KNN
KNN即k-nearest neighbor(k近邻法),多应用于分类问题。
k近邻法的输入为实例的特征向量,对应于特征空间中的点。输出为实例的类别。
K近邻法原理
给定一个训练数据集,对新的输入数据,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该实例分为这个类。
K近邻算法
输入:训练数据集
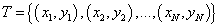
其中xi为实例的特征向量,yi为实例的类别
输出:实例x所属的类y
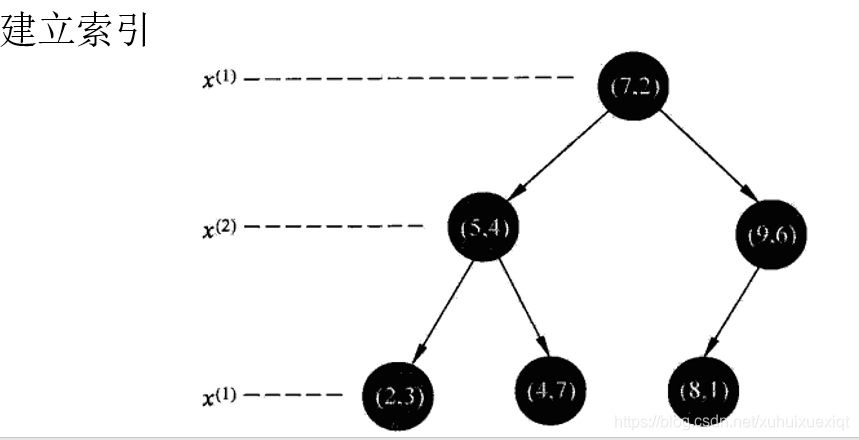
K近邻模型
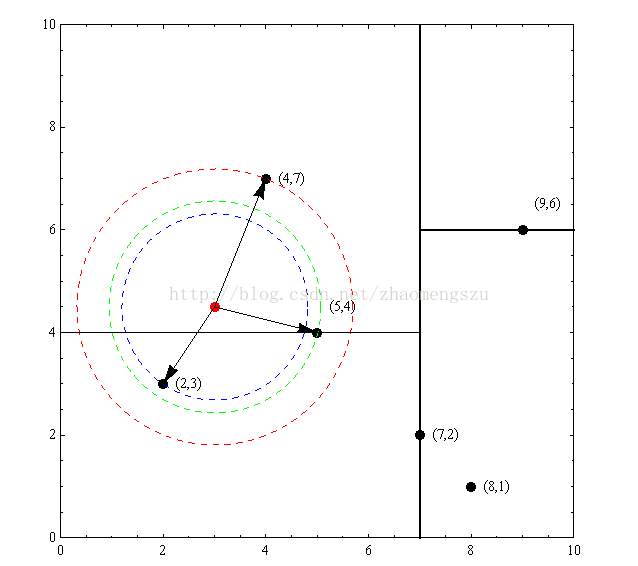
特征空间中,对每个训练样本Xi,距离该店比其他点更近的所有点组成的一个区域,叫做单元(cell)。每个训练实例点拥有一个单元,所有训练实例点的单元构成对特征空间的一个划分。KNN将实例Xi的类Yi作为其单元中所有点的类标记(class label)。下图是二维特征空间划分的一个例子。
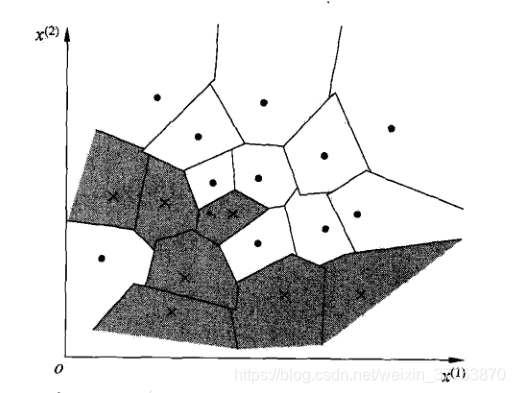
模型的三要素——距离的度量、模型的选择、分类决策规定。
距离的度量——特征空间中两个实例点的距离是两个实例点相似程度的反映。k近邻模型的特征空间一般是n维实数向量空间 R n R^n Rn。使用的距离是欧式距离,但也可以是其他距离。
设特征空间X是n维实数向量空间 R n R^n Rn, x i x_{i} xi, x j x_{j} xj属于空间X, x i x_{i} xi=( x i 1 x_i^1 xi1, x i 2 x_i^2 xi2,…, x i n x_i^n xin)T, x j x_{j} xj=( x j 1 x_j^1 xj1, x j 2 x_j^2 xj2,…, x j n x_j^n xjn)T, x i x_{i} xi, x j x_{j} xj的距离定义为
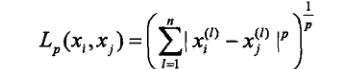

K值的选择
k值的选取会对k近邻法的结果产生重大影响。
如果选取的k值较小,就相当于在较小的邻域中的训练实例进行预测,“学习”的近似误差会减小,只有与输入实例较近的训练实例才会对预测结果起作用。但缺点是“学习”的估计误差会增大,预测结果会对近邻的实例点非常敏感。如果近邻的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合。
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大意味着整体的模型变得简单。
在应用中,k值一般取一个比较小的值。通常采用交叉验证法来选取最优的k值。
KNN实现判断癌症代码
import csv
import random#读取
with open(r"J:\KNN源码及数据集\prostate-cancer\Prostate_Cancer.csv") as file:reader = csv.DictReader(file)datas = [row for row in reader]random.shuffle(datas) #打乱数据的顺序#分组
n = len(datas)//3
test_set = datas[0:n] #测试集
train_set = datas[n:] #训练集#KNN
#将传入单个字典
def distance(d1,d2): #求距离res = 0for key in ("radius","texture","perimeter","area","smoothness","compactness","symmetry","fractal_dimension"):res += (float(d1[key])-float(d2[key]))**2return res**0.5 k = 6#将传入单个字典
def knn(data):res = [{"result":train["diagnosis_result"],"distance":distance(data,train)} #1.距离for train in train_set]sorted(res,key = lambda item:item['distance']) #2.排序-----升序#取前K个值res2 = res[0:k]#加权平均(result是最终判据)result = {'B':0,'M':0}#总长度sum_dist = 0for r1 in res2:sum_dist += r1['distance']#逐个分类加和for r2 in res2:result[r2["result"]] += 1-r2["distance"]/sum_distprint(result)if result['B'] > result['M']:return 'B'else:return 'M'#----------------------------------------------------------------------#correct = 0
for test in test_set:result = test['diagnosis_result'] #真实结果result2 = knn(test) #测试结果if result == result2:correct = correct + 1;print(str(correct/len(test_set)))
网盘链接
提取码:h04t