深度学习边缘检测 HED 训练自己的数据
数据集制作
使用labelme标注,选择lineStrip(线条束)标注
生成json文件。
之后使用批量处理脚本将json文件转为边缘数据集。具体过程如下:
首先将所有的json文件放入一个文件夹内,同时将接送json2dataset.py脚本放入文件夹内:
json2dataset.py 批量处理
可以在这个地方修改linewidth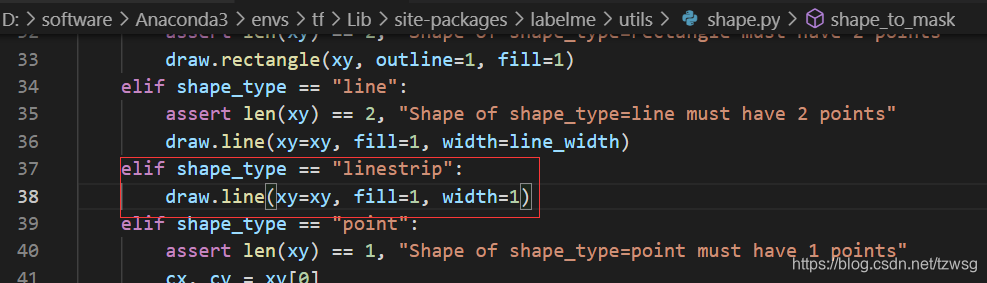
#-*-coding:utf-8-*-
import os
files=os.listdir('./')
files.remove('json2dataset.py')
for i in range(len(files)):os.system('labelme_json_to_dataset '+files[i])
之后会生成同等数量的文件夹,每个文件夹的内容如下:
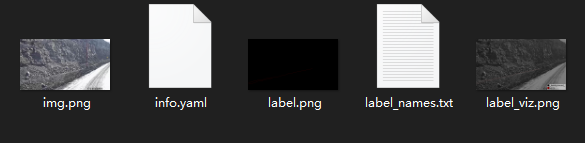
其中img.png是我们所需的标注图,需要对其进行改名并将所有的标注图提取到一个文件夹内。
首先运行rename.py,放在文件夹外,此脚本将所有的label.png重命名为你原图的名字+.png
#-*-coding:utf-8-*-
# 把label.png改名为1.png
import os
for root, dirs, names in os.walk(r'json'): # 改成你自己的json文件夹所在的目录for dr in dirs:file_dir = os.path.join(root, dr)# print(dr)file = os.path.join(file_dir, 'label.png')# print(file)new_name = dr.split('_')[0] + '.png'new_file_name = os.path.join(file_dir, new_name)os.rename(file, new_file_name)
再运行copy.py,作用是提取所有的标注图到edge文件夹内。
#-*-coding:utf-8-*-
import os
from shutil import copyfile
for root, dirs, names in os.walk(r'json'): # 改成你自己的json文件夹所在的目录for dr in dirs:file_dir = os.path.join(root, dr)print(dr)file = os.path.join(file_dir,'label.png')print(file)new_name = dr.split('_')[0] + '.png'new_file_name = os.path.join(file_dir, new_name)print(new_file_name)再对标注图进行二值化:
import cv2
import osdir = 'data/wire/train/edge'
edge = 'data/wire/train/edge1607'def canny(path):out = edge + '/' + path.split('.')[0] + '.png'print(out)path = dir + '/' + pathimg = cv2.imread(path,0)img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)print(img.shape)ret, img = cv2.threshold(img, 20, 255, cv2.THRESH_BINARY)cv2.imwrite(out, img)# for x in range(img.shape[0]):# for y in range(img.shape[1]):# px = img[x,y]# if px.any() != 0:# print(px)# print(img.shape)for path in os.listdir(dir):canny(path)之后
git clone https://github.com/xwjabc/hed
下载预训练权重
cd hed
wget https://cseweb.ucsd.edu/~weijian/static/datasets/hed/hed-data.tar
tar xvf ./hed-data.tar
仿照HED-BSDS数据集制作自己的数据集
训练
python hed.py --vgg16_caffe ./data/5stage-vgg.py36pickle --dataset ./data/wire
测试
python hed.py --checkpoint output/epoch-39-checkpoint.pt --output ./output3 --test --dataset ./data/wire