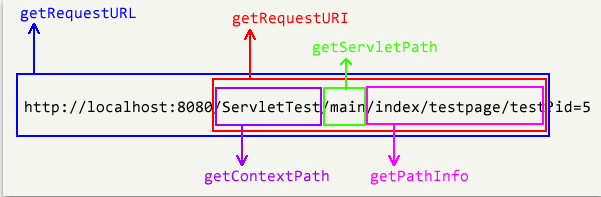
大数据架构演变
- 一、传统离线大数据架构
- 二、Lambda架构(离线处理+实时链路)-传统实时开发
- 三、Lambda架构(离线数仓+实时数仓)
- 四、Kappa架构
- 五、架构选择:
- 六、湖仓一体(流批一体)实时数仓架构
- 七、从普通项目到Hadoop,再到Spark
- 1、普通单机方式
- 2、按照分布式计算(多机器方式):
- 3、多机器优化
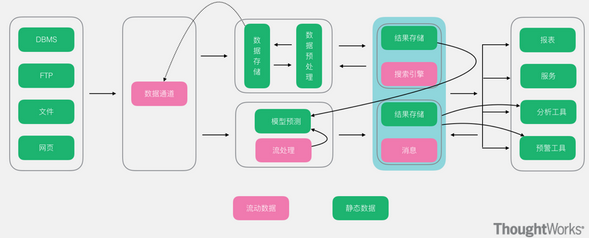
一、传统离线大数据架构

一般在刚引入大数据架构是开始使用,比较适合做批量处理,T+1数据处理等
优点是做批量计算性能比较高,特别适合做批量数据的聚合分析计算。
缺点:这种架构不好支持实时业务数据的开发。一般这种离线数仓分层计算之间都是通过Mapreduce/SparkSQL做批量处理来实现聚合分析,除了数据落库的磁盘IO等比较慢以外,还有一点就是批处理是需要数据来了以后等待一会,聚集一批数据在处理,这样数据从头到尾下来就需要等待和处理较长的时间。而对于一些对实时性要求高的数据来说,这种滞后性是无法容忍的。
二、Lambda架构(离线处理+实时链路)-传统实时开发
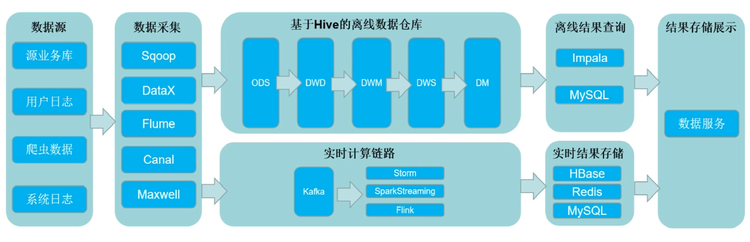
从原有离线处理架构的基础上加上了实时处理链路部分,实现了实时业务数据的处理。
对于批处理任务,还是使用原有的传统离线架构不变,支持高性能的离线批处理。
对于实时性要求比较高的场景和需求,单独采用实时链路进行开发,数据流过来了能直接处理,而不需要积累一定的时间或量级再进行处理,尽可能的提高数据从流入到结果产出的时间效率。
缺点:实时链路的业务数据处理是烟囱式的开发,不能对实时链路处理的中间结果做复用处理,每一个实时业务需求都需要从头开始做处理。
三、Lambda架构(离线数仓+实时数仓)
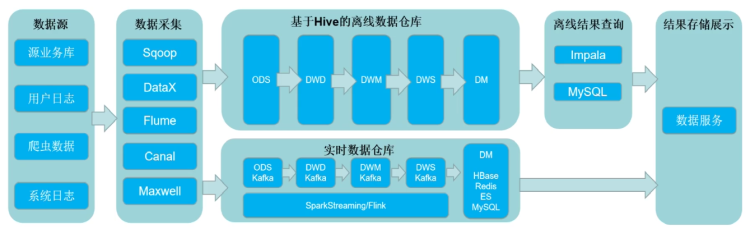
上面的实时链路没有对中间结果进行保存,当有大量的实时需求需要开发时,需要尽可能的对中间结果进行复用,以此来提交效率,因此需要把这些中间结果保存起来,使用kafka作为实时数仓。
(其实我觉得大部分应该都是这样,短链路处理就是实时链路,长链路处理就是实时数仓,对于后端开发人员来说,尤其微服务架构化之后,同一链路的各种数据处理应该都是按功能分配在不同的服务中,而服务与服务之间的数据传递,就需要用到kafka,实际这就已经类似于实时数仓了)
