JS面试题总结
- 一、this指向问题
- (1)this的理解
- (2)怎样改变this的指向问题
- (3)Call,bind,apply三者的区别
- (4)容易判读错的几种this情况
- (5)this指向问题,说输出;这两中a,b写法,在内存消耗上有什么区别
- 二、手写节流(throttle)和防抖(debounce)
- 节流(throttle):
- 防抖(debounce):
- 改进:实现第一次点击和最后一次点击生效
- 三、js事件循环机制(宏任务,微任务,同步任务,异步任务)
- (1) JS事件循环机制概念
- (2)为什么js是单线程
- (3)线程和进程是什么?举例说明
- (4)js引擎的执行栈
- (5)setTimeout、Promise、Async/Await 的区别
- (6) Web Worker 标准
- (7)浏览器是多进程的
- 浏览器包含的进程
- 浏览器多进程的优势
- 进程间的通信(进程通信)
- 什么是进程的死锁
- 介绍一下银行家算法
- linux中硬链和软链的区别
- 介绍一下linux文件绝对路径和相对路径
- 四、跨域
- (1)为什么会出现跨域问题?
- (2)同源策略
- (3)为什么需要同源策略(跨域限制)
- (4)什么是跨域
- (5)怎么允许跨域(跨域解决办法)
- A、JSONP
- B、 CORS跨域资源共享:
- 简单请求
- 非简单请求(预检请求)
- C、Nginx反向代理
- D、webpack (在vue.config.js文件中)中 配置webpack-dev-server
- 五、es6的新特性
- common js和es6模块的区别
- 六、Symbol(es6新增)
- Symbol的应用场景
- 七、let var const的区别
- const是怎么实现的只能赋值一次
- 八、介绍下set,weakset,map,weakmap的区别
- Set:
- Weakset:
- Map:
- Weakmap:
- 九、原型和原型链
- (1)构造函数
- (2)为什么引入原型对象prototype
- (3) 原型对象
- (4)构造函数,实例对象,原型对象三者之间的关系
- (5)原型链
- (6)原型链打印题踩坑
- 10、了解JS的继承吗?ES5继承与ES6继承的区别
- (1)继承:
- (2)Es5和es6继承的区别:
- (3)js继承的六种方法:
- 11、js如何定义一个类并实现继承;要求不能使用es6的语法(手写一个寄生组合式继承)
- 组合继承(构造函数和原型链实现继承)
- 寄生组合式继承
- Es6实现继承
- 12、讲一讲Promise;语法
- Promise的缺点:
- Promise用法
- Promise.then
- Promise.catch
- Promise.all
- Promise.any
- Promise .finally
- Promise .race
- Promise.allSettled
- 13、如何中止promise链式调用
- 14、promise发生错误,怎么捕捉
- 15、手写promise;手写promise.all;手写promise.any;手写promise.finally;手写Promise.race;手写Promise.allSettled
- 手写Promise
- 手写Promise.all:
- 手写Promise.any:
- 手写Promise.finally:
- 手写Promise.race:
- 手写Promise.allSettled:
- 17、什么是事件委托(事件代理),为什么在父元素上绑事件,子元素上点击可能触发。
- 事件流/事件传播
- 事件委托的实现
- 18、js数据类型,怎样判断数据类型;基本数据类型和引用数据类型的区别;怎么判断一个数组是不是Array类型(insatnceof,object.prototype.toString.call);堆和栈是什么
- js数据类型
- 堆和栈
- 判断方法
- Typeof:
- Instanceof:
- Object.prototype.toString.call():可以精准判断数据类型
- 19、undefined和null的区别
- 20、箭头函数与普通函数的区别是什么?
- 21、构造函数可以使用new生成实例,那么箭头函数可以吗?为什么?
- 箭头函数不能使用new生成实例
- New的过程:
- 22、循环(遍历)的方法,各个方法的区别
- 遍历
- 23、除了for...of还有哪些方法可以遍历字符串,数组中reduce方法有哪些参数,是怎样使用的
- 24、怎么让对象的一个属性不可被改变
- (1) Object.defineProperty()
- (2)object.preventExtensions()
- 25.对浏览器的理解
- 26.对浏览器内核的理解
- 27.浏览器所用的内核
- 28.浏览器内核比较
- 29.浏览器的渲染原理
- 30、重排重绘
- 什么时候发生重排?
- 什么时候发生重绘?
- 如何减少重排重绘?
- 浏览器的优化机制
- 31、flat数组扁平化
- flat方法
- 递归处理(递归遍历每一项,若为数组继续遍历,否则concat(拼接))
- 用reduce实现的数组扁平化(遍历数组每一项,若为数组就继续遍历,否则就concat(连接))
- 扩展运算符
- 已知如下数组:var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];编写一个程序将数组扁平化并去除其中重复部分数据,最终得到一个升序且不重复的数组
- 32、什么是闭包;闭包的作用;使用闭包实现每秒钟打印数组中的一个数组[5,4,3,2,1]
- 使用闭包实现每秒钟打印数组中的一个数组[5,4,3,2,1]
- 闭包:
- 闭包产生的原因:
- 闭包的作用:
- 缺点:
- 33、输出什么/函数每秒依次输出
- (1)怎么修改可以让上面代码从1到5秒依次输出0-4,写出你能想到的所有方法
- 33、手写:ajax请求,解释状态码含义;
- 手写ajax
- 状态码含义
- 34、手写ajax请求,用promise封装
- 35、== 和===的区别
- 36、JS隐式转换
- 37、如何让if(a==1&&a==2&&a==3)条件成立?
- 38、JS的垃圾回收机制
- v8引擎对垃圾回收做了哪些优化
- 增量标记:对活动对象和非活动对象进行标记
- 懒性清理:V8采用的是惰性清理来释放内存
- 并发回收:
- 38、内存泄露(memory leak)
- 39、内存三大件
- 40、浏览器存储方式
- 39、JS的设计模式
- 模块模式
- 原型模式
- 观察者模式
- 单例模式
- 工厂模式
- 为什么JS单例模式不会产生互锁现象(异步)
- 40、考查原型和函数的打印题
- 41、手写代码:浏览器打开了一个页面,在控制台执行脚本,获取页面TagName种类。
- 42、连续赋值-输出以下代码的执行结果并解释为什么?(连续赋值的坑)
- 43、操作DOM的方法
- 创建新节点
- 添加节点
- 删除节点
- 替换节点
- 获取/查找节点
- 属性操作
- getQuerySelector和getClassName的区别
- 44、求两个数组的并集和交集和差集
- 45、数组的常用方法
- 46.深拷贝和浅拷贝
- 如何实现深拷贝
- 浅拷贝的方法
- 47.手写instanceOf
- 48.数组去重
- 49.New的实现(构造函数的执行过程,new实现、new的过程,new干了什么)
- 50.函数柯里化
- 51.二分查找(顺序表)
- 52.两个数组合并成一个数组。请把两个数组 ['A1', 'A2', 'B1', 'B2', 'C1', 'C2', 'D1', 'D2'] 和 ['A', 'B', 'C', 'D'],合并为 ['A1', 'A2', 'A', 'B1', 'B2', 'B', 'C1', 'C2', 'C', 'D1', 'D2', 'D']。
- 53、0.1+0.2 !== 0.3,如何让它等于
- 54、Console.log(typeof typeof typeof null)
- 55、 Let mySet = new Set();
- 56、 ParseInt(071)和parseInt(‘071’)分别会输出多少,js中有哪些表示数值的方式
- 57、[‘1’,’2’,’3’].map(parseInt) what? Why?
- 答案:[1,NaN,NaN]
- 原因:
- 58、实现 convert 方法,把原始 list 转换成树形结构,要求尽可能降低时间复杂度。(render函数)
- 给一个树形对象结构,写一个函数层次遍历这个树形结构
- 59、git常用命令
- 60、linux常用命令
- 61、实现一个计数器
- 62、判断一个函数是普通函数还是构造函数(补全funcA(){})
- 63、写一个简单的计算器类,实现+-*÷,链式调用
- 64、打印题
- 65、让所有的c都变成h(包括大写的C) 'abcdbac'
- 66、手写一个repeat()函数,加上下面的代码运行,使每3s打印一个helloword,总共执行4次
- 67、promise,async,await的应用场景和区别
- 69、补全myNew,让打印满足条件
- 70、作用域(分为全局作用域,函数作用域,块级作用域)
- 71、求连续子数组的最大和
- 72、字符串相加/大数相加
- 73、搜索二维矩阵
- 74、进制转换
- 75、大数相乘
- 76、事件监听
- 77、快排,哈希,插入排序
- 插入排序
- 78、随机生成一个颜色
- 79、"kuai-shou-gong-cheng"转化为"KuaiShouGongCheng"(变驼峰命名)
- 80、HashMap的数据结构
- 81、手写:字符串补0
- 82、值传递和引用值传递打印题
- 83、只出现一次的数字
- 84、多数元素
- 85、合并两个有序数组
- 86、外观数列
- 87、二叉树中序遍历(栈)(左根右)
- 88、手写Promise并发控制调度器。大概是:一次性可能发10个请求,但是请求池控制一次性只能处理三个,请求池内的请求一个处理完后推进下一个请求
- 89、递归数组求和
- 91、二维数组排列组合:
- 92、输入abbccccaaa 输出a1b2c4a3
- 93、反转链表
- 94、 Interface和type的区别
- 95、never 和 void 的区别
- 96、如何使 TypeScript 项目引入并识别编译为 JavaScript 的 npm 库包?
- 97、简述工具类型 `Exclude`、`Omit`、`Merge`、`Intersection`、`Overwrite`的作用
- 98、keyof 和 typeof 关键字的作用
- 99、 字符串翻转
- 100、去除字符串中重复字符
- 101、实现一个栈,要求实现min函数以返回栈中的最小值
- 102、使用两个栈实现一个队列
- 103、写一个函数来产生第n个斐波那契数
- 104、将数字转化为16进制
- 105、 compose 函数柯里化
- 106、计算数组交集
- 107、把id排序后对应的name拿出来
- 108、 组合和高阶函数;
- 109、 什么时候可以使用函数声明和表达式110、上下遍历——Node.parentNode、Node.firstChild、Node.lastChild 和 Node.childNodes;左右遍历——Node.previousSibling 和 Node.nextSibling;
- 111、性能——当有很多节点时,修改 DOM 的成本会很高,应该知道如何使用文档片段和节点缓存。
- 113、有这样一个场景,页面中有个列表,数据量非常大,如何保障页面不卡顿?(用虚拟列表)
- (1)数据不分页
- (2)数据分页的两种方法
- (3)实现虚拟列表
- 114、表格实现如何做性能优化,比如有10万数据
- 115、有一个会频繁触发的函数,该函数依赖页面中某些dom的offsetHeight属性,如何保障页面不卡顿?
- 115、是否了解文档片段,在什么情况下使用?(DOM)
- 116、如何判断一个元素是否在可视区域内?(DOM)
- 117、获取页面中第一个span的字体颜色
- 118、ES6 代码转成 ES5 代码的实现思路是什么?
- 119、webpack打包有什么优化手段可以让打包出的内容尽量小或打包速度加快
- (1)减少打包时间:
- (2)减少打包大小:
- 120、实现限制fetch并发数
- 124、手写Loadash中的get函数
- 125、断点续传如何实现
- 126、图片的上传接口如何写
- 127、如何保证上传的图片在服务器上不重复
- 128、上传的进度条如何得到
- 129、短链UUID算法
- 130、算法题,倒置N阶矩阵
- 131、给定一个数组,没有重复数字,输出全部排列组合
- 132、什么是dom和bom?
- 133、排序的时间,空间复杂度
一、this指向问题
(1)this的理解
JS是一个文本作用域的语言,也就是,变量的作用域在写这个变量的时候确定。this设计的目的就是在函数体内部,指代函数当前的运行环境。This具体来说有四种:
(1)默认的this绑定,非严格模式下,this就是全局变量Node环境中的global,浏览器环境下的window。严格模式下,默认的指向是undefined(es6中的类会自动使用严格模式)
(2)隐式绑定:使用obj.foo()这样的语法调用函数的时候,函数foo中的this绑定到obj对象。
(3)显示绑定:调用call,apply,bind方法
(4)构造绑定:new Foo(),foo中的this引用这个新创建的对象。
this指向最后调用它的对象,如果没有调用,则指向window对象(独自运行的函数也指向window;立即执行函数也指向window);
构造函数中this指向构造函数的实例;
箭头函数始终指向函数定义时的this.
es6中类会默认使用严格模式,禁止this指向全局对象,指向undefined。
(2)怎样改变this的指向问题
通过es6的箭头函数(指向函数定义时的this)
通过call,bind,apply函数改变this指向。
(3)Call,bind,apply三者的区别
Call,bind,apply这三个函数的第一个参数都是this的指向对象,第二个参数不同,call和bind都是接收参数列表,apply接收的是一个包含多个参数的数组(也可以是类数组)。而且bind函数还会返回一个新的函数。
(4)容易判读错的几种this情况
es6中类会默认使用严格模式,禁止this指向全局对象,所以会指向undefined
class C{//类a(){console.log(this);}b=()=>{console.log(this);}}c = new C();c.a();//this指向Cf = c.a;f();//this指向undefined es6中类会默认使用严格模式,禁止this指向全局对象,所以会指向undefinedc.b()//this指向C
var name = "windowsName";var a = {fn:function(){console.log(this.name);}}window.a.fn();//undefined 指向a
var name = "windowsName";var a = {name:'Cherry',func1:function(){console.log(this.name)},func2:function(){console.log(this)//this指向a(object)setTimeout(function(){console.log(this)//this指向window,自己执行的所以指向windowthis.func1()//报错,window里面没有func1函数},100);}}a.func2()
var name = '123';var obj = {name:'456',getName:function(){function printName(){console.log(this.name)}printName()}}obj.getName()//输出123
怎样把结果变为456?
