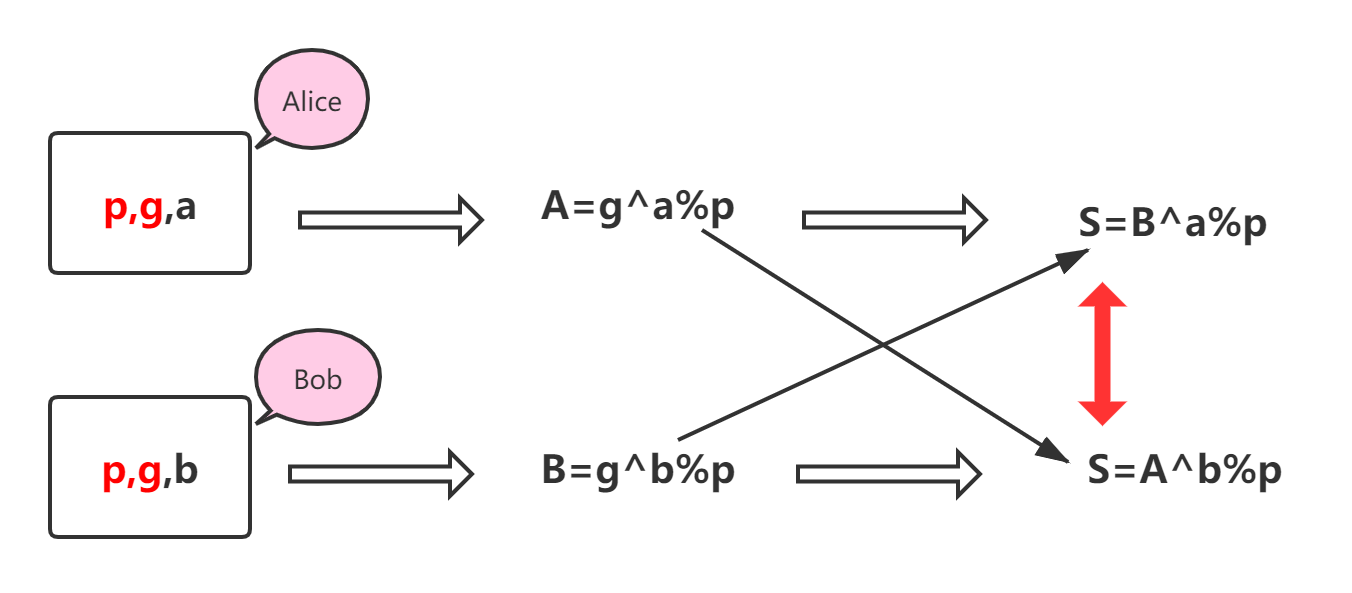
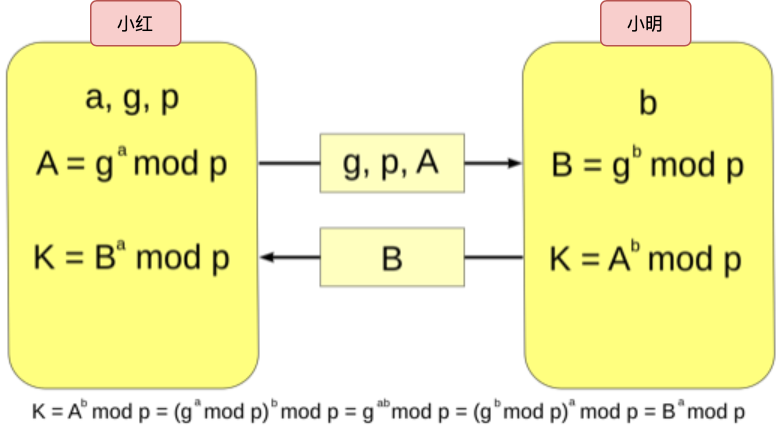
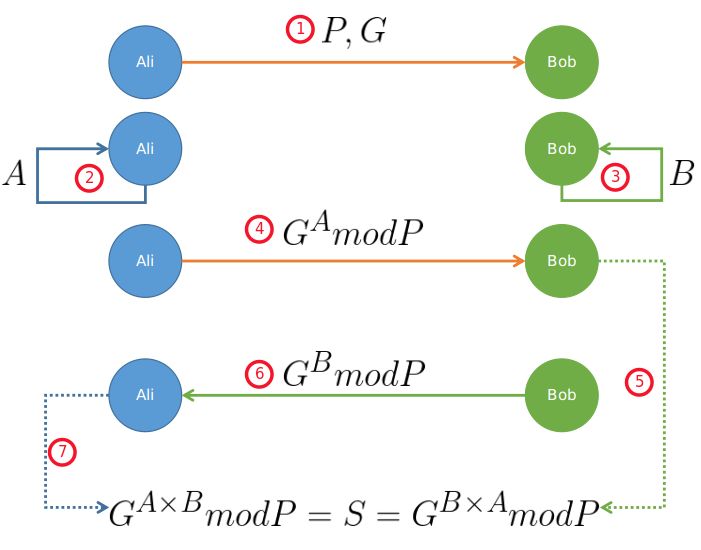
通信方A和B首先各自生成密钥 D a D_a Da和 D b D_b Db,然后通过某种计算获得各自的公钥 P a P_a Pa和 P b P_b Pb,接下来,A和B互相交换公钥 P a P_a Pa和 P b P_b Pb。现在,A持有自己的密钥 D a D_a Da和B的公钥 P b P_b Pb,B持有自己的密钥 D b D_b Db和A的公钥 P a P_a Pa, D a D_a Da与 P b P_b Pb、 D b D_b Db与 P a P_a Pa经过某种数学运算,都能生成一个相同的加密密钥S用于通信。正在监听通信的第三方由于只得到了 P a P_a Pa和 P b P_b Pb,是无法计算得出密钥S的。
具体的过程如下图所示:

公钥 P a P_a Pa和 P b P_b Pb由函数 f 1 f_1 f1计算得出,共享密钥由 f 2 f_2 f2计算得出。这两个函数的破解难度直接影响到整个密钥交换算法的强度。
不妨选择函数为 f 2 ( a , b ) = a b f_2(a,b)=ab f2(a,b)=ab,也就是说我们需要让等式 D a P b = D b P a D_aP_b=D_bP_a DaPb=DbPa成立(否则无法生成相同的密钥)。现在我们随便选择一个常量因子F,令函数 f 1 ( x ) = F ⋅ x f_1(x)=F·x f1(x)=F⋅x,则有 D a F D b = D b F D a D_aFD_b=D_bFD_a DaFDb=DbFDa,等式 D a P b = D b P a D_aP_b=D_bP_a DaPb=DbPa成立了。
现在我们得出了一个简单的密钥交换策略:双方都先约定好一个常数F,假设为100好了,然后A和B各自随机生成一个密钥,假设 D a = 3 D_a=3 Da=3, D b = 4 D_b=4 Db=4,按照函数 f 1 f1 f1生成公钥 P a = 300 P_a=300 Pa=300, P b = 400 P_b=400 Pb=400,然后互相交换。现在A知道 D a D_a Da和 P b P_b Pb,一乘起来就是1200,B那边也是, D b ⋅ P a = 1200 D_b·P_a=1200 Db⋅Pa=1200,这个1200就是他们的共享密钥S。
