目标检测:锚点介绍及应用
- 介绍
- 应用
- 生成锚点图
- 步骤
- 锚点匹配
- 步骤
介绍
锚点相当于在待预测的特征数据上预设出可能的物体边界框,即预设出特征数据可能代表的物体区域,每个区域通常由两个属性构成——尺度(scale或size)和比例(ratios),即区域面积和区域矩形的宽高比例,也可以是锚点宽高数据。每个锚点都是在特征图像素点的基础上设置的,在设立锚点之前,每个像素点都可以代表原始图像的一个小区域,称为感受野,如果特征数据的感受野较大,则说明该特征可以代表原始图像较大的区域,一个特征数据的感受野越大,则说明该特征可以**“看”**到越大的区域,因此该特征上锚点尺度就应该越大(后续FPN会用到这一概念),例如在Faster R-CNN中,作者在最后一个特征层上做预测,尺度被设为 12 8 2 、 25 6 2 、 51 2 2 128^2、256^2、512^2 1282、2562、5122,比例被设置为 1 : 1 、 1 : 2 、 2 : 1 1:1、1:2、2:1 1:1、1:2、2:1,因此特征图上每个像素点往往对应多个锚点,从而对应原图多种区域,进一步可以对应多种可能存在物体的区域。
注意:
- 同一特征可以同时预设多个尺度不同的锚点,即锚点尺度和特征感受野无一一对应关系,但他们往往是正相关的,即大感受野往往对应较大的锚点,反之亦然。如果特征感受野较大,则该特征往往对应大的尺度,即预测大的物体,因为它们可以看到更大的区域,又因为它们看到的区域比较大,因此预测小物体会不准,因为容易被同一区域内的其他物体所干扰。
- 为了同时检测大物体和小物体,实际的目标检测算法往往在多组特征图上部署锚点,实现多尺度目标检测的功能,可以参考FPN网络;
- 锚点尺度可以大于特征感受野,通俗来讲即使一个特征只能看到物体的一半,但他也可以利用这一半来预测整个物体。

应用
生成锚点图
每个特征数据对应一组锚点,每个锚点对应原图上的一个小区域,如果想利用所有的锚点图参与边界框预测,必须要将每个锚点所对应的区域以坐标的形式表示出来,也就是将每个锚点区域表示出来,得到一组坐标数据(这里的坐标对应原始图像的绝对坐标),比如在上图中,要将右侧彩色框的坐标表示出来,并且和左图的特征数据做好对应关系。
步骤
- 给定原始图像尺寸、特征图的尺寸(可以是多个,对应不同特征层参与预测)和每个锚点的尺寸(例如Faster R-CNN中的size和aspect_ratios,也可以是YOLO中的宽高数据);
- 根据给定的锚点尺寸生成锚点模板坐标;
- 利用原图尺寸和特征图尺寸计算步长,之后将特征图像素点按等比映射到原图区域位置(相当于感受野左上角,网格的交汇点),得到特征数据在原图上的映射坐标,坐标等距分布;
- 映射坐标和锚点坐标相加,做一次坐标偏移,得到原图上的锚点图。
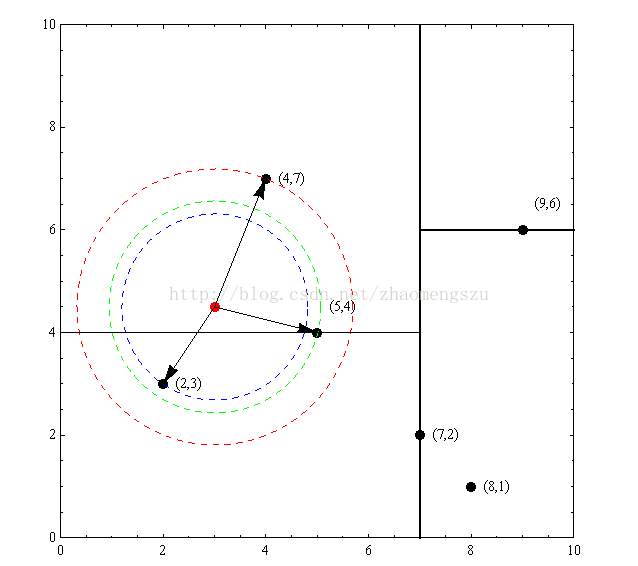
锚点模板
以像素点为中心的一组锚点图,表示每个特征数据上的所有锚点框。以坐标的形式储存,(0,0)表示锚点中心,即原图像素点,如下图所示:

上图一共有九个框,表示当前特征(特征层)对应九个锚点,不同颜色代表不同的尺度,九个锚点对应3*3,即3个尺度、3个比例。(引自Faster R-CNN算法)
注:
- 并非所有的目标检测算法都需要生成锚点图,例如YOLO算法修改了检测机制,不需要生成整张图像的锚点数据,只需要筛选“前景锚点”,之后再根据前景锚点坐标数据生成指定的锚点框即可;
- 具体代码实现方法见:锚点生成器
锚点匹配
在训练过程中,我们不仅需要利用锚点预测出边界框来,还需要指导每个锚点样本预测的对不对,利用期望值与预测值之间的差额来优化网络参数,也就是需要对每个锚点打标签,判定该锚点是属于背景还是前景,如果是前景则需要再指明是属于标签中的哪个物体(第几个前景),便于后续给锚点生成锚点标签(即属于该锚点的物体类别和对应的回归参数)。
步骤
Faster R-CNN机制
不同的预测机制具有不同的锚点匹配步骤,如果想利用整张图中所有的锚点参与预测(例如Faster R-CNN和RetinaNet算法),则需要根据每个锚点所代表的区域与物体边界框区域打标签,步骤如下:
- 给定前景阈值、背景阈值、前景边界框坐标与锚点边界框坐标;
- 逐一计算每个锚点与所有前景之间的IoU值,得到IoU矩阵;
- 对IoU矩阵,沿物体方向求最大值,即得到每个锚点最大的IoU值及对应的前景物体;
- 逐一判断每个锚点的最大IoU数值,大于前景阈值的标记成对应前景的序号、小于背景阈值的标记成-1,介于二者之间的舍弃,默认标记成-2。
注:
- 若该锚点属于前景,则对应值为 [ 0 , M − 1 ] [0, M-1] [0,M−1],其中M为当前图片的物体数量,使每个属于前景的锚点都有一个真实前景物体做对应,便于后续生成类别标签以及回归参数标签;
- iou值计算公式:
IoU = S a ∩ t S a ∪ t \text{IoU}=\frac{S_{a\cap t}}{S_{a\cup t}} IoU=Sa∪tSa∩t
其中下标 a a a和 t t t分别表示锚点区域和前景标签区域,也就是相交的面积除以相并的面积。
YOLO机制
如果只期望利用边界框附近,并且形状相似的锚点参与预测(例如YOLO算法),则只需要筛选出指定的锚点(即前景锚点),并且打上标签即可,步骤如下:
-
逐一计算物体边界框和预设锚点模板之间的IoU(默认0.2),对于每个物体匹配出宽高比例比较像的预设锚点(这里每个物体可能会匹配多个锚点模板);
-
之后将每个预测特征数据视为一个网格,边界框中心坐标向下取整,得到网格左上角坐标,用于判断物体边界框属于哪个预测特征,该特征上的锚点才可能是前景锚点,再结合刚才匹配到的预设锚点,得到前景锚点,前景锚点满足两点:宽高比例和物体边界框宽高比例类似、物体中心位于该锚点内部(也就是网格内部);
-
对于每个匹配到的锚点,逐一计算网格左上角坐标和边界框中心之间的偏移量,并且再提取对应边界框的宽高数据,得到锚点的坐标标签,之后根据中心点坐标得到置信度标签,再利用锚点与边界框之间的IoU(或GIoU)对置信度标签做加权处理(宽高比例越像,权重越大)。
注:以上仅是笔者个人见解,若有问题,欢迎指正。