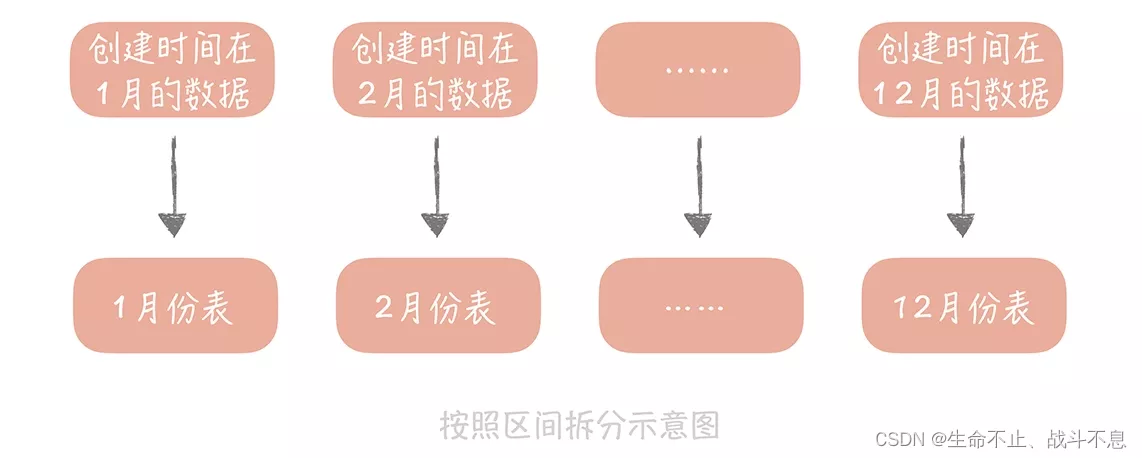
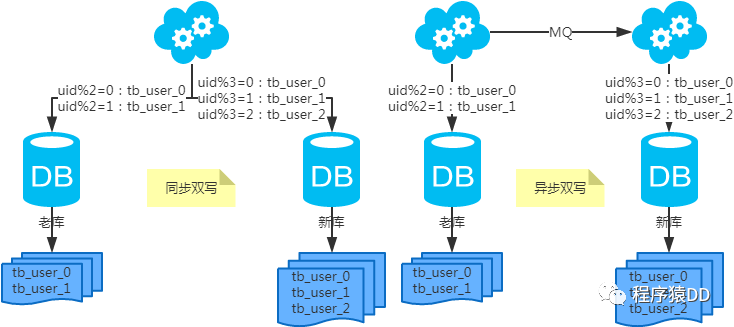
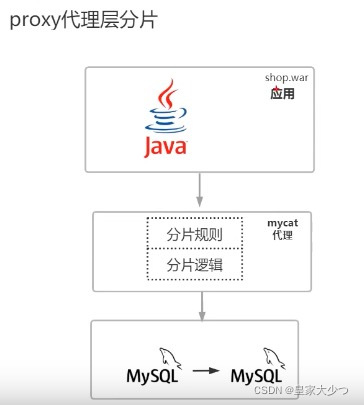
Mysql·分库分表
- 在mysql中新建数据库用以表分库分表
- mycat解压后配置文件参数
- server.xml 主要配置mycat服务的参数,比如端口号,myact用户名和密码使用的逻辑数据库等
- rule.xml 主要配置路由策略,主要有分片的片键,拆分的策略(取模还是按区间划分等)
- schema.xml 文件主要配置数据库的信息,例如逻辑数据库名称,物理上真实的数据源以及表和数据源之间的对应关系和路由策略等。
- 启动mycat
window环境下运行的,实际生产推荐在Linux上运行
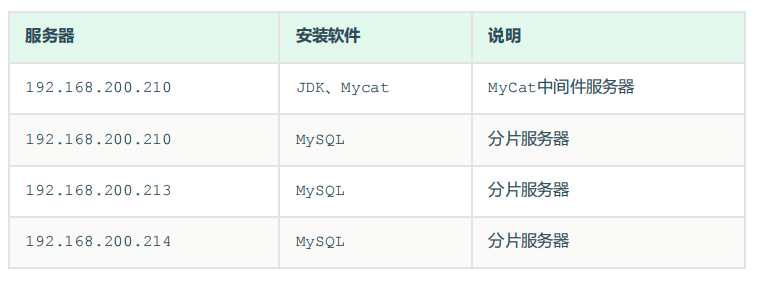
使用前软件环境搭建
下载安装mysql:mysql-5.7.36-winx64
下载安装jdk-8u251-windows-x64
下载安装Mycat-server-1.3.0.3-release-20150527095523-win
在mysql中新建数据库用以表分库分表
create database yy01;
create database yy02;
create database yy03;select 'yy01',a.* from yy01.item a union all
select 'yy02',a.* from yy02.item a union all
select 'yy03',a.* from yy03.item a ;explain select * from item ;
mycat解压后配置文件参数
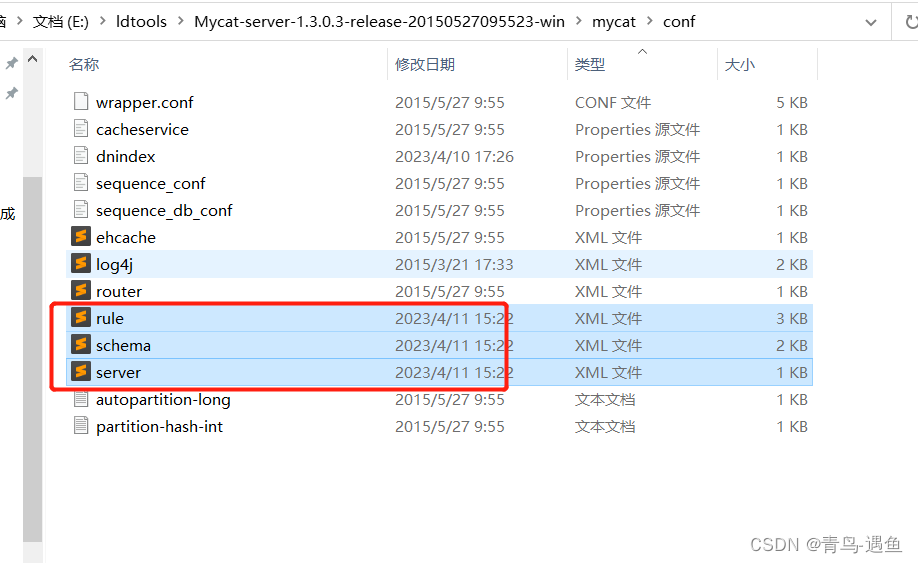
server.xml 主要配置mycat服务的参数,比如端口号,myact用户名和密码使用的逻辑数据库等
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/"><system><property name="defaultSqlParser">druidparser</property></system><user name="test"><property name="password">test</property><property name="schemas">TESTDB</property> </user><user name="user"><property name="password">user</property><property name="schemas">TESTDB</property><property name="readOnly">true</property></user>
</mycat:server>