缺点:
- 对于离线部分和实时部分的同样业务需要开发两套代码实现
- 集群资源使用增多,既要进行实时计算也要进行离线计算
- 离线结果和实时结果不一致
- 批量计算T+1数据任务量大,可能计算不过来
- 同时需要存储两套数据,增加存储成本
四、Kappa架构
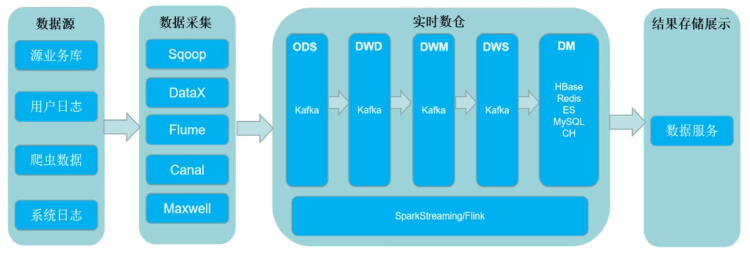
Kappa架构的点就在于,利用大数据组件(spark、flink)的延时数据处理能力,实现批、流的统一。
缺点:
- Kafka无法支撑海量数据的存储,一般只能存储一周或者半个月的数据。
- Kafka无法支持高效的OLAP,而大多数业务希望能够直接从DW层使用SQL查询数据,但这里只能间接通过Spark、Flink开发个程序再从kafka中拿数据出来进行分析。
- 无法复用数据血缘管理体系(比如后面的结果出错了,想要检查它依赖的前面的结果的正确性,却不好通过kafka来观察)
- Kafka不支持更新操作(比如部分数据有延时,在后面发过来后需要对数据做重新计算,但是kafka是一个顺序写入的基于日志的消息系统,不支持修改历史数据)
五、架构选择:
1、 刚上大数据系统,或者暂时没有实时场景
传统离线大数据架构
2、 离线业务多,实时业务少
离线数仓+实时处理链路的Lambda架构
3、公司离线业务和实时业务都比较多
离线数仓+实时数仓的Lambda架构
4、实时业务多,离线数据少
Kappa出实时数仓架构
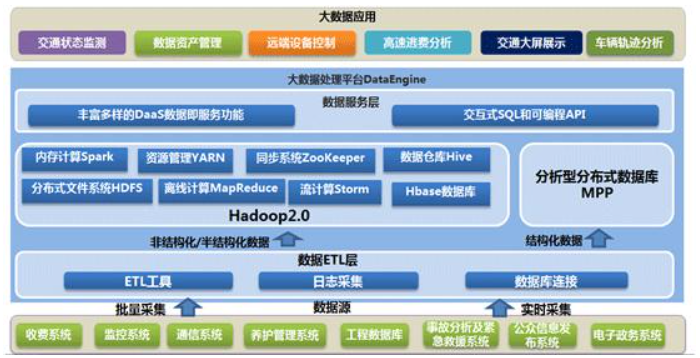
六、湖仓一体(流批一体)实时数仓架构
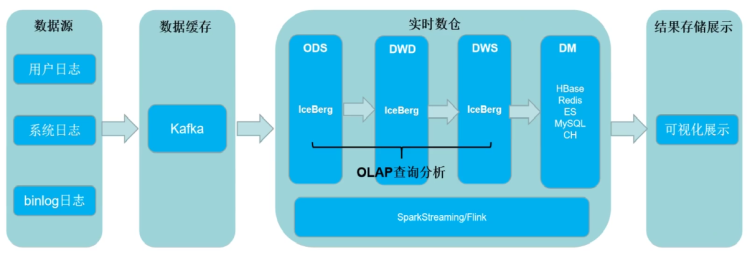
湖仓一体解决的问题:
- 存储统一,不需要再为实时和离线做两套存储
- 解决Kafka作为实时数仓存储容量小的问题
- 任意分层都可以用SQL直接做OLAP处理
- 复用同一套相同的血缘关系,不会因为实时、离线分开处理导致逻辑不一致
- 支持数据更新
这是一个折中的方案,相对于kafka做实时数仓而言,性能会比较差,但是综合性能与实时性最佳。
七、从普通项目到Hadoop,再到Spark
当一批数据之大,一台机子放不下 之时,采用Hadoop/Spark 这样的并行计算框架,就能够发挥出并行计算的魅力,使得计算能力随着机器的增多而提升。
