文章目录
- 一、前言
- 1.1 垂直切分
- 1.2 垂直切分的优缺点:
- 1.3 水平切分
- 1.3.1 水平分表
- 1.3.2 水平分库
- 1.4 水平切分优缺点
- 二、Mycat 中间件实现读写分离
- 2.1 mycat
- 2.2 mycat安装
- 2.3 利用mycat实现mysql的读写分离
- 三、Mysql高可用
一、前言
刚开始我们的系统只用了单机数据库
随着用户的不断增多,考虑到系统的高可用和越来越多的用户请求,我们开始使用数据库主从架构
当用户量级和业务进一步提升后,写请求越来越多,这时我们开始使用了分库分表
如何解决? 数据切分
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机) 上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
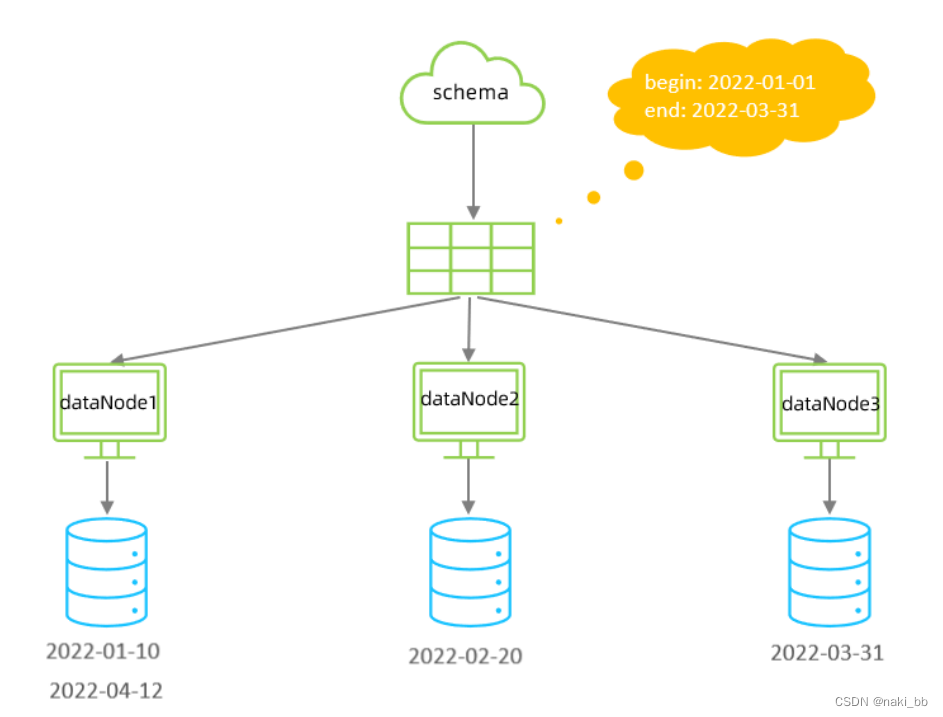
一种是按照不同的表(或者 Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据 表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小, 业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。 根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中, 对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
1.1 垂直切分
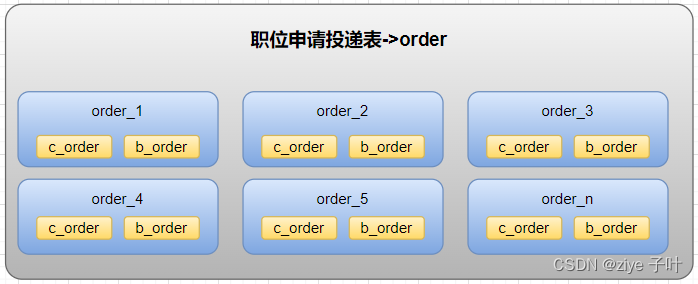
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面
