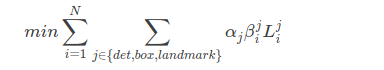人脸检测算法总结:PyramidBox
- Introduction
- PyramidBox
- Training
PyramidBox是百度提出的人脸检测算法,提出后在widerface上排第一(现在已经不是了,但仍居前三),PyramidBox可以看做是S3FD的升级版,其各种操作都是在S3FD的基础上改进的。
Introduction
首先简单介绍了人脸检测的发展,SSH、S3FD通过设计具有尺度不变性的网络结构,在单个网络的各个特征金字塔上检测不同尺度的人脸。如何通过人脸的上下文信息(contextual information)来辅助人脸检测,一直是被忽略的方向,因为人脸一般都不会单独的存在与图像中,一般都会包含头、肩、身体等部位,当人脸由于遮挡、低分辨率、模糊等情形不容易被检测时,这些上下文的信息其实是可以辅助人脸检测的。本文的PyramidBox通过结合上下文信息,以辅助人脸检测。
1,提出PyramidAnchors,设计 contextual anchor 通过半监督的方法,来说学习高层特征的上下文信息,具体的,结合了人头,身体等信息,以检测出小尺度,模糊,遮挡的人脸。
2,设计了Low-Level Feature Pyramid Network(LFPN),联合合适的高层语义信息(不使用高层,而是中间feature map层)+低层feature map 特征。以检测所有尺度的人脸。这么做的出发点是作者认为大小尺度人脸所包含的信息量是不一样的,并非所有高层feature map上的信息对小尺度检测都有帮助。
3,提出了Context-sensitive prediction module(CPM),借鉴了SSH,使用wider + deeper的网络结构,融合人脸附近的contextual information,并提出max-in-out提升分支中人脸检测和分类的准确率。
最后,文章还提出了全新的训练策略Data-anchor-sampling(DAS)来调整数据分布,通过数据增强的方式提升小尺度人脸的多样性。
PyramidBox
1.Network architecture

Scale-equitable Backbone Layers
使用S3FD的backbone(VGG16)和extra layers,同时采用S3FD的等比例间隔策略,使得不同feature map上anchor具有相同的采样密度。
Low-level Feature Pyramid Layers
为检测大尺度范围内变化的人脸,并利用高低层feature map各自优势(高层feature map蕴含高语义信息,大感受野,方便检测大尺度目标;低层feature map包含更多的细节信息,小感受野,方便检测小尺度目标);将高层低层信息结合主要是FPN式的结合,一般都用了最高若干层的feature map。但PyramidBox认为最高层的feature map特征不利于小尺度人脸的检测,原因有二:1,小尺度、模糊、遮挡的人脸与大尺度人脸包含不同的信息,如果简单粗暴地融合大尺度目标检测的高层feature map来辅助检测小尺度目标是不合适的。2,高层特征包含人脸区域的上下文特征较少,不能帮助到小尺度人脸检测,相反会引起噪声。比如Pyramidbox中conv7-2、conv6-2的理论感受野是724,468,而输入训练的图像尺度是640,也即640pix图像中若包含大尺度的人脸,该人脸将占满整个图片,感受野范围内的上下文信息就比较少了,因此不利于中小尺度人脸的检测。
PyramidBox 中提出的LFPN,灵感来自于FPN,融合了高低层feature map的特征,但是是从中间层开始的,而不是从最高层开始的。获得感受野的尺寸刚好为图像尺度的一般。其具体操作如下图。