如果只得知双方交换的公钥,是无法得出密钥S的,但是F被第三方得知的话,通信加密就会立刻被破坏。首先,这个常数F不能固定写在程序内,因为程序一旦发布,这个固定的常数就有暴露的风险,更糟糕的是,F暴露之后所有使用这个常数的会话都变得不安全了。而每次会话随机选择一个常数F,面临的问题则是双方如何在不安全信道交换F。
上述简单策略不能实现密钥交换的原因是算法过于简单并且可逆。若是只是简单的使用加减乘除进行多项式计算,基本都是可逆且能够快速计算出来的。因此,如何防止别人利用从公钥 P a P_a Pa、 P b P_b Pb根据函数 f 1 f_1 f1进行逆向分解得出A或B的密钥,即不可逆,同时又可以让A和B根据公钥生成公共的密钥成了关键。(就算函数 f 1 f_1 f1不出现在网络中,但在最坏的情况下函数 f 1 f_1 f1会暴露)。
生成公钥的 f 1 f_1 f1有两种实现方式:基于离散对数难题的最早版本的DH算法,和结合了椭圆曲线问题的加强版算法ECDH。
基于离散对数难题的DH算法
要实现不可逆的目标,其实也就是令函数 f 1 f_1 f1没有反函数,例如 f ( x ) = x 2 f(x)=x^2 f(x)=x2在定义域 R R R上没有反函数。当然,只是没有反函数的话强度是不够的, y = x 2 y=x^2 y=x2中的y只有两种可能的x取值,稍微用密文试试手就知道x和-x谁才是密钥了。一个y最好对应无穷个x的值,例如 y = x m o d p y=x\mod p y=xmodp,但是这样还不够,仍存在被暴力破解的风险。
f 1 f_1 f1实现如下,它利用了离散对数问题的难解性:
选择一个二元组 ( g , p ) (g,p) (g,p),定义函数 f 1 ( x ) = g x m o d p f_1(x)=g^x \mod p f1(x)=gxmodp,其中 x ∈ ( 1 , p ) x \in (1,p) x∈(1,p)且为整数,作为公钥生成的函数。
这其中g和p都是一个常数。假设窃听者得知了公钥 P a P_a Pa,想要计算 D a D_a Da的话,不妨设 n ∈ N n \in N n∈N,然后有:
g D a = n ⋅ p + P a → D a = log g ( n ⋅ p + P a ) g^{D_a}=n·p+P_a \rightarrow D_a=\log_{g}(n·p+P_a) gDa=n⋅p+Pa→Da=logg(n⋅p+Pa)
想要解答上述算式存在时间上的问题,对于精心挑选的的g和p而言,没有多项式时间的经典算法可用于破解它们。
如何选择二元组(g,p)
如果并不关心算法参数的具体实现,这一节内容可以跳过。
二元组需要满足什么条件,才不会被轻易破解呢?