需要各个表直接尽可能都合度降低,最好不要有依赖关系,因为跨表查询不方便。但通常关系型数据库很难做到耦合度降低,特别是存在复杂的join关系

1.2 垂直切分的优缺点:
优点:拆分后业务清晰,拆分规则明确系统之间整合或扩展容易数据维护简单
缺点:部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高事务处理复杂
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
1.3 水平切分
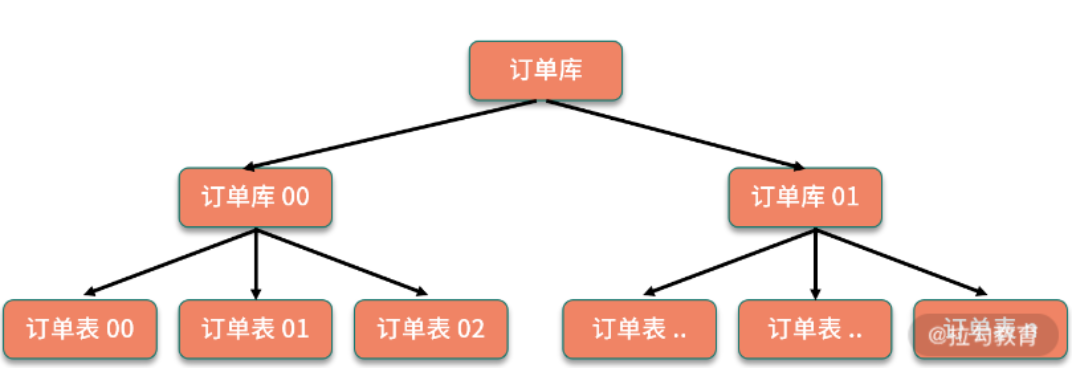
水平切分分为水平分库和水平分表
1.3.1 水平分表
按照id范围、用户来源、用户级别等规则。
针对数据量巨大的单张表(比如订单表),按照规则把一张表的数据切分到多张表里面去。
但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。

1.3.2 水平分库
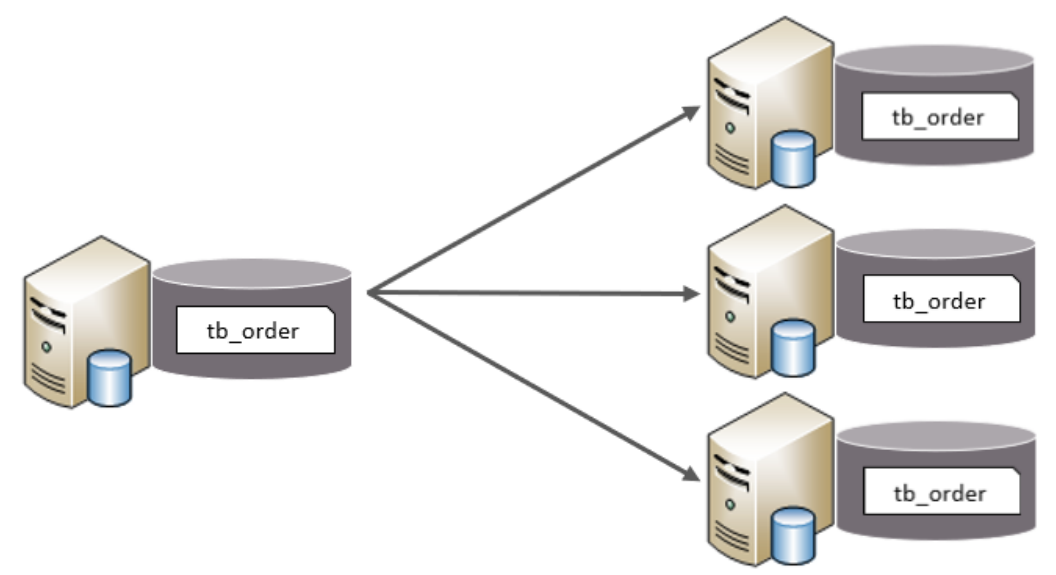
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合
不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件
资源等的瓶颈
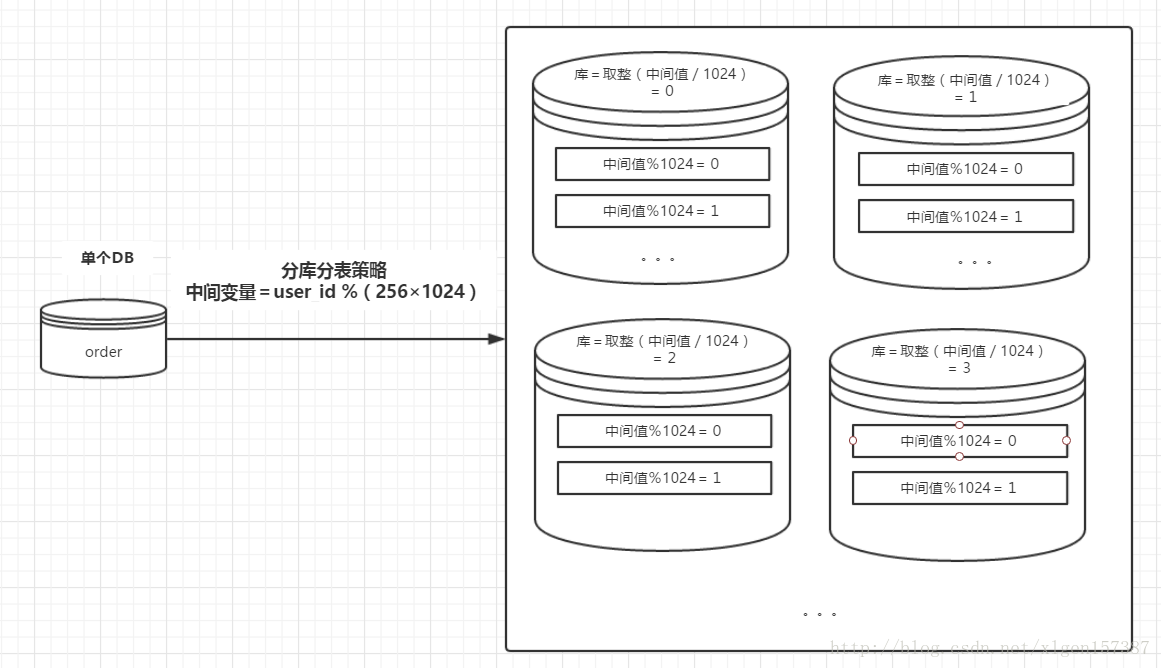
简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中

拆分数据就需要定义分片规则。
几种典型的分片规则包括:
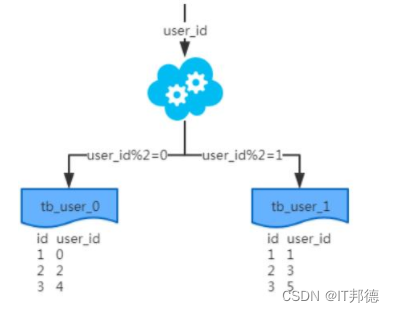
- 按照用户 ID 求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中