rule.xml 主要配置路由策略,主要有分片的片键,拆分的策略(取模还是按区间划分等)
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE mycat:rule SYSTEM "rule.dtd">
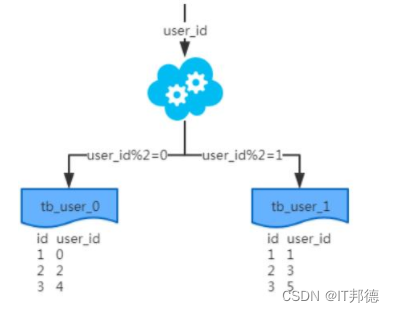
<mycat:rule xmlns:mycat="http://org.opencloudb/"><tableRule name="role1"><rule><columns>id</columns><algorithm>mod-long</algorithm></rule>
</tableRule><tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule><function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash"><property name="seed">0</property><!-- 默认是0--><property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片--><property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍--></function><function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property></function><function name="rang-long" class="org.opencloudb.route.function.AutoPartitionByLong"><property name="mapFile">autopartition-long.txt</property></function><function name="mod-long" class="org.opencloudb.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">3</property></function><function name="func1" class="org.opencloudb.route.function.PartitionByLong"><property name="partitionCount">8</property><property name="partitionLength">128</property></function>
</mycat:rule>