假设我们选择了一个二元组(2,7),不妨使用函数 f 1 f_1 f1计算一下:
2 1 m o d 7 = 2 2 2 m o d 7 = 4 2 3 m o d 7 = 1 2 4 m o d 7 = 2 2^1\mod 7=2 \\ 2^2\mod 7=4 \\ 2^3\mod 7=1 \\ 2^4\mod 7=2 21mod7=222mod7=423mod7=124mod7=2
2 x m o d 7 2^x \mod 7 2xmod7的值存在一个循环,这可不是什么好消息,攻击者无需遍历1~p就有可能猜出密钥!
上面的循环,我们专门用阶来定义这种概念。
阶的定义:m为正整数,若 ( a , m ) = 1 (a,m)=1 (a,m)=1,使得 a d m o d m = 1 a^d \mod m=1 admodm=1成立的最小正整数d,被称为a对模m的阶,记作 o r d m ( a ) ord_m(a) ordm(a)。 ( a , m ) (a,m) (a,m)的含义为a与m互质。
我们可以证明, a , a 2 , ⋯ a o r d m ( a ) a,a^2,\cdots a^{ord_m(a)} a,a2,⋯aordm(a)mod m m m的值两两不相等(或者说它们互不同余)。那么要想加强算法的强度,阶d最好应当等于m-1,这样意味着 a d m o d m a^d \mod m admodm的取值范围为 [ 1 , m − 1 ] [1,m-1] [1,m−1],达到了最大化。
想要达到这个目的,我们还得回答一个问题: a d m o d m a^d \mod m admodm中,对于任意一个m而言,a存在某个值,使得其阶d等于m-1吗?
要回答这个问题,需要引入欧拉函数的概念:
对于正整数n,欧拉函数 φ ( x ) \varphi(x) φ(x)是小于n的正整数中与n互质的数的数目。
例如 φ ( 10 ) = 4 \varphi(10)=4 φ(10)=4,与它互质的数分别为1、3、7、9。而 φ ( 7 ) = 6 \varphi(7)=6 φ(7)=6,对于质因数x而言, φ ( x ) = x − 1 \varphi(x)=x-1 φ(x)=x−1。
下面的欧拉定理能部分回答我们的问题:
若 a , m 均 为 正 整 数 , ( a , m ) = 1 , 则 a φ ( m ) m o d m = 1 若a,m均为正整数,(a,m)=1,则a^{\varphi(m)}\mod m=1 若a,m均为正整数,(a,m)=1,则aφ(m)modm=1
上面的定理实际上告诉了我们a对模m的阶的最大值至多为 φ ( m ) \varphi(m) φ(m)。例如对于模15来说,不管如何选择底数a,它的阶最大也只可能是 φ ( 15 ) = 8 \varphi(15)=8 φ(15)=8,而不可能是我们期望的最好的值14。要想达到最好的效果,模m就必须选择一个奇质数(2是质数但它太小了),这样 φ ( m ) = m − 1 \varphi(m)=m-1 φ(m)=m−1,才有希望取到最大的阶。
不过问题还没回答完,对于某个确定的模m(比如说7),真的存在一个数a,它的阶是 φ ( m ) \varphi(m) φ(m)吗?请不要把这个问题和上面的欧拉定理混淆,虽然 a φ ( m ) m o d m = 1 a^{\varphi(m)}\mod m=1 aφ(m)modm=1(欧拉定理)必定成立,但是不代表值 φ ( m ) \varphi(m) φ(m)是a的阶啊!
举一个很明显的例子,假设a=2,p=7,我们很容易得知 φ ( 7 ) = 6 \varphi(7)=6 φ(7)=6,而 2 6 m o d 7 = 1 2^6\mod 7=1 26mod7=1,欧拉定理确实是成立的,但重新再看看上面举的例子,我们发现 2 3 m o d 7 = 1 2^3\mod 7=1 23mod7=1,也就是说2对7的阶为3,并不是6!
