介绍
问题分析
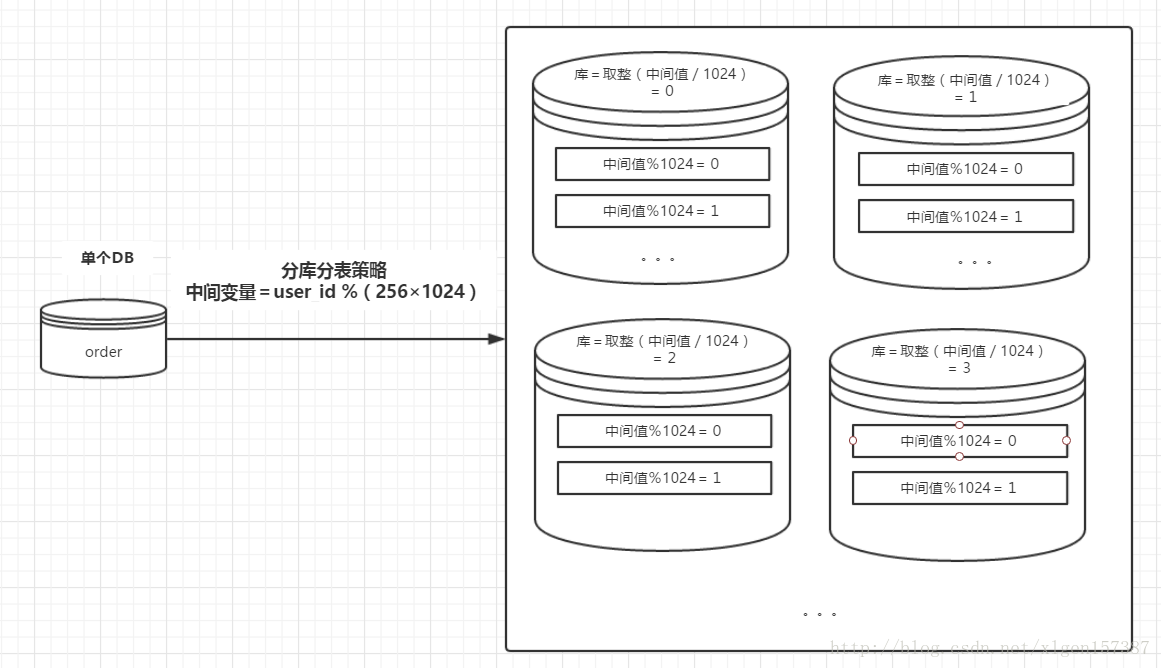
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
- IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。 请求数据太多,带宽不够,网络IO瓶颈。
- CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源,请求数太多,CPU出现瓶颈。
为了解决上述问题,我们需要对数据库进行分库分表处理。
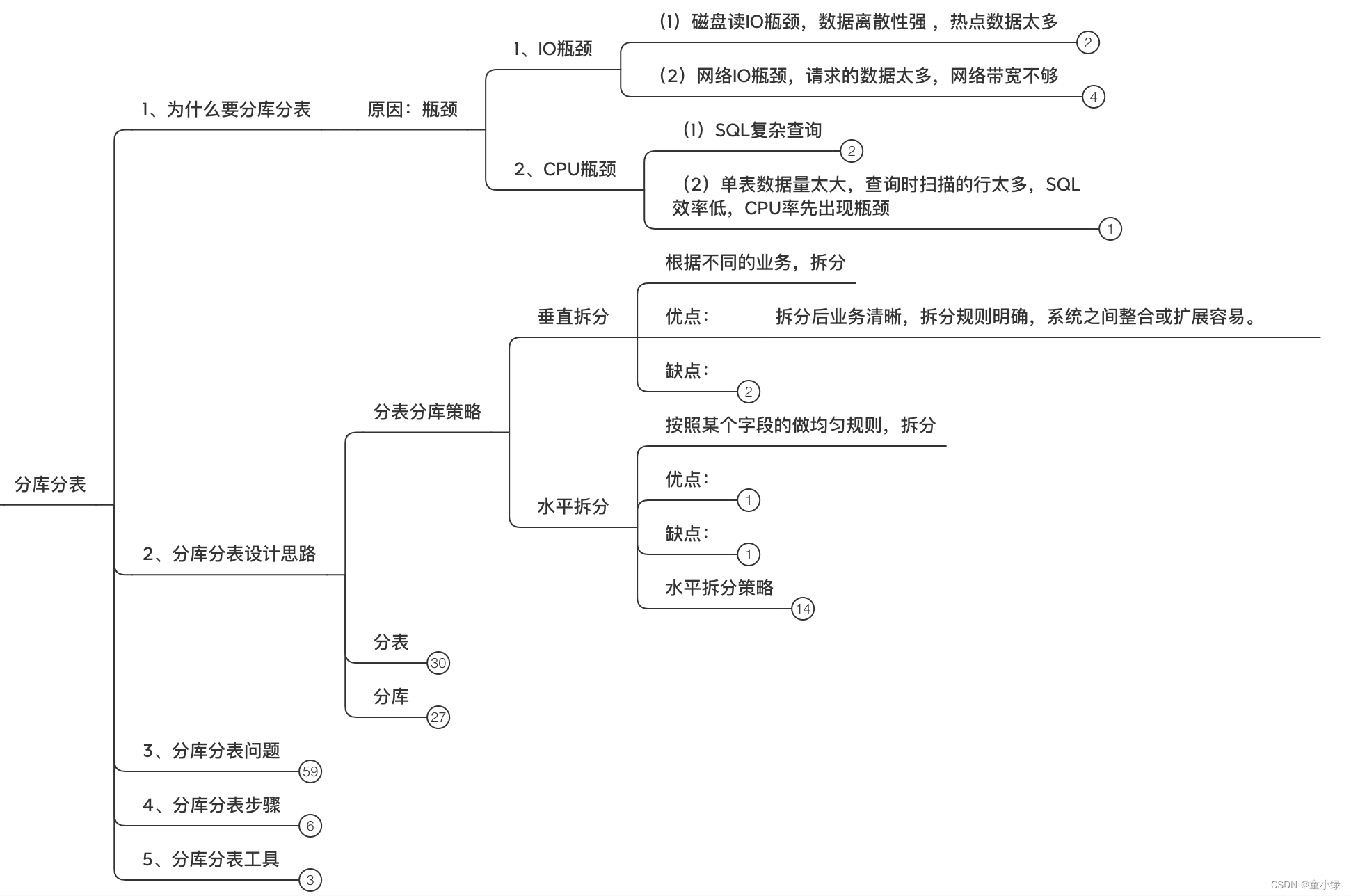
拆分策略
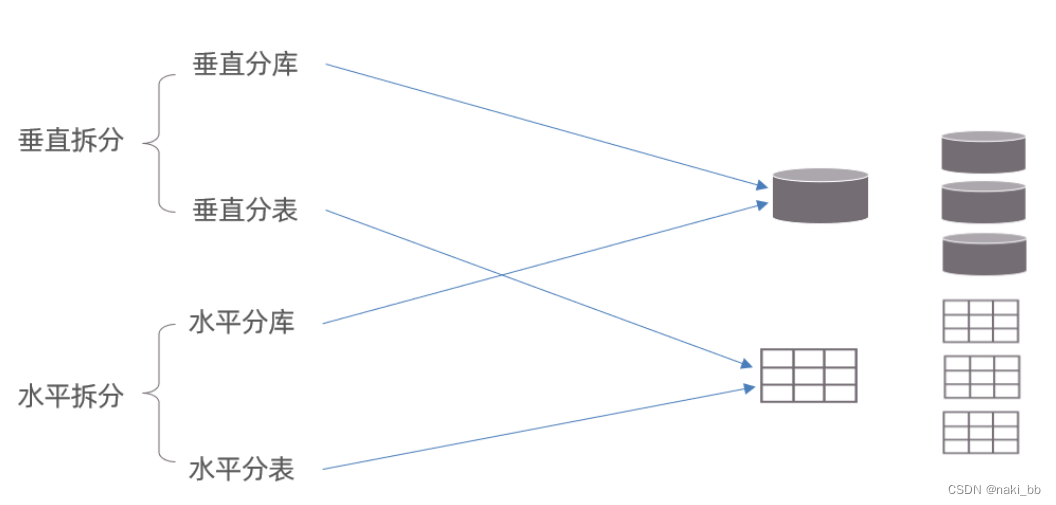
垂直拆分
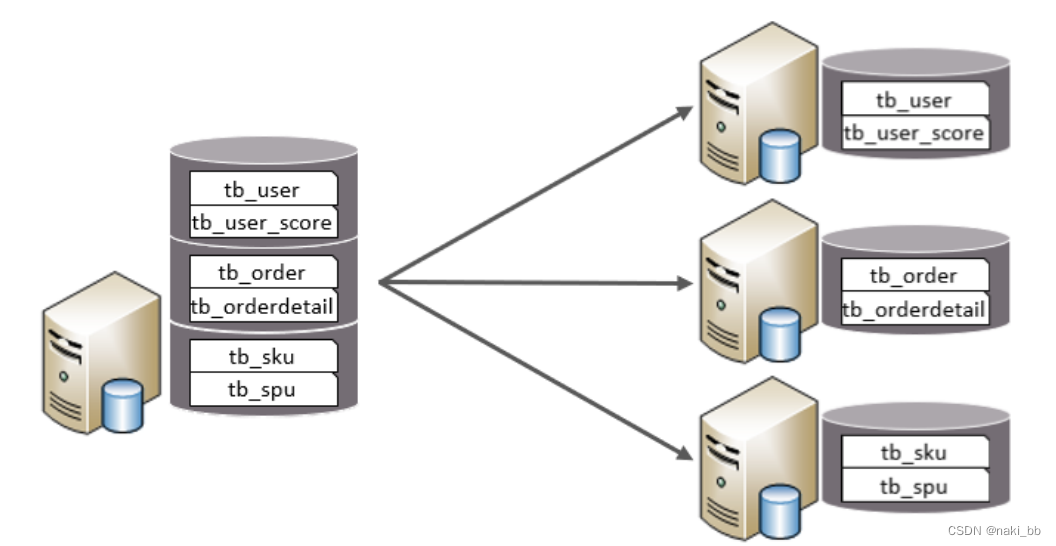
垂直分库:以表为依据,根据业务将不同表拆分到不同库中
- 每个库的表结构都不一样。
- 每个库的数据也不一样。
- 所有库的并集是全量数据。
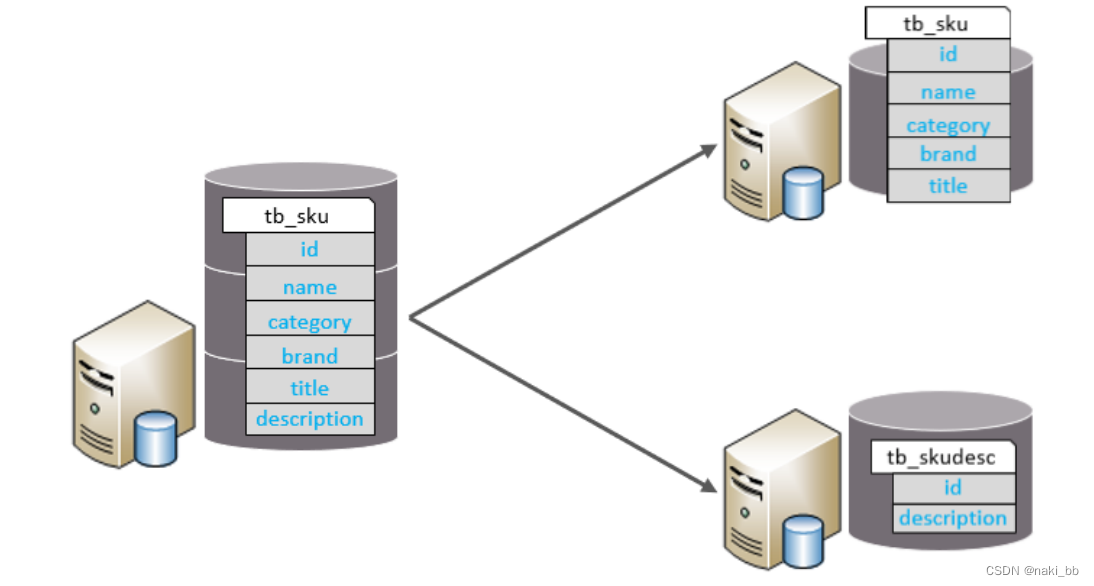
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
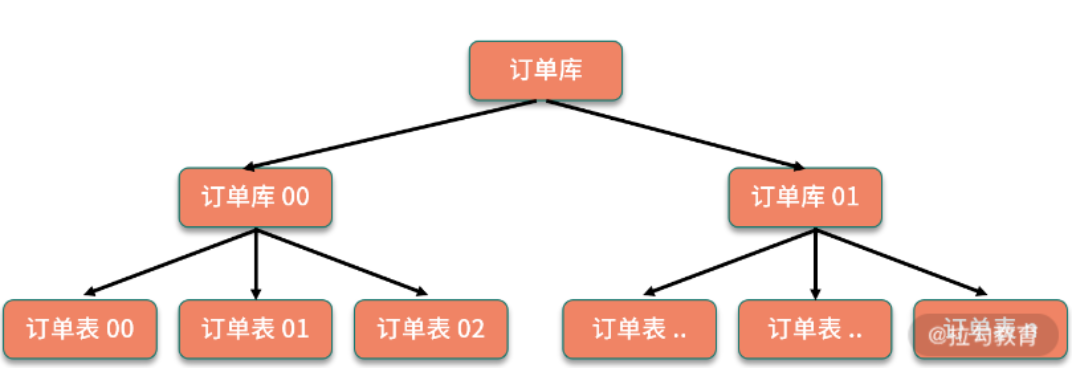
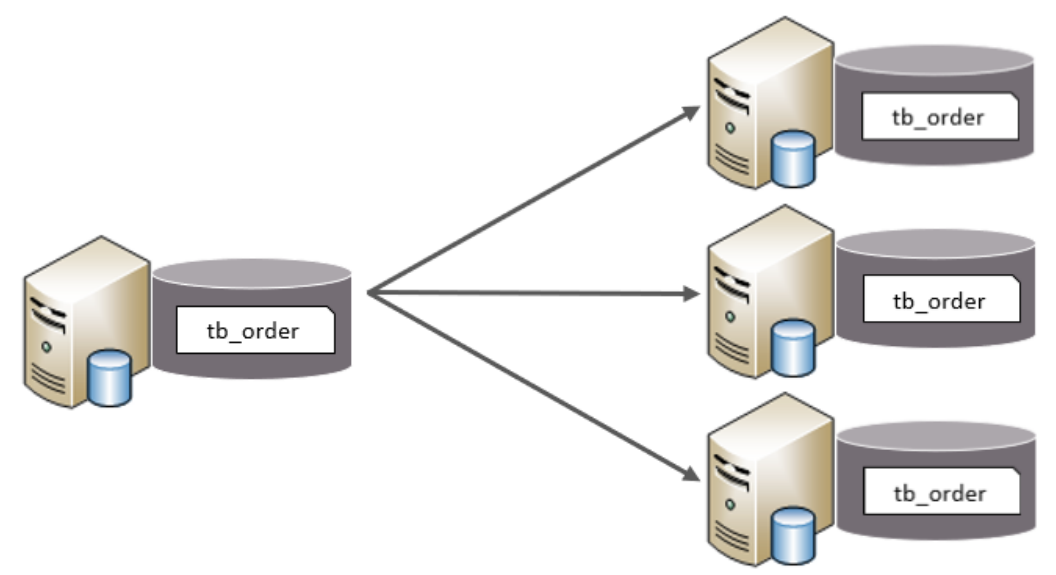
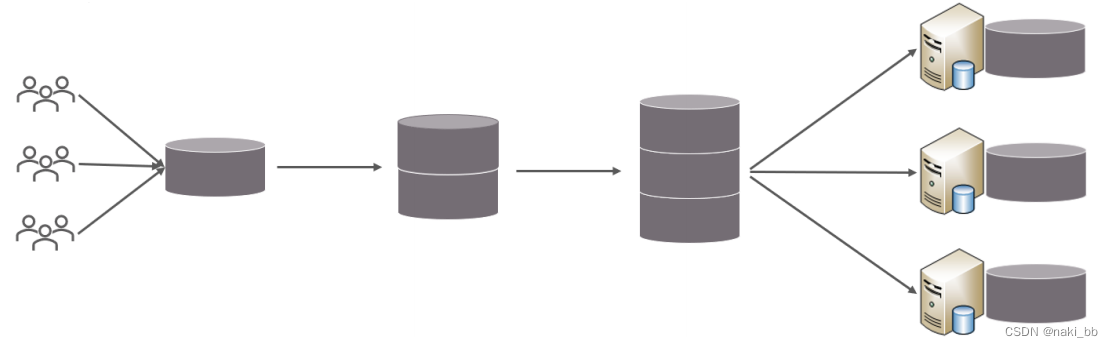
水平拆分
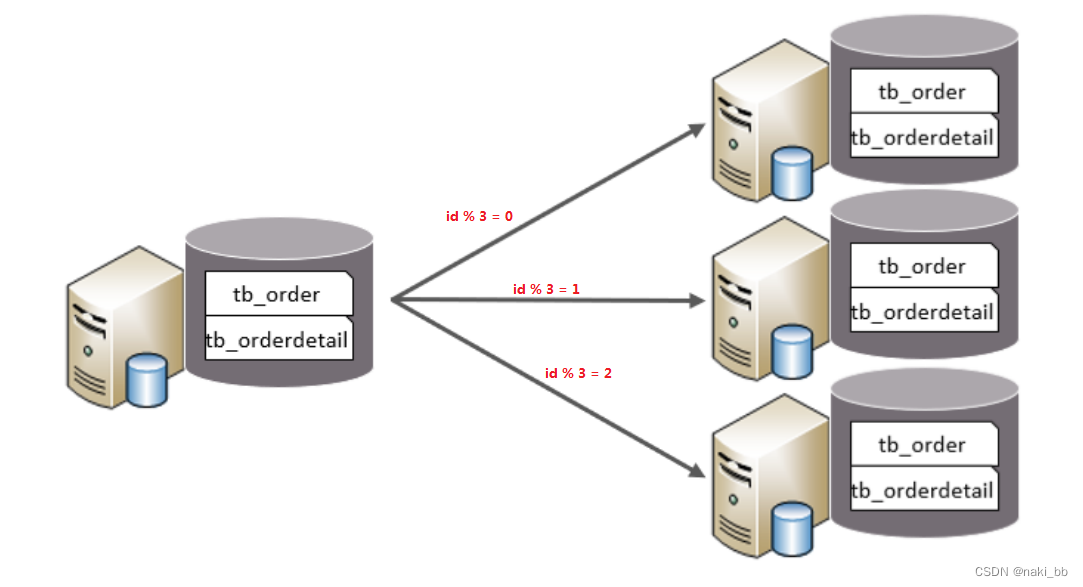
- 每个库的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全量数据。
水平分表
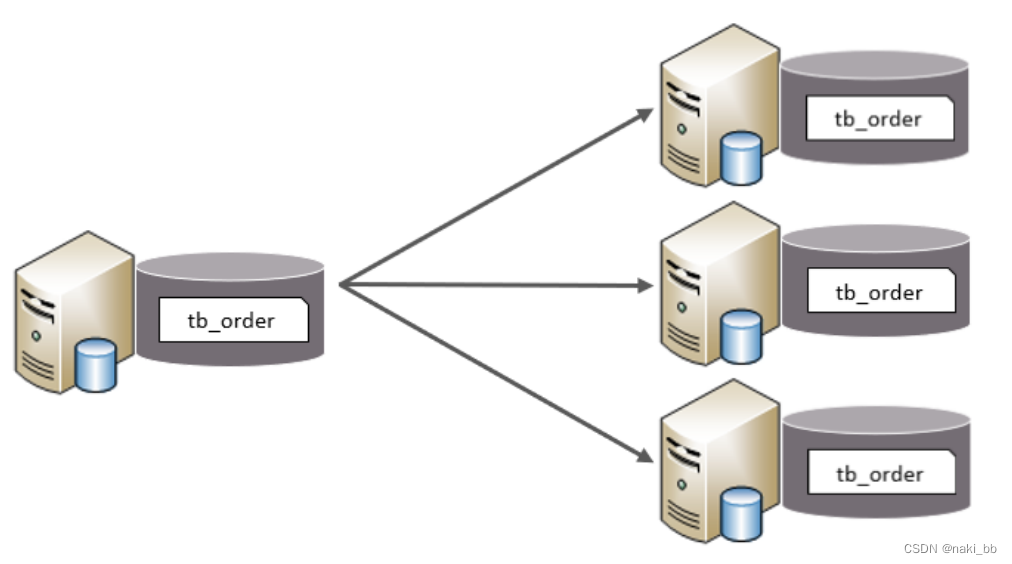
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
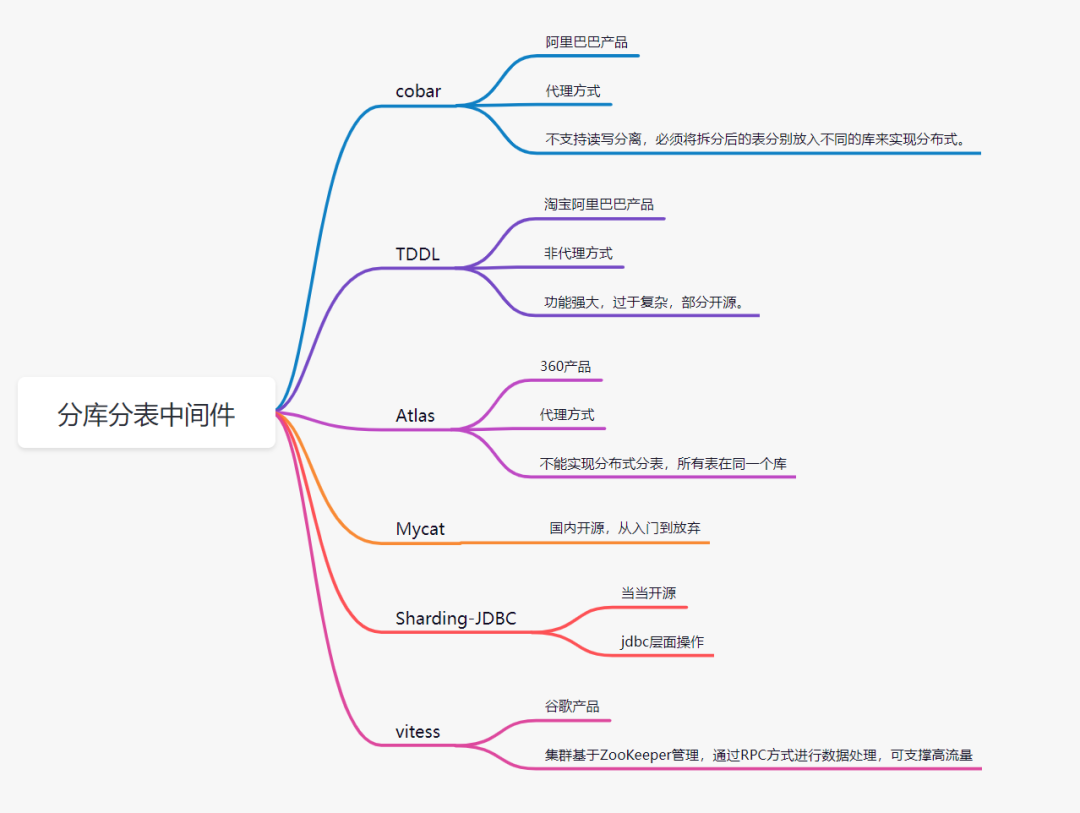
实现技术
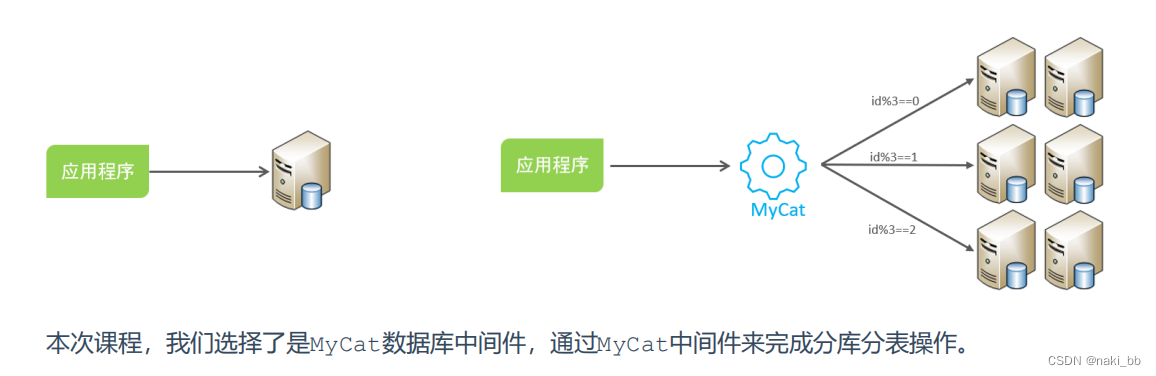
- shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
- MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者。
MyCat
介绍
- 性能可靠稳定
- 强大的技术团队
- 体系完善
- 社区活跃
下载,安装
