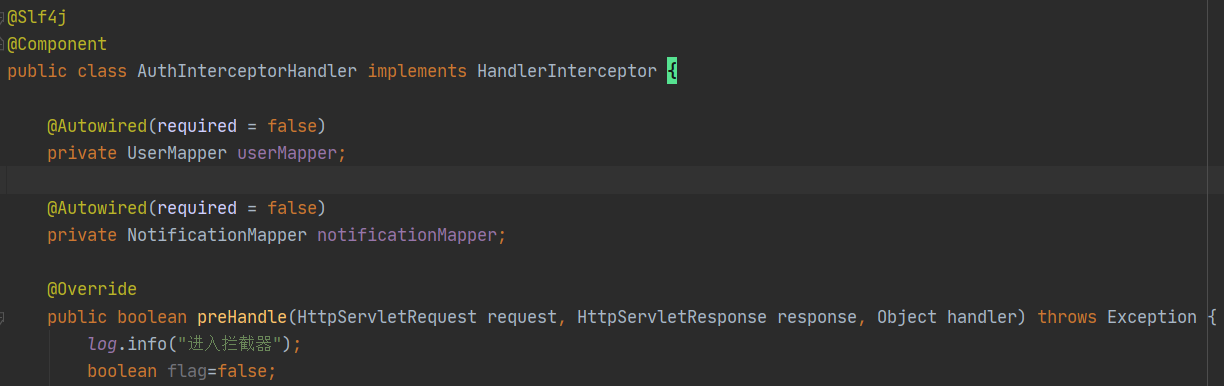
首先,我想讲一个叫庖丁解牛的故事,想必你应该听过。庖丁从开始杀牛,到他的故事被写下,操刀十九年,杀了数千头牛。也正是由于丰富的实践经验,他总结出了解杀牛的方法论:依照牛生理上的天然结构,砍入牛体筋骨相接的缝隙,顺着骨节间的空处进刀。依照牛体本来的构造,筋脉经络相连的地方和筋骨结合的地方,都不曾被刀碰到过,更何况大骨呢!这样,能够顺利地把牛解开,还不会对刀造成损害。所以,他明白了最核心的思维,即顺应天然结构,这种思维成就了他的大厨身份。反之,如果对于一个没有这种思维的人,即便是拿着最锋利的刀,面对一头完整的牛也会手足无措。
每个行业都有每个行业的思维方式,这些思维暗示着行业运转背后的规律。当我最初了解到这些思维方法,我还是一个行业新人,对其中所讲的内容一知半解,不置可否,而今天,当我再次回顾这些方法的时候,感到醍醐灌顶,无比认同。这些思维方式往往经过很多对这个行业的深入研究,并且能够通过现象看到本质的大师结合自己的经验总结而成的。
那么接下来,就让我们看一下,在大数据时代,有哪些思维方式可以帮助我们快速进入工作状态。
全量思维
在介绍全量思维之前,我们先来思考一个问题:如果要统计阳澄湖中大闸蟹的数目,你想采取怎样的方法?
