1.爬虫目的
用通俗易懂的话来说,是对多种类型数据(如文字,图片,音频,视频等)进行批量式的采集与存储。
本文为个人一些学习心得,举例对网页进行信息爬取操作,使用python中基础的方法进行爬取,便于理解学习。
2.爬虫准备
需要对python有一些基础,对字符串,列表,循环结构等有了解。需要对HTML语言有一些了解,能看懂结构即可。
3.爬虫流程
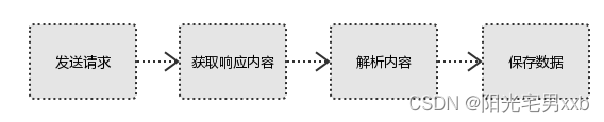
选取目标数据源(以网站为例)→向目标网站发起网络请求→获取目标的响应数据→对信息进行选取→利用表达式或方法(如正则表达式,xpath方法等)进行信息匹配→获得信息并储存
4.调用模块概要
4.1 request模块是用于模拟浏览器向目标网址发送网络请求并获得响应数据的模块。
4.2 lxml模块是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据。
其中的etree函数,主要可以用来解析XML字符串,也是基础的解析方法。
5.爬取实例
刚开始学习爬虫时,厌倦了一成不变的桌面壁纸,于是便找到一个小众的壁纸网站Awesome Wallpapers - wallhaven.cc,想大量爬取图片来更换桌面壁纸,算是一些个人的兴趣爱好了,以下是我的代码实现,注释较为详细。
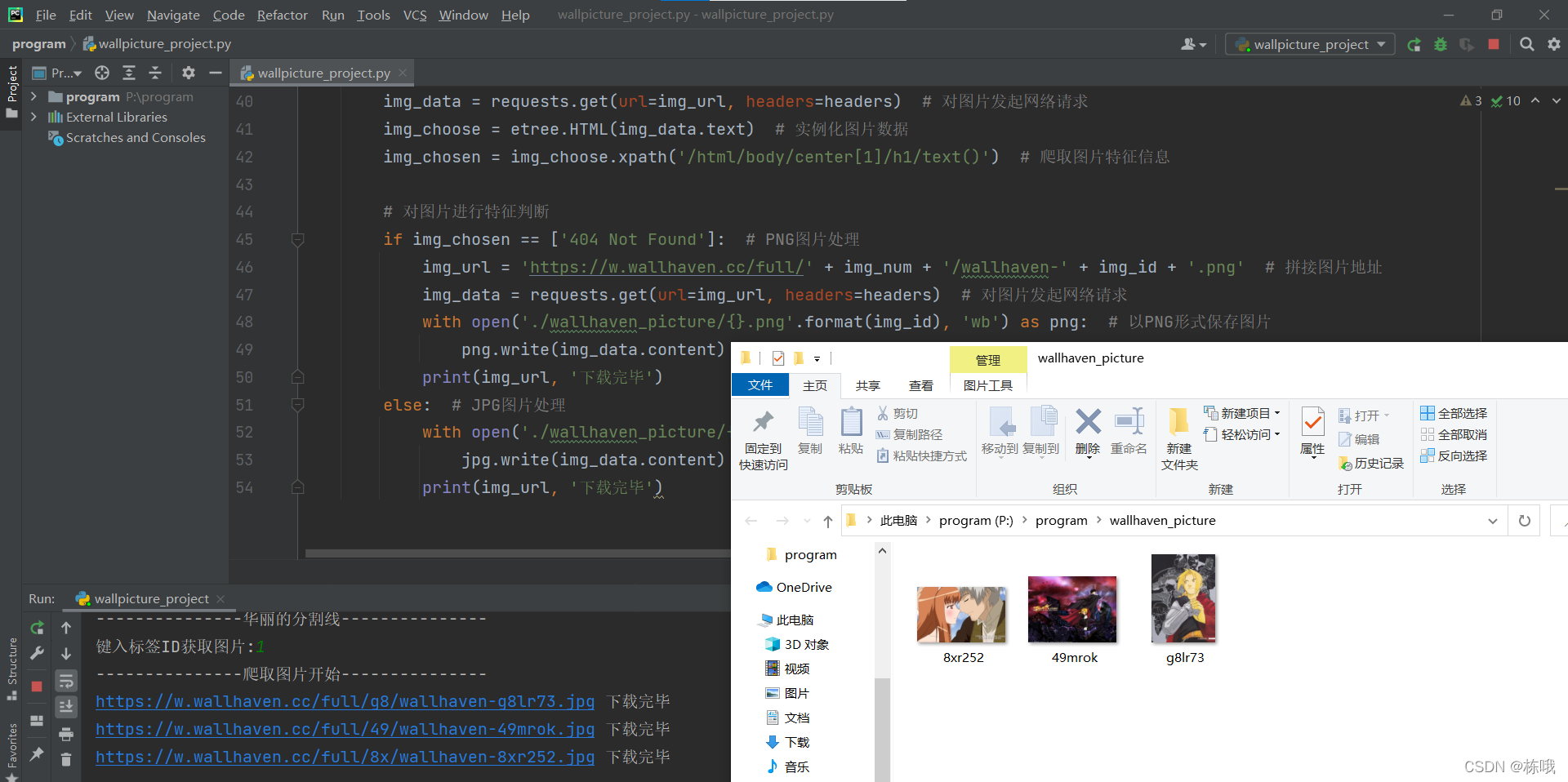
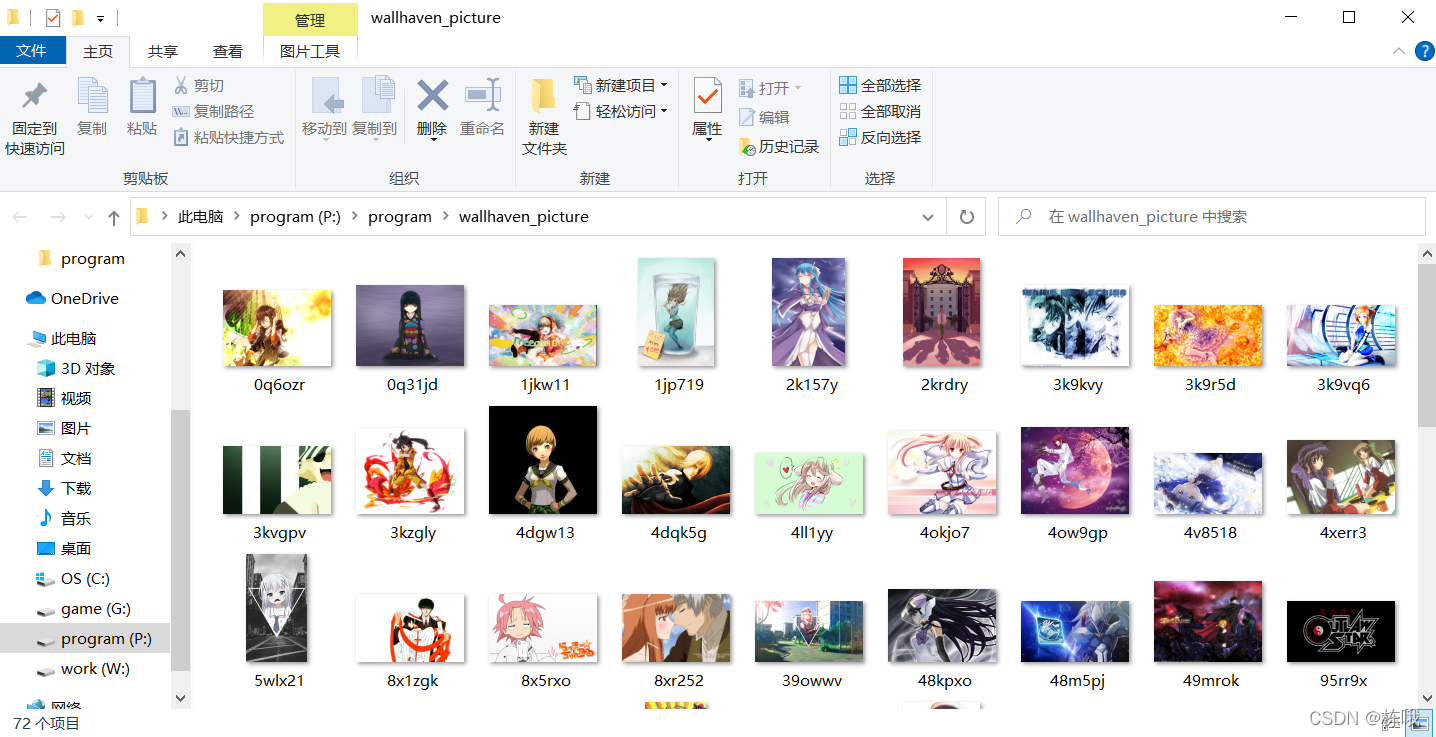
6.爬取成果
# 导入模块
from lxml import etree
import requests
import os# 创建文件夹
if not os.path.exists('./wallhaven_picture'):os.mkdir('./wallhaven_picture')# 准备参数(进行UA伪装)
# 为了防止恶意访问造成网站损失,大部分网站都有设置有反爬机制
# UA伪装即伪装成浏览器来获取数据,以免遭到反爬机制拦截
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.4281.147 Safari/532.36 Edg/87.0.632.15'}# 爬取热门标签