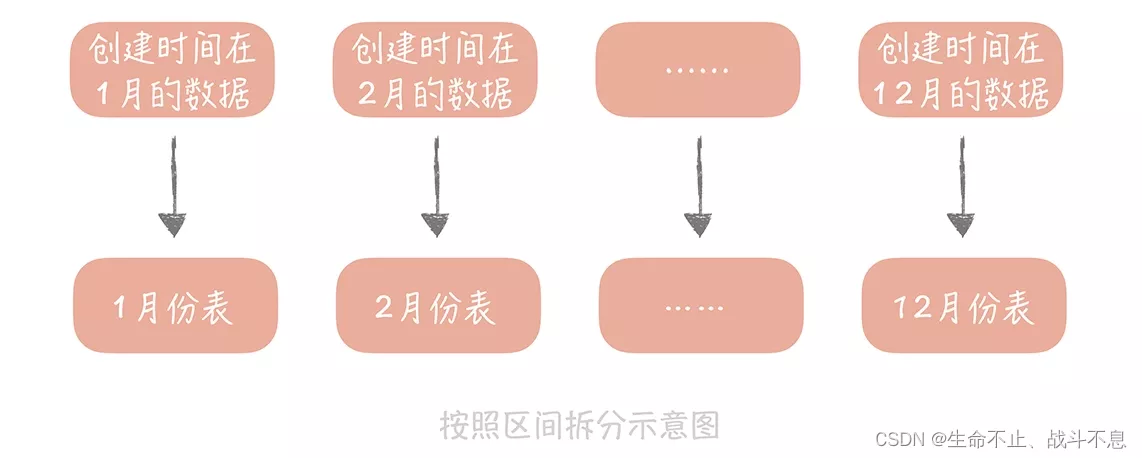
- 按照日期,将不同月甚至日的数据分散到不同的库中
- 按照某个特定的字段求模,或者根据特定范围段分散到不同的库中
切分原则都是根据业务找到适合的切分规则分散到不同的库,下面用用户 ID 求模举例:

1.4 水平切分优缺点
优点:拆分规则抽象良好,join 操作基本都可以数据库完成不存在单库大数据,高并发的性能瓶颈应用端改造较少提高了系统的稳定性跟负载能力
缺点:拆分规则难以抽象分片事务一致性难以解决数据多次扩展难度跟维护量极大跨库 join 性能较差
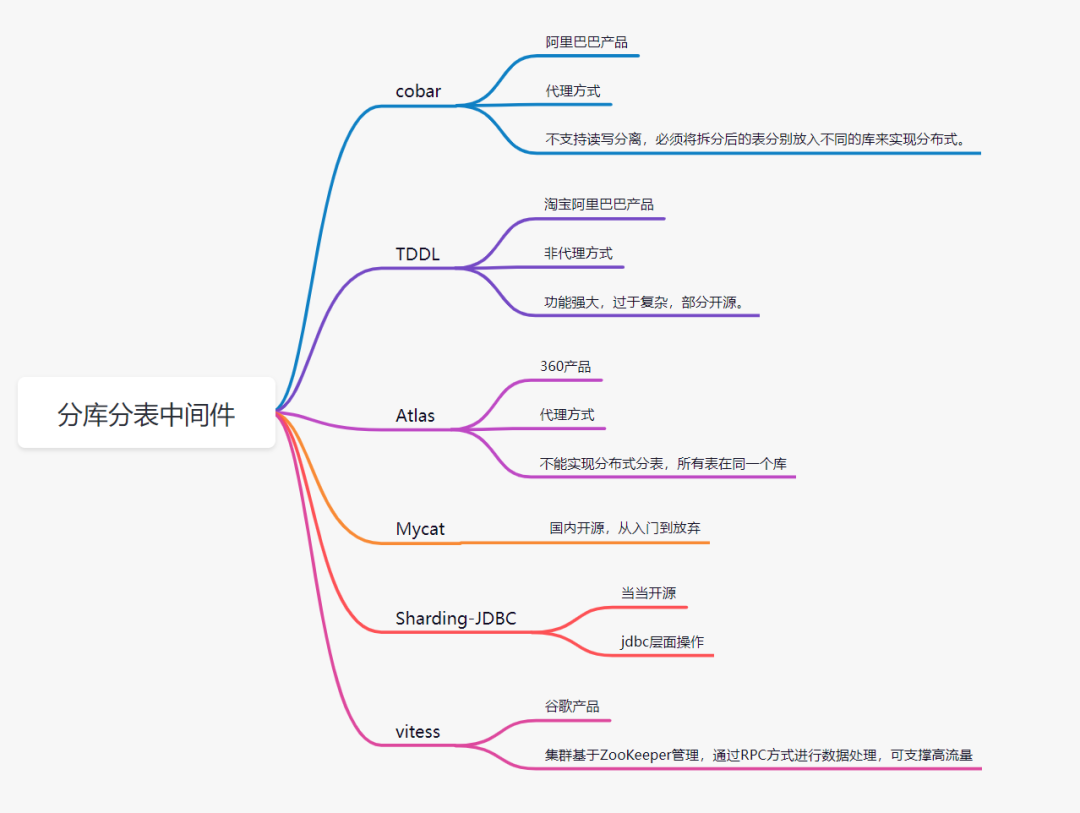
二、MySQL 中间件

- mysql-proxy:Oracle,https://downloads.mysql.com/archives/proxy/
- Atlas:Qihoo,https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
- dbproxy:美团,https://github.com/Meituan-Dianping/DBProxy
- Cetus:网易乐得,https://github.com/Lede-Inc/cetus
- Amoeba:https://sourceforge.net/projects/amoeba/
- Cobar:阿里巴巴,Amoeba的升级版, https://github.com/alibaba/cobar
- Mycat:基于Cobar http://www.mycat.io/ (原网站)
http://www.mycat.org.cn/
https://github.com/MyCATApache/Mycat-Server - ProxySQL:https://proxysql.com/
二、Mycat 中间件实现读写分离