显而易见,最直接的方法就是把阳澄湖的水抽干,把里面的大闸蟹都捞上来,然后一个一个地数一数共有多少只大闸蟹。
但是想到这个方案的瞬间你可能就会打消这个念头,因为这个方案实现成本太大,几乎是不可能完成的。
退而求其次,我们可以在阳澄湖的几个不同的区域撒一些网,看看每个区域能够捞到多少只大闸蟹,然后推断一下与之面积类似的区域的大闸蟹数量。这种方法比起前一种方法更加可行,但是获得的结果肯定不如前一种精确。
第二种方法就是“抽样”。抽样思维在很长的一段时间里,甚至在现在很多的行业和实验中,都扮演者十分重要的角色。在数据获取困难、处理难度大的情况下,抽样思维是一种非常优秀的权宜之计。
而与这种抽样思维相反的,就像我们的第一种方法——全量思维,即把所有大闸蟹都捞出来数一数。
你肯定会说,第一种方法实现成本不是巨大吗?然而在大数据场景下,数据的采集已经变得极其方便,数据的存储也不再昂贵,各种硬件的性能不断提高,数据的计算速度也越来越快。尤其是还有很多优秀的研发机构推出了强大的大数据架构方案,比如 Hadoop、Spark、Flink 等,进一步降低了全量处理的成本。
如果要做一个服装行业消费情况的分析,我们仅仅是从数据中随机地抽取一些用户消费记录来分析他们的消费情况,可能永远也没办法知道在人均消费 200 元的市场上,会有人一掷千金花费 200 万元来购置衣服。所以,在全量思维的情况下,任何没有经过全体数据验证的事情,都可能是存在问题的。
所以,在现在工作中,涉及获取数据的环节,我们通常是事先规划好所有能够获取的全部数据情况,拿用户阅读内容为例,用户阅读的内容不用说,用户点击的时间、用户阅读的比例、用户阅读的时长、用户阅读时点击的区域等行为信息都要一一记录下来,全部存储到用户行为日志中,在后续的处理过程中再进行选择,而不是在一开始就对数据进行取舍,导致在后面需要用时捉襟见肘。
容错思维
在全量思维的基础之上,第二个重要的思维是容错。
我们所处的世界是纷繁复杂的,不确定性使得我们的世界充满了各种异常、偏差、错误,所以我们收集的全量数据自然也存在着这些问题,数据的残缺、误差、采集设备的不足、对非结构化数据的不同认知等都会引起这些问题。过去,对数据的处理我们往往追求精益求精,希望借助严格的数据筛选策略和足够复杂的计算逻辑来获得完美的效果,然而,这是不符合实际情况的,极端复杂也导致了泛化性能不好,在测试阶段的优秀效果,到了实际的生产环境中往往水土不服。
比如说我们要做一个给新闻进行分类的项目,在项目之初我们往往会进入对新闻进行精确分类的死胡同,期望能够给每一条新闻分出一个明确的类别。然而,世界上的新闻是多种多样的,事实上,一条新闻可能属于一个类别,也可能属于多个类别,甚至在不同的读者看来,它属于不同的分类。在自然中的东西很少是泾渭分明的,我们的新闻自然也是如此,我们追求模型的准确率,从 75% 到 85%,再到 95%,然而我们永远不可能做到 100%,因为这种完美分类本身就是不存在的。
当然,我们不能在准确率不足的时候,以其本身的不确定性为借口。相反,我们应该:
-
去追求准确率的提升;
-
明白我们所关注的目标是**最终的效果,**比如说用户的阅读体验、用户的下单比例等。
在大数据的体系下,我们应该更加关注效率的提升,在这样一个前提下,要容忍那些本身就存在的误差甚至是错误。
相关思维