Pyramid Detection Layers
采用6个feature map并设置相应的anchor(16,32,64,128,256,512)
Predict Layers
输出多个通道,用于face,head,region的分类和回归,其中人脸的分类借鉴了S3FD的max-in-out,需使用4(=cpl+cnl)通道,cpl,cnl分别是fg/bg label的max-in-out输出:
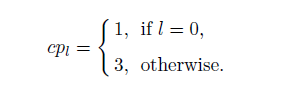
如上所示,最底层的fg为1,其他层为3。
人头、人体的分类分别需要2通道预测(fg / bg),人脸、人头、人体的定位分别需要4通道(x1、y1、x2、y2;或x、y、w、h)。
2 Context-sensitive Predict Module
Predict Module
SSH通过在不同分支上不同的stride+conv堆叠来扩展感受野大小,学习更多的contextual information,而DSSD使用residual block,得到deeper的预测分支,PyramidBox借鉴了两种思路,提出了CPM。将SSH中的context module中的conv层换成DSSD的残差预测模块,这样CPM同时包含了DSSD+SSH的上下文信息的优势。具体结构见下图。

max-in-out
借鉴了S3FD,不过S3FD只在conv3-3层使用。PyramidBox在所有的层上都使用,不过在不同的层,cp的数量不同,在低层cp=1,因为低层预定义的anchor较小,就有较多的小尺度的false negative,其它层cp=3,这样可以召回更多的人脸检测目标。
3 Context-reinforced PyramidAnchors
S3FD通过等比例均衡采样策略让不同层feature map上的anchor有相同的采样密度,有利于地城feature map上小尺度人脸的检测,但anchor只针对于人脸,忽略了上下文的信息。PyramidAnchors可以结合人脸人头人体等上下文信息。
对于每个人脸gt bbox,PyramidAnchors生成一系列包含人脸上下文信息的更大尺度anchor,如包含了head、shoulder、body等。PyramidBox通过将gt bbox与anchor尺度匹配的方法,将anchor分配到对应的feature map层;可以让高层feature map从底层人脸尺度(lower-level scale faces)中学到更多有益特征。理论上只要对head、shoulder、body附加额外标签,就可将anchor与gt bbox做准确地匹配以生成loss;但如果对head、body添加额外的标定信息就太不公平了,因此PyramidBox使用半监督学习的方式来学到这些标签。基于假设为:不同人脸的相同尺度、长宽比区域有相似的上下文特征;也即,PyramidBox使用一组统一的bbox来逼近head、shoulder、body的实际区域,只要不同人脸中这些bbox的特征是相似的即可。
假设原图中人脸gtbox在region_target位置,anchor_ij定义为:第i层featuremap上的第j个anchor,其尺度为si版pyramid-anchor-ij的第k个标签为:
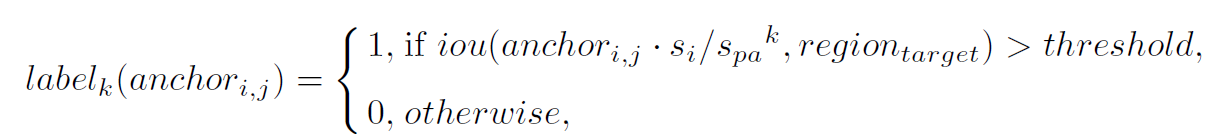
Spa为anchor的stride(取2),anchor_ij_si表示原图上anchor_ij对应的区域,anchor_ij_si/s_pa^k表示通过stride=s_pa的k次方后的做下采样得到的区域。