2.1 mycat
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
为什么要用MyCat
这里要先搞清楚Mycat和MySQL的区别(Mycat的核心作用)。我们可以把上层看作是对下层的抽象,例如操作系统是对各类计算机硬件的抽象。那么我们什么时候需要抽象?假如只有一种硬件的时候,我们需要开发一个操作系统吗?再比如一个项目只需要一个人完成的时候不需要leader,但是当需要几十人完成时,就应该有一个管理者,发挥沟通协调等作用,而这个管理者对于他的上层来说就是对项目组的抽象
同样的,当我们的应用只需要一台数据库服务器的时候我们并不需要Mycat,而如果你需要分库甚至分表,这时候应用要面对很多个数据库的时候,这个时候就需要对数据库层做一个抽象,来管理这些数据库,而最上面的应用只需要面对一个数据库层的抽象或者说数据库中间件就好了,这就是Mycat的核心作用。所以可以这样理解:数据库是对底层存储文件的抽象,而Mycat是对数据库的抽象
mycat工作原理
Mycat的原理中最重要的一个动词是"拦截",它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
Mycat适用场景
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
- 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化报表系统,借助于Mycat的分表能力,处理大规模报表的统计
- 替代Hbase,分析大数据
- 作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择
MyCat的高可用性:
需要注意: 在生产环境中, Mycat节点最好使用双节点, 即双机热备环境, 防止Mycat这一层出现单点故障.