var name = '123';var obj = {name:'456',getName:function(){function printName(){console.log(this.name)}printName.call(this)//使用call修改this指向}}obj.getName()//456
(5)this指向问题,说输出;这两中a,b写法,在内存消耗上有什么区别
a消耗小,a是直接定义在原型链上的;b相当于在每一个实例上赋值。
class C{a(){console.log(this);}b=()=>{console.log(this);}}c = new C();c.a();//cf = c.a;f();//undefined//es6中类禁止指向全局对象,指向undefinedc.b();//c
二、手写节流(throttle)和防抖(debounce)
用户点击过快会导致卡顿,可以使用节流/防抖限制函数的执行次数,达到优化的目的。
节流(throttle):
高频事件触发,但在n秒内只执行一次。(购物中的秒杀)
防抖(debounce):
事件被触发n秒后执行回调,如果在n秒内事件又被触发,就重新计时。

function throttle(fn,delay){//手写节流函数var preTime = Date.now();//初始时间return function(){var context = this,args = arguments,nowTime = Date.now();//触发事件的时间if(nowTime - preTime >= delay){//如果两次时间间隔超过了指定时间,则执行函数preTime = Date.now();//把初始时间更新为最新的时间return fn.apply(context,args);}}}
function debounce(fn,wait){//手写防抖函数var timer = null;//创建一个标记来存放定时器的返回值return function(){var context = this;args = arguments;if(timer){clearTimeout(timer);//如果定时器存在,清除定时器重新计时timer = null;}timer = setTimeout(()=>{//设置定时器,使事件间隔指定时间后执行fn.apply(context,args);//确保上下文环境为当前的this,所以不能直接用fn(直接用fn会指向window);因为不确定入参的数量,所以还可以传入扩展后的arguments},wait);}}
改进:实现第一次点击和最后一次点击生效
三、js事件循环机制(宏任务,微任务,同步任务,异步任务)
(1) JS事件循环机制概念
js是一个单线程的脚本语言。当执行栈(执行环境的栈)中所有任务都执行完毕后,去看微任务队列中是否有事件存在,如果存在,则依次执行微任务队列中事件的回调,直到微任务队列为空。然后去宏任务队列中取出一个事件,把对应的回调加入当前执行栈,当执行栈中所有任务都执行完毕后,再去检查微任务队列中是否有事件存在。这个循环的过程就是事件循环。(浏览器的主线程是一个事件循环,)
微任务:promise.then;process.nextTick(Node的) ;promise.catch;promise.finally
宏任务:setTimeout,setInterval,setImmediate,I/O,Ui交互事件(鼠标点击,滚动页面,放大缩小等),script(整体代码)
打印顺序的题:同步任务->微任务->宏任务
New promise中的直接执行,是同步任务
process.nextTick比promise.then(都是微任务),但process.nextTick先执行
Async函数内,await和await之前的都是同步任务;await执行之后放入微任务队列中。
栗子:
setTimeout(()=>{console.log('quick timer')
},0)
new Promise((resolve,reject)=>{console.log('init promise')process.nextTick(resolve)
}).then(()=>{console.log('promise.then')
})
process.nextTick(()=>{console.log('nextTinck')
})
setImmediate(()=>{console.log('immediate')
})
//init promise-> nextTinck->promise.then->quick timer->immediate
(2)为什么js是单线程
JS是单线程的原因主要和JS的用途有关,JS主要实现浏览器与用户的交互,以及操作DOM。
如果JS被设计为多线程,如果一个线程要修改一个DOM元素,另一个线程要删除这个DOM元素,这时浏览器就不知道该怎么办,为了避免复杂的情况产生,所以JS是单线程的。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
(3)线程和进程是什么?举例说明
进程:cpu分配资源的最小单位(是能拥有资源和独立运行的最小单位)
线程:是cpu最小的调度单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
栗子:比如进程=火车,线程就是车厢
- 一个进程内有多个线程,执行过程是多条线程共同完成的,线程是进程的部分。
一个火车可以有多个车厢 - 每个进程都有独立的代码和数据空间,程序之间切换会产生较大的开销;线程可以看作轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
【多列火车比多个车厢更耗资源】
【一辆火车上的乘客很难换到另外一辆火车,比如站点换乘,但是同一辆火车上乘客很容易从A车厢换到B车厢】 - 同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
【一辆火车上不同车厢的人可以共用各节车厢的洗手间,但是不是火车上的乘客无法使用别的火车上的洗手间】
(4)js引擎的执行栈
执行栈也叫执行上下文栈,用于存储代码执行期间创建的所有上下文,具有先进后出的特点。 也就是当代码第一次执行的时候,会把浏览器创建的全局执行上下文压入栈中;当以后调用函数时,会把调用函数所创建的函数执行上下文压入栈中。当函数执行完,就会将其从栈中弹出。当所有的代码都执行完毕之后,就把全局执行上下文弹出,执行上下文栈就为空了。(执行上下文分为三种,全局执行上下文,它是由浏览器创建的,也就是常说的window对象;函数执行上下文,它是函数被调用时被创建的,同一个函数被多次调用,会产生多个执行上下文;eval函数执行上下文)
(5)setTimeout、Promise、Async/Await 的区别
(1)SetTimeOut的回调函数放到宏任务队列中,等到执行栈清空以后执行。
(2)promise本身是同步的立即执行函数。当执行resolve或reject的时候,此时是异步操作。Promise.then里的回调函数会放到相应宏任务的微任务队列里,等宏任务里面的同步代码执行完再执行。
(3)Async函数返回一个promise对象,当函数执行的时候,一旦遇到await就会先返回。等到触发的异步操作完成,再执行函数体内后面的语句。可以理解为,是让出了线程,跳出了ASYNC函数体。
(6) Web Worker 标准
HTML5则提出了 Web Worker 标准,表示js允许多线程,但是子线程完全受主线程控制并且不能操作dom,只有主线程可以操作dom,所以js本质上依然是单线程语言。
JS引擎是单线程单,JS如果执行时间过长,就会阻塞页面。
HTML5中支持了web worker。创建worker时,JS引擎向浏览器申请开一个子线程。子线程是浏览器开的,完全受主线程控制,而且不能操作DOM。JS引擎线程与worker线程之间通过特定单方式通信(postMessage API,需要通过序列化对象与线程交互特定的数据)。
如果有非常耗时的工作,可以单独开一个Worker线程。
(7)浏览器是多进程的
浏览器之所以能够运行,是因为系统给它分配了资源(cpu,内存)
也就是说每打开一个tab页面,就相当于创建了一个独立的浏览器进程(但是不是绝对的,有时候打开多个tab页面,会发现有的进程被合并了)。
浏览器包含的进程
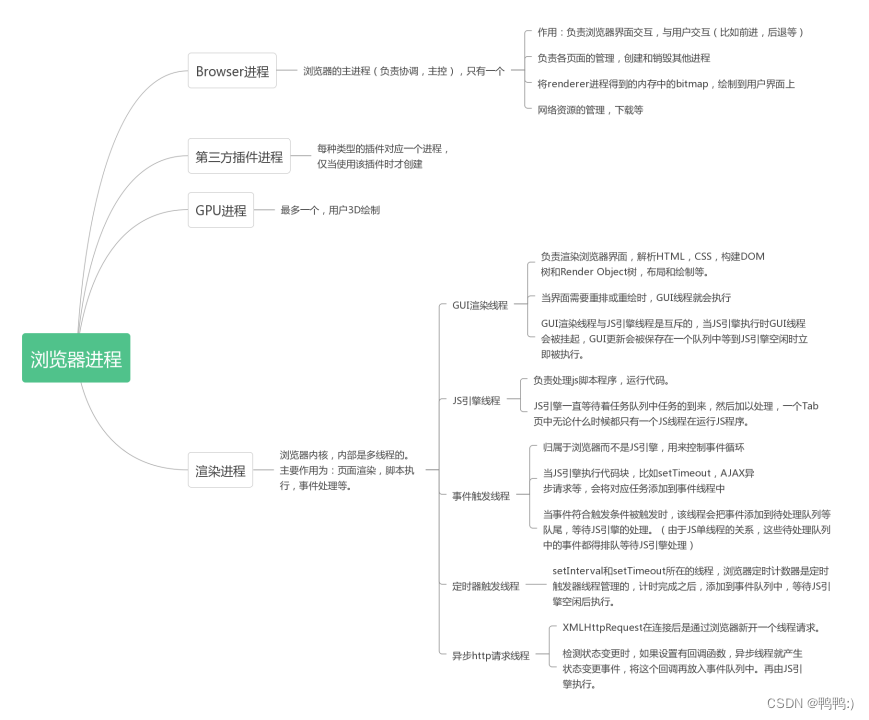
浏览器多进程的优势
避免某个页面崩溃或者插件崩溃影响整个浏览器
多进程充分利用多核优势
方便使用沙盒模型隔离插件等进程,提高浏览器等稳定性
进程间的通信(进程通信)
管道通信:操作系统在内核中开辟了一段缓存区,进程1可以将需要交互的数据拷贝到这个缓存区里,进程2读取。
消息队列通信:消息队列是用户可以添加和读取消息的列表,消息队列里提供了一种从一个进程向另一个进程发送数据块的方法,不过和管道通信一样每个数据块有最大长度限制。
共享内存通信:映射一段能被其他进程访问的内存,由一个进程创建,但多个进程都可以访问。共享进程最快的是信号量通信:比如信号量初始值是1,进程1来访问一块内存的时候,就把信号量设为0,然后进程2也来访问的时候看到信号量为0,就知道有其他进程在访问了,就不访问了
socket:其他的都是同一台主机之间的进程通信,而在不同主机的进程通信就要用到socket的通信方式了,比如发起http请求,服务器返回数据。
什么是进程的死锁
介绍一下银行家算法
linux中硬链和软链的区别
介绍一下linux文件绝对路径和相对路径
四、跨域
(1)为什么会出现跨域问题?
因为浏览器的同源策略的限制。
(2)同源策略
同源策略是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器正常的功能都有可能受影响。可以说web是构建在同源策略基础之上的。浏览器只是针对同源策略的一种实现。同源策略会阻止一个域的JS脚本和另一个域的内容进行交互。所谓同源就是指两个页面具有相同的协议,域名,端口号。
(3)为什么需要同源策略(跨域限制)
(1)如果没有XMLHttpRequest同源策略,那么黑客可以进行CSRF攻击(登录正常网站之后,本地产生了cookie,正常网站没有登出的情况下访问了危险网站,危险网站伪装成用户向安全网站发送请求,cookie会自动附加到请求头,这样就会被安全网站认为是用户的操作。也就是说攻击者盗用了你的身份,以你的身份发送恶意请求。----->处理方法:验证码;对来源进行验证;使用token)。
(2)如果没有DOM同源策略,那么不同域的iframe之间可以相互访问。
(4)什么是跨域
当2个URL中的协议,域名,端口号中任意一个不相同时,就算作不同域。不同域之间相互请求资源,就是跨域。
跨域的请求能发出去,服务端能收到请求并返回结果,只是结果被浏览器给拦截了。
(5)怎么允许跨域(跨域解决办法)
A、JSONP
在页面上,js脚本,css样式文件,图片这三种资源是可以与页面本身不同源的。jsonp就利用了script标签进行跨域取得数据。
JSONP允许用户传递一个callback参数给服务器端,然后服务器端返回数据时会将这个callback参数作为函数名来包裹住JSON数据。这样客户端就可以随意定制自己的函数来自动处理返回的数据了。
JSONP只能解决get请求,不能解决post请求。
<script>function callback(data){console.log(data);}</script><script src="http://localhost:80/?callback=callback"></script>
使用ajax实现跨域:
<script src="http://code.jquery.com/jquery-latest.js"></script> $.ajax({url:'http://localhost:80/?callback=callback',method:'get',dataType:'jsonp', //=> 执行jsonp请求success:(res) => {console.log(res);}})function callback(data){console.log(data);}
B、 CORS跨域资源共享:
浏览器会自动进行CORS通信,实现CORS通信的关键是后端。服务端设置Access-Control-Allow-Origin就可以开启CORS。该属性表示哪些域名跨域访问资源。
主要设置以下几个属性:
Access-Control-Allow-Origin//允许跨域的域名
Access-Control-Allow-Headers//允许的header类型
Access-Control-Allow-Methods//跨域允许的请求方式
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
简单请求
只要同时满足以下两大条件,就属于简单请求。

对于简单请求,浏览器直接发出CORS请求。具体来说,就是在头信息之中,增加一个Origin字段。
非简单请求(预检请求)
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为预检请求(preflight),该请求由option方法得到,通过该请求来指导服务端是否允许跨域请求。

C、Nginx反向代理
通过nginx配置一个代理服务器将客户机请求转发给内部网络上的目标服务器;并将服务器上返回的结果返回给客户端。
D、webpack (在vue.config.js文件中)中 配置webpack-dev-server
devServer: {proxy: {'/api': {target: "http://39.98.123.211",changeOrigin: true, //是否跨域},},},
五、es6的新特性
增加了块级作用域,关键字let,常量const
解构赋值
模块(将JS代码分割成不同功能的小块进行模块化)
模板字符串(使用反引号创建字符串,字符串里面可以包含用${}包裹的变量)
箭头函数;扩展运算符(…[1,2,3]->1,2,3)
Class类
Promise异步对象
For…of循环
Map,set,weakmap,weakset
新增的数组方法:Array.from()将set类变为数组;Array.find()找出第一个符合条件的数组成员
字符串方法:string.includes(value)->是否包含某个值,是返回true
symbol数据类型,表示独一无二的值。
Proxy代理
common js和es6模块的区别
commonjs模块输出的是一个值的拷贝,es6模块输出的是值的引用。
commonjs模块是运行时加载,es6模块是编译时输出接口。
commonjs是单个值导出,es6模块可以导出多个。
commonjs是动态语法可以写在判断里,es6模块静态语法只能写在顶层。
commonjs的this是当前模块,es6模块的this是undefined
六、Symbol(es6新增)
symbol不能使用new,因为symbol是原始数据类型,不是对象。
每一个symbol的值都是不相等的,是唯一的。主要是为了防止属性名冲突。
symbol不能和其他的数据类型比较,比较的话会报错
如果symbol和symbol比较,值为false。
for…in和object.keys()均不能访问到symbolz作为key的值。可以通过object.getOwnPropertySymbols获取。
Symbol的应用场景
(1)防止属性污染
在某些情况下,我们可能要为对象添加一个属性,此时就有可能造成属性覆盖,用Symbol作为对象属性可以保证永远不会出现同名属性。
(2)借助Symbol类型的不可枚举,我们可以在类中模拟私有属性,控制变量读写
(3)可以防止XSS攻击,JSON中不能存储Symbol类型的变量,这就是防止XSS的一种手段。
七、let var const的区别
(1)var定义的变量,没有块的概念,可以跨块访问(块{}),不能跨函数访问
Let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问
Const用来定义常量,使用时必须初始化(必须赋值),只能在块作用域里面访问,且不能修改。
(2)var可以先使用后声明,因为var有变量提升;let必须先声明后使用
(3)Var允许相同作用域内重复定义,let和const不允许重复定义
(4)Var声明的全局变量会自动成为window属性,但是let和const不会
(5)TDZ(临时性死区):凡是在使用let,const声明的变量之前,这些变量都是不可使用的。CONST
if (true) {// TDZ开始tmp = 'abc'; // ReferenceErrorconsole.log(tmp); // ReferenceError//在没有声明变量之前tmp都是错误的let tmp; // TDZ结束console.log(tmp); // undefinedtmp = 123;console.log(tmp); // 123}
const是怎么实现的只能赋值一次
八、介绍下set,weakset,map,weakmap的区别
Set:
类似于数组,但是set的值是唯一的;向set加入值的时候不会发生类型转换(set内部判断两个值是否相等,类似于精确相等运算符(===),所以5和’5’是两个不同的值)
Weakset:
和set类似,也是不重复的值的集合。它和set有三个个区别:
Weakset的成员只能是对象;
weakset不能遍历;
weakset中的对象都是弱引用,也就是说如果其他对象都不再引用该对象,那么垃圾回收机制会自动回收该对象占的内存。(没有size属性和foreach)
Map:
类似于对象,是键值对的集合(键不局限于字符串,各种类型都可以当做键)。
Weakmap:
与Map结构类似,是键值对的集合。它和map区别有两点:
weakmap只接受对象作为键名
键名是弱引用,一旦不需要,weakmap里面的键值对会自动消失,不需要手动删除。
九、原型和原型链
(1)构造函数
构造函数是一种特殊的函数,主要用来初始化对象(也就是为对象成员变量赋值),它总与new一起使用。我们可以把对象中一些公共属性和方法抽取出来,然后封装到这个函数里面。
(2)为什么引入原型对象prototype
构造函数方法很好用,但是存在浪费内存的问题。
构造函数中不变的方法在每次new一个实例的时候,都会在堆里面开辟一个空间。我们想让这个不变的方法只占一个空间,所以就有了构造函数原型。
JS规定每一个构造函数都有一个原型对象。我们可以把那些不变的方法,直接定义在prototype对象上,这样所有对象的实例就可以共享这些方法。
(3) 原型对象
原型是什么:原型是一个对象,我们也称prototype为原型对象。
原型的作用是什么:共享方法
(4)构造函数,实例对象,原型对象三者之间的关系
每个构造函数都有一个原型对象,可以通过构造函数的prototype属性指向这个原型对象。
原型对象里面也有一个constructor属性,这个属性又指回了构造函数本身。
可以通过new和构造函数创建一个实例对象,这个实例对象里面有一个__proto__属性,这个属性指向构造函数的原型对象。

(5)原型链
当访问一个对象的某个属性时,会先从对象本身的属性去查找,如果没有找到的话,就会通过__proto__属性去构造函数的prototype上去查找;如果还没有找到,就去构造函数的prototype上的__proto__去查找,这样一层一层向上找所形成的链式结构,就是原型链。
(原型链的顶端是object的原型对象,也就是object.prototype.__proto__指向null)
原型链的应用:原型链是实现继承的主要方法
(6)原型链打印题踩坑
Function.prototype.a = () => console.log(1);Object.prototype.b = () => console.log(2);function A(){};var a = new A();a.a();//报错 除非把function改成A,才输出1a.b();//2 a的原型链上只有Object原因:new返回了一个新对象{a:4,b:5},这个新的对象原型(proto)不是Foo,所以访问不到Foo原型对象里面的值。(o insatnceof Foo为false)
function Foo(){this.a = 1;return{a:4,b:5}}Foo.prototype.a = 6;Foo.prototype.b = 7;Foo.prototype.c = 8;var o = new Foo();//console.log(o)//{a:4,b:5}//console.log(o instanceof Foo)//falseconsole.log(o.a);//4console.log(o.b);//5console.log(o.c);//undefined
10、了解JS的继承吗?ES5继承与ES6继承的区别
(1)继承:
子类可以继承父类的一些属性和方法
(2)Es5和es6继承的区别:
- Es5的继承实质是先创建子类的实例对象,然后再将父类的方法添加到this上(Father.call(this))。
Es6的继承实质是先创建父类的实例对象this,然后再用子类的构造函数修改this。 - Es5的继承通过构造函数和原型来实现
Es6通过class关键字定义类,类里面有构造方法,类之间通过关键字extends实现继承。子类必须在constructor方法中调用super方法,否则新建实例报错。因为子类没有自己的this对象,而是继承类父类的this对象,然后对其加工。如果不调用super方法,子类将得不到this对象。
(3)js继承的六种方法:
原型链继承,借用构造函数继承,组合继承(原型加构造函数),原型式继承,寄生式继承,寄生组合式继承
11、js如何定义一个类并实现继承;要求不能使用es6的语法(手写一个寄生组合式继承)
组合继承(构造函数和原型链实现继承)
function Father(name,age){this.name = name;this.age = age;}Father.prototype.work = function(){//父亲的方法console.log('父亲工作')}function Son(name,age){Father.call(this,name,age)//继承父类的属性(在father中把this指向子构造函数的实例)}Son.prototype.study = function(){console.log('孩子上学')}Son.prototype = new Father();//继承父类的方法(直接赋值,修改了儿子原型对象的constructor)Son.prototype.constructor = Son;//把儿子的constructor修改回去var son = new Son('小明',18);console.log(son);console.log(son.__proto__.constructor)console.log(son instanceof Father);

