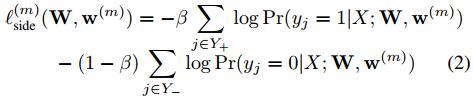(HED)Holistically-Nested Edge Detection
解决问题
ICCV2015的文章。主要解决两个问题:
(1)基于整个图像的训练和预测;
(2)多尺度和多水平(多层次)的特征学习。该算法通过深度学习模型,完成了从图像到图像的预测,并通过学习到的丰富的分级特征,完成边缘检测中的细节问题。
在 HED 网络出现之前,大多数边缘检测方法如 N4-field、DeepEdge、DeepContour 等都是基于局部区域的算法。虽然通过 CNN 的学习能力上述方法也取得了不错的边缘检测性能,但也存在计算成本高,测试成本高的缺陷。而HED基于整体图像的训练和预测通过直接对图像中的每个像素进行判断,简单高效精确度高。
基本思想
HED论文提出的end-to-end的边缘检测系统,称为holistically-nested edge detection (HED),
- 使用holistically来表示边缘预测的结果是基于图像到图像的,端到端的过程;
- 而nested则强调了在生成的输出过程中不断地继承和学习得到精确的边缘预测图的过程(具体算法后面再说明)。
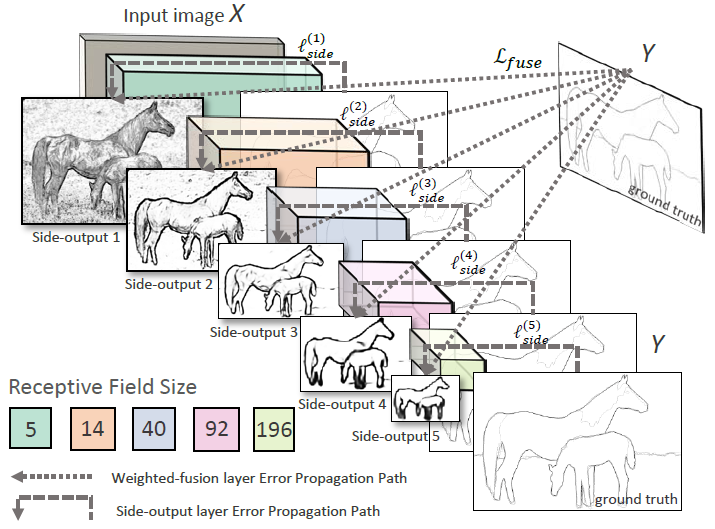
- 这里使用多尺度的方法进行特征的学习,多尺度下的该方法边缘检测结果示意图如下图,图中的d,e,f分别为卷积层2,3,4响应得到的边缘检测结果,HED方法的最后输出是远远优于canny算子的。

HED 网络拥有多个**侧输出(每层conv都输出)**的单流深层网络,能够通过多尺度的学习,对中间细节进行丰富的特征提取。相比于直接利用输出层的最终结果,多尺度多层次的特征学习会拥有更好地边缘检测结果
网络结构
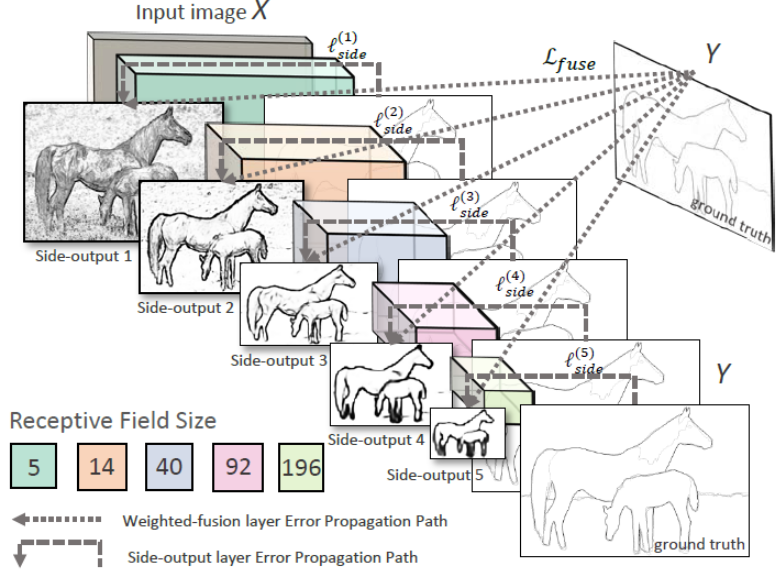