由于大数据数量众多,而数据中又存在着各种各样的误差,甚至是错误,数据之间的关系错综复杂。通过这些数据,我们会发现其中蕴含着各种各样奇怪的知识,而这些知识都属于“事实”,而非“因果”。比如说,当某个地区在百度上搜索“感冒”的人数超出了往常,你可能会从数据中推测出这里有很多人得了感冒,从而做出一些商业决策,比如说销售感冒药,但是你很难从这个数据中得出他们是为什么得了感冒。因为得感冒的原因很多:
-
可能是这个地方的天气突然转冷;
-
也可能是这个地区组织了大型集会活动,导致流感病毒的扩散加剧了;
-
还有可能是自然的流感季节到来。
在大数据背景下,我们不再追求难以捉摸的确定的因果关系,而是转向对相关关系的探索。通过对相关关系的分析,我们可以知道:
-
广东人比东北人更爱泡澡;
-
香山的 10 月中到 11 月中是全年流量高峰;
-
美国大选时义乌印谁的旗子多谁就会当选。
如此种种不胜枚举。通过数据掌握相关关系,可以让我们在商业决策中做出正确的决定,有时候甚至是出奇制胜的妙招。
这种相关思维甚至有点中国传统的中庸之道的味道,即知道是什么就够了,不需要知道为什么。相关关系不存在绝对性,而是存在着概率性的变化。在大数据之下发现的相关关系可能有着特定的环境和背景,比如随着中国的崛起,低端印刷产业转移到了东南亚;而我们义乌的旗子产量可能与美国大选的结果就不存在这种关系了。所以,我们要正确地认识相关思维,千万不要把因果关系与之画等号,在这个千变万化的世界中,相关关系也会随着内外部条件发生转移,唯一不变的就是变化。
高可复用
正是由于前面三个大数据思维,在我们的日常工作中,一定要保持一种数据复用的思维。当你逐渐明白了,全量的数据才能表示全量;当你能面对各种问题数据心平气和;当你能够从数据中找到各种各样的相关关系,那你一定能明白数据复用的重要性。
一个公司的数据看似由不同的部门产生,并用在不同的业务上,然而这些部门往往存在着千丝万缕的联系,这些业务也存在着不同程度的交叉。所以,一份数据如何能够进行不同程度的复用,将是你获得突破的核心思考。
比如说滴滴旗下有打车业务,有顺风车业务,有代价业务,有地图业务,有共享单车业务,还有社区团购业务。打车业务的大量打车信息,每一辆行驶中的汽车及其中的乘客,都是一个个丰富的数据收集器:
-
首先可以用来帮助计划车辆的调度、优化行车路线、提高公司的业绩;
-
同时,还可以给地图业务提供拥堵信息;
-
可以帮单车业务规划单车投放地点;
-
甚至根据打车人群为社区团购提供数据支撑。
这些还都仅仅是在公司内部的复用,这里给你留一个小小的思考,打车数据是否还可以用来做一些 ToB 的业务,从而为公司获得更加丰厚的利润呢?
所以,在这样的数据背景下,你所熟知的数据可能不被其他部门或者其他业务的人所熟知,跳出你的业务惯性,积极地思考数据所能够带来的价值,能够在什么地方发挥作用,是一个重要的思维方法。也正是因为这样,你的一个不经意的思考,可能带来意想不到的效果。
总结
讲到这里,关于大数据思维的几个要点就介绍完了,这可能不完全,也可能不准确,因为我们的大数据体系也在飞速地变化和发展。但是这一讲中提到的几个思维方式的变化,是我在整个工作中感悟比较深刻的几点。当然了,这些思维方式也不是我提出来的,而是在前人的基础上,加入了一些我自己的解读,希望能够给你带来一点自己的思考。
另外我在上文中留的小作业,希望你能思考下。并且有任何问题和心得,都可以在留言区留言。
下一讲,我们开始讲解大数据框架的模块,到时见!