寄生组合式继承
function Father(name,age){this.name = name;this.age = age}Father.prototype.work = function(){console.log('父亲工作')}function Son(name,age){Father.call(this,name,age);//继承父类的属性}Son.prototype.study = function(){console.log('孩子上学')}Son.prototype = Object.create(Father.prototype);//继承父类的方法:先创建了一个临时的构造函数,然后将父亲的原型对象作为这个构造函数的原型,最后返回临时类型的新实例//然后让儿子的原型对象指向临时类型的新实例(这样就可以实现继承了)Son.prototype.constructor = Son;var son = new Son('aaa',23);console.log(Son.prototype);console.log(son.__proto__.constructor)
object.create相当于下面的create函数(不用写)function create(obj) {function F() {}//先创建了一个临时的构造函数F.prototype = obj;//然后将传入的对象作为这个构造函数的原型return new F();//返回了临时类型的新实例}

Es6实现继承
class Father{constructor(x,y){this.x = x;this.y = y;}sum(){console.log(this.x + this.y);console.log(this.x)}say(){return '我是爸爸'}}class Son extends Father{constructor(x,y){super(x,y);//调用了父类中的构造函数,必须在子类this之前调用this.x = x;this.y = y;}say(){console.log(super.say() + '的儿子')//super调用父类的普通函数}}var son = new Son(1,2)son.sum();
12、讲一讲Promise;语法
promise主要用于异步状态,可以将异步状态操作队列化,按照希望的顺序执行,用来替换es5的异步回调,解决回调地狱。
promise有三种状态,pending进行中,fulfilled成功,rejected失败。异步操作的结果可以决定是哪种状态。对象状态改变只有两种可能:从pending变成fulfilled和从pending变成rejected;状态改变之后不会再变,称为已定型resolved。
Promise的缺点:
无法取消promise,一旦新建它就会立即执行,无法中途取消。
如果不设置回调函数,promise内部抛出的错误,不会反映到外部
当处于pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)
Promise用法
Promise的构造函数接收一个函数作为参数,这个函数得传入两个参数:异步操作执行成功后的回调函数resolve和异步操作失败后的回调函数reject。
Promise.then
Promise.then方法也可以接收两个参数,第一个对应resolve的回调,第二个对应reject的回调。第二个参数是可选的,不一定要提供。
Promise.catch
Promise.catch方法和.then方法的第二个参数一样,用来指定reject的回调。不过它还有另外一个作用,在执行resolve回调(也就是.then的第一个参数时),如果代码出错,并不会报错卡死js,而是进入到catch这个方法中。
Promise.all
Promise.all方法接收一个数组参数(可迭代对象,例如数组,map,set),返回一个promise对象。提供了并行执行异步操作的能力,并且在所有异步操作执行完成后才执行回调。也就是将多个promise实例包装成一个新的promise实例。如果有一个promise失败,都失败;如果都成功,结果才返回成功。(项目中写删除选中的全部商品时用到了promise.all。因为之前写好了删除某一个产品的方法,所以把选中的商品遍历,用promise.all封装起来)
Promise.any
Promise.any方法接收一组promise实例作为参数,只要有一个promise成功,就返回已经成功的那个promise,如果没有一个promise成功,就返回一个失败的promise和AggregateError类型(它把单一的错误集合在一起)的实例。
Promise .finally
Promise .finally方法接收一个回调函数作为参数,返回一个promise。在promise结束时,无论结果是fulfilled或者是rejected,都会执行这个回调函数。避免了同样的语句.then和.catch中各写一次的情况。
Promise .race
Promise .race方法接收一个可迭代对象作为参数,迭代器中哪个promise获得的快,就返回那个结果,不管结果本身是成功状态还是失败状态。
Promise.allSettled
Promise.allSettled方法返回一个在所有给定的promise都已经fulfilled或rejected后的promise,并带有一个对象数组,每个对象表示对应的promise结果。
const promise1 = Promise.resolve(3);
const promise2 = new Promise((resolve,reject)=>setTimeout(reject,100,'foo'));
const promise3 = [promise1,promise2];
Promise.allSettled(promise3).then((results)=>results.forEach((result)=>console.log(result)))
结果是:
{ status: 'fulfilled', value: 3 }
{ status: 'rejected', reason: 'foo' }
13、如何中止promise链式调用
(1)抛出一个异常,然后用catch接收
(2)返回一个pending状态的promise对象也可以结束回调,但是这样finally和catch都不会执行。
(3)返回一个rejected状态的promise
14、promise发生错误,怎么捕捉
- 在then中指定异常处理函数,在then中添加两个函数,第二个函数用来处理失败的情况。
- 用.catch实现全部捕获。
- 在浏览器端,用window对象监听异常,监听方式是onunhandledrejection和onrejectionhandled,然后在回调函数中都会创建一个参数,该参数是个对象,包含了type,reason(错误原因),promise。
15、手写promise;手写promise.all;手写promise.any;手写promise.finally;手写Promise.race;手写Promise.allSettled
手写Promise
class WPromise {static pending = 'pending';//static静态方法/静态属性;表示该方法不会被实例继承;而是通过类来直接调用static fulfilled = 'fulfilled';static rejected = 'rejected';constructor(executor) {this.status = WPromise.pending;//初始化状态为pendingthis.value = undefined;//存储操作成功(this._resolve)返回的值this.reason = undefined;//存储操作失败(this._reject)返回的值this.callbacks = [];//存储then中传入的参数,同一个promise的then方法可以调用多次,所以用数组存executor(this._resolve.bind(this), this._reject.bind(this));//_方法名:表示这是只限于内部使用的私有方法}//onFulfilled是成功时执行的函数;onRejected是失败时执行的函数then(onFulfilled, onRejected) {//返回一个新的promisereturn new WPromise((nextResolve, nextReject) => {//把下一个promsie的resolve函数和reject函数也存在callback中,是为了将//onFulfilled的执行结果通过nextResolve传入到下一个promise作为它的value值。this._handler({nextResolve,nextReject,onFulfilled,onRejected})})}_resolve(value) {//处理onFulfilled执行结果是一个promise时的情况if (value instanceof WPromise) {//当为true,说明promise肯定不是第一个promise,而是后续then方法返回的promisevalue.then(//获取value;当value是个promsie时,内部会存有value变量this._resolve.bind(this),this._reject.bind(this));return;}this.value = value;this.status = WPromise.fulfilled;//将状态设置为成功this.callbacks.forEach(cb => this._handler(cb));//通知事件执行}_reject(reason) {if (reason instanceof WPromise) {reason.then(this._resolve.bind(this),this._reject.bind(this));return;}this.reason = reason;this.status = WPromise.rejected;//将状态设置为失败this.callbacks.forEach(cb => this._handler(cb));}_handler(callback) {const {onFulfilled,onRejected,nextResolve,nextReject} = callbackif (this.status === WPromise.pending) {this.callbacks.push(callback);return;}if (this.status === WPromise.fulfilled) {const nextValue = onFulfilled ? onFulfilled(this.value) : this.value;//传入存储的值,未传入onFulfilled时,value传入nextResolve(nextValue);return;}if (this.status === WPromise.rejected) {const nextReason = onRejected ? onRejected(this.reason) : this.reason;//传入存储的错误信息,未传入onRejected时,reason传入nextReject(nextReason);}}}
测试:
let p = new WPromise((resolve,reject)=>{//resolve('ok')reject('error')})p.then((data)=>{console.log('成功' + data)},(err)=>{console.log('失败' + err)})
手写Promise.all:
思路:接收一个可迭代对象作为参数,方法返回一个promise实例,参数中的所有promise都完成时回调完成(resolve);如果参数中有一个promise失败,这个实例回调失败(reject)。
Promise.myAll = function(promises){if(!Array.isArray(promises)) return//判断参数是不是数组,是返回return new Promise((resolve,reject)=>{//返回一个promise实例const result = [];let count = 0;for(let i = 0;i < promises.length;i++){Promise.resolve(promises[i]).then(value=>{result.push(value);count++;if(count===promises.length){//相等也意味着promise都完成resolve(result)}}).catch((reason)=>{reject(reason)})}})
}
测试:
Const promise1 = Promise.resolve(3);const promise2 = 42;const promise3 = new Promise((resolve, reject) => {setTimeout(resolve, 100, 'foo');});Promise.myAll([promise1, promise2, promise3]).then((values) => {console.log(values);});
手写Promise.any:
思路:接收一组promise实例作为参数,参数中只要一个promise成功,就返回那个已经成功的promise;如果没有一个成功,就返回一个失败的promise和aggregateError类型的实例(agreegateError用于把单一的错误集合在一起)
Promise.myany = function(promises){if(!Array.isArray(promises)) returnreturn new Promise((resolve,reject)=>{let errcount = 0;for(let i = 0;i < promises.length;i++){Promise.resolve(promises[i]).then(value=>{resolve(value)}).catch((reason)=>{errcount++;if(errcount>=promises.length){reject(new AggregateError('All promises were rejected'))}})}})}
测试:
const pErr = new Promise((resolve, reject) => {reject("总是失败");});const pSlow = new Promise((resolve, reject) => {setTimeout(resolve, 500, "最终完成");});const pFast = new Promise((resolve, reject) => {setTimeout(resolve, 100, "很快完成");});Promise.myany([pErr, pSlow, pFast]).then((value) => {console.log(value);// 打印‘很快完成’})Promise.any([pErr]).catch((err) => {console.log(err);//All promises were rejected})
手写Promise.finally:
思路:不管成功还是失败都会执行finally.因为不知道promise的最终状态,所以不接收参数
Promise.finally = function (callback) {let p = this.constructor;return this.then(value => p.resolve(callback()).then(() => value),reason => p.resolve(callback()).then(() => { throw reason }))}
测试:
const p = new Promise((resolve, reject) => {console.info('starting...');setTimeout(() => {Math.random() > 0.5 ? resolve('success') : reject('fail');}, 1000);});// 正常顺序测试p.then((data) => {console.log(`%c resolve: ${data}`, 'color: green')}).catch((err) => {console.log(`%c catch: ${err}`, 'color: red')}).finally(() => {console.info('finally: completed')});
手写Promise.race:
思路:接收一组promise实例作为参数,哪个promise获得的快,就返回那个结果,不管结果是成功还是失败。
Promise.myrace = function (promises) {return new Promise((resolve, reject) => {promises.forEach(promise => {promise.then(resolve, reject)});})}
测试:
const promise1 = new Promise((resolve, reject) => {setTimeout(resolve, 500, 'one');});const promise2 = new Promise((resolve, reject) => {setTimeout(resolve, 100, 'two');});Promise.myrace([promise1, promise2]).then((value) => {console.log(value);//two});
手写Promise.allSettled:
const promise1 = Promise.resolve(3);
const promise2 = new Promise((resolve, reject) =>setTimeout(reject, 100, "foo")
);
const promise3 = [promise1, promise2];
Promise.myAllSettled = function(promises){return new Promise((resolve,reject)=>{let count = 0;let resolvedCount = 0;const result = [];for(let promise of promises){let i = count;count++;Promise.resolve(promise).then((data)=>{resolvedCount++;result[i] = {status:'fullfilled',value:data}},(err)=>{resolvedCount++;result[i] = {status:'rejected',err}}).finally(()=>{if(resolvedCount>=count){resolve(result)}})}
})
}
Promise.myAllSettled(promise3).then((results) =>results.forEach((result) => console.log(result))
);
17、什么是事件委托(事件代理),为什么在父元素上绑事件,子元素上点击可能触发。
事件委托:把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理多个子元素的事件。
原理:事件冒泡。也就是事件从发生的元素一直向上传播,直到传递到document为止。在传播过程中,会依次检查经过的节点是否有事件监听函数,如果有,就执行。
事件委托的优点:
可以大量节省内存占用,减少事件注册(比如在ul上代理所有li的点击事件)
事件流/事件传播
一个事件触发后,会在子元素和父元素之间传播。这个传播(事件传播/事件流)分为三个阶段:捕获阶段,目标阶段,冒泡阶段。
捕获阶段:事件从document一直向下传播到事件发生的元素。
目标阶段:在目标节点上触发
冒泡阶段:事件从发生的元素一直向上传播,直到传播到document为止。
事件委托的实现
<ul id="list"><li>1</li><li>2</li><li>3</li><li>4</li>
</ul>
<script>let ul = document.querySelector('#list');ul.addEventListener('click', function (e) {let target = e.target;//被点击的目标元素while (target.tagName !== 'LI') {//target.tagName可以获取到元素名if (target.tagName === 'UL') {target = null;break;}target = target.parentNode;}if (target) {console.log('你点击了ui里的li')}})</script>
18、js数据类型,怎样判断数据类型;基本数据类型和引用数据类型的区别;怎么判断一个数组是不是Array类型(insatnceof,object.prototype.toString.call);堆和栈是什么
js数据类型
Js数据类型分为基本类型和引用数据类型。
基本类型(值放在栈中):number,string,null,undefined,boolean,symbol
引用数据类型(值放在堆内存中,栈中保存指向该数据的指针):object,array,function
堆和栈
栈:是一个先进后出的数据结构,它是由操作系统分配管理的,也就是说它的内存是规整的,内存的大小在申请之后不会发生变化。栈也不会出现碎片化,读取的速度很快。基本数据在声明的时候,内存的大小已经确定,它们会放到栈中。栈内存中的变量用完就会回收了。
堆:堆的内存分配比较自由,并不要求是连续的内存,只要有空间,都可以拿来分配,不过这样会导致产生很多碎片,不利于高速读取。堆主要存放的是大小不固定的内存结构。
判断方法
Typeof:
能够区分基本数据类型;不能区分array和null,都返回’object’
console.log(typeof [])//objectconsole.log(typeof null)//object
Instanceof:
主要检测的是引用值,原理是检测构造函数的原型(右边)是否出现在对象的原型链(左边)上。返回true/false.