可以使用的高可用集群方式有:
- Keepalived+Mycat+Mysql
- Keepalived+LVS+Mycat+Mysql
- Keepalived+Haproxy+Mycat+Mysql
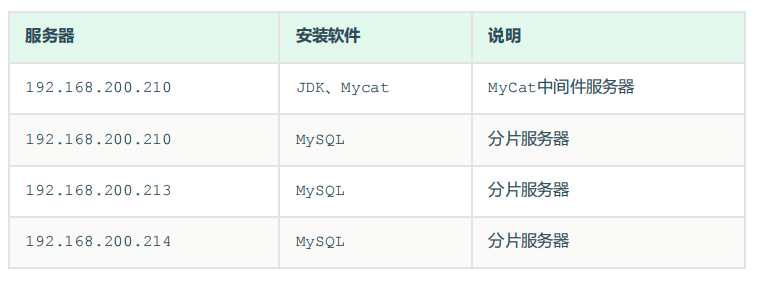
2.2 mycat安装
1.mycat基于java ,下载安装JDK
yum install java -y
2.下载mycat 下载的是编译好的,可以直接解压使用
wget http://dl.mycat.org.cn/1.6.7.4/Mycat-server-1.6.7.4-release/Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
3.解压
mkdir /apps
tar xzf Mycat-server-1.6.7.6-release-20210303094759-linux.tar.gz -C /apps/
4.mycat目录说明
mycat安装目录结构:
bin mycat命令,启动、重启、停止等
catlet catlet为Mycat的一个扩展功能
conf Mycat 配置信息,重点关注
lib Mycat引用的jar包,Mycat是java开发的
logs 日志文件,包括Mycat启动的日志和运行的日志
version.txt mycat版本说明
logs目录:
- wrapper.log mycat启动日志
- mycat.log mycat详细工作日志
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
- server.xml Mycat软件本身相关的配置文件,设置账号、参数等
- schema.xml Mycat对应的物理数据库和数据库表的配置,读写分离、高可用、分布式策略定制、节点控制
- rule.xml Mycat分片(分库分表)规则配置文件,记录分片规则列表、使用方法等启动和连接
5.启动和连接
#配置环境变量
vim /etc/profile.d/mycat.sh
PATH=/apps/mycat/bin:$PATH#启动
source /etc/profile.d/mycat.sh
mycat start
#查看日志,确定成功
[root@localhost ~]# cat /apps/mycat/logs/wrapper.log
STATUS | wrapper | 2021/11/20 23:47:34 | --> Wrapper Started as Daemon
STATUS | wrapper | 2021/11/20 23:47:34 | Launching a JVM...
INFO | jvm 1 | 2021/11/20 23:47:35 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2021/11/20 23:47:35 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2021/11/20 23:47:35 |
INFO | jvm 1 | 2021/11/20 23:47:36 | MyCAT Server startup successfully. see logs in logs/mycat.log#连接mycat:
mysql -uroot -p123456 -h 127.0.0.1 -P8066
2.3 利用mycat实现mysql的读写分离
| 服务器 | ip | 角色 |
|---|---|---|
| client | 10.0.0.63 | 客户端 |
| mycat中间件 | 10.0.0.212 | 代理 |
| master | 10.0.0.201 | 主节点 |
| slave | 10.0.0.211 | 从节点 |

1.创建mysql主从数据库
2.中间节点安装mycat
3.修改mycat端口,默认为8806
vim /apps/mycat/conf/server.xml
如下为客户连接mycat的用户名和密码,系统默认已经创建
<user name="root" defaultAccount="true"> # 连接mycat的用户名<property name="password">123456</property> # 连接mycat的密码<property name="schemas">TESTDB</property><property name="defaultSchema">TESTDB</property>逻辑数据库为TESTDB,这些信息都可以自己随意定义,读写权限都有,没有针对表做任何特殊的权限。重点关注上面这段配置,其他默认即可。
4.在后端主服务器上创建用户(可以自动同步到从上),用于mycat可以连接它
mysql> create user 'root'@'10.0.0.%' IDENTIFIED BY '123456' ;
mysql> grant all on *.* to 'root'@'10.0.0.%';
5.修改schema.xml文件,实现读写分离策略
[root@localhost ~]# cat /apps/mycat/conf/schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema><dataNode name="dn1" dataHost="localhost1" database="hellodb" /><dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat> <!--心跳检测--><writeHost host="host1" url="10.0.0.201:3306" user="root" password="123456"><readHost host="host2" url="10.0.0.211:3306" user="root" password="123456" /></writeHost></dataHost>
</mycat:schema>上面配置中,balance改为1,表示读写分离。以上配置达到的效果就是10.0.0.201为主库,10.0.0.211为从库
注意:要保证能使用root/123456权限成功登录10.0.0.201和10.0.0.211机器上面的mysql数据库。同时,也一定要授权mycat机器能使用root/123456权限成功登录这两台机器的mysql数据库!!这很重要,否则会导致登录mycat后,对库和表操作失败!