这个图非常形象,在卷积层后面侧边插入一个输出层 side-output 层,在side-output层上进行deep supervision,使得结果向着边缘检测方向进行。同时随着side-output层越向后大小的变小,将receptive field变大,最后通过一个weighted-fusion layer得到多尺度下的输出。
- HED 模型包含五个层级的特征提取架构,每个层级中:
– 使用 VGG Block 提取层级特征图
– 使用层级特征图计算层级输出
– 层级输出上采样 - 最后融合五个层级输出作为模型的最终输出:
– 通道维度拼接五个层级的输出
– 1x1 卷积对层级输出进行融合 - HED 网络架构建立在 VGG16 网络的基础之上,但做出了两方面的修改:
– 为了进行多尺度多层次的特征学习,在 VGG16 网络每个阶段的最后一个卷积层(conv1_2,conv2_2,conv3_3,conv4_3,conv5_3)之后添加侧输出层。
– 为了节约网络训练的内存/时间成本,去掉了最后一个池化层和之后的全连接层。 (FCN是将最后的全连接变成了全卷积)
通过将卷积层后引出的 5 个侧输出以及 5 个侧输出经过融合层后的结果同时进行训练,计算 6 个损失函数。通过多个侧输出,进行多尺度的学习,对中间细节进行特征提取。对于每个侧输出,通过双线性差值算法进行上采样,还原到原始图像的尺寸,通过融合层输出结果。
完整的网络结果如下图所示。
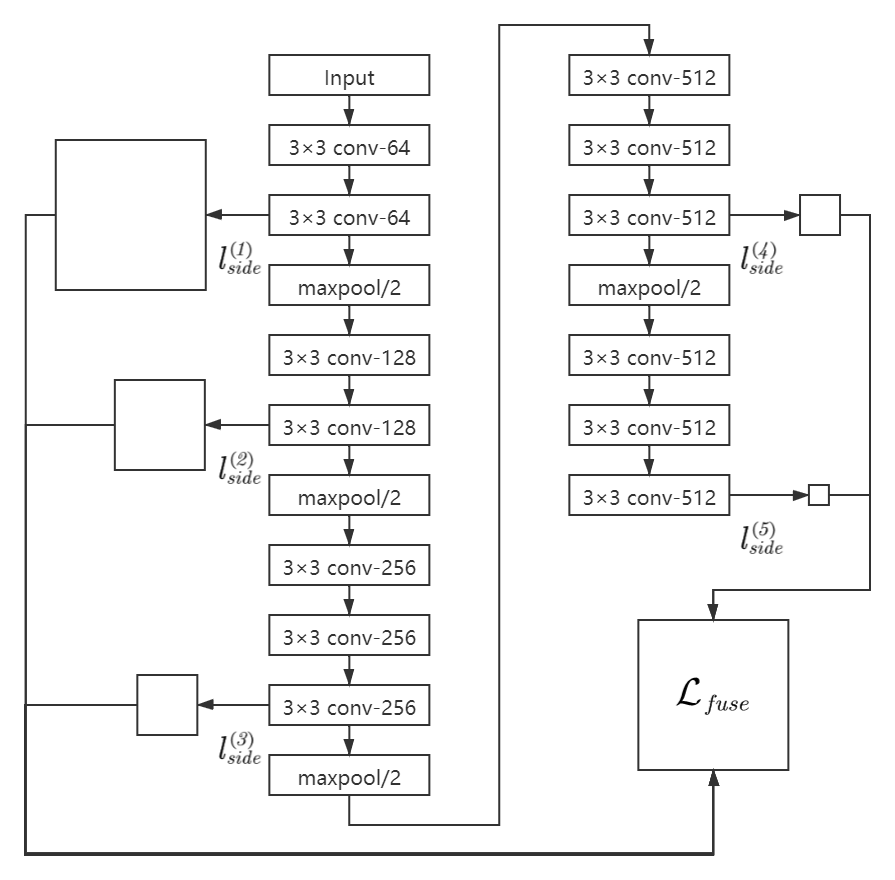
算法结构
作者将具体多尺度下的深度学习分为四种,如下图。
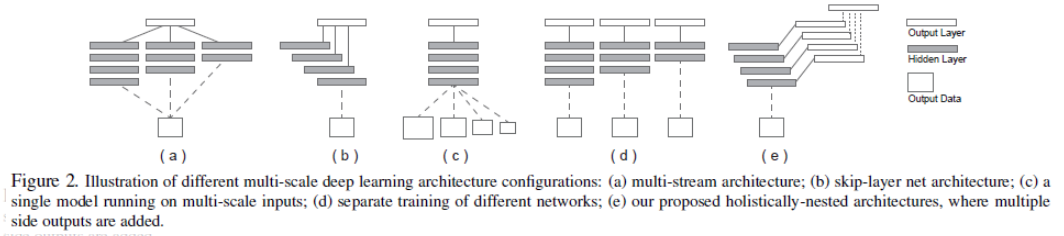
(a)Multi-stream learning 示意图,可以看到图中的平行的网络下,每个网络通过不同参数与receptive field大小的不同,获得多尺度的结果。输入影像是同时进入多个网络处理,得到的特征结果直接反应多尺度。