schema.xml 文件主要配置数据库的信息,例如逻辑数据库名称,物理上真实的数据源以及表和数据源之间的对应关系和路由策略等。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"><!-- 数据同步 --><table name="users" primaryKey="id" dataNode="dn1,dn2,dn3" /> <!-- 数据分库分表 rule="role1" 分库分表规则分库表数据union all在一起是全量数据 如不设置默认所有库下数据相同 --><table name="item" primaryKey="id" dataNode="dn1,dn2,dn3" rule="role1" /> <table name="users2" primaryKey="id" dataNode="dn1,dn2,dn3" rule="role1" /><table name="orders" primaryKey="id" dataNode="dn1,dn2,dn3" rule="role1" /></schema><dataNode name="dn1" dataHost="localhost1" database="yy01" /><dataNode name="dn2" dataHost="localhost1" database="yy02" /><dataNode name="dn3" dataHost="localhost1" database="yy03" /><!-- <dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" /><dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" /><dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" />--><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hostM1" url="localhost:3306" user="root"password="123456"><!-- can have multi read hosts --><!-- <readHost host="hostS1" url="localhost:3306" user="root" password="123456" /> --></writeHost><!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --></dataHost></mycat:schema>
启动mycat
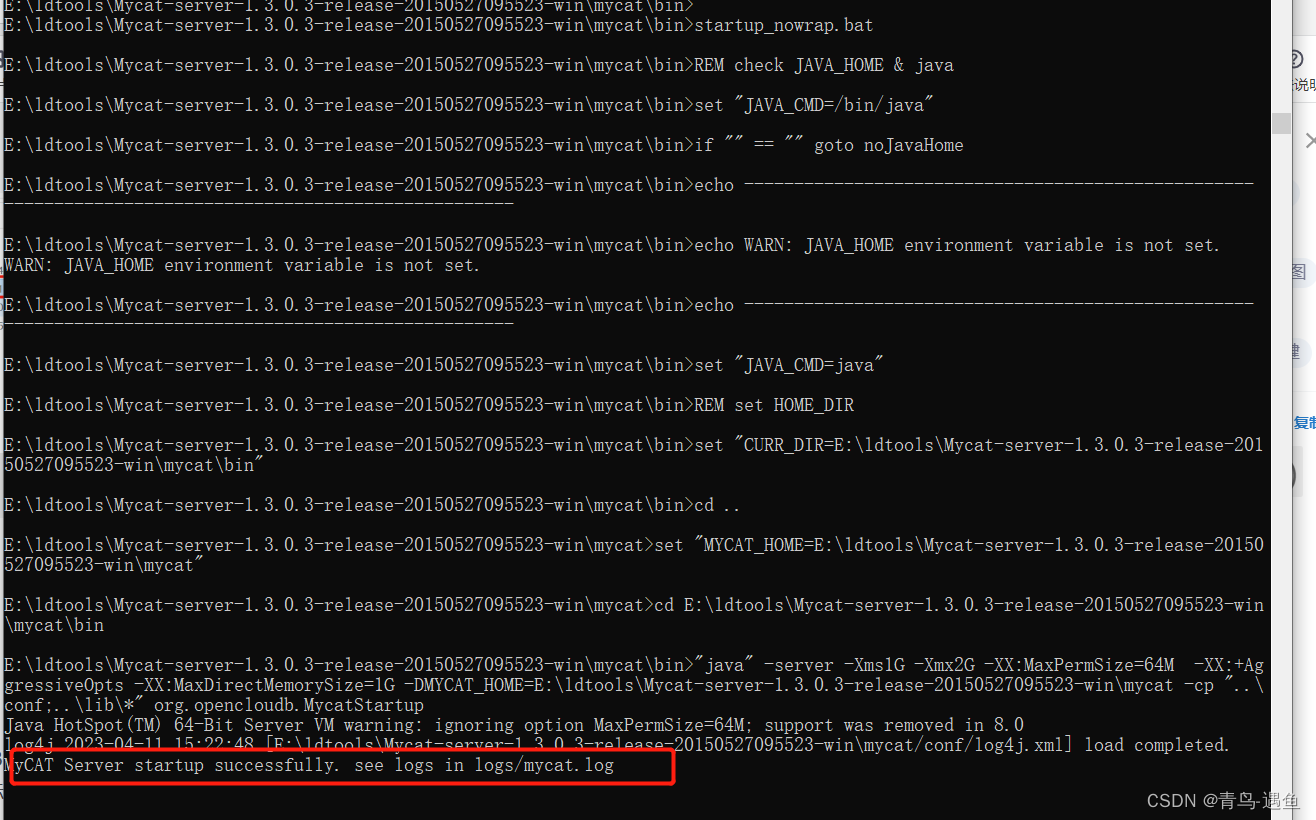
出现此画面说明启动成功
验证结果
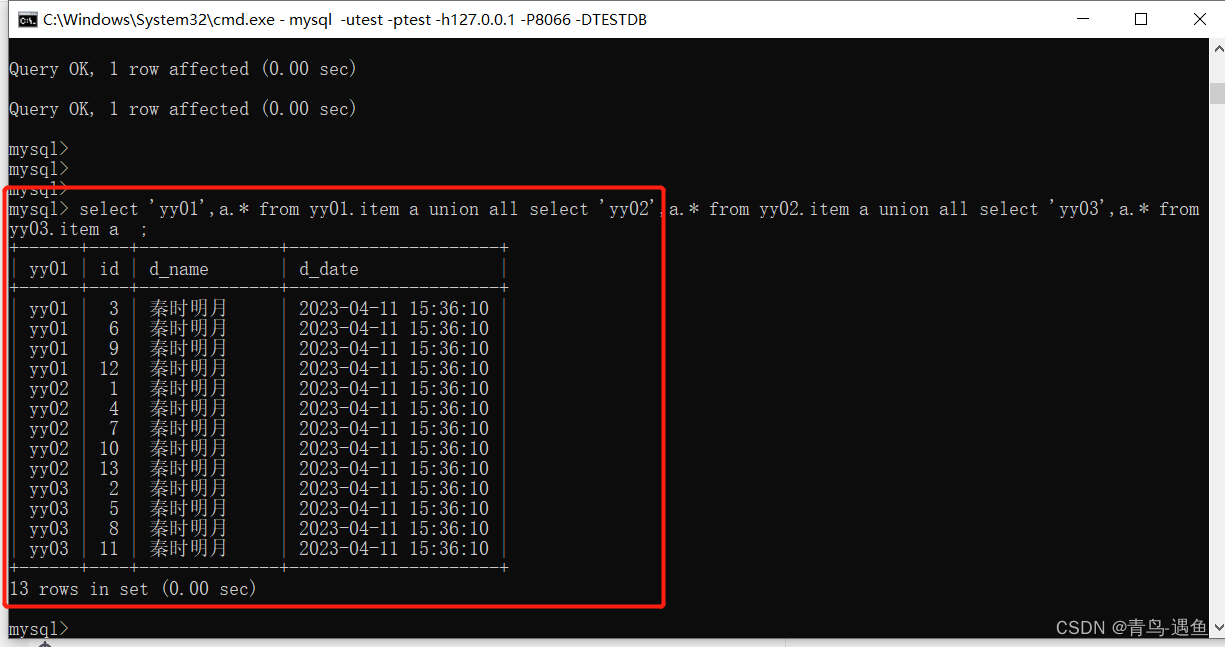
在命令行访问mycat逻辑数据库,采用如下的命令:
mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB
现在通过数据库查询数据库和表,发现只有逻辑数据库TESTDB而不是yy01, yy02, yy03;而且表也是统一显示的,而不是分布在不同的实际数据库中。参考图片如下:

在TESTDB库中创建item表用以测试
drop table if exists item ;
CREATE TABLE item ( id INT NOT NULL AUTO_INCREMENT, d_name varchar(100) , d_date varchar(100) default '0000-00-00 00:00:00', PRIMARY KEY (id)
)AUTO_INCREMENT= 1 ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into item (id,d_name,d_date) values(01,'秦时明月',now());
insert into item (id,d_name,d_date) values(02,'秦时明月',now());
insert into item (id,d_name,d_date) values(03,'秦时明月',now());
insert into item (id,d_name,d_date) values(04,'秦时明月',now());
insert into item (id,d_name,d_date) values(05,'秦时明月',now());
insert into item (id,d_name,d_date) values(06,'秦时明月',now());
insert into item (id,d_name,d_date) values(07,'秦时明月',now());
insert into item (id,d_name,d_date) values(08,'秦时明月',now());
insert into item (id,d_name,d_date) values(09,'秦时明月',now());
insert into item (id,d_name,d_date) values(10,'秦时明月',now());
insert into item (id,d_name,d_date) values(11,'秦时明月',now());
insert into item (id,d_name,d_date) values(12,'秦时明月',now());
insert into item (id,d_name,d_date) values(13,'秦时明月',now());select 'yy01',a.* from yy01.item a union all
select 'yy02',a.* from yy02.item a union all
select 'yy03',a.* from yy03.item a ;explain select * from item ;
如下图所示,mycat配置分库分表成功