能够区别array,object,function,不能判断number,string,布尔等基本类型数据
Object.prototype.toString.call():可以精准判断数据类型
var toString = Object.prototype.toString;console.log(toString.call(1));//[object Number]console.log(toString.call('ass'));//[object String]console.log(toString.call([]));//[object Array]console.log(toString.call({}));//[object Object]console.log(toString.call(undefined))//[object Undefined]
19、undefined和null的区别
Undefined代表的是未定义,而null表示的是一个空对象。
一个变量声明了但未赋值,就会返回undefined;而null主要用来初始化一些可能返回对象的变量。
20、箭头函数与普通函数的区别是什么?
(1)this
普通函数有自己的this,谁调用指向谁;箭头函数没有this,它会从作用域链的上一层继承this
(2)原型
普通函数有原型,箭头函数没有
(3)Arguments(arguments是一个传递给函数参数的类数组对象)
普通函数有arguments;箭头函数没有arguments对象,如果要用,可以用rest参数代替
(4)New
普通函数可以使用new,箭头函数不可以(原因在下一题)
21、构造函数可以使用new生成实例,那么箭头函数可以吗?为什么?
箭头函数不能使用new生成实例
原因:箭头函数没有自己的this,无法调用call,apply;
箭头函数没有prototype属性,而new命令在执行时需要将构造函数的prototype赋值给新的对象_proto_
New的过程:
- 创建一个新的对象
- 将新对象的__proto__设置为构造函数的prototype
- 让函数的this指向这个对象,执行构造函数中的代码
- 判断函数的返回值类型,如果是值类型,返回创建的对象;如果是引用类型,就返回这个引用类型的对象。
function myNew(constructor,...args){const obj = {};obj.__proto__ = constructor.prototype;const result = constructor.call(obj,...args)//让this指向实例return result instanceof Object?result:obj;}
测试:
var father = function(name,age){this.name = name;this.age = age}var a = myNew(father,'aaa',23);console.log(a)
22、循环(遍历)的方法,各个方法的区别
xxxxxxxxxx
array.map(function(currentValue,index,arr), thisValue)
xxxxxxxxxx
遍历
23、除了for…of还有哪些方法可以遍历字符串,数组中reduce方法有哪些参数,是怎样使用的
遍历字符串:for…in;for…of;str.charAt(2)返回指定下标的字符
reduce包含两个参数:回调函数,传给函数的初始值。reduce() 方法遍历数组中的每一项,接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。
24、怎么让对象的一个属性不可被改变
(1) Object.defineProperty()
可以使用Object.defineProperty()方法,让对象的某一个属性不可变,把对象某一属性的writable和configurable设置为false.
let obj = {a:1,b:2};Object.defineProperty(obj,'c',{value:100000,writable:false,//当该属性的 writable 键值为 true 时,属性的值才能被赋值操作修改configurable:false//当为true时,该属性的描述符才能够被改变,同时该属性也能从对应的对象上被删除。})obj.c = 282031283console.log(obj.c)//100000
(2)object.preventExtensions()
让对象不能添加新属性,可以使用object.preventExtensions()方法。(但是可以修改属性值)
let obj = {a:1,b:2};Object.preventExtensions(obj);obj.c = 1000;console.log(obj)
25.对浏览器的理解
浏览器主要的功能是将用户选择的web资源呈现出来。它需要从服务器请求资源,并将其显示在浏览器的窗口中。资源的格式通常是HTML,PDF,image等格式。用户用URI(统一资源定位标识符)来指定所请求资源的位置。
简单来说,浏览器可以分为两个部分,shell(脚本)和内核。其中shell的种类相对比较多,内核则比较少。shell是指浏览器的外壳,例如菜单,工具栏等。主要是提供给用户界面操作,参数设置等等,它是调用内核来实现各种功能的。内核才是浏览器的核心,它是基于标记语言显示内容的程序或模块。
26.对浏览器内核的理解
浏览器内核主要分为渲染引擎和JS引擎两部分。
渲染引擎的作用就是在浏览器窗口中显示所请求的内容,渲染引擎可以显示html,xml文档及图片,它也可以借用插件,显示其他类型的数据。例如使用PDF阅读器插件,可以显示PDF格式。
JS引擎可以解析和执行js来实现网页的动态效果。最开始渲染引擎和JS引擎区分的不是很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
27.浏览器所用的内核
IE:Trident内核
Chrome:以前是webkit内核,现在是Blink内核
Firefox:Gecko(/ˈɡekoʊ/)内核
Safari:webkit内核
Opera:最初使用的是presto内核,后来加入谷歌大军,从webkit内核又变成了Blink内核
360,猎豹浏览器:IE+chrome双内核
28.浏览器内核比较
Trident:是IE浏览器用的内核,对真正的网页标准支持不是很好,还有很多Bug等安全问题没有解决。很多用户开始转向其他浏览器。
Gecko:是firefox采用的内核,这个内核的优点是功能强大,丰富,可以支持很多复杂网页效果和浏览器扩展接口,缺点是会消耗很多内存。
Presto:opera曾经采用的就是presto内核,它是浏览网页速度最快的内核,它在处理JS等脚本语言时,会比其他的内核快3倍左右,缺点就是网页兼容性不好。
Webkit:是safari采用的内核,它的优点是网页浏览速度快,缺点是网页代码的容错性不高,也就是会让一些编写不标准的网页无法显示。
Blink:是chrome现在使用的内核,它就是webkit的一个分支。
29.浏览器的渲染原理
解析HTML,生成DOM树;解析CSS,生成CSSOM树(也就是css object model)。DOM树中每一个节点对应着网页里每一个元素;CSSOM树中每个节点对应着网页里每个元素的样式。
但是DOM/CSSOM树不能直接用于排版和渲染,浏览器会生成另一棵树:Render树。Render树生成的过程就是:从DOM树的根节点遍历每个可见节点(不可见节点就是:不会渲染输出的节点,比如script,meta,link等;一些通过css隐藏的节点,比如设置了display:none的节点(visibility和opacity在渲染树中)),对于每个可见的节点,找到cssom树中对应的规则并应用它们;根据每个可见节点和对应样式,组合生成渲染树。
构造渲染树之后,我们还需要计算它们在设备视口内确切的位置和大小,这个计算的阶段就是重排。
我们通过构造渲染树和重排阶段,知道了哪些节点是可见的,以及可见节点的样式和具体的位置,大小,那么就可以将渲染树的每个节点都转为屏幕上的实际像素,这个阶段就叫重绘。
经过重排重绘之后,我们就可以在浏览器上看到网页了。
30、重排重绘
重排:根据生成的渲染树,得到节点的几何信息(位置,大小),这个过程称为重排。
重绘:根据生成的渲染树和重排得到的几何信息,得到节点的绝对像素的过程称为重绘。
重排一定引起重绘,而重绘不一定会引起重排
什么时候发生重排?
添加或删除可见的DOM元素
元素的位置发生变化
元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
元素内容改变
页面一开始渲染的时候
浏览器的窗口尺寸变化(因为重排是根据视口的大小来计算元素的位置和大小的)
什么时候发生重绘?
DOM元素的字体颜色,背景色,visibility等改变会发生重绘
如何减少重排重绘?
