前言
上一节实现了题目的整理,没整理答案是不完整的,所以这一节加上答案的爬取。
上一节地址:Python网络爬虫与信息提取(16)—— 题库爬取与整理
效果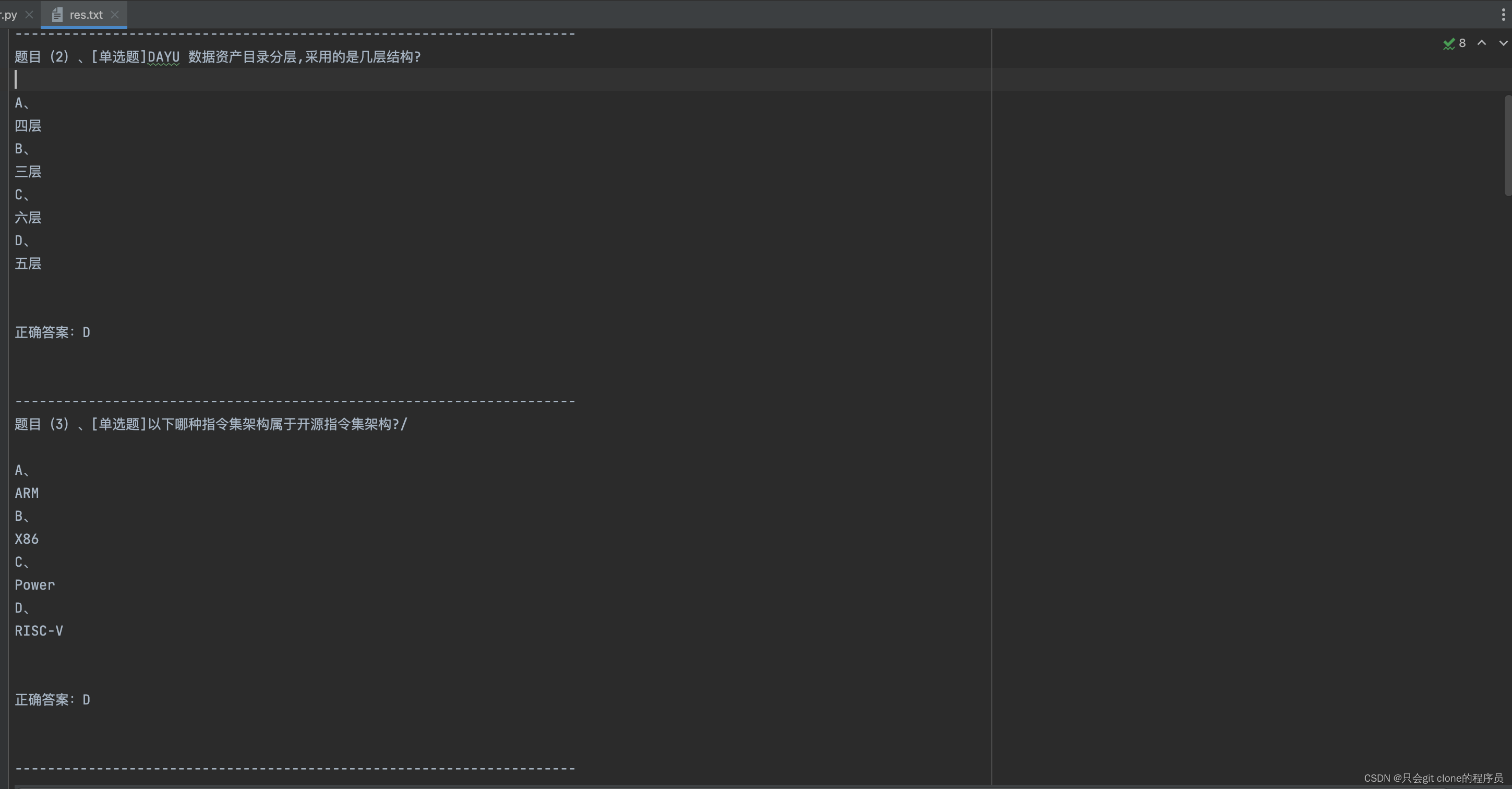
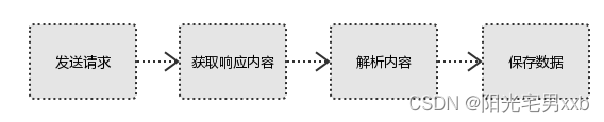
思路
爬答案有点难搞,像这种题库的答案都是要么要会员,要么要登陆账号才能看答案,这种就比较费劲了,解决方案有两种:
- 用控制台看点击查看答案会请求哪些接口,然后看看发送请求的格式以及返回response的格式来模拟查看答案。这个方法比较麻烦,因为你不是网站的开发人员,你需要猜他是个什么情况,而且有些会对数据加密,更看不出来了…
- 第二种比较万精油,控制浏览器自动化的处理然后检索数据就好了。
难点
- 答案的存储格式不唯一,因为题型有单选、多选、简答和填空,整理答案比较麻烦
- 网站有反扒,访问快了网页会404,再快了会封IP
- 网站的答案要登录才能看到,selenium每次控制浏览器会新起一个这样需要重新登陆,可以控制指定端口的谷歌浏览器来解决这个问题。