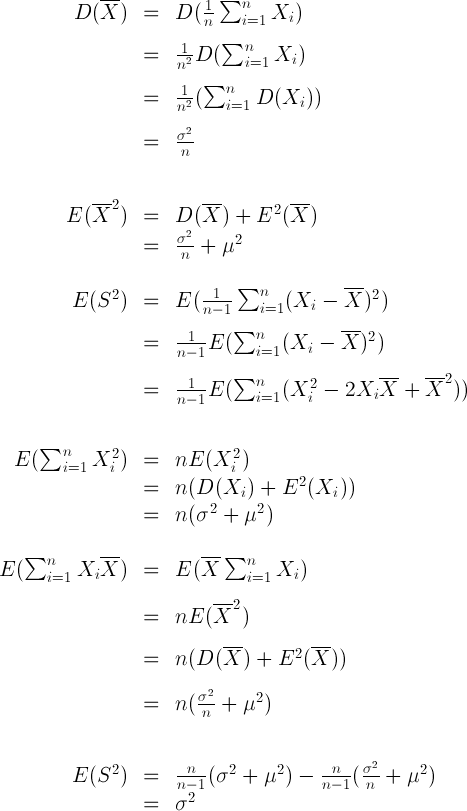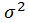最近在学习链表,看到书上说可以采取每次在链表头部插入新增节点的方法,将链表逆序,也就是建立的链表节点内容与数据的输入顺序相反。我便来了兴趣,想着试试看,结果没搞懂,于是开始百度。看了几遍博客后终于是明白了,而后写作的兴趣又上来了。。。。一个初学者就算再怎么来了兴趣,也不可能写得很好,所以有不对的地方,欢迎大家指出!顺便这里附上一篇写得很好的博客:点击蓝色字体。我正是看了这篇博客才大概弄懂了链表逆序,还自己手画链表才理解的。
博主要讲的单链表逆序有5种(感觉不止,但是博主只会5种):
一、用数组接收链表的数据,然后控制下标输出
简单的说一下这个方法的思路吧:其实很简单,就是通过链表的遍历,将链表中的数据一一赋值给一个数组。然后控制下标进行输出。
我看了几篇博客,发现他们都是用自定义的函数来介绍链表逆序的,这对初学者有些不友好(问就是我是初学者),所以我直接这里就拿一个最简单的动态链表运用来举例子,直接上代码:
#include<stdio.h>
#include<stdlib.h>//malloc()函数的头文件
struct node{//定义结构体int id;node *next;//尾指针
};
int main()
{node *head=(node*)malloc(sizeof(node));//为都指针head开辟空间node *s=head;//命名一个动态指针,且让它指向头指针 scanf("%d",&s->id);//进行数据输入while(s->id!=0){//当输入的数据不为0时,继续输入,当然,也可以用-1等其他的数字来代替,并不唯一s->next=(node*)malloc(sizeof(node));//s此时的节点已经被存入了一个数据,所以要开辟下
/一个节点来进行下一个节点的输入s=s->next;//将刚指针s指向刚开辟的指针,实际就是将s代表的节点换为下一个节点//当然,之前的数据已经存到链表里面了scanf("%d",&s->id);//继续输入数据}s->next=NULL;//最后将尾节点的指针指向空,也就是NULLs=head;//令指针s重新指向头节点,后面遍历将值赋给数组int a[10000]={0},i=0;//定义数组while(s!=NULL){a[i++]=s->id;//给数组赋值s=s->next;}i--;//数组下标的运用for(;i>=0;i--){printf("%d ",a[i]);//输出开头第一个为0,之前说到的标记,也可以用一个条件语句让0不输出}return 0;
}简单介绍下malloc()函数:malloc()括号内就是指开辟空间的大小,只是为了完美的开辟一个不大不小,刚好合适的空间,我们用sizeof()语句来获取已经定义的结构体的大小。最后就是malloc()函数返回的数据类型是(void*),所以我们在运用时要进行类型的强制转换,也就是在前面加上(node*)(node*是我定义的结构体的类型)
最后说一下这种方法的缺点:学过链表的都知道,链表与数组相比,最大的优势就是可以动态分配内存空间。所以这个方法的缺点就是太浪费空间。链表是可以无限输入输出的,但是通过数组来进行逆序输出,再无限也变得有限了,因为我们不知道输入的数据有多少个,只能提前定义一个比较大一点的数组来进行逆序。而数据少了,浪费空间;数据多了,数组空间不足。
二、用三个指针遍历单链表,将链接点一一进行反转
如下图,这是一个单链表,上面是数据域,下面书指针域,第一个节点就是头节点,最后一个节点的尾指针指向NULL。

这个方法就是用三个指针将图中每个节点二点指向反向(也就是箭头反指)。看图:

这样,将每一个节点的指向反转。将逆序前的头指针指向空,最后就可以得到逆序的链表了,下面是实现代码(用的例子都是一样的,只是链表的逆序方法不同,就不像第一个方法那样打那么多注释了):
#include<stdio.h>
#include<stdlib.h>
struct node{int id;node *next;
};
int main()
{node *head=(node*)malloc(sizeof(node));node *s=head;scanf("%d",&s->id);while(s->id!=0){ s->next=(node*)malloc(sizeof(node));s=s->next;scanf("%d",&s->id);}s->next=NULL;//node *p,*q,*r;//用三个指针将链表逆序 p=head;//将p、q指向链表的前两个节点 q=head->next;head->next=NULL;//链表逆序后原来的头指针变为空 while(q!=NULL){//将链表的顺序一个一个反转 ,因为链表原来 r=q->next;//的排序最后一个节点为空,所以当链表逆序完成后,q指向的节点其实为空q->next=p;//而p指向的节点就是逆序后的头节点p=q;q=r;}head=p;s=head;//让指针指向头节点开始逆序输出while(s!=NULL){//遍历逆序后的链表printf("%d ",s->id);s=s->next;}return 0;