MyCat 下载,安装_naki_bb的博客-CSDN博客
- MySQL
- JDK
- Mycat
MyCat 入门
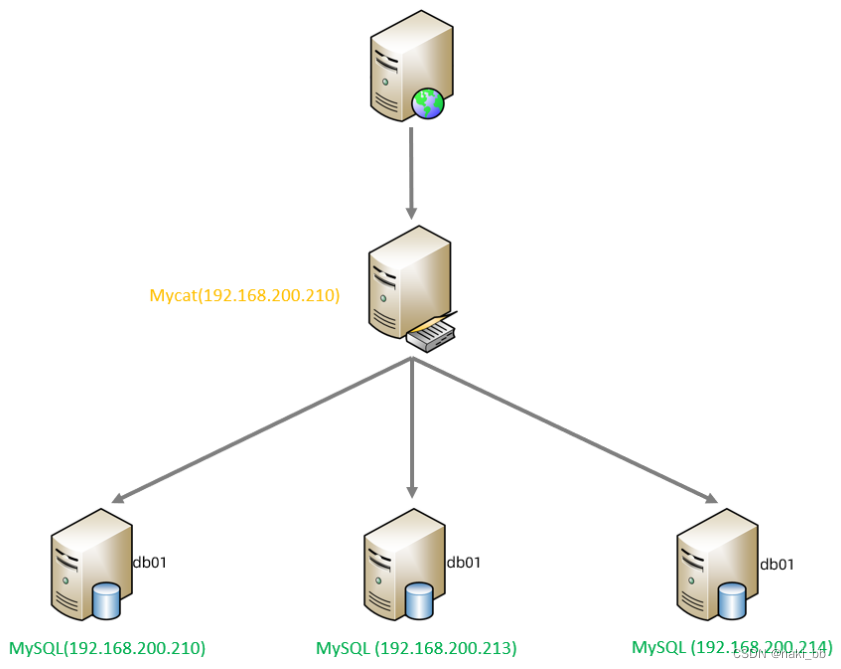
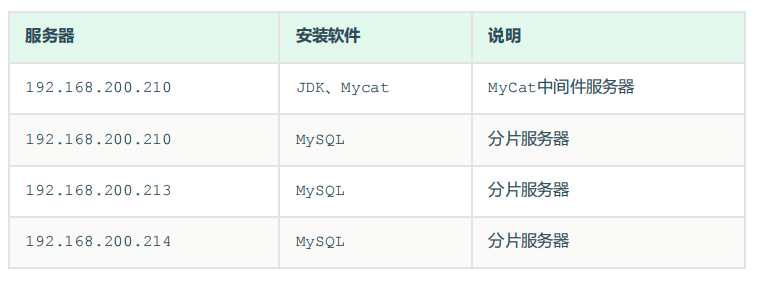
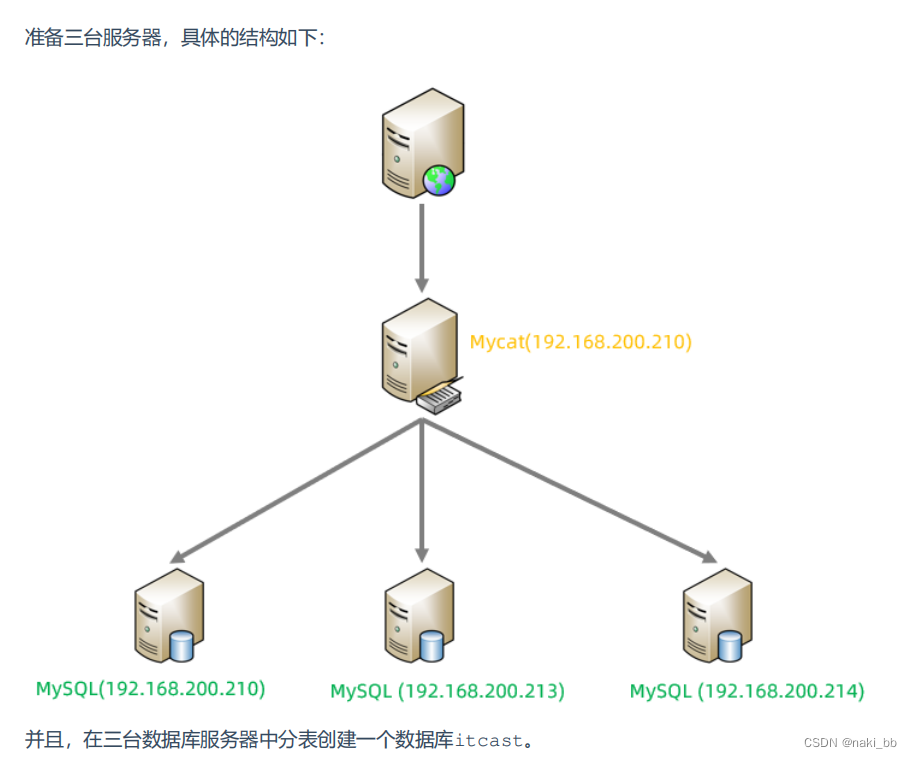
| 服务器 | 安装软件 | 说明 |
| 192.168.200.210 | JDK 、 Mycat | MyCat 中间件服务器 |
| 192.168.200.210 | MySQL | 分片服务器 |
| 192.168.200.213 | MySQL | 分片服务器 |
| 192.168.200.214 | MySQL | 分片服务器 |
# 开放指定3306端口
firewall-cmd --zone=public --add-port=3306/tcp -permanent
firewall-cmd -reload#关闭防火墙
systemctl stop firewalld
systemctl disable firewalldMycat 入门 - 配置
schema.xml
路径: 安装目录的/conf , /usr/local/mycat/conf

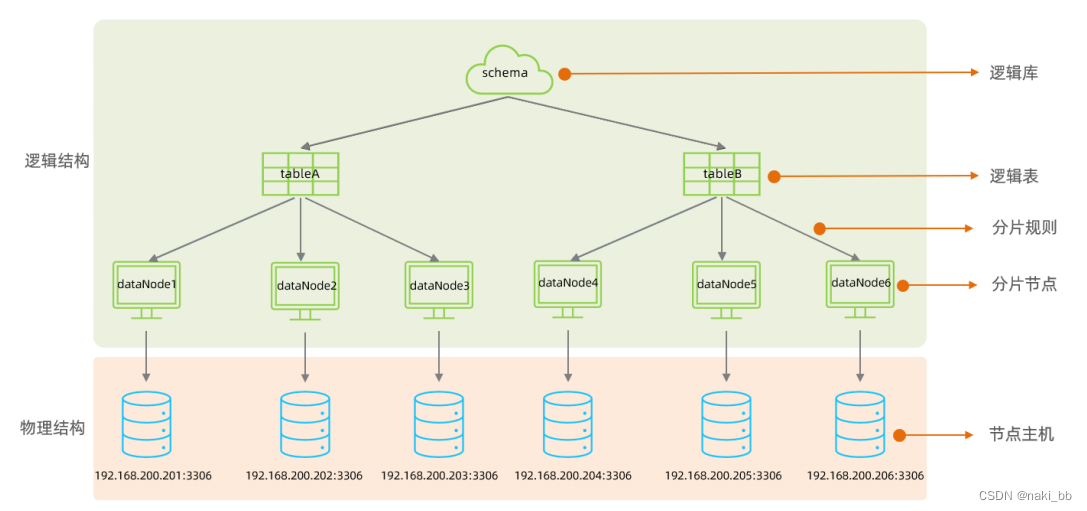
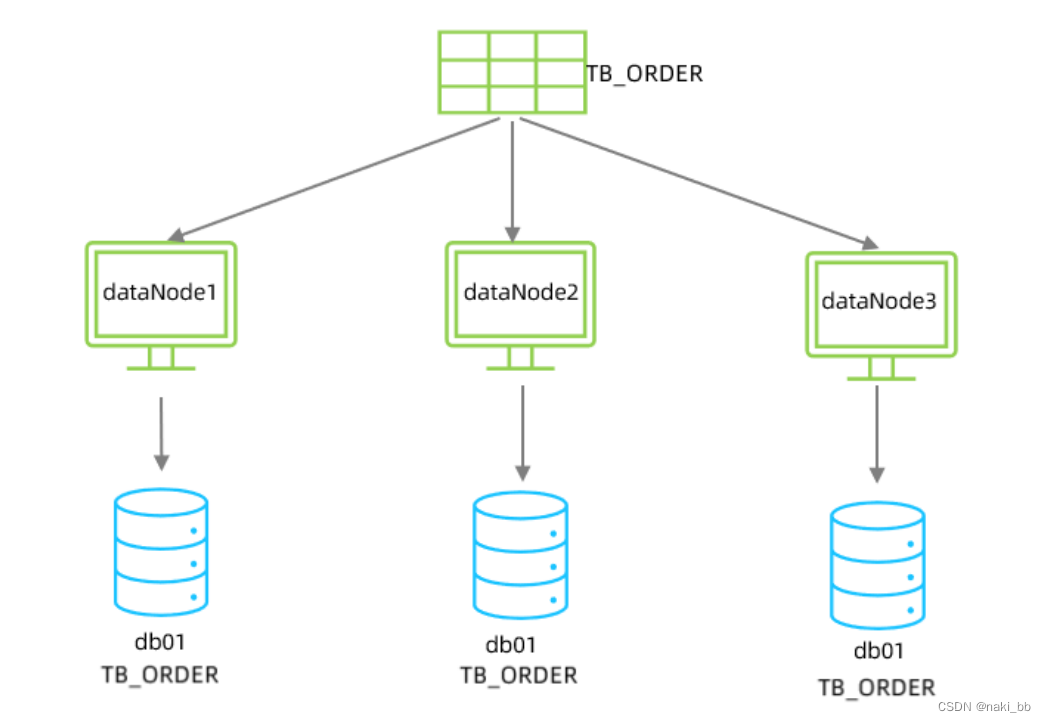
在schema.xml中配置逻辑库、逻辑表、数据节点、节点主机等相关信息。具体的配置如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><!-- 设置逻辑库信息 --><schema name="DB01" checkSQLschema="true" sqlMaxLimit="100"><!-- 设置逻辑表,分片节点,分片规则 --><table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /></schema><!-- 设置分片节点信息,包含数据库的连接信息以及选择的数据库 --><dataNode name="dn1" dataHost="dhost1" database="db01" /><dataNode name="dn2" dataHost="dhost2" database="db01" /><dataNode name="dn3" dataHost="dhost3" database="db01" /><!