精选评论
**一:
打车To B业务可能可以搞一下针对大企业,大园区的巴士业务,班车业务,方便员工上下班
**9982:
全量思维,容错思维,相关思维,高可复用
**3961:
全量,容错,相关,复用
在前面的部分,我们从思想和理念上大致了解了大数据的整体情况。从这一讲开始,我们就深入到实际的产品研发工作中,看一下大数据体系中涉及的各种工具和方法,以及它们在生产工作中都扮演着什么样的角色。
这一讲呢,我们先从几个案例出发,看一下在当前的互联网大厂中实践的大数据体系是什么样子的,当然,这其中涉及很多的专业名词、缩写以及英文名称,可能让你摸不着头脑,不要怕,在后续的课程中这些都会被讲解到。
互联网大厂的大数据解决方案
滴滴的大数据体系
我们先来看一组来自滴滴出行的数据:
截止到 2019 年 7 月,滴滴注册用户已超过 5.5 亿,年运送乘客达 100 亿人次,每日处理数据 4875+TB,日定位数超过 150 亿,每日路径规划请求超过 400 亿次。
那这样庞大的数据量,背后是由一个怎样的大数据体系作为支撑呢?如下是在全球软件开发大会上讲解的滴滴大数据研发平台。

-
最上层的红色箭头标志展示的是一个基于大数据平台开发工程的发布流程,当然,这个流程跟大数据的关系并不是很大,任何一个工程基本都要遵照这个过程进行发布。
-
紧挨着的流程是机器学习部分,机器学习会涉及数据挖掘 / 数据分析 / 数据应用几个步骤。
-
再往下是实时计算解决方案和离线计算解决方案。
-
在架构图的最底层是相关的支持,包括了数据安全、数据管理、开发运维和计算引擎四个部分。
就滴滴公布的大数据发展历程来看。
-
滴滴大数据先经历了裸奔时代:引擎初建,即通过 Sqoop 从 MySQL 导入 Hadoop,用户通过命令行访问大数据;
-
然后逐步引进了相关的工具化建设,但是这个阶段的工具还处于各自为政、四分五裂的状态:租户管理、权限管理、任务调度等;
-
在那之后,逐步产生了平台化思维,开始搭建一站式的智能开发和生产平台,使其可以覆盖整个离线场景,并且内置开发和生产两套逻辑环境,规范数据开发、生产和发布流程;
-
最后,也就是最新的一套大数据架构,在一站式开发生产平台的基础上进行了更多的扩展,已经可以集离线开发、实时开发、机器学习于一体。
阿里云的大数据体系
飞天大数据平台和 AI 平台支撑了阿里巴巴所有的应用,是阿里巴巴 10 年大平台建设最佳实践的结晶,是阿里大数据生产的基石。下图是飞天大数据的产品架构:

-
最下面是计算存储引擎,这里面包含了通用的存储和计算框架。存储方面,OSS 是阿里云的云存储系统,底层的 HDFS 文件存储系统,以及其他的各种 DB 系统;在计算框架方面,有 MapReduce 这种离线计算平台、实时计算平台、图计算引擎、交互式分析引擎等。
-
在存储和计算的基础上,是全域数据集成,这里面主要是对数据的各种采集和传输,支持批量同步、增量同步、实时同步等多种传输方式。
-
集成后的数据进入到统一元数据中心,统一进行任务调度。
-
再往上是开发层,通过结合各种算法和机器学习手段开发各种不同的应用。
-
最上面的数据综合治理,其实是在大数据全流程起到保障作用的一些模块,包含了智能监控、数据安全等模块。
美团的大数据体系
这是美团早些年公开的大数据体系架构:

在图上我们可以看到。
-
最左侧是美团的各种业务服务,从这些业务的数据库和日志,可以通过数据传输、日志采集等手段对数据进行汇总,一方面对于计算需求,直接进入到 Storm 流式计算框架进行计算,把结果存储于 HBase 等各种数据库中,并在业务上应用;另一方面,数据汇总到Hadoop 框架的存储中心,经过各种解析和结构化存储在 Hive 表中,并在各种机器学习和数据挖掘项目中进行应用。
-
在底层,是围绕着 Hadoop 架构建设的调度系统、配置中心,以及数据开放平台。
-
在最右侧,是经过集成的查询中心和查询引擎,并通过平台化开发建立了一套数据分析产品平台。
当然,美团的大数据体系不是一蹴而就的,也是随着时间的推移不断迭代和演进的:
-