在css方面:
使用visibility代替display:none(因为visibility只引起重绘,display:none改变了布局,引起重排)
避免使用table布局
将动画效果应用到position属性为absolute或fixed的元素上(因为它们脱离了文档流),避免影响其他元素布局,这样只是重绘
在js方面:
最小化重排和重绘,可以合并多次对DOM和样式的修改,然后一次性处理掉(比如修改css的class属性)
避免频繁读取会引发重排重绘的属性(比如offsetTop,scrollTop等),如果要多次用,就用一个变量缓存起来
浏览器的优化机制
由于每次重排都会造成额外的计算消耗,因此大多数浏览器都会通过队列化修改并批量执行来优化重排过程。
浏览器会将修改操作放入到队列里,直到过了一段时间或者操作达到了一个阈值,才清空队列。但是,当你获取布局信息的操作的时候,会强制队列刷新。比如当你使用了:offsetTop,offsetLeft,offsetWidth,offsetHeight,scrollTop,scrollLeft,clientTop,clientLeft等这些属性时会强制队列刷新,所以要避免使用,若要使用,最好用变量存储起来。
31、flat数组扁平化
flat方法
let arr1 = [1,2,['a','b',['中','文',[1,2,3,[11,21,31]]]],3];//使用 Infinity,可展开任意深度的嵌套数组
console.log( arr1.flat( Infinity ) );
递归处理(递归遍历每一项,若为数组继续遍历,否则concat(拼接))
function flat(arr) {let arrresult = [];arr.forEach(item => {if (Array.isArray(item)) {arrresult = arrresult.concat(flat(item)) } else {arrresult.push(item);}})return arrresult;}
用reduce实现的数组扁平化(遍历数组每一项,若为数组就继续遍历,否则就concat(连接))
function flatten(arr){return arr.reduce((result,item)=>{return result.concat(Array.isArray(item)?flatten(item):item)},[])//result初始值为[]}
reduce() 方法接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。reduce包含两个参数:回调函数,传给函数的初始值。
扩展运算符
while (arr1.some(Array.isArray)) {//判断数组元素是否为数组arr1 = [].concat(...arr1);//扩展运算符...和concat都可以去掉一层[]}console.log( arr1 );
Arr.some(条件):检测数组中的元素是否满足指定条件。返回布尔值,满足条件返回true。Arr1.concat(arr2):用于连接两个数组,将新数组的成员添加到原数组的尾部。返回一个新数组。
[].concat([[1],[2],[3]])->[[1],[2],[3]]
[].concat(1,[[2,3],[7]])->[1,[2,3],[7]]
已知如下数组:var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];编写一个程序将数组扁平化并去除其中重复部分数据,最终得到一个升序且不重复的数组
Arr.flat()->数组扁平化
New Set()->数组去重(会被变成set类)
Array.from()->将set类变为数组
Arr.sort(排序)
var arr = [ [1, 2, 2], [3, 4, 5, 5], [6, 7, 8, 9, [11, 12, [12, 13, [14] ] ] ], 10];let newarr = Array.from(new Set(arr.flat(Infinity)));console.log(newarr.sort((a,b)=>{return a-b}))
32、什么是闭包;闭包的作用;使用闭包实现每秒钟打印数组中的一个数组[5,4,3,2,1]
使用闭包实现每秒钟打印数组中的一个数组[5,4,3,2,1]
for(var i = 0;i < 5;i++){(function(j){setTimeout(()=>{console.log(j)},1000)})(i)}
闭包:
函数和函数内部能访问到的变量的总和就是一个闭包。
闭包产生的原因:
有作用域链的存在,因为作用域链不仅保存着当前的变量对象,还保存着创建该函数时的变量对象。当你查找一个变量时,如果在当前变量对象中没找到,就去上一个变量对象中去找。(函数作用域链是程序根据函数所在的执行环境栈来初始化的)
闭包的作用:
读取函数内部的变量
让变量的值始终保持在内存中
缺点:
闭包会让函数中的变量都保存在内存之中,内存消耗很大。在IE中,我们使用完闭包之后,依然回收不了闭包中的引用变量,会造成内存泄漏(用不到的变量,依然占着内存空间)。
可能会导致this指向不正常
33、输出什么/函数每秒依次输出
for(var i = 0;i < 5;i++){setTimeout(function(){console.log(i)},1000)}console.log(i)
每秒打印的都是5
(1)怎么修改可以让上面代码从1到5秒依次输出0-4,写出你能想到的所有方法
Let声明的变量会在当前的块级作用域里面创建一个文法环境,该环境里面包括了当前for循加粗样式环过程中的i(let会绑定作用域)
for (let i = 0; i < 10; i++) {setTimeout(() => {console.log(i);}, 1000)}
等价
for (var i = 0; i < 10; i++) {let j = isetTimeout(() => {console.log(j);}, 1000)}
闭包:用立即执行函数和闭包构建一个单独作用域
for (let i = 0; i < 10; i++) {(function (i) {setTimeout(() => {console.log(i);}, 1000)})(i)}
利用setTimeout函数的第三个参数,会作为回调函数的第一个参数传入
for (let i = 0; i < 10; i++) {setTimeout(i => {console.log(i);}, 1000,i)}
使用promise函数
for (var i = 0; i < 10; i++) {new Promise((resolve, reject) => {resolve(i)}).then(function(data){setTimeout(() => {console.log(data);}, 1000)})}
33、手写:ajax请求,解释状态码含义;

手写ajax
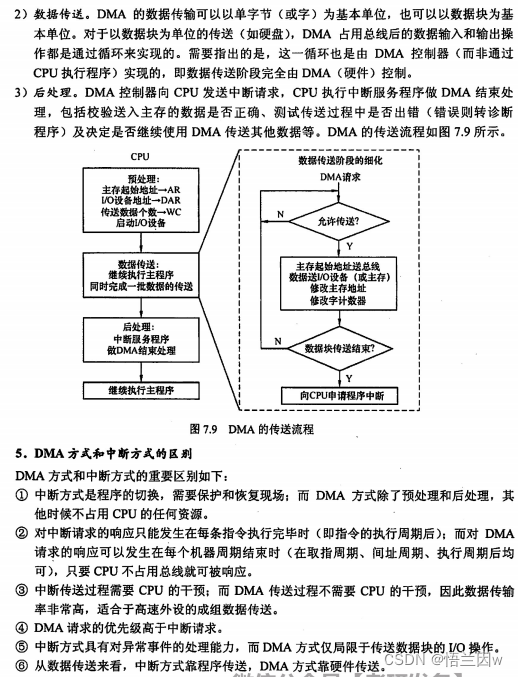
var xhr = new XMLHttpRequest();//1.创建ajax核心对象xmlhttprequestxhr.open('get','https://cnodejs.org/api/v1//topics',true);//2.向服务器发送请求,第三个参数是布尔值,如果为true就为异步,如果为false就为同步xhr.setRequestHeader('content-Type', 'application/x-www-form-urlencoded');//设置请求头xhr.send();//可以发送请求时携带参数xhr.onreadystatechange = function(){if(xhr.status===200&&xhr.readyState===4){//readyState用来标识当前XMLHttPRequest对象处于什么状态console.log(xhr.responseText)//responseText:获取字符串形式的响应数据}}
状态码含义
readystate状态码含义(ajax的5种状态):
0:未初始化,还未调用open方法
1:启动,已经调用open方法,但没有调用send方法
2:发送,已经调用send方法,但尚未接收到响应
3:接收,已经接收到部分数据
4:完成,已经接收全部数据了,可以使用
34、手写ajax请求,用promise封装
const ajax = function(url,method,data){//url:地址;method:请求方法;data:数据(可选)return new Promise((resolve,reject)=>{let xhr = new XMLHttpRequest();//1.创建xhr对象if((method==="get"||method==="GET")&&data){ //get方式并传参url = url +"?" +data;//把data拼接在地址栏里xhr.open("get",url);//发送请求xhr.send(null);}else if(method==="get"||method==="GET"&&!data){ //get方式不传参xhr.open("get",url);xhr.send(null);}else{ //post方式xhr.open("post",url);xhr.send(data);//可以携带参数}xhr.onreadystatechange = function(){//绑定事件对象if(this.status===200&&this.readyState===4){resolve(this.responseText); //将成功信息传入then方法}else if(this.status!==200&&this.readyState===4){reject(this.status);//将错误码传入then方法}}})}
测试:ajax("https://cnodejs.org/api/v1//topics","get").then(info=>{console.log(info);},err=>{console.log(err);});
35、== 和===的区别
== :只比较两边的值是否相等。当进行双等号比较时,先检查两个操作数的操作类型,如果相同,就进行恒等( === )比较;如果不同,就先进行类型转换,转换成相同类行再比较。
===:又叫严格判断,不仅比较值相等还比较类型是否相等。
Null= = undefined//true
把字符串化成数值比较
把true->1比较,把false->0比较
把对象换成基础类型再比较(利用对象内置的valueOf或toString方法1)
36、JS隐式转换
console.log([] == false)//true 布尔值转为number,为0;[]转为number,也为0;所以相等console.log({} == false)//false {}转为number为NAN,不相等console.log([] == ![])//true 两个[]不指向同一个地址,不相等,返回trueconsole.log(!!undefined)//false !隐式调用Boolean()函数console.log(Boolean(''))//falseconsole.log(Boolean(0))//falseconsole.log(Number([1, 2])); // NaNconst demo3 = {toString() {return 30},valueOf() {return {}}}console.log(demo3 - 4); //减号,将对象转为number,调用valueof函数,结果不是基础类型,继续调用toString,返回30,30-4=26
在JS中,当运算符在运算时,如果两边数据不统一,CPU就无法计算,JS引擎会把运算符两边的数据转成一样的类型再计算。这种自动转换的方式就叫隐式转换。
- 当进行加法运算时:
有一方为string,那么另一方也会被转为string
一方为number,另一方为原始值类型,则将原始值转换为number
一方为number,另一方为引用类型,将双方都转为string(引用类型转string就调用toString函数) - 乘除,减号,取模,就隐式调用Number()函数,转为number
- == (相等操作符)的类型转换是:
Null==undefined//true
布尔值与其他类型比较时,先转换为number
string与number比较,string转为number
引用类型与值类型比较,引用类型先转为值类型(引用类型转值类型调用valueOf函数,结果为基础类型就返回,不是基础类型就再调用toString)
引用类型与引用类型比较,直接判断是否指向同一对象
Null,undefined与其他任何类型进行比较,结果都为false - !隐式调用Boolean函数

37、如何让if(a1&&a2&&a==3)条件成立?
var a = ?;
if(a == 1 && a == 2 && a == 3){console.log(1);
}
解析:用==(相等操作符)判断会进行隐式类型转换,隐式转换会调用toString(将数组/num转换为字符串)或者valueOf方法,所以重写toString/valueOf方法就行了。
var a = {i: 1,toString() {//重写tosting方法return a.i++;}}if (a == 1 && a == 2 && a == 3) {//a==1 对象和数字比较,先把对象转换为基础类型(利用toString方法转换为字符串),再把字符串转化为数值console.log(1);}
38、JS的垃圾回收机制
JS的垃圾回收机制主要解决内存的泄露(不用的内存,没有及时释放)。它会定期的找出那些不再用到的变量(内存),然后释放其内存。
- 垃圾回收怎样进行
现在浏览器通常采用的垃圾回收机制有两种方法:标记清除和引用计数
(1)标记清除法:垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为0的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为0,等待下一轮垃圾回收
缺点:
标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片,并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题,假设我们新建对象分配内存时需要大小为 size,由于空闲内存是间断的、不连续的,则需要对空闲内存列表进行一次单向遍历找出大于等于 size 的块才能为其分配。
(2)引用计数:语言引擎中有一张引用表,保存了内存里面所有资源的引用次数。如果一个值的引用次数为0,就表示这个值不再用到了,因此可以将这块内存释放。
- 对象在垃圾回收机制中有三种状态:可达性,可恢复性,不可达性
当一个对象被创建后,只要有一个以上的引用变量引用它,这个状态就处于可达状态。
当一个对象失去了所有的引用之后,它就进入了可恢复状态。这个状态下,垃圾回收机制会随时对它占用的资源回收。
被垃圾回收机制回收之后,就会进入不可达状态。
v8引擎对垃圾回收做了哪些优化
V8中将堆内存分为新生代和老生代两区域。新生代的对象为存活时间较短的对象,也就是新产生的对象;老生代的对象为存活时间长或者常驻内存的对象,也就是经历过新生代垃圾回收之后还存活下来的对象,容量通常比较大。
(1)新生代对象空间采用并行策略,也就是说垃圾回收器在主线程上执行的过程中,开启多个辅助线程,同时执行同样的回收工作。(JS是单线程语言,是运行在主线程的,那在进行垃圾回收时就会阻塞js脚本的执行,需要等待垃圾回收完毕之后再恢复脚本执行,这个就是全停顿)。
(2)老生代采用增量标记和懒性清理/并行回收。增量标记就是将一次垃圾回收标记的过程分成了很多小步,每执行完一小步就让应用逻辑执行(js)一会,这样交替多次后完成一轮GC标记。
老生代主要使用并发标记,主线程在开始执行js时,辅助线程也同时执行标记操作(标记操作全都由辅助线程完成)。标记完成之后,再执行并行清理操作,同时,清理的任务会采用增量的方式分批在各个js任务之间执行。
增量标记:对活动对象和非活动对象进行标记
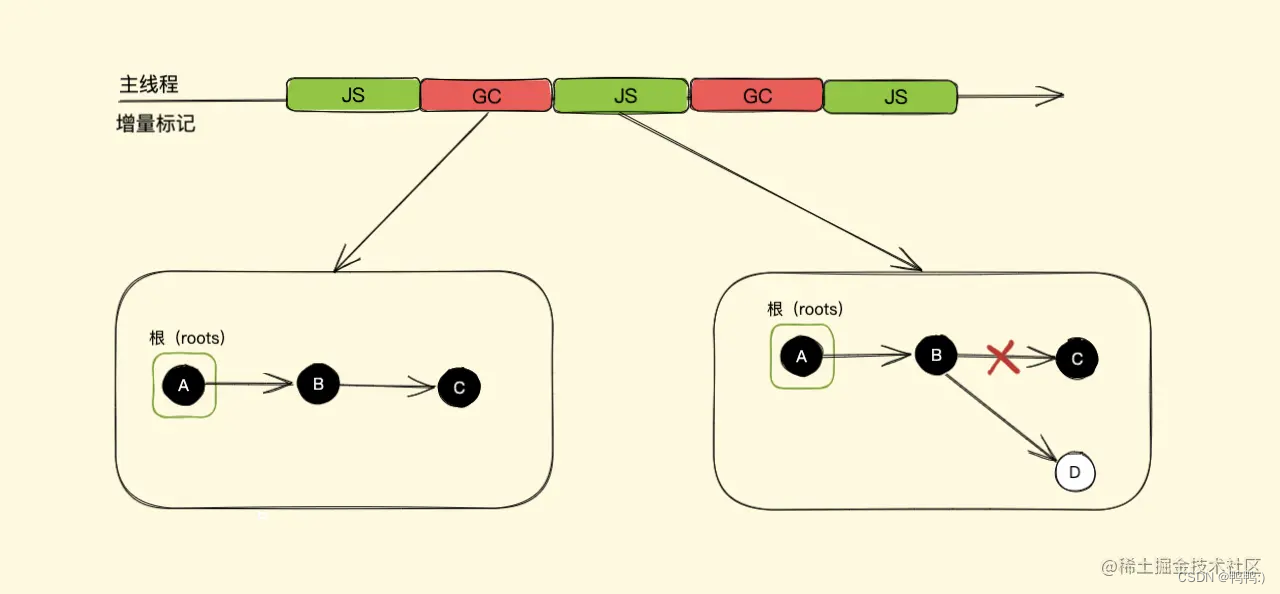
将一次完整的gc标记分次执行,那在每一小次gc标记执行完之后如何暂停下来去执行任务程序,之后又如何恢复?V8对这两个问题提出的解决方案是三色标记法和写屏障。
三色标记法:两个标记位编码了3种颜色:白,黑,灰。白色指的是未被标记的对象,灰色指的是自身被标记,成员变量(该对象的引用对象)未被标记。黑色是指自身和成员变量都被标记。从根开始标记,最后剩下的白色对象都是不可达的,也就是等待回收。
采用三色标记法后在恢复时就好办了,可以直接通过当前内存中有没有灰色节点来判断整个标记是否完成,如果没有灰色节点,直接进入清理阶段,如果还有灰色标记,恢复时直接从灰色的节点开始继续执行就可以。
三色标记法的mark操作可以渐进执行而不需要每次都扫描整个内存空间,可以很好的配合增量回收进行暂停恢复的一些操作,减少了全停顿的时间。
写屏障:一次完整的GC标记分块暂停后,执行任务程序时内存标记好的对象引用关系被修改了,也就是增量中修改引用。比如我们有A,B,C三个对象依次引用,在第一次增量分段中全部标记为黑色(活动对象),而后暂停开始执行应用程序也就是js脚本,在脚本中我们将对象B的指向由C改为了对象D,接着恢复执行下一次增量分段。我们来看新的对象D是初始的白色,按照之前说的,已经没有灰色对象了,也就是全部标记完毕接下来要清理了。新修改的白色对象D将在次轮GC的清理阶段被回收,还有引用关系就被回收,后面我们程序里可能还会用到对象D呢,这肯定是不对的。
为了解决这个问题,V8增量回收使用写屏障机制,也就是说一旦有黑色对象引用白色对象,该机制会强制将引用的白色对象改为灰色,从而保证下一次增量GC标记阶段可以正确标记,这个机制也被称为强三色不变性。
将对象B的指向由对象C改为D后,白色对象D会被强制改为灰色。
懒性清理:V8采用的是惰性清理来释放内存
增量标记完成之后,惰性清理就开始了。当增量标记完成之后,假如当前的可用内存足以让我们快速的执行代码,其实是没必要立即清理内存的。可以将清理过程稍微延迟一下,让js脚本代码先执行。也不用一次清理完所有非活动对象内存,可以按需逐一进行清理直到所有的非活动对象内存都清理完毕,后面再接着执行增量标记。
并发回收:
并行回收会阻塞主线程,增量标记与惰性清理让主线程的停顿时间减少,但并没有减少总暂停时间,也没有降低应用程序吞吐量。并发回收指的是主线程在执行js的过程中,辅助线程能够在后台完成执行垃圾回收的操作,辅助线程在执行垃圾回收的时候,主线程也可以自由执行而不会被挂起。
38、内存泄露(memory leak)
(1)什么是内存泄露
引擎中有垃圾回收机制,主要针对一些程序中不再使用的对象,对其清理回收释放掉内存。虽然引擎针对垃圾回收做了各种优化,尽可能确保垃圾得以回收,但是不是所有无用对象内存都可以被回收的,当不再用到的对象内存没有被及时回收,就叫内存泄露。
(2)常见的内存泄露
不正当的闭包
隐式全局变量
游离DOM引用:当我们使用变量缓存DOM节点引用之后删除了节点,如果不将缓存引用的变量置空,依然进行不了GC,也就会出现内存泄露。
遗忘的定时器:当不需要setTimeout或者setInterval时,最好调用clearInterval或者clearTimeout.如果没有被clear掉的话,就会造成内存泄露。
遗忘的事件监听器
遗忘的监听者模式