-- 设置数据库信息 --><dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- 设置连接信息 --><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /></dataHost><dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /></dataHost><dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" /></dataHost>
</mycat:schema>server.xml
路径: 安装目录的/conf , /usr/local/mycat/conf
<!-- 设置mycat root用户密码以及权限 -->
<user name="root" defaultAccount="true"><!-- 密码 --><property name="password">123456</property><!-- 可以操作的逻辑库 --><property name="schemas">DB01</property><!-- 表级 DML 权限设置 --><!-- <privileges check="true"> <schema name="DB01" dml="0110" > <table name="TB_ORDER" dml="1110"></table> </schema> </privileges> -->
</user>
<!-- 设置mycat user用户密码以及权限 -->
<user name="user"><!-- 密码 --><property name="password">123456</property><!-- 可以操作的逻辑库 --><property name="schemas">DB01</property><!-- user只有DB01逻辑库的只读权限 --><property name="readOnly">true</property>
</user>Mycat 入门 - 启动
#启动
bin/mycat start #停止
bin/mycat stop
Mycat 入门 - 测试
1.连接mycat
mysql -h 192.168.200.210 -P 8066 -uroot -p123456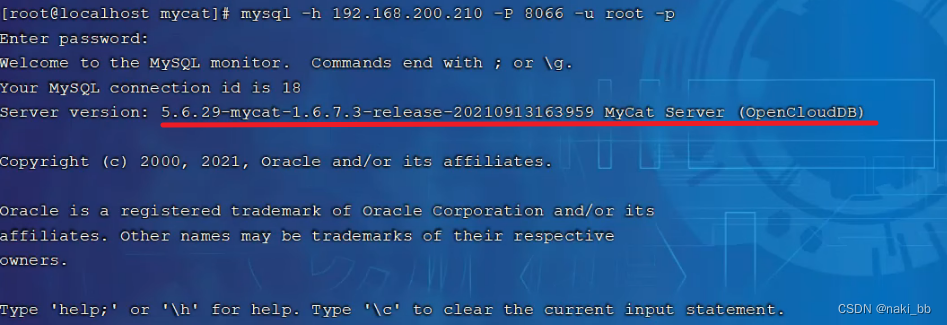
2.数据测试
-- 创建表 三个数据库节点会同时创建
CREATE TABLE TB_ORDER
(id BIGINT(20) NOT NULL,title VARCHAR(100) NOT NULL,PRIMARY KEY (id)
