https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html
人脸识别各论文参考
知乎一个栏目:
https://zhuanlan.zhihu.com/p/25025596
首先介绍一下常用人脸检测的常用数据库:
FDDB和WIDER FACE
FDDB总共2845张图像,5171张,人脸非约束环境,人脸的难度较大,有面部表情,双下巴,光照变化,穿戴,夸张发型,遮挡等难点,是目标最常用的数据库。有以下特点:
- 图像分辨率较小,所有图像的较长边缩放到450,也就是说所有图像都小于450*450,最小标注人脸20*20,包括彩色和灰度两类图像;
- 每张图像的人脸数量偏少,平均1.8人脸/图,绝大多数图像都只有一人脸;
- 数据集完全公开,published methods通常都有论文,大部分都开源代码且可以复现,可靠性高;unpublished methods没有论文没有代码,无法确认它们的训练集是否完全隔离,持怀疑态度最好,通常不做比较。(扔几张FDDB的图像到训练集,VJ也可以训练出很高的召回率。。需要考虑人品能不能抵挡住利益的诱惑)
- 有其他隔离数据集无限制训练再FDDB测试,和FDDB十折交叉验证两种,鉴于FDDB图像数量较少,近几年论文提交结果也都是无限制训练再FDDB测试方式,所以,如果要和published methods提交结果比较,请照做。山世光老师也说十折交叉验证通常会高1~3%。
- 结果有离散分数discROC和连续分数contROC两种,discROC仅关心IoU是不是大于0.5,contROC是IoU越大越好。鉴于大家都采用无限制训练加FDDB测试的方式,detector会继承训练数据集的标注风格,继而影响contROC,所以discROC比较重要,contROC看看就行了,不用太在意。
WIDER FACE:
WIDER FACE总共32203图像,393703标注人脸,目前难度最大,各种难点比较全面:尺度,姿态,遮挡,表情,化妆,光照等。有以下特点有:
- 图像分辨率普遍偏高,所有图像的宽都缩放到1024,最小标注人脸10*10,都是彩色图像;
- 每张图像的人脸数据偏多,平均12.2人脸/图,密集小人脸非常多;
- 分训练集train/验证集val/测试集test,分别占40%/10%/50%,而且测试集的标注结果(ground truth)没有公开,需要提交结果给官方比较,更加公平公正,而且测试集非常大,结果可靠性极高;
- 根据EdgeBox的检测率情况划分为三个难度等级:Easy, Medium, Hard。
有关人脸识别,主要分为两个步骤算法,人脸检测算法和人脸识别算法。本文总结介绍最近几年常用的人脸检测算法,方便自己以后参考。
1.SSD
这篇博文介绍了SSD跑自己数据的做法
https://blog.csdn.net/wfei101/article/details/78821575
SSD关键点分为两类:模型结构和训练方法。模型结构包括:多尺度特征图检测网络结构和anchor boxes生成;训练方法包括:ground truth预处理和损失函数。
文章的核心之一是作者同时采用lower和upper的feature map做检测。假定有8×8和4×4两种不同的feature map。第一个概念是feature map cell,feature map cell 是指feature map中每一个小格子,假设分别有64和16个cell。另外有一个概念:default box,是指在feature map的每个小格(cell)上都有一系列固定大小的box,如下图有4个(下图中的虚线框,仔细看格子的中间有比格子还小的一个box)。