# request的get方法能帮助我们模拟对网站发起请求
# request的get方法有几个参数,这里使用了url即目标网站;headers即用于伪装的身份信息
# etree用于接收目标网站的反馈数据,为此实例化一个tree的对象,到此完成获取目标网站的全部数据
# xpath是用于在全部信息中找到我们所需要的信息,如文字,图片等等(也可以使用正则表达式等)
# xpath方法中定位信息需要简单看懂HTML的结果与其中包含的标签信息,这里不赘述
# tips:csdn中有很多大佬讲解的HTML语音与结构,可以打开一个网页按F12去试着定位信息
# tips:在定位到需要的信息是,可以右击复制xpath路径能帮助去更好去理解结构
url_tag = 'https://wallhaven.cc/tags/popular'
# 对标签页发起网络请求
response = requests.get(url=url_tag, headers=headers)
# 实例化标签页数据
tree = etree.HTML(response.text)
# 爬取所有标签信息
tag_list = tree.xpath('//div[@class="taglist-tagmain"]/span[@class="taglist-name"]')
print('---------------当前热门标签---------------')
for n in tag_list:# 爬取标签名称tag_name = n.xpath('./a/text()')[0]# 爬取标签原IDtag_id = n.xpath('./a/@href')[0]# 裁剪标签IDtag_num = tag_id.split('/tag/')[-1]print('标签:', tag_name)print('ID:', tag_num)
print('---------------华丽的分割线---------------')# 爬取图片
# 爬取图片的过程与上面获取标签页的步骤一致,最后将图片存储到本地文件夹
id_value = input('键入标签ID获取图片:')
print('---------------爬取图片开始---------------')