) ENGINE = INNODBDEFAULT CHARSET = utf8; -- 插入数据会落到 第一个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(1,'goods1');
-- 插入数据会落到 第一个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(2,'goods2');
-- 插入数据会落到 第一个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(3,'goods3');
-- 插入数据会落到 第一个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(5000000,'goods5000000'); -- 插入数据会落到 第二个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(5000001,'goods5000001');
-- 插入数据会落到 第二个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(10000000,'goods10000000');-- 插入数据会落到 第三个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(10000001,'goods10000001');
-- 插入数据会落到 第三个数据库节点
INSERT INTO TB_ORDER(id,title) VALUES(15000000,'goods15000000'); -- 会报错
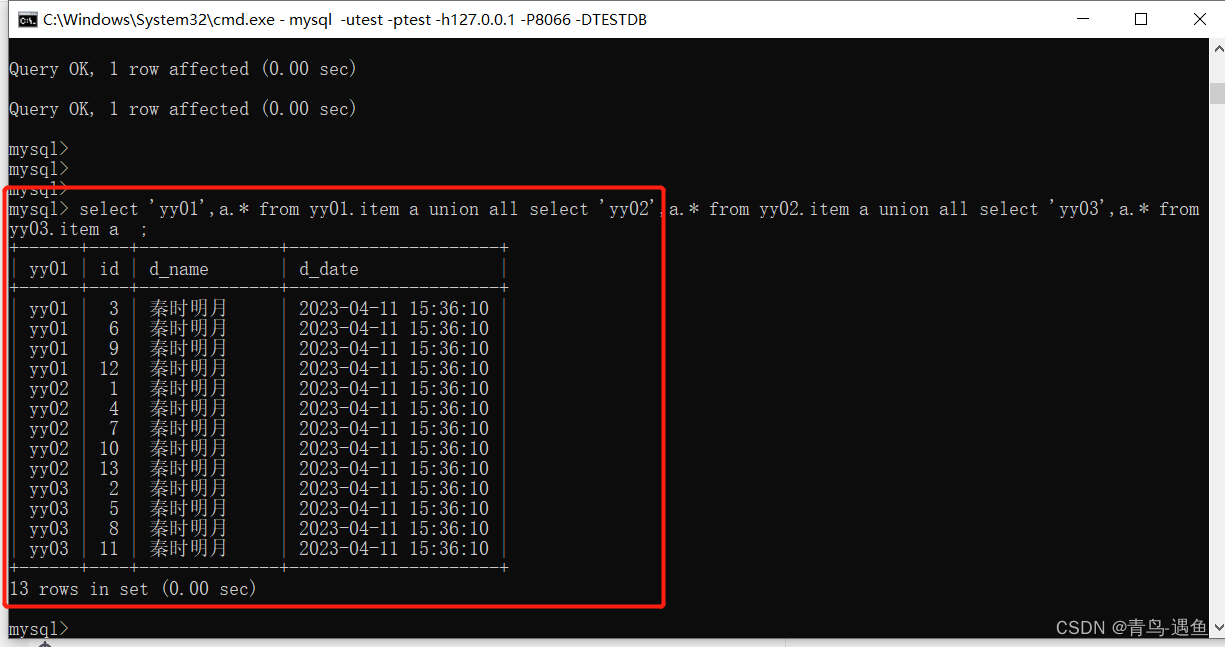
INSERT INTO TB_ORDER(id,title) VALUES(15000001,'goods15000001');- 如果id的值在1-500w之间,数据将会存储在第一个分片数据库中。
- 如果id的值在500w-1000w之间,数据将会存储在第二个分片数据库中。
- 如果id的值在1000w-1500w之间,数据将会存储在第三个分片数据库中。
- 如果id的值超出1500w,在插入数据时,将会报错。
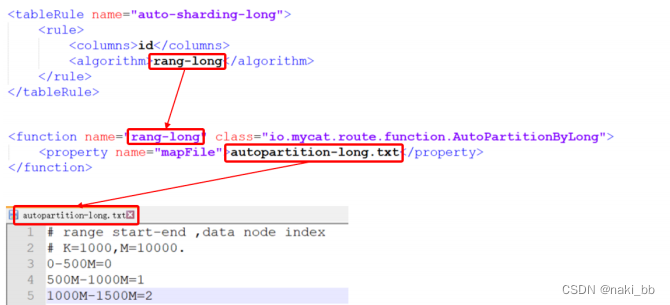
而我们选择的 “auto-sharding-long” 分片规则如下
0-500W在第一个分片,500W-1000W在第二个分片,1000W-1200W在第三个分片,配置的上限只有1500W,如果超过这个限制就会报错.