}要理解上面的代码最重要的是(博主的个人理解):要理解 指针->next= 其实就是上面两个图中的箭头,指针指向谁,箭头就指向谁,因为单链表中每个节点都只能指向一个节点,将一个节点的指针指向一个新的节点,那这个节点原来指向的那个节点的箭头就自动断开。
三、从第2个节点到第N个节点,依次逐节点插入到第1个节点(head节点)之后,最后将第一个节点挪到新表的表尾。
还是得看图理解:
| 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 3 | 2 | 4 | 5 | 6 |
| 1 | 4 | 3 | 2 | 5 | 6 |
| 1 | 5 | 4 | 3 | 2 | 6 |
| 1 | 6 | 5 | 4 | 3 | 2 |
| 6 | 5 | 4 | 3 | 2 | 1 |
对于一条链表,从第2个节点到第N个节点,依次逐节点插入到第1个节点(head节点)之后,(N-1)次这样的操作结束之后就得到上图。
最后在将第一个节点连接到新表的结尾就完成链表的逆序了。
下面是实现代码:
#include<stdio.h>
#include<stdlib.h>
struct node{int id;node *next;
};
int main(){node *head=(node*)malloc(sizeof(node));node *s=head;scanf("%d",&s->id);while(s->id!=0){s->next=(node*)malloc(sizeof(node));s=s->next;scanf("%d",&s->id);}s->next=NULL;node *p,*q;p=head->next;while(p->next!=NULL){q=p->next;p->next=q->next;q->next=head->next;head->next=q;} //在上面的表格中p->next=head;//将尾节点指向头节点,形成一个环,也就是将末尾的2与1相连head=p->next->next;//将6定义为头节点p->next->next=NULL;//然后将1和6之间的连接断开,也就是将节点1指向空,作为末尾s=head;//最后遍历输出while(s!=NULL){printf("%d ",s->id);s=s->next;}
}四、用递归
要用递归来进行逆序的话,就不得不使用自定义函数了:
#include<stdio.h>
#include<stdlib.h>
struct node{int id;node *next;
};
node *reversal(node*p){//定义函数if(p==NULL||p->next==NULL){//少于两个节点不需要反转return p;}node *newhead=reversal(p->next);//不断调用自身函数,最后头节点会变成原来的最后一个节点p->next->next=p;p->next=NULL;return newhead;
}
int main()
{node *head=(node*)malloc(sizeof(node));node *s=head;scanf("%d",&s->id);while(s->id!=0){s->next=(node*)malloc(sizeof(node));s=s->next;scanf("%d",&s->id);}s->next=NULL;head=reversal(head);//通过自定义函数获取逆序后的头结点s=head;while(s!=NULL){//一样的遍历输出printf("%d ",s->id);s=s->next;}return 0;
} 五、用头插法不断将新的数据插入链表头部
直接看代码:
#include<stdio.h>
#include<stdlib.h>
struct node {int id;node *next;
};
int main(){node *head=(node*)malloc(sizeof(node));node *p=head;scanf("%d",&p->id);head->next=NULL;while(p->id!=0){//以0为结束标志node *q=(node*)malloc(sizeof(node));//开辟一个节点q->next=head;//将这个节点插入头节点head=q;p=q;//或是p=head也可以scanf("%d",&p->id);//重新对头节点进行输入}p=head;while(p!=NULL){printf("%d ",p->id);p=p->next;}
}