通俗来讲就是在相邻的三个feature map上生成3个目标,分别表示face,head,body。
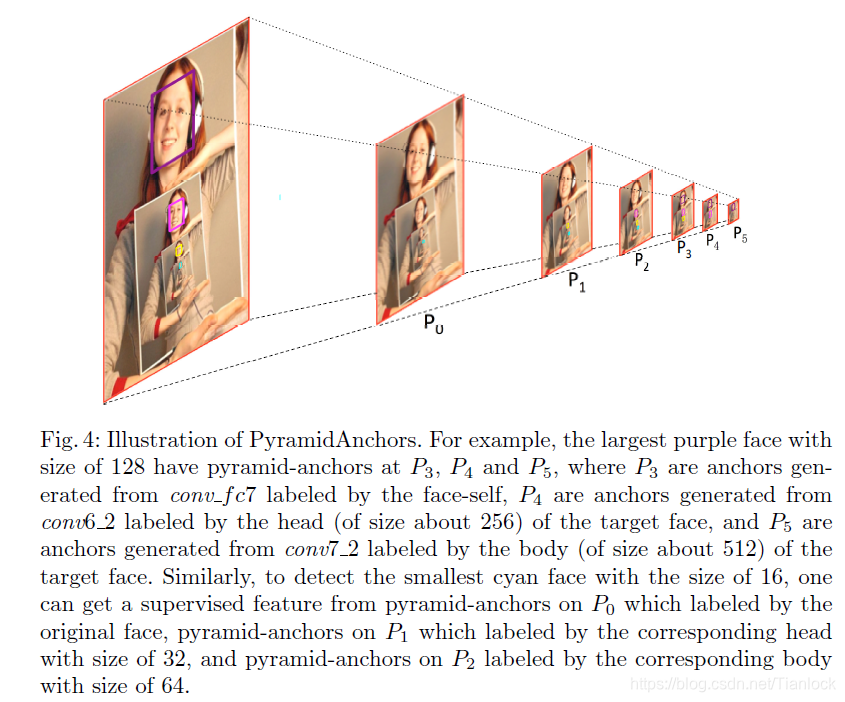
受益于PyramidAnchors,PyramidBox可以更好地检出小尺度、模糊、遮挡人脸,PyramidAnchors的自动生成无需额外标定信息,这种半监督学习方法可以让PyramidAnchors获取近似的上下文特征;前向预测时,PyramidBox仅使用人脸检测分支,不使用人头、人体分支,因此对比标准anchor-based检测器,前向时不需要额外的计算开销。
这里再加一些我的理解:pyramid anchor的操作,我认为首先是对常规的anchor匹配gtbox,然后对匹配后的anchor进行在原图的区域进行下采样,如果更gtbox的iou仍大于阈值,那么在对应的下一层featuremap上的anchor其实就是head信息且标注为1.以此类推,这是标注。在测试时,pyramid仅预测人脸,但是在下一层anchor的对应位置即为head,然后计算head的损失。
Training
Data anchor sampling
1.从图像中随机选择一个Sface的人脸gtbox,
2.从(16,32,64,128,256,512)anchor中找到匹配该gtbox的anchor尺度S1。
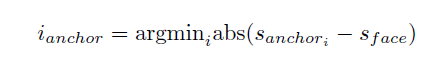
3.从目标(16,32,64,S1*2)中随机选择一个尺度S2。
4,对包含Sface的原图进行resize,resize的scale=S2/Sface
5,从resize之后的图片中crop成640×640大小的图进行训练。
比如:
step 1 随机选择一个人脸,假设其尺度为140 pix;
step 2 找到与之最匹配的预定义anchor尺度,128 pix;
step 3 从{16、32、64、128、256}中随机选择一个目标尺度,如32 pix;
step 4 将包含140 pix人脸的原图img1,做scale = 32 / 140 = 0.2285的resize,得到img2;
step 5 从img2中crop出包含该人脸的640 x 640子图像
DAS操作可以改变数据的分布:1提升小尺度人脸的占比,2通多大尺度人脸生成小尺度人脸,以增加小尺度人脸的多样性。
损失函数
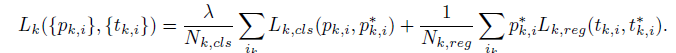
和FasterRCNN一样,不再过多介绍。
对比试验
1.LFPN这种“自中向下”融合中层feature map信息至低层feature map的方式能取得非常好的性能;
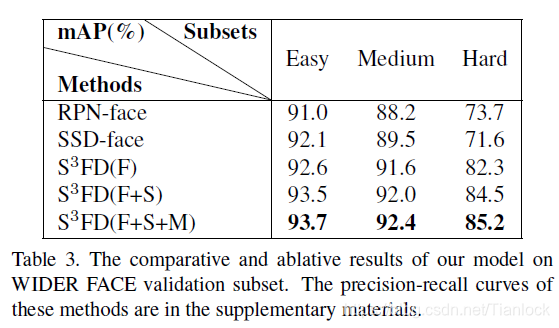
2.基于LFPN的DAS策略也能进一步提升PyramidBox的性能,在wider face验证集上分别提升了0.4%、0.4%、0.6%(easy、medium、hard,可参照table 4),可见DAS对大、中、小尺度人脸的检测性能都有提升;
3.上下文信息对人脸检测帮助很大,PyamidAnchor比常规anchor能提供更多的监督信息
4.CPM比DSSD、SSH性能都好,且大尺度感受野能提升分类、定位的准确度
5.max-in-out对PyramidBox的性能也有提升
结论
正如对比试验所示,上面的5个创新点均提高了精度。
另外,PyramidBox的代码百度已经开源,但是是百度自己的框架PaddlePaddle写的,我自己试过的pytorch的版本,精度上来说想比较于百度的版本还是稍差一点,在widerface上的精度没有论文中的那么高。
本文参考:https://zhuanlan.zhihu.com/p/41300221