Mycat配置
schema.xml

- schema标签
- datanode标签
- datahost标签
schema标签
1. 定义逻辑库

- name:指定自定义的逻辑库库名
- checkSQLschema:在SQL语句操作时指定了数据库名称,执行时是否自动去除;true:自动去除,false:不自动去除
- sqlMaxLimit:如果未指定limit进行查询,列表查询模式查询多少条记录
2.schema 中的table定义逻辑表

- name:定义逻辑表表名,在该逻辑库下唯一
- dataNode:定义逻辑表所属的dataNode,该属性需要与dataNode标签中name对应;多个 dataNode逗号分隔
- rule:分片规则的名字,分片规则名字是在rule.xml中定义的
- primaryKey:逻辑表对应真实表的主键
- type:逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,就是普通表;全局表,配置为 global

- name:定义数据节点名称
- dataHost:数据库实例主机名称,引用自 dataHost 标签中name属性
- database:定义分片所属数据库
datahost标签

- name:唯一标识,供上层标签使用
- maxCon/minCon:最大连接数/最小连接数
- balance:负载均衡策略,取值 0,1,2,3
- writeType:写操作分发方式(0:写操作转发到第一个writeHost,第一个挂了,切换到第二 个;1:写操作随机分发到配置的writeHost)
- dbDriver:数据库驱动,支持 native、jdbc
rule.xml
server.xml
server.xml配置文件包含了MyCat的系配置信息,主要有两个重要的标签:system、user
1.system标签

主要配置MyCat中的系统配置信息,对应的系统配置项及其含义,如下:
| 属性 | 取值 | 含义 |
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ; 开启之后, MyCat会自动统计SQL语句的执行情况 ; mysql -h 127.0.0.1 -P 9066 -u root -p 查看MyCat执行的SQL, 执行效率比较低的SQL , SQL的整体执行情况、读写比例等 ; show @@sql ; show @@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文件,1 为数据库方式,2 为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ或者 mycatseq进入序列匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器, 在MyCat1.3后增加了Druid解析器, 所以要设置defaultSqlParser属性来指定默认的解析器; 解析器有两个 : druidparser 和 fdbparser, 在MyCat1.4之后,默认是druidparser, fdbparser已经废除了 | |
| processors | 1,2.... | 指定系统可用的线程数量, 默认值为CPU核心 x 每个核心运行线程数量; processors 会影响processorBufferPool, processorBufferLocalPercent, processorExecutor属性, 所有, 在性能调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节, 也会影响BufferPool长度, 如果一次性获取字节过多而导致buffer不够用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享 businessExecutor固定线程池的大小; MyCat把异步任务交给 businessExecutor线程池中, 在新版本的MyCat中这个连接池使用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收, 默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为 REPEATED_READ , 对应数字为3 READ_UNCOMMITED=1; READ_COMMITTED=2; REPEATED_READ=3; SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时,将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口, 默认9066 |
2.user标签
配置MyCat中的用户、访问密码,以及用户针对于逻辑库、逻辑表的权限信息,具体的权限描述方式及配置说明如下:

privileges 标签的注释放开。 在 privileges 下的schema标签中配置的dml属性配置的是逻辑库的权限。 在privileges的schema下的table标签的dml属性中配置逻辑表的权限。
MyCat分片
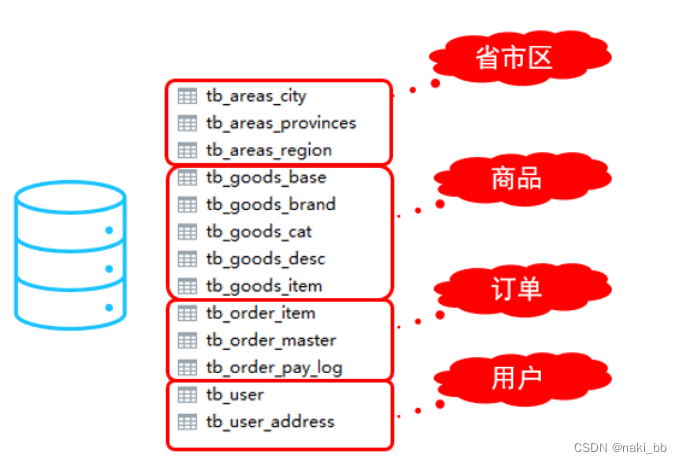
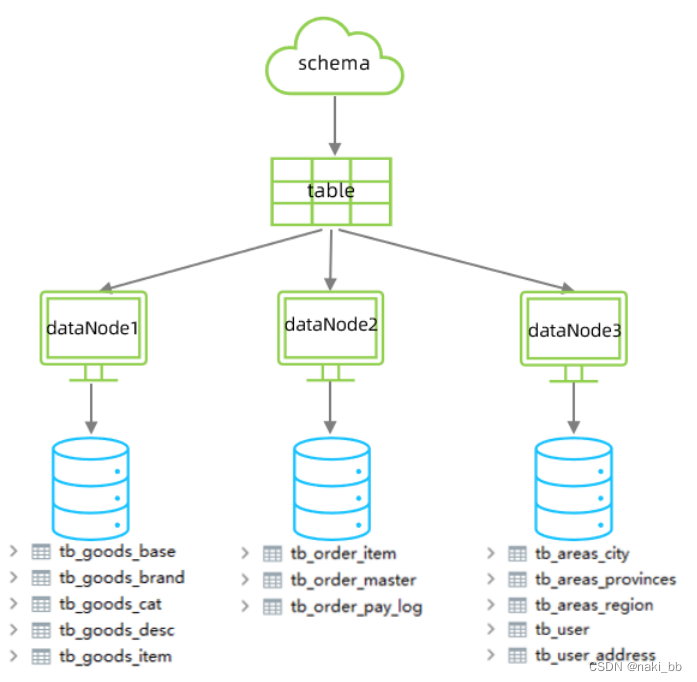
垂直拆分
配置
schema.xml
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_goods_base" dataNode="dn1" primaryKey="id" /><table name="tb_goods_brand" dataNode="dn1" primaryKey="id" /><table name="tb_goods_cat" dataNode="dn1" primaryKey="id" /><table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id" /><table name="tb_goods_item" dataNode="dn1" primaryKey="id" /><table name="tb_order_item" dataNode="dn2" primaryKey="id" /><table name="tb_order_master" dataNode="dn2" primaryKey="order_id" /><table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" /><table name="tb_user" dataNode="dn3" primaryKey="id" /><table name="tb_user_address" dataNode="dn3" primaryKey="id" /><table name="tb_areas_provinces" dataNode="dn3" primaryKey="id"/><table name="tb_areas_city" dataNode="dn3" primaryKey="id"/><table name="tb_areas_region" dataNode="dn3" primaryKey="id"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping" />
<dataNode name="dn2" dataHost="dhost2" database="shopping" />
<dataNode name="dn3" dataHost="dhost3" database="shopping" />
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" />
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" />
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234" />
</dataHost>server.xml
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">SHOPPING</property><!-- 表级 DML 权限设置 --><!-- <privileges check="true"> <schema name="DB01" dml="0110" > <table name="TB_ORDER" dml="1110"></table> </schema> </privileges> -->
</user>