(b)Skip-layer network learning 示意图,该方法主要连接各个单的初始网络流得到特征响应,并将响应结合在一起输出。
这里(a)和(b)都是使用一个输出的loss函数进行单一的回归预测,而边缘检测可能通过多个回归预测得到结合的边缘图效果更好。
(c)Single model on multiple inputs 示意图,单一网络,图像resize方法得到多尺度进行输入,该方法在训练和test过程均可加入。同时在非深度学习中也有广泛应用。
(d)Training independent networks ,从(a)演化来,通过多个独立网络分别对不同深度和输出loss进行多尺度预测,该方法下训练样本量较大。
(e)Holistically-nested networks,本文提出的算法结构,从(d)演化来,类似地是一个相互独立多网络多尺度预测系统,但是将multiple side outputs组合成一个单一深度网络。
pytorch代码
HED优缺点
- 优点:借助 VGG 网络强大的特征提取能力,HED 边缘检测算法能够对图像进行多尺度多层次的学习,直接对整幅图像进行操作。在侧输出层通过深度监督,将不同尺度的侧输出结果进行融合,最后得到了较为优秀的边缘检测结果。
- 缺点:然而,随着网络深度的加深,深层特征的分辨率不断降低,导致了一些信息的丢失,在边缘的精细度方面有所欠缺。
(RCF)Richer Convolutional Features
在 HED 方法中只采用每个卷积阶段最后一层的卷积特征,而没有充分利用 CNN 丰富特性的层次结构。为了解决这一问题,Liu 等以 HED 网络为基础,提出了一种新的深层结构,Richer Convolutional Features,即更丰富的卷积特征(RCF)。RCF 通过自动学习将所有卷积层的信息组合起来,从而能够获得不同尺度的更加精细的特征。
作者观点
- 传统的边缘检测算法虽然也很有前景,但是其局限性在于其得到的低层级特征信息很难去表征高层次信息;