遗忘的map,set对象:当使用map或者set存储对象时,同object一致都是强引用,如果不将其主动清除引用,会造成内存不自动进行回收。可以使用weakset和weakmap存储对象,他俩是对对象对弱引用,也就是被认为是不可达的,可能在任何时候被回收。
未清理的console输出:浏览器保存了我们输出对象的信息数据引用,未清理的console输出也会造成内存泄露。因为console.log是全局方法,在打印当前组件中的变量时,实际上就相当于全局持有了这个变量的引用,垃圾回收的时候是不释放内存的。
39、内存三大件
内存泄露
内存膨胀:在短时间内内存占用极速上升到达一个峰值,想要避免需要使用技术手段减少对内存对占用。
频繁GC:GC执行的频繁,一般出现在频繁使用大的临时变量导致新生代。空间被装满的速度极快,而每次新生代装满时就会触发GC,频繁GC会导致页面卡顿
Cookie,localstorage,sessionstorage的区别(浏览器存储方式)
40、浏览器存储方式
cookie
cookie 是服务器保存在浏览器的一小段文本信息。浏览器每次向服务器发出请求,就会自动附上这段信息。
localStorage
localStorage保存的数据若不主动清空,则一直存在;
sessionStorage
sessionStorage保存的数据用于浏览器的一次会话,当会话结束(通常是窗口关闭),数据被清空;
IndexedDB
IndexedDB 就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。IndexedDB 允许储存大量数据,提供查找接口,还能建立索引。(非关系型数据库)
相同点
都存储在客户端
不同点
(1)Cookie存储数据的大小不能超过4kb;sessionStorage和localStorage的存储比cookie大得多,可以达到5Mb。
(2)生命周期不同:cookie在设置的过期时间(max-age)之前一直有效;localStorage是永久存储,浏览器关闭后数据不丢失除非主动删除数据;sessionStorage数据在浏览器窗口关闭后自动删除。
(3)Cookie的数据会自动传递到服务器;sessionStorage和localStorage数据保存在本地中。
39、JS的设计模式
模块模式
可以让特定部分的代码与其他部分相独立。它提供了松散耦合支撑了良好的代码结构。模块就是js中的类,类的好处就是封装,避免自身的状态和行为被其他类获取。模块模式允许私有和公有访问级别。
(function(){
//私有变量或者函数
return {
//公有变量或者函数
}
})()
原型模式
原型设计模式依赖于js原型继承。原型继承主要用来在性能密集的条件下创建对象。
观察者模式
观察者模式就是如果一个对象被更新,它会对依赖它的对象进行广播,告知它有变化发生了。
单例模式
单例模式旨在保证一个类仅有一个实例,并提供一个全局的访问点。
工厂模式
工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类
为什么JS单例模式不会产生互锁现象(异步)
40、考查原型和函数的打印题
function Foo() {Foo.a = function () {console.log(1)}this.a = function () {console.log(2)}}//是Foo的构造函数,没有产生实例,此刻也没有执行Foo.prototype.a = function () {console.log(3)}//在Foo的原型对象上挂载了方法aFoo.a = function () {console.log(4)}//给构造函数Foo挂载了直接方法aFoo.a();//4 立刻执行了Foo上的a方法let obj = new Foo();//调用了FOO的构建方法,把FOO的全局上的直接方法替换掉,输出1,在新对象上挂载直接方法a,输出值为2obj.a();//3cuo 2 因为有直接方法(this.a),所以不需要去原型链上访问Foo.a();//1
function Foo(){getName = function(){console.log(1);};console.log(this)//windowreturn this}//Foo的构造函数Foo.getName = function(){console.log(2)}//给Foo挂载了直接方法(2)Foo.prototype.getName = function(){console.log(3);}//在Foo原型上挂在了方法var getName = function(){console.log(4);}//存在变量提升function getName(){console.log(5)}//存在函数提升,函数提升在变量提升之上Foo.getName();//2 执行直接方法getName();//4 上面的执行顺序:function getName(){console.log(5)};var getName;getName=function(){console.log(4)} 4覆盖了5Foo().getName();//1 Foo()返回this,相当于this.getName(),全局范围,Foo中的getName未使用let,所以覆盖了4,打印1getName();//1
41、手写代码:浏览器打开了一个页面,在控制台执行脚本,获取页面TagName种类。
var list = document.querySelectorAll('*');var newlist = new Set();list.forEach(item=>{//console.log(item)newlist.add(item.tagName)//获取node的tagName属性(标签名)})console.log(Array.from(newlist));
42、连续赋值-输出以下代码的执行结果并解释为什么?(连续赋值的坑)
var a = {n:1};var b = a;a.x = a = {n:2};//a.x->a->a={n:2}->a.x={n:2}(这里的a仍然指向旧对象)(从左到右赋值)console.log(a.x);//undefinedconsole.log(b.x)//{n:2}
43、操作DOM的方法
创建新节点
document.createElement(eName); //创建一个节点
document.createTextNode(text); //创建文本节点
添加节点
document.insertBefore(newNode,referenceNode); //在某个节点前插入节点
parentNode.appendChild(newNode); //给某个节点添加子节点
删除节点
parentNode.removeChild(node); //删除某个节点的子节点 node是要删除的节点
替换节点
replace(newNode,oldNode);
获取/查找节点
document.getElementById(id); //返回对拥有指定id的第一个对象进行访问
document.getElementsByName(name); //返回带有指定名称的节点集合
document.getElementsByTagName(tagname); //返回带有指定标签名的对象的集合document.getElementsByClassName(classname); //返回带有指定class名称的对象集合
document.querySelector(‘#idxxx’)
document.querySelectorAll(‘.red’)[0]
属性操作
document.createAttribute(attrName); //对某个节点创建属性
getAttribute(name) //通过属性名称获取某个节点属性的值
setAttribute(name,value); //修改某个节点属性的值
removeAttribute(name); //删除某个属性
getQuerySelector和getClassName的区别
getQuerySelector只能是获取到静态的已经渲染出来的子元素,如果是动态创建加入的就获取不到。
getClassName可以实现获取动态元素。
44、求两个数组的并集和交集和差集
//求两个数组的并集和交集let a = [1,2,3];let b = [4,3,2];let a1 = new Set(a);let b1 = new Set(b)let union = new Set([...a,...b]);//并集let intersect = new Set([...a1].filter(item => b1.has(item)));//交集let different = new Set([...a1].filter(item=>!b1.has(item)))//a相对于b的差集console.log(union);console.log(intersect);console.log(different)
45、数组的常用方法
46.深拷贝和浅拷贝
浅拷贝:只复制指向某个对象的指针而不复制对象本身,新旧对象共享一块内存。无论在新旧对象上哪一个进行修改,两者都会发生变化。
深拷贝:会另外创造一个一模一样的对象,新对象和旧对象不共享内存,修改新对象不会修改原对象。
如何实现深拷贝
(1)用JSON.stringify()将对象转换为JSON字符串,再用JSON.parse()把字符串解析成对象。(可以处理对象和数组实现深拷贝,但不能处理函数)
let arr = [1,2,{name:'hst'}];let copyarr = JSON.parse(JSON.stringify(arr));copyarr[2].name = 'aaa'console.log(arr)console.log(copyarr)
(2)递归
function deepClone(currobj){if(typeof currobj !== 'object'){return currobj;}if(currobj instanceof Array){//是否为数组var newobj = [];}else{var newobj = {};}for(let item in currobj){if(typeof currobj[item] !== 'object'){//不是引用类型,则直接赋值newobj[item] = currobj[item];}else{//是引用类型,就递归遍历复制对象newobj[item] = deepClone(currobj[item])}}return newobj}
测试:
let obj = [1,2,{name:'hst'}];let copyobj = deepClone(obj);copyobj[2].name = 'aaa'console.log(obj)console.log(copyobj)
浅拷贝的方法
(1)Object.assign(目标对象,源对象):将源对象拷贝给目标对象,然后返回目标对象。
当object只有一层的时候,是深拷贝;当object有多层,是浅拷贝。
(3)array.concat和array.slice是浅拷贝。
47.手写instanceOf
function myInstanceOf(left,right){//判断构造函数的原型是否出现在对象的原型链上//原始值返回falseif(typeof left !== 'object'||left === null) return false;left = left.__proto__;while(true){if(left === null) return false;//找到原型链顶端了都没找到,返回falseif(left === right.prototype) return true;//比如[] instanceOf Arrayleft = left.__proto__}}console.log(myInstanceOf([],Array))
48.数组去重
(1)元素前后比较
var arr = [1,3,3,5,7,8,8]function unique(arr){var newarr = [arr[0]];for(let i = 1;i < arr.length;i++){if(arr[i] !== arr[i - 1]){newarr.push(arr[i])}}return newarr}console.log(unique(arr))
(1)用indexOf方法判断新数组中是否出现该元素
function unique(arr) {if (!Array.isArray(arr)) return;let newArr = [];for (let i = 0; i < arr.length; i++) {if (newArr.indexOf(arr[i]) === -1) {//indexOf()可返回数组中某个指定元素的下标;若返回-1,就是没找到newArr.push(arr[i]);}}return newArr;}
(2)利用es6中的set类
function unique1(arr){if (!Array.isArray(arr)) return;//return Array.from(new Set(arr));return [...new Set(arr)]}
49.New的实现(构造函数的执行过程,new实现、new的过程,new干了什么)
- 创建一个新的对象
- 将新对象的__proto__设置为构造函数的prototype
- 让函数的this指向这个对象,执行构造函数中的代码
- 判断函数的返回值类型,如果是值类型,返回创建的对象;如果是引用类型,就返回这个引用类型的对象。
function myNew(constructor,...args){const obj = {};obj.__proto__ = constructor.prototype;const result = constructor.call(obj,...args)//让this指向实例return result instanceof Object?result:obj;}
测试:
var father = function(name,age){this.name = name;this.age = age}var a = myNew(father,'aaa',23);console.log(a)
50.函数柯里化
柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。可以实现参数复用。
function curry(fn,currArgs){//fn是处理的原函数;currArgs是调用curry时传入的参数列表return function(){//返回一个匿名函数let args = [].slice.call(arguments);//将arguments数组化,不然arguments没法使用数组的方法if(currArgs !== undefined){//递归调用的时候进行参数拼接args = args.concat(currArgs);}if(args.length < fn.length){//判断args的个数是否与fn的参数个数相等,//相等就把参数传给fn;否则,继续递归调用,直到两者相等。return curry(fn,args);}return fn.apply(null,args);}}
Es6实现:
function curry(fn, ...args) {return fn.length <= args.length ? fn(...args) : curry.bind(null, fn, ...args);//判断args的个数是否与fn的参数个数相等,//相等就把参数传给fn;否则,继续递归调用,直到两者相等。}
测试:
function sum(a,b,c,d,e){console.log(a + b + c + d + e)}const fn = curry(sum);fn(1,2,3)fn(1)(2)(3)fn(3,2)(6)fn(1)(2)(3)(4)(5)
51.二分查找(顺序表)
表中元素按顺序排列才可以使用二分查找(升序、降序)。基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x(x是要查找的元素)做比较。如果x=a[n/2],则找到x,算法终止;如果x>a[n/2],就在a数组的右半部分查找;如果x<a[n/2],就在a数组的左半部分查找。
var findNumber = function(arr,target){if(arr.length === 0) return;let left = 0;let right = arr.length - 1;let middle = Math.floor(arr.length / 2);while(left <= right){if(arr[middle] === target){return middle;}else if(arr[middle] > target){//去左边找right = middle - 1;}else if(arr[middle] < target){//去右边找left = middle + 1}middle = Math.floor((left + right)/2)}}let arr = [1,2,3,4,4,5,6,6,8];let index = findNumber(arr,8);console.log(index)
52.两个数组合并成一个数组。请把两个数组 [‘A1’, ‘A2’, ‘B1’, ‘B2’, ‘C1’, ‘C2’, ‘D1’, ‘D2’] 和 [‘A’, ‘B’, ‘C’, ‘D’],合并为 [‘A1’, ‘A2’, ‘A’, ‘B1’, ‘B2’, ‘B’, ‘C1’, ‘C2’, ‘C’, ‘D1’, ‘D2’, ‘D’]。
let arr1 = ['A1', 'A2', 'B1', 'B2', 'C1', 'C2', 'D1', 'D2'];let arr2 = ['A', 'B', 'C', 'D']let result = []let temp = arr2[0];let j = 0;arr1.forEach((item,index)=>{if(temp === item.charAt(0)){//str.charAt(0) 返回字符串的第一个字符 或者把判断条件变成item.includes(temp)->判断字符串里面是否有某个字符result.push(item);}else{result.push(temp);result.push(item);temp = arr2[++j]}if(index===arr1.length-1){result.push(temp)}})console.log(result)
53、0.1+0.2 !== 0.3,如何让它等于
0.1+0.2=0.30000000000000004
原因:计算机计算0.1+0.2的时候,实际上计算的是两个数字在计算机内部存储的二进制之和,这两个数字转换为二进制后会无限循环。但由于标准位数有限,所以标准位后面的数字会被截掉,就产生了精度缺失。
54、Console.log(typeof typeof typeof null)
打印String。
Typeof null 返回object(是一个字符串),typeof typeof null返回string ,typeof typeof typeof返回string
55、 Let mySet = new Set();
mySet.add({});//mySetx.size?? 1
mySet.add({});//mySetx.size?? 2
56、 ParseInt(071)和parseInt(‘071’)分别会输出多少,js中有哪些表示数值的方式
57、[‘1’,’2’,’3’].map(parseInt) what? Why?