<user name="user"><property name="password">123456</property><property name="schemas">SHOPPING</property><property name="readOnly">true</property>
</user>重启mycat
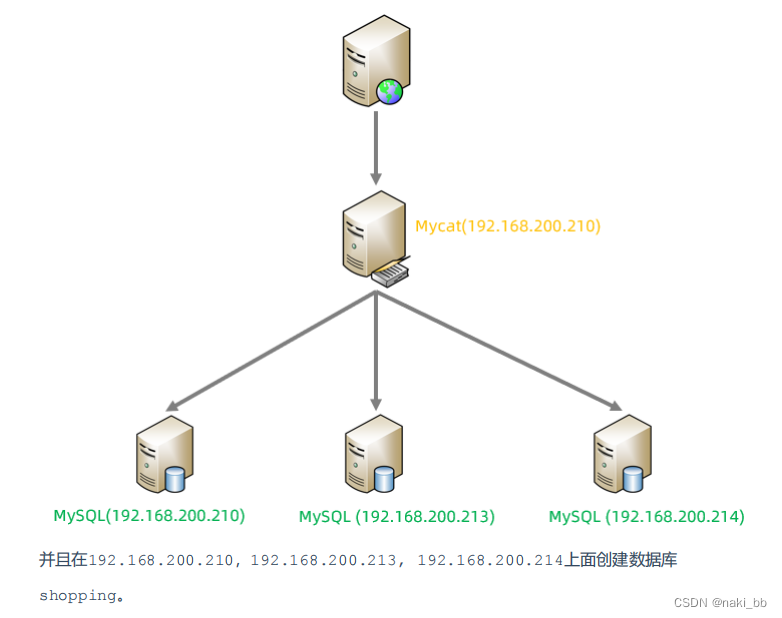
逻辑表的概念都是mycat中的,所以table中的表在物理节点是不存在的,需要用mycat手动执行建表语句,mycat在根据配置的逻辑表与分片节点-配置的关系,在对应的物理节点创建对应的表。
测试
source /root/shopping-table.sql
source /root/shopping-insert.sql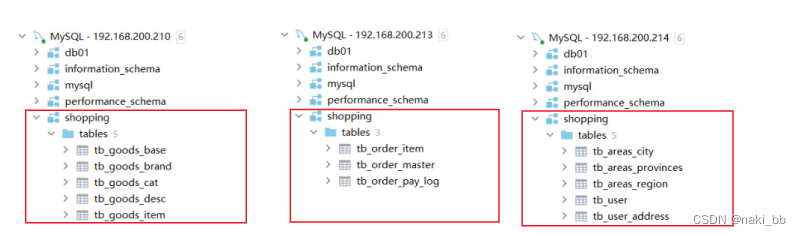
1) 查询用户的收件人及收件人地址信息(包含省、市、区)。
在MyCat的命令行中,当我们执行以下多表联查的SQL语句时,可以正常查询出数据。
select ua.user_id, ua.contact, p.province, c.city, r.area , ua.address from tb_user_address ua ,tb_areas_city c , tb_areas_provinces p ,tb_areas_region r where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id = r.areaid ;
2)查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o , tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND o.receiver_region = r.areaid ;
全局表
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/>
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id" type="global"/>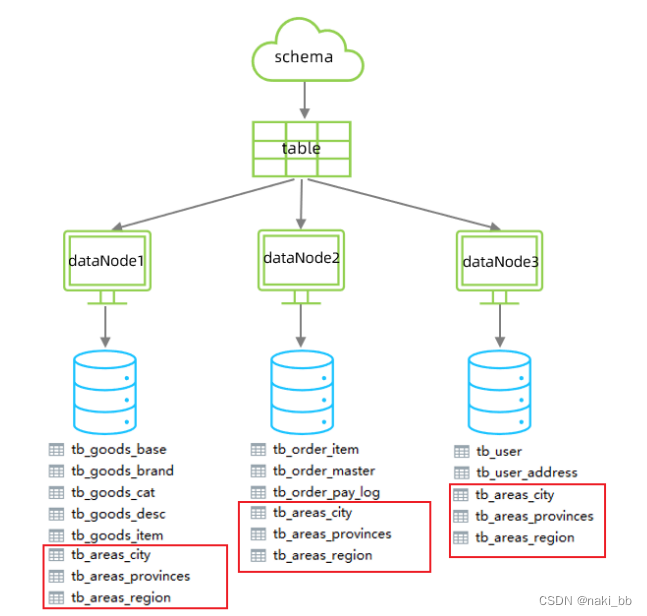
source /root/shopping-table.sql
source /root/shopping-insert.sqlSELECT order_id , payment ,receiver, province , city , area FROM tb_order_master o , tb_areas_provinces p , tb_areas_city c , tb_areas_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city = c.cityid AND o.receiver_region = r.areaid ;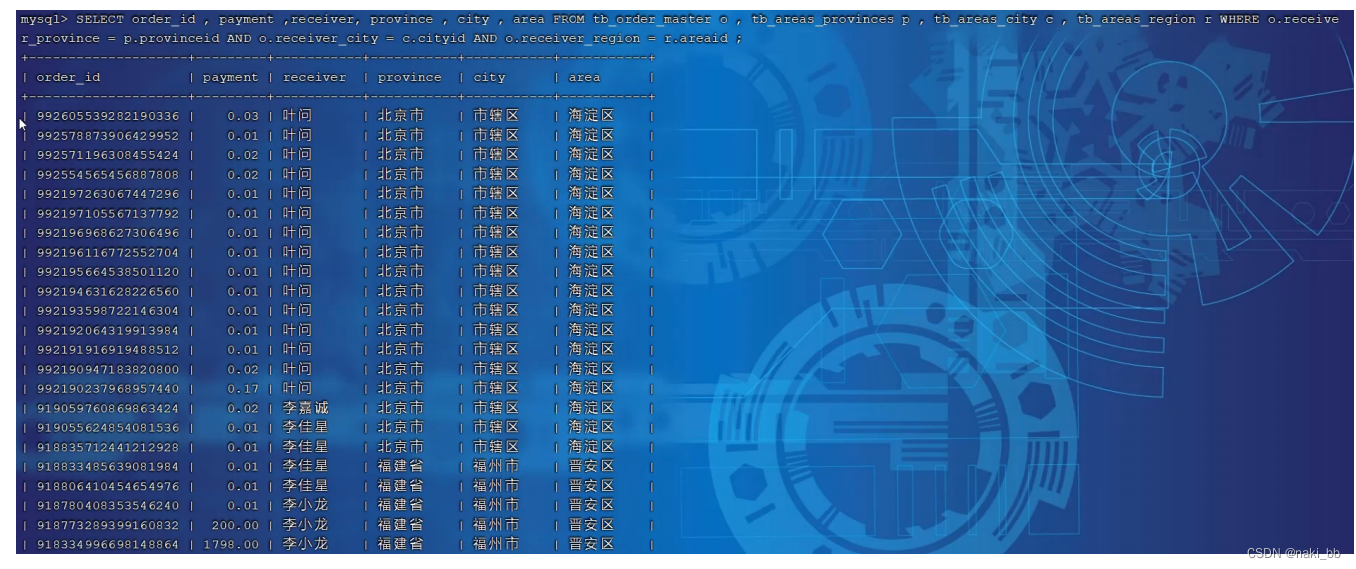
水平拆分
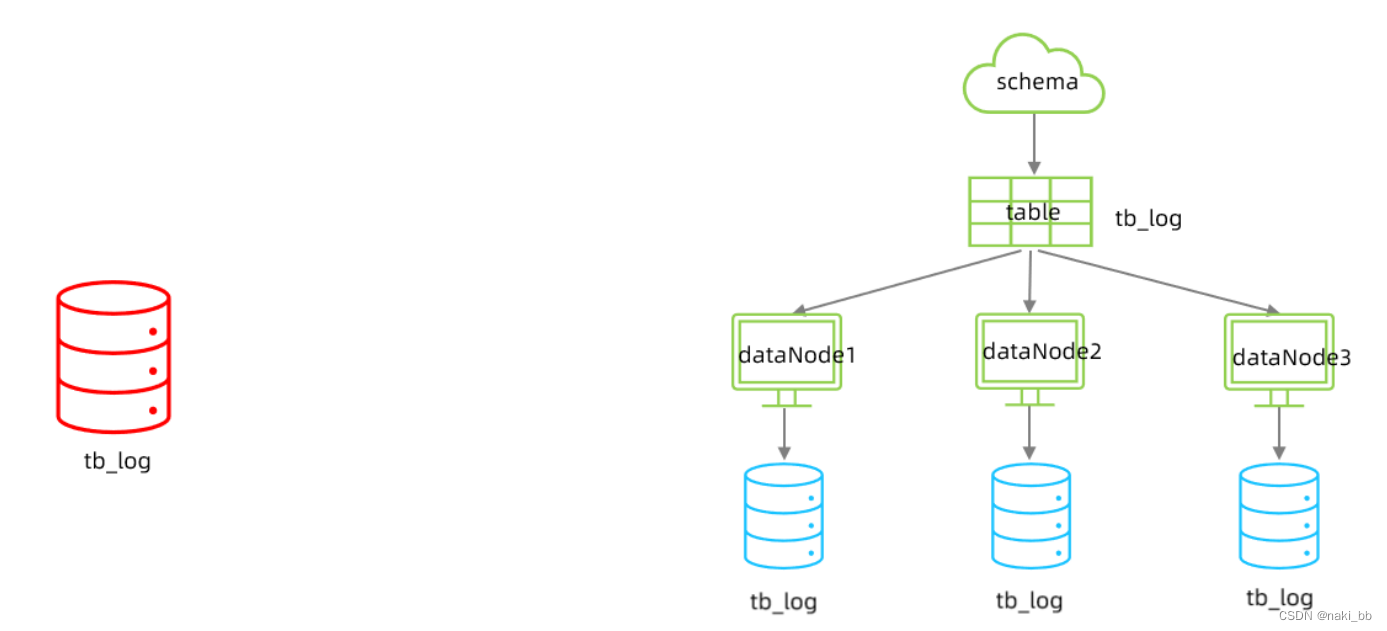
配置
1) schema.xml
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />
</schema>
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" /><user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">SHOPPING,ITCAST</property><!-- 表级 DML 权限设置 --><!-- <privileges check="true"> <schema name="DB01" dml="0110" > <table name="TB_ORDER" dml="1110"></table> </schema> </privileges> -->
</user>测试
CREATE TABLE tb_log
(id bigint(20) NOT NULL COMMENT 'ID',model_name varchar(200) DEFAULT NULL COMMENT '模块名',model_value varchar(200) DEFAULT NULL COMMENT '模块值',return_value varchar(200) DEFAULT NULL COMMENT '返回值',return_class varchar(200) DEFAULT NULL COMMENT '返回值类型',operate_user varchar(20) DEFAULT NULL COMMENT '操作用户',operate_time varchar(20) DEFAULT NULL COMMENT '操作时间',param_and_value varchar(500) DEFAULT NULL COMMENT '请求参数名及参数值',operate_class varchar(200) DEFAULT NULL COMMENT '操作类',operate_method varchar(200) DEFAULT NULL COMMENT '操作方法',cost_time bigint(20) DEFAULT NULL COMMENT '执行方法耗时, 单位 ms',source int(1) DEFAULT NULL COMMENT '来源 : 1 PC , 2 Android , 3 IOS',PRIMARY KEY (id)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('1','user','insert','success','java.lang.String','10001','2022-01-06 18:12:28','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro ller.UserController','insert','10',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('2','user','insert','success','java.lang.String','10001','2022-01-06 18:12:27','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro ller.UserController','insert','23',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('3','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro ller.UserController','update','34',1);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('4','user','update','success','java.lang.String','10001','2022-01-06 18:16:45','{\"age\":\"20\",\"name\":\"Tom\",\"gender\":\"1\"}','cn.itcast.contro ller.UserController','update','13',2);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('5','user','insert','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.co ntroller.UserController','insert','29',3);
INSERT INTO tb_log (id, model_name, model_value, return_value, return_class, operate_user, operate_time, param_and_value, operate_class, operate_method, cost_time,source) VALUES('6','user','find','success','java.lang.String','10001','2022-01-06 18:30:31','{\"age\":\"200\",\"name\":\"TomCat\",\"gender\":\"0\"}','cn.itcast.co ntroller.UserController','find','29',2);