在这里说的性能提升,并不是一批数据在内存中做处理的性能提升,因为CPU运算本来就很快,那个性能提升相对于磁盘IO而言是可以忽略不计的。在大数据项目中处理数据,主要的瓶颈就来自于磁盘IO的瓶颈,其次就是网络IO的瓶颈。
并且spark可以实现就像写单机程序一样的代码来实现多机器数据处理。
举个例子:
一个1Tb的文件,读取该文件,找出两个相同的行出来。
磁盘IO:100M/S
网络IO:500M/S
可用内存大小:10GB
1、普通单机方式
由于内存不能一次性读取这么多数据,只能按照一定的算法分批次进行处理,如下
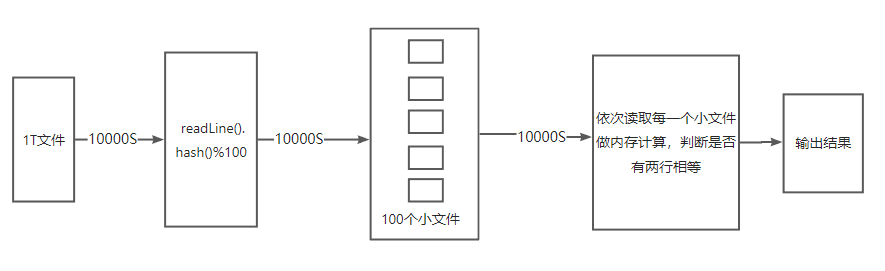
- 逐行读取1T文件
- 按照哈希取模的方式,将所有行映射到100个文件中,这能确保相同行一定映射到同一个文件中
- 依次从100个文件读取数据,在内存中判断是否有两行相等,有则进行输出
以上三个步骤总计花费500min时间。
2、按照分布式计算(多机器方式):
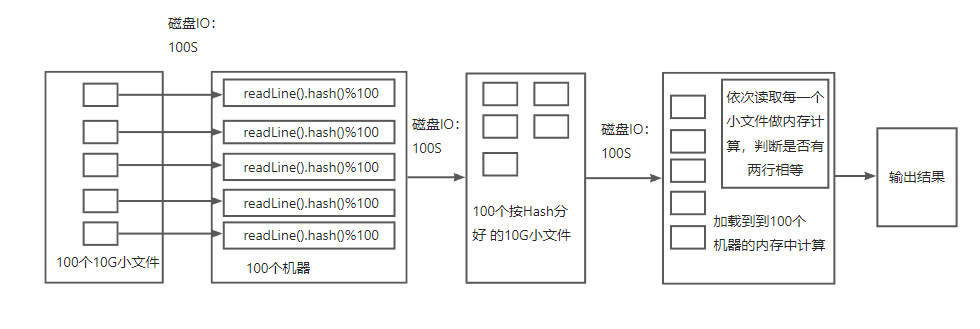
- 由于需要配合多机分布式计算,这个1TB文件应该放到多个磁盘上,防止单个磁盘成为性能瓶颈,如果数据都分布在一个磁盘上。
- 按照多台机器,就可以实现多级并行处理,先将文件加载到内存中,再使用hash取模方式将数据重新划分为100个文件,这些中间结果文件进行落盘,然后再从磁盘加载分好的小文件做内存计算,输出结果。
- 按照多台机器,就可以实现多级并行处理,共计300S时间,当然这只是理想情况下的比较,实际上可能分布式计算会有多个节点的各种损耗,而达不到实际时间=总时间/机器数的效果,但是处理效率确实就是随机器增多而增大的。
3、多机器优化
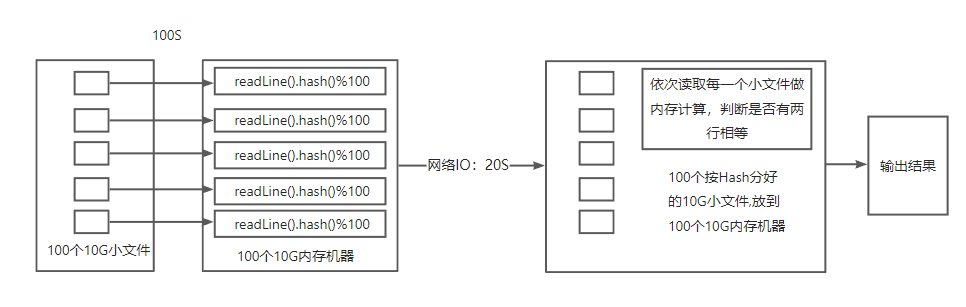
- 由于需要配合多机分布式计算,这个1TB文件应该放到多个磁盘上,防止单个磁盘成为性能瓶颈,如果数据都分布在一个磁盘上。
- 按照多台机器,就可以实现多级并行处理,先将文件加载到内存中,再使用hash取模方式将数据重新划分为100个文件,这个过程在多机器的内存和网络中进行数据交换,这中间结果不涉及数据落盘,然后再对每一个分好的小文件做内存计算,输出结果。
- 按照多台机器,就可以实现多级并行处理,共计120S时间,相对于上一种方式,是中间结果不落库的方式,减少了数据写入磁盘和重新从磁盘读取的次数,从而加快了速度。