for k in range(10):url_img = 'https://wallhaven.cc/search?q=id%3A'+id_value+"&page="+str(k+1)response = requests.get(url=url_img, headers=headers) tree = etree.HTML(response.text) # 爬取所有图片信息img_list = tree.xpath('//div/section[1]/ul/li')for i in img_list:# 爬取图片原IDimg_id = i.xpath('./figure/@data-wallpaper-id')[0]# 剪裁图片IDimg_num = img_id[:2]# 拼接图片地址,这里得到完整的目标图片路径img_url = 'https://w.wallhaven.cc/full/' + img_num + '/wallhaven-' + img_id + '.jpg'img_data = requests.get(url=img_url, headers=headers)img_choose = etree.HTML(img_data.text)# 爬取图片特征信息img_chosen = img_choose.xpath('/html/body/center[1]/h1/text()')# 对图片进行特征判断,图片主要为JPG与PNG的格式,这里进行分支判断# JPG图片处理if img_chosen == ['404 Not Found']:img_url = 'https://w.wallhaven.cc/full/' + img_num + '/wallhaven-' + img_id + '.png' # 对图片发起网络请求img_data = requests.get(url=img_url, headers=headers)# 以PNG形式保存图片with open('./wallhaven_picture/{}.png'.format(img_id), 'wb') as png:png.write(img_data.content)print(img_url, '下载完毕')# JPG图片处理else:# 以JPG形式保存图片with open('./wallhaven_picture/{}.jpg'.format(img_id), 'wb') as jpg:jpg.write(img_data.content)print(img_url, '下载完毕')6.爬取成果
7.个人体会
在学习一门新的应用为主的技能时,个人认为实践才是较快的学习方法,进行实操时,去运用并熟练。多多学习其他大佬的经验,毕竟站在巨人的肩膀上才能看的更远,也祝大家学有所成。