因为分片规则为mod-long,取模,并且默认的配置个数为3

所以id=3,6 会数据会落到第一个节点
所以id=1,4 会数据会落到第二个节点
所以id=2,5 会数据会落到第三个节点
Mycat 分片规则
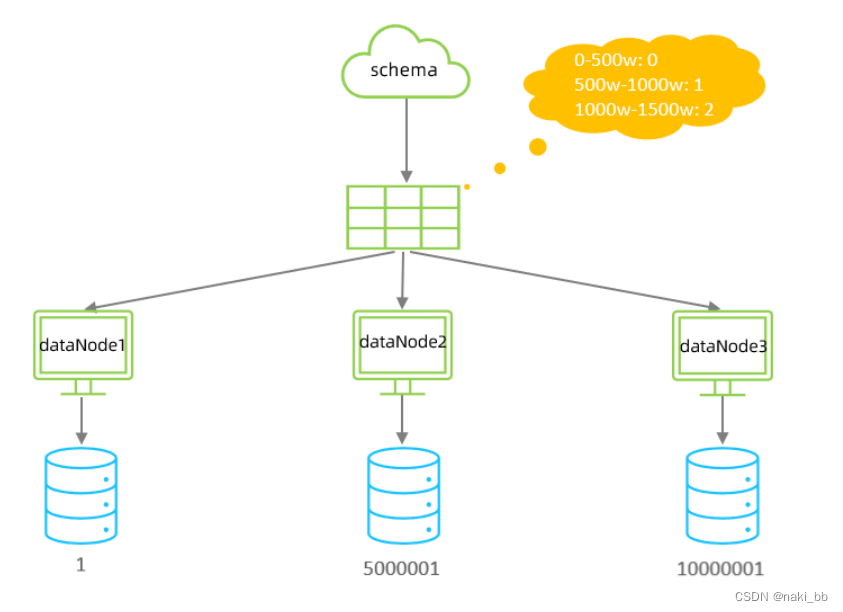
1.范围分片
配置
schema.xml
逻辑表配置
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />数据节点配置
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />rule.xml 分片规则配置
<tableRule name="auto-sharding-long"><rule><!-- 对应的数据库字段 --><columns>id</columns><algorithm>rang-long</algorithm></rule>
</tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property><!-- 超过配置的最大值时,会插入到默认的节点中 --><property name="defaultNode">0</property>
</function>属性含义
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为 0 ; 0 表示 Integer , 1 表示 String |
| defaultNode | 默认节点 默认节点的所用 : 枚举分片时 , 如果碰到不识别的枚举值 , 就让它路由到默认节点 ; 如果没有默认值 , 碰到不识别的则报错 。 |
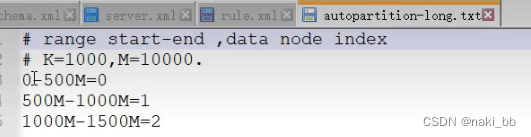
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
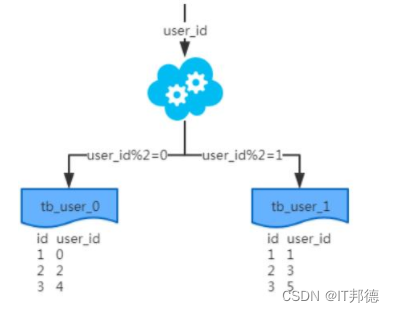
1000M-1500M=22.取模分片
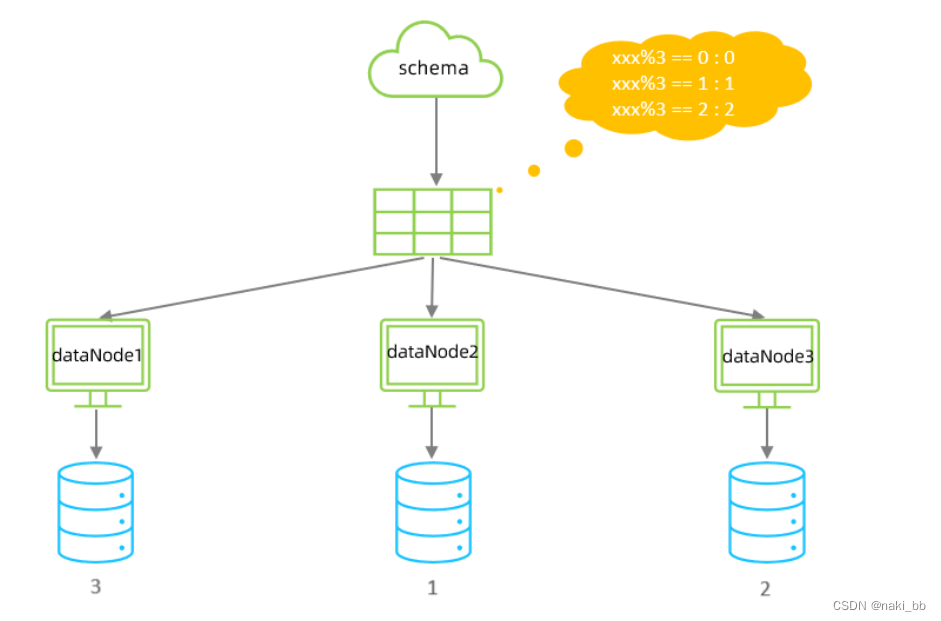
配置
schema.xml
逻辑表配置:
<table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片规则配置:
<tableRule name="mod-long"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod"><property name="count">3</property>
</function>属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| count | 数据节点的数量 |
3.一致性hash分片
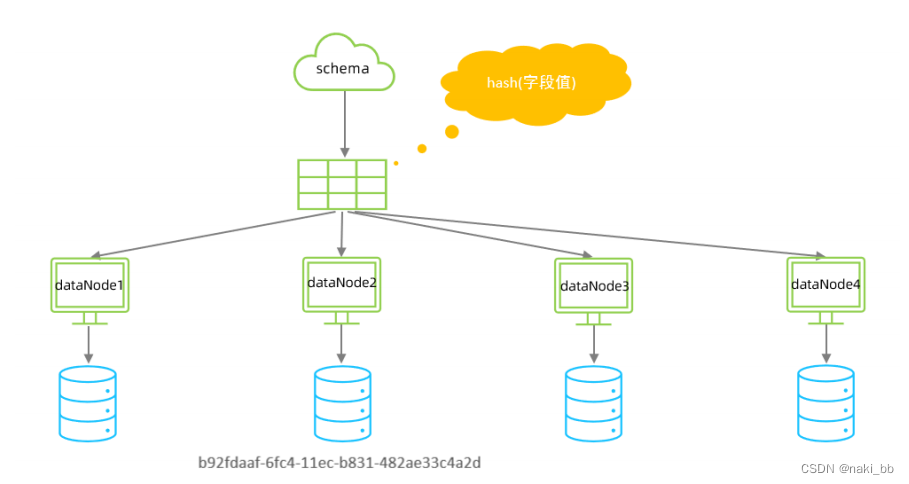
配置
schema.xml
逻辑表配置:
<!-- 一致性hash -->
<table name="tb_order" dataNode="dn4,dn5,dn6" rule="sharding-by-murmur" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片规则配置:
<tableRule name="sharding-by-murmur"><rule><columns>id</columns><algorithm>murmur</algorithm></rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash"><property name="seed">0</property><!-- 默认是0 --><property name="count">3</property><property name="virtualBucketTimes">160</property>
</function>属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| seed | 创建 murmur_hash 对象的种子,默认 0 |
| count | 要分片的数据库节点数量,必须指定,否则没法分片 |
| virtualBucketTimes | 一个实际的数据库节点被映射为这么多虚拟节点,默认是 160 倍,也就是虚拟节点数是物理节点数的160 倍 ;virtualBucketTimes*count 就是虚拟结点数量 ; |
| weightMapFile | 节点的权重,没有指定权重的节点默认是 1 。以 properties 文件的格式填写,以从0 开始到 count-1 的整数值也就是节点索引为 key ,以节点权重值为值。所有权重值必须是正整数,否则以1 代替 |
| bucketMapPath | 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash 值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 |
4.枚举分片
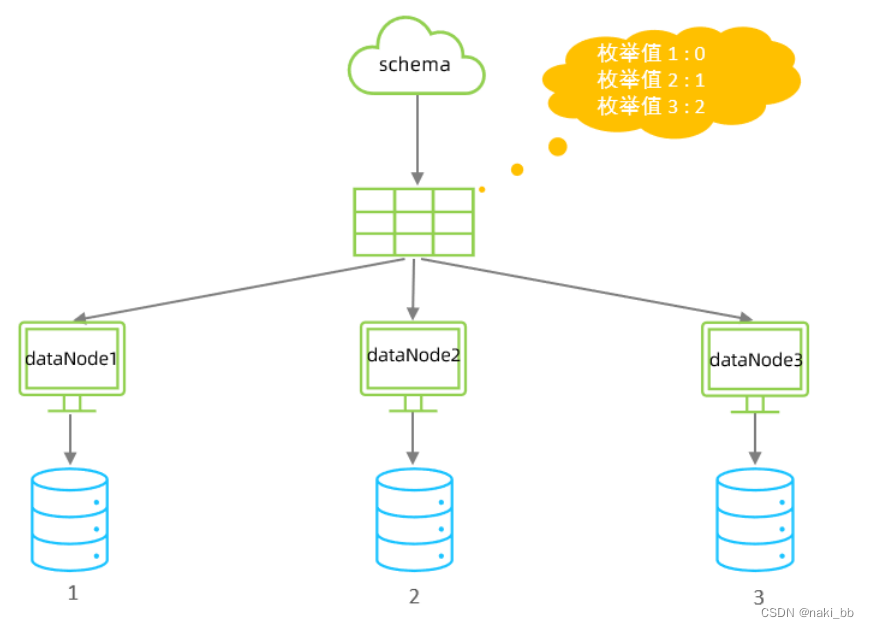
配置
schema.xml
逻辑表配置:
<!-- 枚举 -->
<table name="tb_user" dataNode="dn4,dn5,dn6" rule="sharding-by-intfile-enumstatus" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片规则配置:
<!-- 自己增加 tableRule -->
<tableRule name="sharding-by-intfile-enumstatus"><rule><!-- 根据status列的值作为枚举值 --><columns>status</columns><algorithm>hash-int</algorithm></rule>
</tableRule><function name="hash-int" class="io.mycat.route.function.PartitionByFileMap"><property name="defaultNode">2</property><property name="mapFile">partition-hash-int.txt</property>
</function>1=0
2=1
3=2属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| mapFile | 对应的外部配置文件 |
| type | 默认值为 0 ; 0 表示 Integer , 1 表示 String |
| defaultNode | 默认节点 ; 小于 0 标识不设置默认节点 , 大于等于 0 代表设置默认节点 ; 默认节点的所用: 枚举分片时 , 如果碰到不识别的枚举值 , 就让它路由到默认节点 ; 如果没有默认值 , 碰到不识别的则报错 。 |
5.应用指定算法
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。
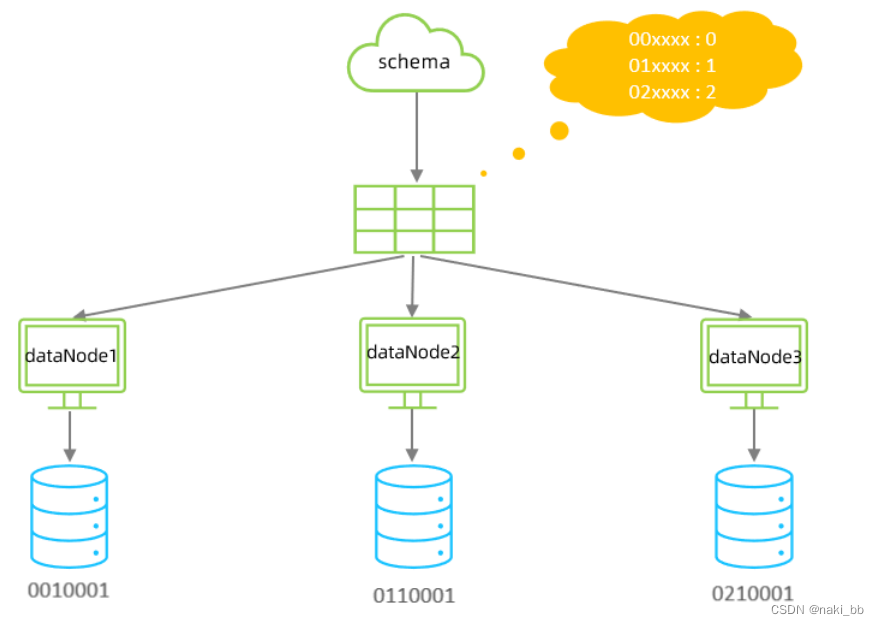
配置
schema.xml
逻辑表配置:
<!-- 应用指定算法 -->
<table name="tb_app" dataNode="dn4,dn5,dn6" rule="sharding-by-substring" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片规则配置:
<tableRule name="sharding-by-substring"><rule><columns>id</columns><algorithm>sharding-by-substring</algorithm></rule>
</tableRule><function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString"><property name="startIndex">0</property><!-- zero-based --><property name="size">2</property><property name="partitionCount">3</property><property name="defaultPartition">0</property>
</function>属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| startIndex | 字符子串起始索引 |
| size | 字符长度 |