在最早的 2011 年,美团基本还处于数据裸奔的状态,只有在有需求的时候才手工开发一个数据报表;
-
在 2011 年下半年引入了整个数据仓库的概念,梳理了所有数据流,设计了整个数据体系;
-
2012 年上了四台 Hadoop 机器,后面十几台,到最后的几千台以支撑各个业务的使用;
-
对于实时计算部分,在 2014 年开始启动应用,与此同时,也开始进行各种平台化的封装,以使得这些开源的工具框架能够更好地为业务所用;
-
时至今日,距离这个分享又过去了五年,在美团最新公开的一些关于大数据的文章和视频分享上,我们也可以看到整个大数据体系发生了长足的进展,不管是在平台化的演进还是对于现今技术的应用方面,都已经有了飞速的变化。
大数据体系的共同点
一口气看了这么多互联网大厂的大数据体系解决方案:
-
其中有比较早期的大数据体系,如 2016 年的美团大数据架构;
-
也有比较偏向于业务型的大数据架构,如滴滴的大数据平台;
-
也有用于通用解决方案的大数据体系,比如阿里飞天大数据平台产品架构。
它们属于不同的公司,作用于不同的业务,当然会有很多的不同点,但是不难看出,在大数据体系的发展过程中,也存在着很多相同的部分。
(1)模块化
大数据体系涉及了关于数据的一系列动作。随着大数据体系建设的逐渐完善,各个步骤变得更加清晰可分,不管是存储、调度、计算都被拆分成单独的模块,从而可以支持更多的业务,并根据需要进行灵活的选用。
(2)平台化
实施大数据的公司往往都有各种各样的业务,早期的大数据一定是围绕着各个业务去单独建设的,但是随着时间的流逝,各个业务之间的大数据体系存在着各种各样的差异,这就使得业务之间的数据互动成了一个难以跨越的鸿沟,建设一个把各业务的相似点统一起来,又能够包容各业务的差别的平台,让这些数据发挥出更大的价值成了一个迫在眉睫的需求。
(3)实时化
实时化一直是互联网公司不懈追求的。在大数据体系的演进中也充分体现了这一点。
-
最早期的开源大数据框架 Hadoop 都是基于磁盘开发的,不管是底层数据的存储还是计算的中间结果存储都放在磁盘上,而且其中的计算框架 MapReduce 也是基于离线的数据批处理,没办法对实时数据进行计算。
-
而看现在几大公司的大数据体系,实时计算已经成了大数据体系中一个非常重要的组成部分。
(4 )不完善
根据最近几年的工作经验,虽然大数据体系在不断地发展和变化,各种新技术不断地应用,但是大数据体系还远没有达到一个完善的水平,其中仍然存在着各种各样的问题。我们的数据在不停地生产,规模不断扩大,虽然说各种硬件的性能在提升,价格在下降,但是这仍然是公司非常巨大的一笔开支;同时,在大数据的治理方面还很欠缺,随着数据的不断增长,数据的共享和合理利用效率在不断地下降,同时在数据安全方面也存在着很大的隐患。所以,关于大数据架构的迭代还远没有结束,在未来肯定还会有更多更好的解决方案推陈出新,解决旧问题,满足新需求。
总结
在这一讲中,我们介绍了三个公司的大数据体系架构,从这几个案例中不难看出,目前的大数据体系基本上都包含了数据存储、数据传输、数据计算、机器学习平台以及数据的最终应用等部分,同时结合各自的业务形成了一些各自的特色。当然,不是说每一个公司都需要一个完整的大数据体系,由于它并没有十分完善并且开销巨大,我觉得每一个公司都应该考虑投入产出的效率,根据自己的需求和能力去逐步地建设。
在案例后面,我根据案例的情况总结了大数据体系的发展趋势,当然,不管是模块化、平台化还是实时化,其实都是对效率提升和降低成本的追求。
你可以根据我们这讲所学分析下你所在的公司的大数据框架,或者其他一些比较庞大的大数据体系,有什么问题,可以在评论区留言。
我觉得,虽然大数据体系已经有了很大的发展,但是仍然是不完善的,在以后的时间里仍然可能发生很大的变化。当然,这些都是依据我自己的一些经验,并不一定是最正确的。
下一讲,我们来看一下提到过很多次的 Hadoop 框架是如何构建的。
精选评论
**用户6284:
大致数据流程:数据采集、数据传输、数据存储、数据在线分析、数据离线分析、数据应用、数据安全、数据应用平台化、实时、体系缺点:成本高,投入/产出比例问题
**3961:
效率和成本