- 大多数基于 CNNs 的边缘检测方法,仅仅只利用卷积网络的最后一层,在深层次的特征信息中缺失了浅层的细节信息,而且容易导致网络无法收敛以及梯度消失的情况。
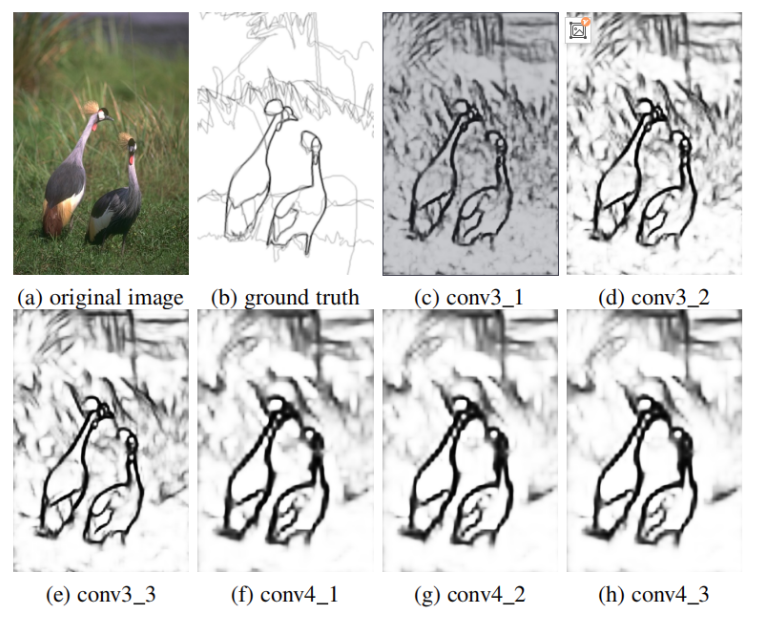
- 从上图可以看到,高层的特征逐渐变得粗糙,而且浅层的特征并未在深层特征中提现出来。可以看到,深层的信息对于图像的细节信息是模糊的,特征提取的并不充分。
- 因此,作者提出了RCF网络架构,该架构在每一个卷积层都计算其Loss,且将所有层的特征信息进行融合得到最终的特征。
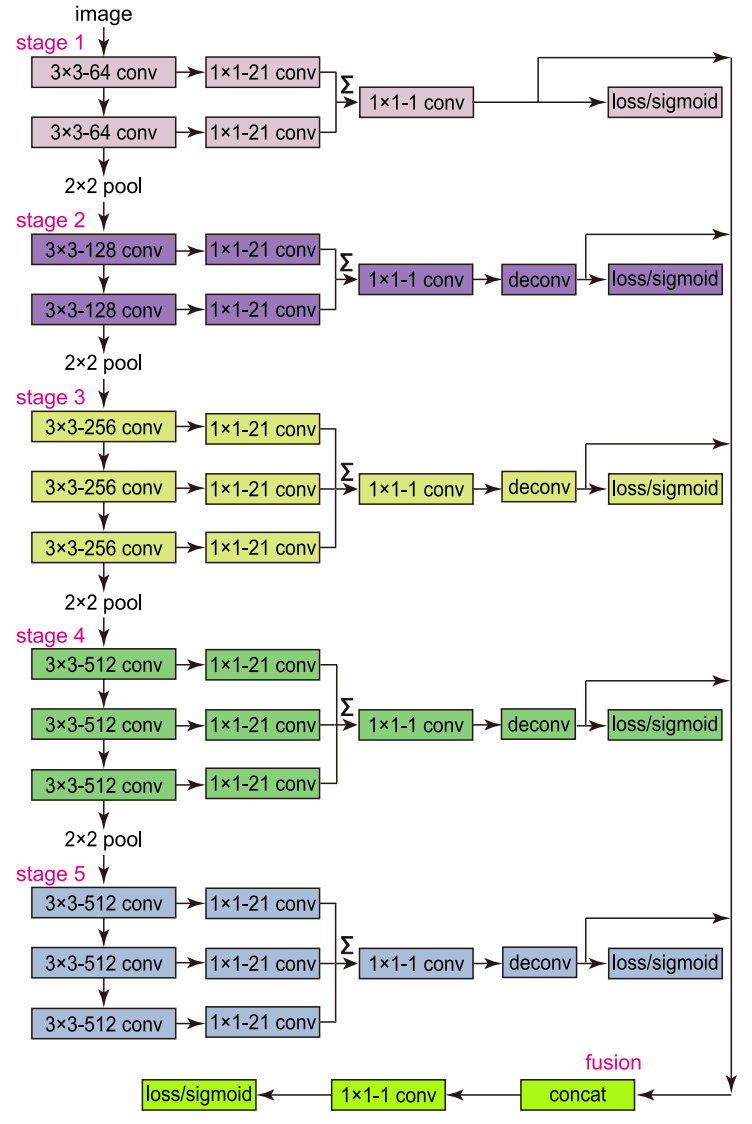
网络结构
RCF 基于 HED 网络,与 VGG16 相比,RCF 主要做了如下修改:
- 与 HED 相同,RCF 去掉了最后一个池化层和之后的全连接层,形成了全卷积网络。
- 在 VGG16 的每个卷积层之后连接一个 1×1 大小深度为 21 的卷积层,并将每一阶段的特征累积得到混合特征。
- 在每个阶段得到混合特征之后添加反卷积层进行上采样(upsample)。
- 在上采样层之后添加 loss/sigmoid 层计算损失。
- 将所有上采用层连接,对每个阶段的特征进行融合,最后再通过 loss/sigmoid 层计算损失。
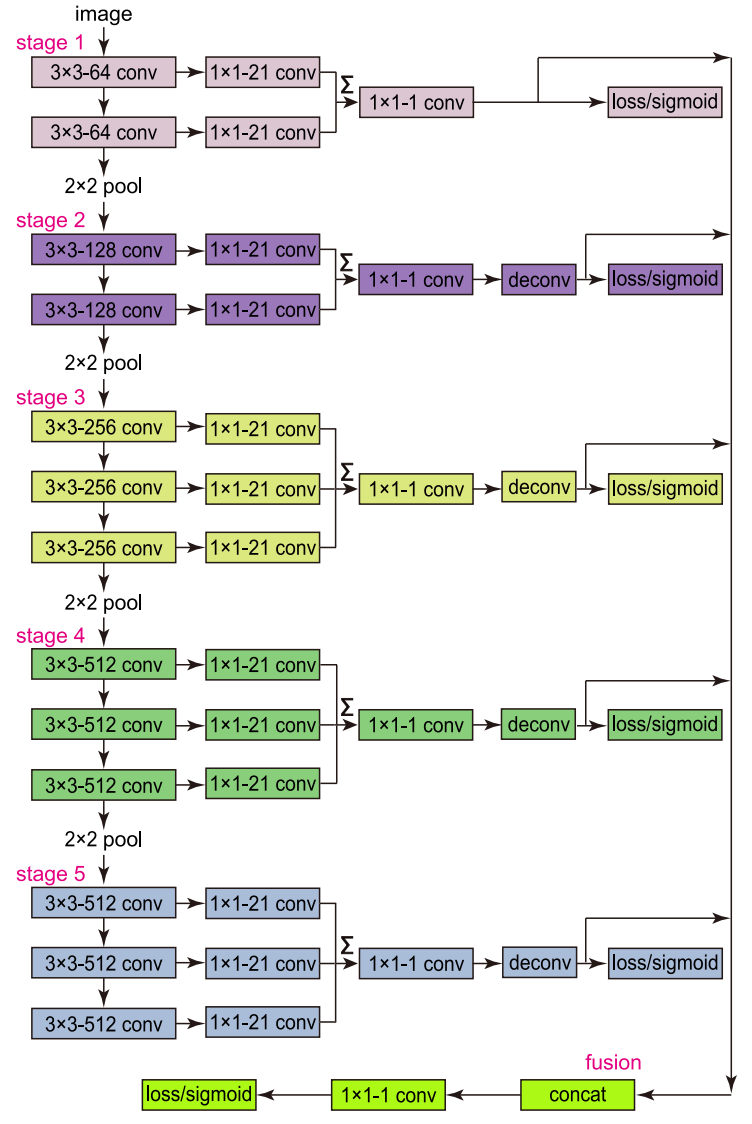
对VGG16的改动如下:
1)去除所有的全连接层和第五池化层。去除全连接层主要是为了得到全卷积网络,第五池化层对降采样特征图,不利于边缘定位。
2)对VGG16中的每个卷积层使用一个 kernel size 1 × 1 and channel depth 21 卷积层, 每个stage中所有的1 × 1 × 21卷积输出进行元素相加操作( eltwise layer),得到一个复合特征