| partitionCount | 分区 ( 分片 ) 数量 |
| defaultPartition | 默认分片 ( 在分片数量定义时 , 字符标示的分片编号不在分片数量内时 , 使用默认分片) |
6.固定分片hash算法
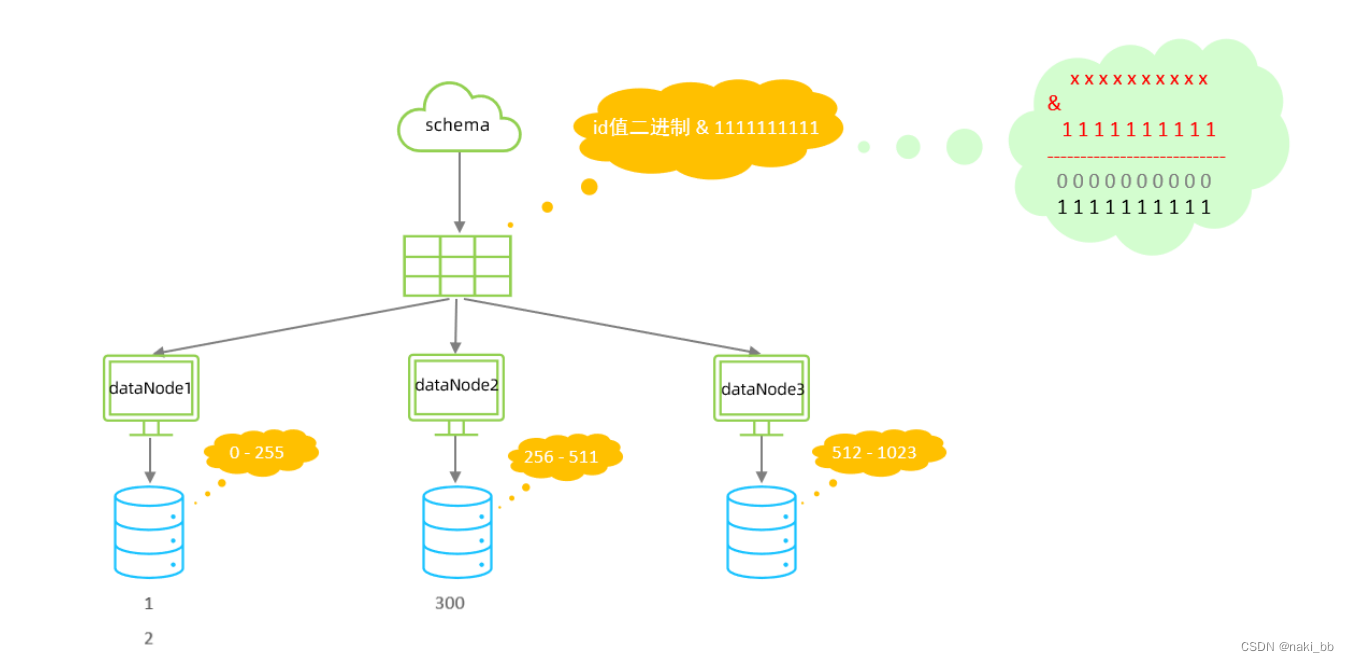
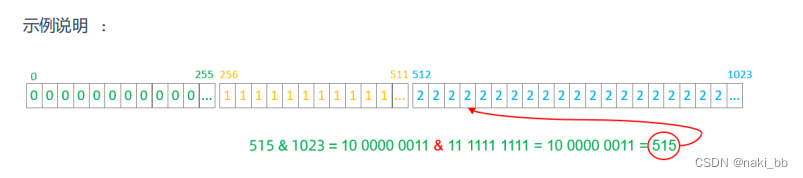
- 如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
- 可以均匀分配,也可以非均匀分配。
- 分片字段必须为数字类型。
配置
schema.xml
逻辑表配置:
<!-- 固定分片hash算法 -->
<table name="tb_longhash" dataNode="dn4,dn5,dn6" rule="sharding-by-long-hash" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />rule.xml分片规则配置:
<tableRule name="sharding-by-long-hash"><rule><columns>id</columns><algorithm>sharding-by-long-hash</algorithm></rule>
</tableRule>
<!-- 分片总长度为1024,count与length数组长度必须一致; -->
<function name="sharding-by-long-hash" class="io.mycat.route.function.PartitionByLong"><!-- 总共三个分片节点 --><property name="partitionCount">2,1</property><!-- 前两个存储256个,第三个512个,第一个0-255,第二个256-511,第三个512-1023 --><property name="partitionLength">256,512</property>
</function>属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionCount | 分片个数列表 |
| partitionLength | 分片范围列表 |
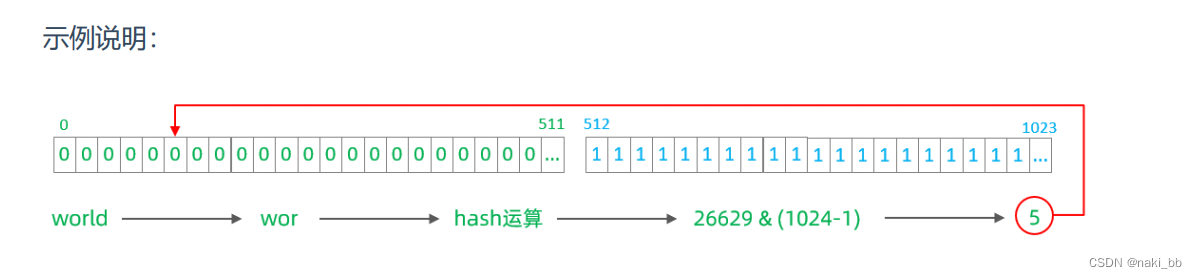
7.字符串hash解析算法
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。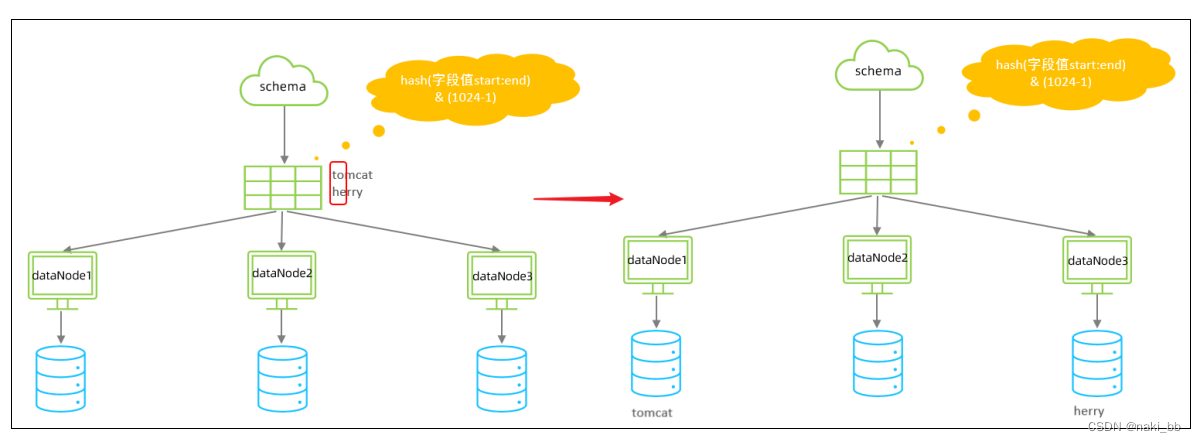
配置
schema.xml
逻辑表配置:
<!-- 字符串hash解析算法 -->
<table name="tb_strhash" dataNode="dn4,dn5" rule="sharding-by-stringhash" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
rule.xml分片规则配置:
<tableRule name="sharding-by-stringhash"><rule><columns>name</columns><algorithm>sharding-by-stringhash</algorithm></rule>
</tableRule><function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString"><property name="partitionLength">512</property><!-- zero-based --><property name="partitionCount">2</property><property name="hashSlice">0:2</property>
</function>属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| partitionLength | hash 求模基数 ; length*count=1024 ( 出于性能考虑 ) |
| partitionCount | 分区数 |
| hashSlice | hash 运算位 , 根据子字符串的 hash 运算 ; 0 代表 str.length() , -1 代表 str.length()-1 , 大于 0 只代表数字自身 ; 可以理解 为 substring ( start , end ), start 为 0 则只表示 0 |
8.按天分片算法
配置
schema.xml
逻辑表配置:
<!-- 按天分片 -->
<table name="tb_datepart" dataNode="dn4,dn5,dn6" rule="sharding-by-date" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml分片规则配置:
<tableRule name="sharding-by-date"><rule><columns>create_time</columns><algorithm>sharding-by-date</algorithm></rule>
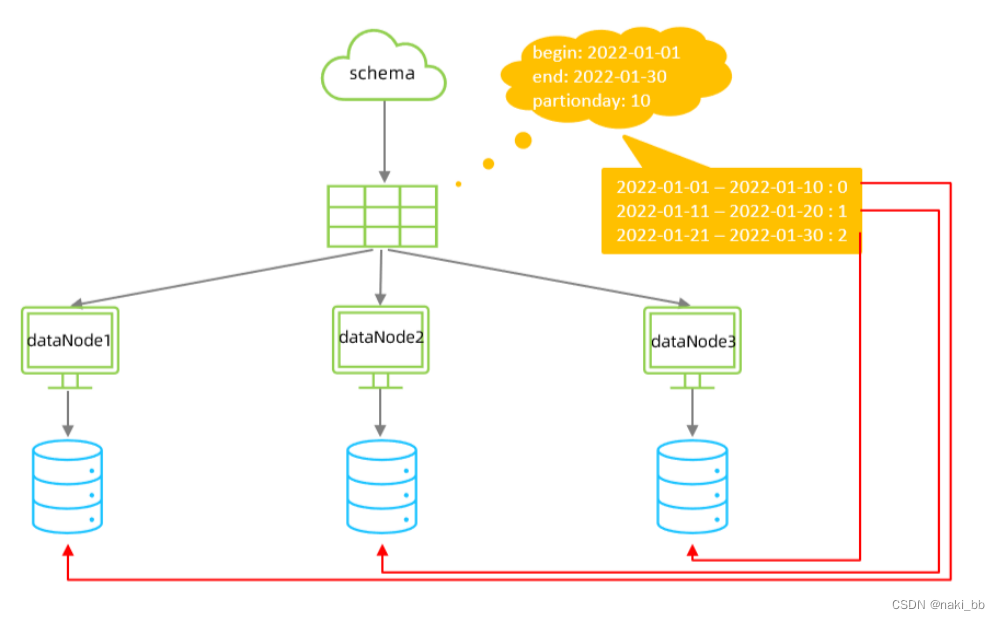
</tableRule><function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2022-01-01</property><property name="sEndDate">2022-01-30</property><property name="sPartionDay">10</property>
</function><!--从开始时间开始,每10天为一个分片,到达结束时间之后,会重复开始分片插入 配置表的 dataNode 的分片,
必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,每 10天一个分片,一共需要37个分片。 -->属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
| sPartionDay | 分区天数,默认值 10 ,从开始日期算起,每个 10 天一个分区 |
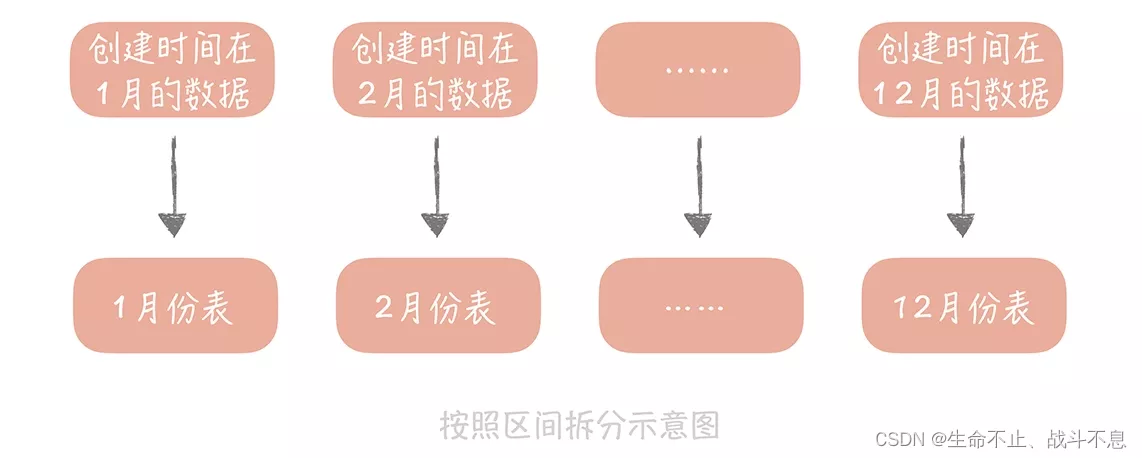
9.自然月分片
配置
schema.xml
逻辑表配置:
<!-- 按自然月分片 -->
<table name="tb_monthpart" dataNode="dn4,dn5,dn6" rule="sharding-by-month" />数据节点配置:
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
rule.xml分片规则配置:
<tableRule name="sharding-by-month"><rule><columns>create_time</columns><algorithm>partbymonth</algorithm></rule>
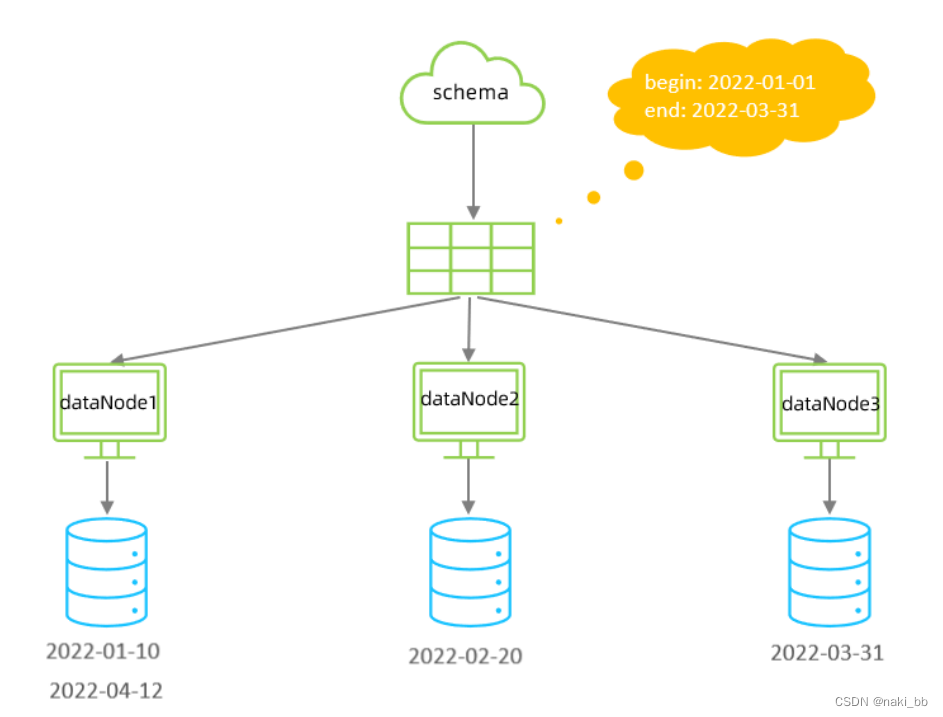
</tableRule><function name="partbymonth" class="io.mycat.route.function.PartitionByMonth"><property name="dateFormat">yyyy-MM-dd</property><property name="sBeginDate">2022-01-01</property><property name="sEndDate">2022-03-31</property>
</function>
<!--从开始时间开始,一个月为一个分片,到达结束时间之后,会重复开始分片插入 配置表的 dataNode 的分片,
必须和分片规则数量一致,例如 2022-01-01 到 2022-12-31 ,一 共需要12个分片。 -->属性说明:
| 属性 | 描述 |
| columns | 标识将要分片的表字段 |
| algorithm | 指定分片函数与 function 的对应关系 |
| class | 指定该分片算法对应的类 |
| dateFormat | 日期格式 |
| sBeginDate | 开始日期 |
| sEndDate | 结束日期,如果配置了结束日期,则代码数据到达了这个日期的分片后,会重复从开始分片插入 |
说明:因为只有3个分片节点,所以添加4月日期的数据时会插入第一个节点,5月插入第二个节点,6月插入第三个节点,以此类推
Mycat 管理 和 监控
MyCat 管理及监控_naki_bb的博客-CSDN博客