让我们计算一下3对7的阶:
3 1 m o d 7 = 3 3 2 m o d 7 = 2 3 3 m o d 7 = 6 3 4 m o d 7 = 4 3 5 m o d 7 = 5 3 6 m o d 7 = 1 3^1\mod 7=3 \\ 3^2\mod 7=2 \\ 3^3\mod 7=6 \\ 3^4\mod 7=4 \\ 3^5\mod 7=5 \\ 3^6\mod 7=1 \\ 31mod7=332mod7=233mod7=634mod7=435mod7=536mod7=1
3的阶是6,也就是说对于7而言,存在一个数3的阶为 φ ( 7 ) \varphi(7) φ(7)。那么如何称呼满足这种性质的数a呢?我们再给出一个原根的定义:
若 a , m 均 为 正 整 数 , ( a , m ) = 1 , 令 a d m o d m = 1 成 立 的 最 小 正 整 数 d , 其 满 足 d = φ ( m ) 的 话 , 则 称 a 是 模 m 的 原 根 若a,m均为正整数,(a,m)=1,令a^d\mod m=1成立的最小正整数d,其满足d=\varphi(m)的话,则称a是模m的原根 若a,m均为正整数,(a,m)=1,令admodm=1成立的最小正整数d,其满足d=φ(m)的话,则称a是模m的原根
可以证明,若p是奇质数,则模p的原根存在,而合数就不一定了,例如15就没有原根。
根据上面的推导,选择二元组的要求呼之欲出:在 ( g , p ) (g,p) (g,p)中,p应当是一个大质数,g应当为p的一个原根,这样一来想要计算出密钥 D a D_a Da是一件相当困难的事情。
生成共同密钥
生成共同密钥的函数 f 2 f_2 f2应当保证两边生成的密钥都是一样的,具体实现为:
对 于 A : S = f 2 ( D a , P b ) = P b D a m o d p 对 于 B : S = f 2 ( D b , P a ) = P a D b m o d p 对于A:S=f_2(D_a,P_b)=P_b^{D_a}\mod p\\ 对于B:S=f_2(D_b,P_a)=P_a^{D_b}\mod p 对于A:S=f2(Da,Pb)=PbDamodp对于B:S=f2(Db,Pa)=PaDbmodp
其中p就是函数 f 1 f_1 f1中的二元组中的p。其实我们把函数 f 1 f_1 f1的参数扩展为两位: f ( D , g ) = g D m o d p f(D, g)=g^D\mod p f(D,g)=gDmodp,函数 f 1 f_1 f1和 f 2 f_2 f2的形式是完全一致的。 我们需要证明 f ( D b , f ( D a , g ) ) = f ( D a , f ( D b , g ) ) f(D_b,f(D_a,g))=f(D_a,f(D_b,g)) f(Db,f(Da,g))=f(Da,f(Db,g))成立。以下是证明:
令 t = f ( D , g ) = g D m o d p t=f(D, g)=g^D\mod p t=f(D,g)=gDmodp,则有 g D = k p + t g^D=kp+t gD=kp+t,反过来, t = g D − k p t=g^D-kp t=gD−kp,其中k是整数。既然 t = f ( D , g ) = g D − k p t=f(D, g)=g^D-kp t=f(D,g)=gD−kp,那么有 f ( D a , f ( D b , g ) ) = ( t ) D a m o d p = ( g D b − k p ) D a m o d p f(D_a,f(D_b,g))=(t)^{D_a}\mod p=(g^{D_b}-kp)^{D_a}\mod p f(Da,f(Db,g))=(t)Damodp=(gDb−kp)Damodp
根据二项式法则展开 ( g D b − k p ) D a (g^{D_b}-kp)^{D_a} (gDb−kp)Da,不带有 k p kp kp的项只有一个 g D b D a g^{D_bD_a} gDbDa,其他带有 k p kp kp的项计算 m o d p \mod p modp的结果都为0,因此 ( g D b − k p ) D a m o d p = g D b D a m o d p (g^{D_b}-kp)^{D_a}\mod p=g^{D_bD_a}\mod p (gDb−kp)Damodp=gDbDamodp基于对称性的思想,可以立刻列出 f ( D b , f ( D a , g ) ) = ( g D a − k p ) D b m o d p = g D a D b m o d p f(D_b,f(D_a,g))=(g^{D_a}-kp)^{D_b}\mod p=g^{D_aD_b}\mod p f(Db,f(Da,g))=(gDa−kp)Dbmodp=gDaDbmodp所以, f ( D b , f ( D a , g ) ) = f ( D a , f ( D b , g ) ) f(D_b,f(D_a,g))=f(D_a,f(D_b,g)) f(Db,f(Da,g))=f(Da,f(Db,g))成立。