6.在客户端测试连接mycat服务器
[root@zabbix-db ~]# mysql -uroot -p123456 -h10.0.0.212
mysql> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+mysql> use TESTDB
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> show tables;
+-------------------+
| Tables_in_hellodb |
+-------------------+
| classes |
| coc |
| courses |
| scores |
| students |
| teachers |
| toc |
+-------------------+
7.通过通用日志确认实现读写分离
在mysql中查看通用日志方式
show variables like 'general_log'; #查看日志是否开启
set global general_log=on; #开启日志功能
show variables like 'general_log_file'; #查看日志文件保存位置
set global general_log_file='tmp/general.log'; #设置日志文件保存位置
在主和从服务器分别启用通用日志,查看读写分离
mysql> select @@server_id;
+-------------+
| @@server_id |
+-------------+
| 2 |
+-------------+在客户端查询,按理说应该在从节点上记录日志
mysql> select * from teachers;在从节点查看日志
2021-11-20T09:12:42.797953Z 17 Query select * from teachers
2021-11-20T09:12:49.969072Z 18 Query select user()在客户端插入数据,按理说应该只在主节点记录日志
mysql> insert into teachers (name,age) values ('MM',18);在主节点查看日志
2021-11-20T09:15:35.501675Z 29 Query SET names utf8;
2021-11-20T09:15:35.503203Z 29 Query insert into teachers (name,age) values ('MM',18)
2021-11-20T09:15:39.954650Z 17 Query select user()停止从节点,mycat自动调度读请求至主节点,但是停止主节点,mycat不会自动调度写请求至从节点
三、Mysql高可用
MHA:Master High Availability,对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,出于机器成本的考虑,淘宝进行了改造,目前淘宝TMHA已经支持一主一从

- MHA利用 SELECT 1 As Value 指令判断master服务器的健康性,一旦master 宕机,MHA 从宕机崩溃的master保存二进制日志事件(binlog events)
- 识别含有最新更新的slave(数据同步最多的slave)
- 应用差异的中继日志(relay log)到其他的slave
- 应用从master保存的二进制日志事件(binlog events)到所有slave节点
- 提升一个slave为新的master
- 使其他的slave连接新的master进行复制
- 故障服务器自动被剔除集群(masterha_conf_host),将配置信息去掉
- MHA是一次性的高可用性解决方案,Manager会自动退出
选举新的Master
- 如果设定权重(candidate_master=1),按照权重强制指定新主,但是默认情况下如果一个slave落后master 二进制日志超过100M的relay logs,即使有权重,也会失效.如果设置check_repl_delay=0,即使落后很多日志,也强制选择其为新主
- 如果从库数据之间有差异,最接近于Master的slave成为新主
- 如果所有从库数据都一致,按照配置文件顺序最前面的当新主
数据恢复
当主服务器的SSH还能连接,从库对比主库position 或者GTID号,将二进制日志保存至各个从节点并且应用(执行save_binary_logs 实现)当主服务器的SSH不能连接, 对比从库之间的relaylog的差异(执行apply_diff_relay_logs[实现])
注意:
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL的半同步复制
MHA软件由两部分组成,Manager工具包和Node工具包
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 故障转移(自动或手动)
masterha_conf_host 添加或删除配置的server信息
masterha_stop --conf=app1.cnf 停止MHA
masterha_secondary_check 两个或多个网络线路检查MySQL主服务器的可用

安装步骤,在MHA管理端安装manager和node
在其他节点安装node