答案:[1,NaN,NaN]
原因:




58、实现 convert 方法,把原始 list 转换成树形结构,要求尽可能降低时间复杂度。(render函数)
以下数据结构中,id 代表部门编号,name 是部门名称,parentId 是父部门编号,为 0 代表一级部门,现在要求实现一个 convert 方法,把原始 list 转换成树形结构,parentId 为多少就挂载在该 id 的属性 children 数组下,结构如下:
// 原始 list 如下 let list =[
{id:1,name:‘部门A’,parentId:0},
{id:2,name:‘部门B’,parentId:0},
{id:3,name:‘部门C’,parentId:1},
{id:4,name:‘部门D’,parentId:1},
{id:5,name:‘部门E’,parentId:2},
{id:6,name:‘部门F’,parentId:3},
{id:7,name:‘部门G’,parentId:2},
{id:8,name:‘部门H’,parentId:4} ]; const result = convert(list, …);
// 转换后的结果如下 let result = [
{
id: 1,
name: ‘部门A’,
parentId: 0,
children: [
{
id: 3,
name: ‘部门C’,
parentId: 1,
children: [
{
id: 6,
name: ‘部门F’,
parentId: 3
}, {
id: 16,
name: ‘部门L’,
parentId: 3
}
]
},
{
id: 4,
name: ‘部门D’,
parentId: 1,
children: [
{
id: 8,
name: ‘部门H’,
parentId: 4
}
]
}
]
}, ];
function convert(list) {let res = [];let map = list.reduce((result, item) => {result[item.id] = item//保存map和id对象的映射return result}, {});list.forEach((item, index) => {if (item.parentId === 0) {res.push(item)}if (item.parentId in map) {let parent = map[item.parentId]//从map里面获取父节点parent.children = parent.children || []parent.children.push(item)}})return res}let list = [{ id: 1, name: '部门A', parentId: 0 },{ id: 2, name: '部门B', parentId: 0 },{ id: 3, name: '部门C', parentId: 1 },{ id: 4, name: '部门D', parentId: 1 },{ id: 5, name: '部门E', parentId: 2 },{ id: 6, name: '部门F', parentId: 3 },{ id: 7, name: '部门G', parentId: 2 },{ id: 8, name: '部门H', parentId: 4 }];console.log(convert(list))
给一个树形对象结构,写一个函数层次遍历这个树形结构
59、git常用命令
git config //配置详情
Git init //初始化仓库
Git remote//管理远程仓库,添加,删除和修改远程分支的关联
Git add//将文件提交到缓存区
Git push//将本地更新推送远程主机
Git status//显示文件状态,红色表示已修改未提交暂存区,绿色代表已提交到暂存区
60、linux常用命令
ls:显示目录下的内容
cd:切换目录
grep:在指定文件中搜索特定的内容。正则匹配。可用来查询DNS服务。
mkdir:建立子目录,所有用户都有权限。
$mkdir -m 777 tsk 创建目录名为tsk的目录
mv:为文件或目录改名;或者将文件由一个目录移入另一个目录。
rm:删除文件 rm -rf 可以删除非空目录
rmdir:删除空目录
cp:复制
touch:创建空文件
cat:用于连接并显示指定的一个或多个文件的有关信息。
cat最简单的一个用处是显示文本文件的内容。也可以将几个文件处理成一个文件,并将这种处理的结果保存到一个单独的输出文件。
tail
chmod:改变文件或者目录的访问权限。使用权限是超级用户。有两种用法,一种是字母和操作符表达式;另一种是包含数字的数字设定法。
数字属性的格式是3个0-7的八进制数,数字表示的含义是:0001为所有者的执行权限,0002为所有者的执行权限,0004为组的执行权限;0020为组的写权限,0040为组的读权限,0010为组的执行权限;0100为其他人的执行权限,0200为其他人的写权限,0400是其他人的读权限;1000为粘贴位置位等。
eg:chmod 666 tem ->代表所有用户对这个文件有读写权限
kill:终止一个进程。
vi编辑文件
ifconfig:用于查看和更改网络接口的地址和参数(包括IP地址,子网掩码,广播地址等)
ping:检测主机网络接口状态可以检测网络是否连通
ps:监视后台进程
61、实现一个计数器
<div class="text"><span id="demo">0</span></div><div class="btn"><button id="add">+</button><button id="sub">-</button></div><script>var counter = document.getElementById("demo").innerHTML;console.log(counter);var add = document.getElementById('add');var sub = document.getElementById('sub');add.onclick = function() {counter++;document.getElementById("demo").innerHTML = counter;}sub.onclick = function() {if(counter == 0) {counter = 0;} else {counter--;document.getElementById("demo").innerHTML = counter;}}</script>
62、判断一个函数是普通函数还是构造函数(补全funcA(){})
构造函数中this指向new创建的实例。所以可通过在函数内部判断this是否为当前函数的实例进而判断当前函数是否作为构造函数。
function A(){if(this instanceof A){console.log('我是构造函数')}else{console.log('我是普通函数')}}A();new A();
63、写一个简单的计算器类,实现±*÷,链式调用
使用class类:
class myCalculator{constructor(value){this.value = value}add(newvalue){this.value += newvaluereturn this}sub(newvalue){this.value -= newvaluereturn this}mul(newvalue){this.value *= newvaluereturn this}division(newvalue){this.value /= newvaluereturn this}}var num = new myCalculator(1);var result = num.add(2).sub(2).mul(5).division(1)console.log(result)
64、打印题
function f(x){var x;console.log(x)}f(5)//5f(a)//报错,a没有定义
65、让所有的c都变成h(包括大写的C) ‘abcdbac’
var str = 'abcdcbaC';console.log('abcdcbaC'.replace(/[cC]/g,'h'))
66、手写一个repeat()函数,加上下面的代码运行,使每3s打印一个helloword,总共执行4次
const repeatFunc = repeat(console.log,4,3000)
repeatFunc('helloword')
const sleep = (time)=>{return new Promise((resolve,reject)=>{setTimeout(resolve,time)})}const repeat = (todo,n,time) => {async function recall(data){while(n--){await sleep(time)todo.call(this,data)}}return recall}const repeatFunc = repeat(console.log,4,3000)repeatFunc('helloword')
67、promise,async,await的应用场景和区别
Promise和async/await常用的就是用来优化多重异步和异步嵌套,防止回调地狱
应用场景:
(1)需要先获取一个人的信息,在通过这个人的信息来进行另外操作,这两个异步操作需要按照先后顺序依次执行(使用async和await)
async function getAllInfo(){let info1 = await getinfo1()console.log(info1)let info2 = await getinfo2(info1)console.log(info2)
}
getAllInfo()
function getinfo1(){return new Promise((resolve,reject)=>{setTimeout(()=>{resolve("get info1!!") },1000) })}
function getinfo2(info1){
//模拟耗时请求return new Promise((resolve,reject)=>{setTimeout(()=>{resolve("get info2!!!") },1000) })
}
(2)需要同时获取一个人的多方面信息,而且信息需要多个请求才能获得,但是获取的信息没有依赖关系,可以同时请求(使用promise.all)
async function getAllInfo(){Promise.all([getinfo1(),getinfo2()]).then((value)=>{console.log(value)}).
}
getAllInfo()
function getinfo1(){return new Promise((resolve,reject)=>{setTimeout(()=>{resolve("get info1!!") },1000) })}
function getinfo2(){
//模拟耗时请求return new Promise((resolve,reject)=>{setTimeout(()=>{resolve("get info2!!!") },2000) })
}
区别:
Promise链式操作,自己catch异常。async则要在函数内catch
69、补全myNew,让打印满足条件
function A() {this.a = 1;}A.prototype.b = 2;function myNew(constructor) {constructor.call(this);console.log(this)this.b = 12;}var a1 = new myNew(A);console.log(a1.a); // 1console.log(a1.b); // 12
70、作用域(分为全局作用域,函数作用域,块级作用域)
作用域就是变量和函数的可访问范围。
es6之前 js 的作用域只有全局作用域和函数作用域两种,es6 之后又新增了块级作用域。
● 全局作用域主要指的是在全局作用域下声明的变量,会在函数在程序的任何地方都能访问到
● 函数作用域只能由函数来创建,在函数作用域下声明的变量或函数,只能在函数里面访问到,在函数外面访问不到
js 采用的是 静态词法作用域,也就是函数的作用域是在创建的时候就已经决定了。
作用域的是有着上下级关系的,上下级关系的确定就是看函数是在哪个作用域下创建的。
作用域的最大用处我觉得就是隔离变量,因为在不同的作用域下的同名变量不会有冲突
var count = 10;function a() {return count + 10;js是静态词法作用域,函数声明时词法作用域就已经确定了,这个题在函数声明时能够访问的是自身的词法作用域,如果没有就会访问全局的词法作用域。
}function b() {var count = 20;return a();
}console.log(b());//20
71、求连续子数组的最大和
思路:动态规划问题,从头开始遍历数组,遍历到arr[i]时,连续的最大和可能为max(dp[i-1])+arr[i],也可能为arr[i].做比较即可得出哪个更大,取最大值。
(1)动态规划
let arr1 = [1, 4, -5, 9, 8, 3, -6]function getMax(arr){//从1到j,将j之前的数字加起来,与arr[j]比较谁大,谁大就选谁//这样层层往前压缩范围选出数字if(arr.length<1){return 0;}if(arr.length===1){return arr[0]}var res = [];res[0] = arr[0];var result = res[0];for(let i = 1;i < arr.length;i++){//将之前的数字加起来与这个位置上的数字比较谁更大,把数字大的保留下来res[i] = Math.max(res[i - 1] + arr[i],arr[i]);//每次比较后都选出目前最大的和result = Math.max(result,res[i]);}return result;}let max = getMax(arr1);console.log(max)
(2)动态规划
let arr1 = [1, 4, -5, 9, 8, 3, -6]function getMax(arr){let dp = new Array(arr.length);//首先定义一个与arr同纬度的数组dp[0] = arr[0];for(let i = 1;i < arr.length;i++){dp[i] = dp[i-1]>0?dp[i-1] + arr[i]:arr[i]//dp[i]是第i个元素之前的所有子数组的和的最大值//当dp[i-1]大于0的时候,加上此时的arr[i],才是包含第i个元素的所有子数组的最大值}dp.sort((num1,num2) => num2 - num1);return dp[0];}let max = getMax(arr1);console.log(max)
72、字符串相加/大数相加
思路:可以从字符串末尾的数字开始依次相加,需要用flag标志位记录是否进位
大数相加:可以将数组转为字符串之后相加
JS的Number类型是遵循IEEE754规范表示的,也就是JS能精确表示的数字是有限的,JS可以精确到个位的最大整数是2的53次方,超过这个范围精度就会丢失,造成JS无法判断大小。可以将number转换为string解决。
IEEE754标准规定了64位双精度浮点数的格式,最高的1位是符号位,然后是11位指数,剩下的52位都是有效数字。
//给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。let str1 = '1234'let str2 = '22'var addStrings = function (num1, num2) {//可以从字符串末尾的数字开始依次相加,需要用flag标志位记录是否进位let i = num1.length - 1;let j = num2.length - 1;let temp = 0; //目前相加的位置上的数字let flag = 0; //记录是否进位let res = ''; //返回的字符串while (i >= 0 || j >= 0 || flag) {let n1 = +num1[i--] || 0;//+num1[i--] 这个加号是让它变成数字类型let n2 = +num2[j--] || 0;temp = n1 + n2 + flag;if (temp > 9) {temp = temp % 10;flag = 1;} else {flag = 0;}res = temp + res;}return res;};console.log(addStrings(str1,str2))
73、搜索二维矩阵
使用二分查找先找到target在哪一行,然后在这一行内继续二分查找
let arr = [[1, 3, 5, 7], [10, 11, 16, 20], [23, 30, 34, 50]]let target = 13;var search = function (matrix, target) {let m = matrix.length;//行数if (m === 0) return false;let n = matrix[0].length;//获取列数let low = 0;let high = m - 1;let mid;let row = -1;//用二分查找在target哪一行while (low <= high) {mid = Math.floor((low + high) / 2);if (matrix[mid][0] > target) {high = mid - 1;} else if (matrix[mid][n - 1] < target) {low = mid + 1;} else {row = mid;break;}}if (row < 0) return false;//继续用二分查找在这一行查找low = 0;high = n - 1;while (low <= high) {mid = Math.floor((low + high) / 2);if (matrix[row][mid] > target) {high = mid - 1;} else if (matrix[row][mid] < target) {low = mid + 1;} else {return true;}}return false;};console.log(search(arr, target));
74、进制转换
(1)Number.toString(radix)
这个函数只能将十进制数字转换为任意进制的字符串形式,同样,radix表示进制,取值2~36。
function toBase(m,n){return m.toString(n)}console.log(toBase(100,2))console.log(toBase(10,3))
(2)原生写
//十进制到2~9任意进制的转化function toBase(m,n){let arr = [];let baseString = ''while(m > 0){arr.push(Math.floor(m % n));m = Math.floor(m / n);}//求出来的结果是反的//比如100的二进制是1100100,但是上面求出来是0010011while(arr.length != 0){baseString += arr.pop()}return baseString;}console.log(toBase(100,2));console.log(toBase(10,3));
75、大数相乘
76、事件监听
77、快排,哈希,插入排序
插入排序
var insert = function(nums){var temp,onner;for(let i = 1;i < nums.length;i++){var temp = nums[i];onner = i;while(temp < nums[i - 1] && onner > 0){nums[i] = nums[i-1];i--;}nums[i] = temp;}}
78、随机生成一个颜色
function getColor() {var colors = "rgba(";for (var i = 0; i < 3; i++) {colors += Math.floor(Math.random() * 256) + ",";}colors += Math.random().toFixed(1) + ")";return colors}console.log(getColor())
79、“kuai-shou-gong-cheng"转化为"KuaiShouGongCheng”(变驼峰命名)
let str = 'kuai-shou-gong-cheng'//变为驼峰命名
let strArr = str.split('-');
for(let i = 0;i < strArr.length;i++){strArr[i] = strArr[i].charAt(0).toUpperCase() + strArr[i].substring(1);
}
console.log(strArr.join(''))
80、HashMap的数据结构
81、手写:字符串补0
82、值传递和引用值传递打印题
let obj = {a:0};function test(obj){//传进来一个obj的副本(也就是说副本也指向obj)obj.a = 1;//副本和obj指向同一块内存,一个变都变obj = {a:2};obj.b = 3;}test(obj);console.log(obj)//{a:1}
原因:ES中的所有函数的参数都是按值传递的,当函数参数为引用类型时,相当于将参数复制了一个副本到局部变量,这个副本就是指向内存中的地址。
83、只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
示例 1:
输入: [2,2,1]
输出: 1
思路:利用异或运算
a ^ a = 0
a ^ 0 = a
a ^ b ^ c = a ^ c ^ b
var arr1 = [4,1,2,1,2];
var singleNumber = function(arr){var result = 0;for(var i = 0;i < arr.length;i++){result ^= arr[i]}return result;
}
var number = singleNumber(arr1);
console.log(number)
84、多数元素
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