假设每个feature map cell有k个default box,那么对于每个default box都需要预测c个类别score和4个offset,那么如果一个feature map的大小是m×n,也就是有m*n个feature map cell,那么这个feature map就一共有(c+4)*k * m*n 个输出。这些输出个数的含义是:采用3×3的卷积核对该层的feature map卷积时卷积核的个数,包含两部分(实际code是分别用不同数量的3*3卷积核对该层feature map进行卷积):数量ckmn是confidence输出,表示每个default box的confidence,也就是类别的概率;数量4kmn是localization输出,表示每个default box回归后的坐标)。训练中还有一个东西:prior box,是指实际中选择的default box(每一个feature map cell 不是k个default box都取)。也就是说default box是一种概念,prior box则是实际的选取。训练中一张完整的图片送进网络获得各个feature map,对于正样本训练来说,需要先将prior box与ground truth box做匹配,匹配成功说明这个prior box所包含的是个目标,但离完整目标的ground truth box还有段距离,训练的目的是保证default box的分类confidence的同时将prior box尽可能回归到ground truth box。 举个列子:假设一个训练样本中有2个ground truth box,所有的feature map中获取的prior box一共有8732个。那个可能分别有10、20个prior box能分别与这2个ground truth box匹配上。训练的损失包含定位损失和回归损失两部分。
SSD算法的缺点:优势是速度快,在GPU上能实时,缺点是对密集小目标的检测比较差,而人脸刚好是密集小目标,这类方法的研究重点是提高密集小目标的检测性能,同时速度也需要尽可能快,GPU实时算法在应用中依然受限。
2.S3FD
github代码:
https://github.com/sfzhang15/SFD
这篇文章对anchor对小人脸检测率低的问题进行了分析和改进。
基于anchor方法的缺点:
Anchor-based方法没有scale-invariant(尺度不变性).对大物体检测的好,对小物体不行。
没有尺度不变性的原因:
- 不适当的网络结构:后面的步长会变很大,会忽略掉一部分小的物体
- anchor合适问题:因为anchor设计的问题,导致有些小脸没有足够多的anchor与其相匹配,故而降低了检测率。
- anchor尺寸问题:若降低anchor的尺度(如在conv3_3加入小尺度的anchor),会大大增加负样本数量。
改进:
- 作者重新设置了anchor的尺度。并且作者认为stride决定了anchor的间隔。所以设置每层stride的大小为每层anchor尺度的1/4.作者称其为equal-proportion interval principle。
- 为了使某些小物体有足够多的anchor与其相匹配,所以适当降低了阈值。
速度比较慢。
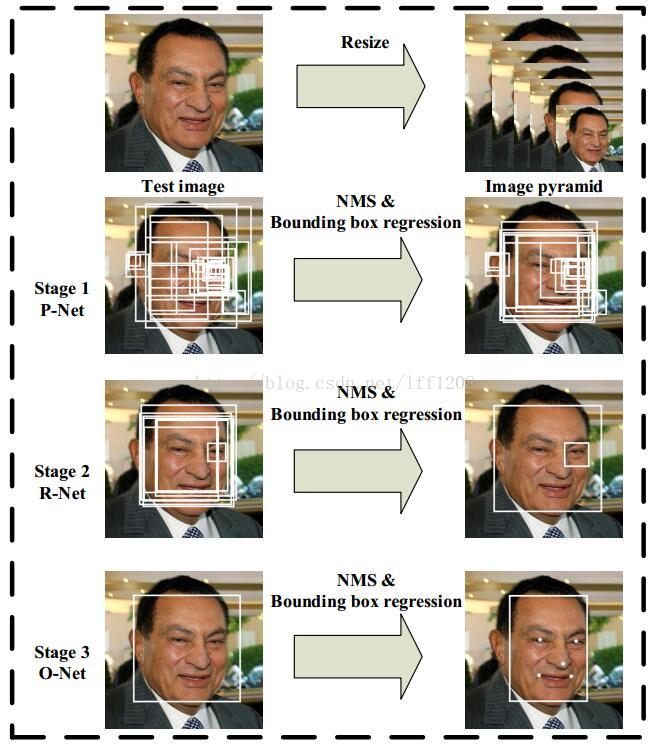
3.MTCNN
该算法直接实现了人脸检测和人脸对其。其结构是是三个CNN级联:
P-net R-net O-net
主要是人脸landmark检测
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。
该代码实现了mtcnn人脸检测部分:(最终结果为画框)
https://github.com/DuinoDu/mtcnn
该代码实现了mtcnn python版本:(还没跑过)
https://github.com/dlunion/mtcnn