3)每个 eltwise layer 后面加一个deconv layer 用于放大特征图尺寸的(up-sampling layer)
4)在每个 up-sampling layer 后面使用一个 cross-entropy loss / sigmoid layer
5)所有的 up-sampling layers 输出进行concatenated,随后使用一个 1×1 conv layer 进行特征图融合,最后使用 一个 cross-entropy loss / sigmoid layer 得到输出
代码
RCF vs HED
RCF与HED之间最明显区别之处在以下三个方面:
- HED对于边缘检测来说,丢失了许多非常有用的信息,因为它仅使用到VGG16中每个阶段的最后一层卷积特征。RCF与之相反,它使用了所有卷积层的特征,使得在更大的范围内捕获更多的对象或对象局部边界成为可能。
- RCF创造性的提出了一个对训练样本非常合适的损失函数。而且,本文首先将标注人数大于A的边缘像素作为正样例,为0的作为负样例。除此之外,还忽略了标注者人数小于A的边缘像素,既不作为正样例,也不作为负样例。
- 与之相反的是,HED将标注人数小于总人数一半的边缘像素作为负样例。上述做法会迷惑网络的训练,因为这些点并不是真实的分边缘像素点。
HED 方法与 RCF 方法最大的区别在于以下两个方面:
-
HED 方法只考虑了 VGG16 网络每个阶段最后一个卷积层的特征,丢失了很多信息;而 RCF 网络充分考虑了 VGG16 网络的所有卷积层,从而能够获得更加丰富的信息,在几乎没有任何花费的情况下,大幅度提高了图像边缘检测的性能。
-
新的损失函数。RCF 在 HED 损失函数的基础上进一步进行了修改,通过设置阈值 η 着重解决了多人标注情况下那些不确定是否为边缘的像素处理,提高了训练的稳定性。具体来说,RCF 将边缘像素概率高于阈值 η 的像素作为正样品,将边缘像素概率等于 0 作为负样本。而 HED 则设置阈值 η=0.5,并且将其作为正负样本的分界线。