示例 1:
输入:[3,2,3]
输出:3
思路:用map保存数组元素和出现次数的映射,当出现次数大于n/2时,就返回
Map类似于对象,是键值对的集合(键不局限于字符串,各种类型都可以当做键)。
var arr = [3, 3, 4];var majorityElement = function (nums) {const n = nums.length / 2;let map = new Map();for (let i = 0; i < nums.length; i++) {//map[属性]可以取到这个属性的值,判断这个值是否存在,不存在 赋值为1,存在赋值+1map[nums[i]] = map[nums[i]] ? map[nums[i]] + 1 : 1if (map[nums[i]] >= n) {return nums[i]}}return null};var number = majorityElement(arr);console.log(number)
85、合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2
中的元素数目。 输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6] 解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6]
,其中斜体加粗标注的为 nums1 中的元素。
思路:先将nums2插入到nums1中,再排序
(1)普通排序
var nums1 = [0];
var m = 0,nums2 = [1], n = 1;
var merge = function(nums1, m, nums2, n) {nums1.length = m;for(let i = 0;i < nums2.length;i++){nums1.push(nums2[i])}nums1.sort(compare);}function compare(num1,num2){return num1 - num2;
}merge(nums1,m,nums2,n);
console.log(nums1);
(2)插入排序
var nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3;
var merge = function(nums1, m, nums2, n) {nums1.length = m;for(let i = 0;i < nums2.length;i++){nums1.push(nums2[i])}insert(nums1);}var insert = function(nums){var temp,onner;for(let i = 1;i < nums.length;i++){var temp = nums[i];onner = i;while(temp < nums[i - 1] && onner > 0){nums[i] = nums[i-1];i--;}nums[i] = temp;}}merge(nums1,m,nums2,n);
console.log(nums1);
86、外观数列
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。

第一项是数字 1
描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 “11”
描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 “21”
描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 “1211”
描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 “111221”
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。
思路:递归+遍历
var countAndSay = function(n){if(n===1) return '1';else{var str = countAndSay(n-1);//递归,把上一个字符返回var temp = str[0];//给temp初始化,让temp为temp[0]var count = 0;//计数var ans = '';//保存字符for(var i = 0;i<str.length;i++){//遍历if(str[i]===temp) count++;//一样计数else{//不一样的话把之前的赋值到ans中,重新给temp,count赋值ans += '' + count + temp;temp = str[i];count = 1;}if (i===str.length-1) ans += '' + count + temp;}return ans;}}console.log(countAndSay(1))//1console.log(countAndSay(3))//21
87、二叉树中序遍历(栈)(左根右)
(1)递归
function inOrder(root){var arr=[];//递归基if(!root) return;inOrder(root.left);arr.push(root.val);inOrder(root.right);return arr;
}
(2)栈
function visit(root,s){while(root){//先访问左子树,因此将将将根节点压入栈中,访问的时候先访问左子树,在访问右子树s.push(root);root=root.left;}
}
function inOrder(root){var s=[],arr=[];while(true){visit(root,s);if(s.length<=0) break;//如果当前弹出的是左子树,那么先将左子树根节点存储起来,访问右子树//如果当前是根节点,那么访问当前根节点的右子树,相当于上一个根节点左子树遍历完成,开始遍历根节点root=s.pop();arr.push(root.val);root=root.right;}
}
88、手写Promise并发控制调度器。大概是:一次性可能发10个请求,但是请求池控制一次性只能处理三个,请求池内的请求一个处理完后推进下一个请求
89、递归数组求和
function sum(arr) {var len = arr.length;if (len == 0) {return 0;} else if (len == 1) {return arr[0];} else {return arr[0] + sum(arr.slice(1));//计算的是 1+sum([2,3])-> 1+2+sum([3])}}
91、二维数组排列组合:
输入:[[A,B],[a,b],[1,2]]
输出:[Aa1,Aa2,Ab1,Ab2,Ba1,Ba2,Bb1,Bb2]
function serialArray(arr) {var lengthArr = [];var productArr = [];var result = [];var length = 1;for (var i = 0; i < arr.length; i++) {var len = arr[i].length;lengthArr.push(len);var product = i === 0 ? 1 : arr[i - 1].length * productArr[i - 1];productArr.push(product);length *= len;}for (var i = 0; i < length; i++) {var resultItem = '';for (var j = 0; j < arr.length; j++) {resultItem += arr[j][Math.floor(i / productArr[j]) % lengthArr[j]];}result.push(resultItem);}return result}var myArr = [['A','B'],['a','b'],[1,2]];console.log(serialArray(myArr));
92、输入abbccccaaa 输出a1b2c4a3
var compressString = function(S) {let result = ''let index = 0//记录字符出现次数,默认为1let count = 1while(index < S.length){//如果当前字符不等于下一个字符,则停止当前字符的计数,统计到result中,否则计数+1if(S[index] !== S[index + 1]){result += S[index] + count//当前字符计数完成后 重置计数为默认值count = 1}else{count++}index++}return result.length >= S.length ? S : result
};
93、反转链表
var reverseList = function(head) {// 判断头节点是否为空或者是否只有头节点if (head == null || head.next == null) {return head;}// 生成的新节点,递归调用const newHead = reverseList(head.next);// 将头节点的下一个指针指向头节点,也就是反转head.next.next = head;// 头节点的下一个指针指向nullhead.next = null;return newHead;
};
94、 Interface和type的区别
- type可以直接声明联合类型,interface不支持这种写法。(type unionType = myType1 | myType2)
- type可以声明基本类型(type myString = string)
- type和interface都可以用来表示接口,也都支持继承,并且可以互相继承。但interface的继承是通过extends实现的,type是通过&实现的。
95、never 和 void 的区别
void表示没有任何类型(可以被赋值为null和undefined)
never表示一个永远不存在的值,拥有void返回值类型的函数能正常运行,拥有never返回值类型的函数无法正常返回,无法终止,或者抛出异常
96、如何使 TypeScript 项目引入并识别编译为 JavaScript 的 npm 库包?
97、简述工具类型 Exclude、Omit、Merge、Intersection、Overwrite的作用
(1)Exclude<T,U>:从T中排除出可分配给U的元素
type A = number|string|boolean
type B = number|boolean
type Foo = Exclude<A,B> 相当于type Foo = string
(2)Omit<T,K>:忽略T中的某些属性
type Foo = {name:string;age:number;
}
type Bar = Omit<Foo,'age'>
相当于
type Bar = {name:string;
}
(3)Merge<O1,O2>:是将两个对象的属性合并
(4)Intersection<T,U>:取T和U的交集属性
(5)Overwrite<T,U>:是用U的属性覆盖T的相同属性
(6)Partial:生成一个新类型,该类型与T拥有相同的属性,但是属性都是可选
(7)Compute<A & B>: 是将交叉类型合并
98、keyof 和 typeof 关键字的作用
keyof 索引类型查询操作符 获取索引类型的属性名,构成联合类型。
typeof 获取一个变量或对象的类型。
99、 字符串翻转
(1)
let str = 'hello world';
let newStr = str.split('').reverse().join('')
console.log(newStr)
(2)
let str = "i am good man ";
let newStr = "";
for(let i = 0;i<str.length;i++){let s = str.charAt(str.length-i-1)newStr += s;
}
console.log(newStr)//nam doog ma i
//从尾部开始遍历字符串,然后逐个拼接字符,得到最终的结果。100、去除字符串中重复字符
let str ="hello world";
let newStr = ''
let newArray =Array.from(new Set(str.split('')));//先把字符串转为数组,再变成set类去重,去重后再转为数组
console.log(newArray.join(''))//把去重后的数组转为字符串101、实现一个栈,要求实现min函数以返回栈中的最小值
思路实现:
push(x)函数:重点为保持辅助栈stack2中的元素是非严格降序的。
1.将x压入数据栈stack1
2.若辅助栈stack2为空或者x小于等于辅助栈stack2的栈顶元素,则将x压入辅助栈stack2
pop()函数:重点为保持数据栈和辅助栈的元素一致性。
1.执行数据栈stack1出栈,将出栈元素记为y
2.若y等于辅助栈stack2的栈顶元素,则执行stack2出栈
top()函数:直接返回数据栈stack1的栈顶元素
min()函数:直接返回辅助栈stack2的栈顶元素
复杂度分析:
- 时间复杂度O(1):push()、pop()、top()、min()四个函数的时间复杂度均为常数级别
- 空间复杂度O(N):当共有N个待入栈元素时,辅助栈stack2最差情况下存储N个元素,使用O(N)额外空间。
var MinStack = function() {this.stack1 = [];//数据栈this.stack2 = [];//辅助栈
};
MinStack.prototype.push = function(x) {this.stack1.push(x); //元素压入数据栈if(this.stack2.length == 0){//若辅助栈为空 直接压入this.stack2.push(x); }else{if(this.stack2[this.stack2.length - 1] >= x){//若辅助栈栈顶元素大于等于该元素 即数据栈中最小值更新this.stack2.push(x);}}
};
MinStack.prototype.pop = function() {var pop = this.stack1.pop();if(pop == this.stack2[this.stack2.length - 1]){//若删除的元素等于辅助栈的栈顶元素 即该元素是数据栈中的最小值 要删除辅助栈栈顶元素 更新最小值 this.stack2.pop();}
};
MinStack.prototype.top = function() {//返回数据栈的栈顶元素return this.stack1[this.stack1.length - 1];
};
MinStack.prototype.min = function() {//返回数据栈中的最小值 即辅助栈的栈顶元素return this.stack2[this.stack2.length - 1];
};var obj = new MinStack()obj.push(10);obj.push(9);obj.push(4);obj.pop()console.log(obj.min())
102、使用两个栈实现一个队列
**思路:**定义两个栈A和B,分别为入队栈和出队栈(栈:先进后出;队列:先进先出)
appendTail操作即放到入队栈中
deleteHead则从出队栈中拿(前提是入队栈先全部清空,放到出队栈中),如果没有则返回-1
//使用两个栈实现一个队列
var CQueue = function() {this.stackA = []this.stackB = []
};
CQueue.prototype.appendTail = function(value) {//从stack1入队this.stackA.push(value)
};
CQueue.prototype.deleteHead = function() {//当stack2不空时,从stack2出队if(this.stackB.length) {return this.stackB.pop()}else{//当stack2空时,将stack1中的所有元素依次压入stack2中while(this.stackA.length) {this.stackB.push(this.stackA.pop())}if(!this.stackB.length) {return -1}else {//此时stack1为空,以全部颠倒放入stack2,取出stack2中栈顶的元素出栈即为出队return this.stackB.pop()}}
};
var queue = new CQueue();
queue.appendTail(1);
queue.appendTail(2);
queue.appendTail(3);
console.log(queue)
queue.deleteHead();
console.log(queue)103、写一个函数来产生第n个斐波那契数
104、将数字转化为16进制
105、 compose 函数柯里化
106、计算数组交集
107、把id排序后对应的name拿出来
let list =[{id:10,name:'部门A'},{id:2,name:'部门B'},{id:34,name:'部门C'},{id:4,name:'部门D'},
]
//先存储每个id对应的item;把id单独拿出来排序;再拿出排序对应后的name
function getSortList(){let map = list.reduce((result,item)=>{result[item.id] = itemreturn result},{})let idArray = [];list.forEach((item,index)=>{idArray.push(item.id)})idArray.sort((a,b)=>{return a-b});let nameSortArray = [];idArray.forEach((item,index)=>{nameSortArray.push(map[item].name)})return nameSortArray
}
console.log(getSortList(list))
108、 组合和高阶函数;
109、 什么时候可以使用函数声明和表达式110、上下遍历——Node.parentNode、Node.firstChild、Node.lastChild 和 Node.childNodes;左右遍历——Node.previousSibling 和 Node.nextSibling;
111、性能——当有很多节点时,修改 DOM 的成本会很高,应该知道如何使用文档片段和节点缓存。
113、有这样一个场景,页面中有个列表,数据量非常大,如何保障页面不卡顿?(用虚拟列表)
(1)数据不分页
有的列表无法使用分页方式来加载,我们一般把这种列表叫长列表。(数据有多少就展示多少,例如,有1000条数据要在客户端全部展示,该怎么去优化列表数据的展示呢?)
因为DOM元素的创建和渲染需要的时间成本很高,在大多数情况下,完整渲染列表所需要的的时间不可接受。所以在只对可见区域渲染的情况下,可以达到极高的初次渲染性能。
非完整渲染长列表:一般有两种方式:懒渲染(是常见的无限滚动,每次只渲染一部分(比如10条),等剩余部分滚动到可见区域,就再渲染另一部分)和可视区域渲染(只渲染可见部分,不可见部分不渲染,在滚动条滚动时动态更新列表项)。
虚拟列表是指可视区域渲染的列表。是一种对长列表的优化方案。(虚拟列表的实现上,分为两种情况,列表项是固定高度的,列表项是动态高度的)
滚动容器元素:一般是window对象,我们可以通过布局的方式,在某个页面中指定一个或多个滚动容器元素。只要某个元素能在内部产生横向或纵向的滚动,那么它就是滚动容器元素。
可滚动区域:滚动容器元素的内部内容区域。假设有100条数据,每个列表项的高度是50,那么可滚动区域的高度就是100*50.可滚动区域当前的具体高度值可以通过滚动容器元素的scrollHeight属性获取。
可视区域:滚动容器元素的视觉可见区域,如果容器元素是window对象,可视区域就是浏览器的视口大小。
(2)数据分页的两种方法
大多数场景下,常见的列表展示方式是分页加载。分页加载又分为两种:普通的分页加载和无限滚动式的分页加载。
普通的分页加载通常需要用户进行点击进行列表的翻页操作,这种方式一般会在一页数据展示完毕的底部都会显示数据分页的页码,上一页,下一页,加载更多等按钮。
无限滚动式的分页加载时根据用户鼠标或者触摸板的向下滚动一直加载下一页数据,直到数据加载完毕,比如知乎首页就用的是这种方式。这种方式的优点是当用户向上滚动时不会再去加载上一页的数据。
还有的是采用两种方式结合进行数据展示,展示给用户的数据前几页是无限滚动的分页加载,当滚动到某页时,则需要用户点击触发下一页的数据的加载。(比如思否的首页)
(3)实现虚拟列表
实现虚拟列表就是在处理用户滚动时,要改变列表在可视区域的渲染部分。
计算当前可见区域起始数据的startIndex,计算当前可见区域结束数据的endIndex,计算当前可见区域的数据,并渲染到页面中。计算startIndex对应的数据在整个列表中的偏移位置startOffset,并设置到列表上。计算endIndex对应的数据相对于可滚动区域最底部的偏移位置endOffset,并设置到列表上。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oHJKrYI6-1667490285257)(https://image-static.segmentfault.com/227/201/2272011973-5bc939b290143)]
先假设每个列表项的高度都是30px,
114、表格实现如何做性能优化,比如有10万数据
A:分页、虚拟列表、缓存。
115、有一个会频繁触发的函数,该函数依赖页面中某些dom的offsetHeight属性,如何保障页面不卡顿?
A:答出节流即可,让其手写实现节流,能答出缓存offsetHeight的方案最佳(结合防抖)。
115、是否了解文档片段,在什么情况下使用?(DOM)
文档片段createDocumentFragment
A:在频繁对DOM操作时使用即可。 实际上浏览器会做优化,使用文档片段和不使用差不多。
我们在使用原生js进行开发时,经常会用到两种更新DOM节点的方法,innerHTML和appendChild(),innerHTML会完全替换掉原先的节点内容,如果我们想向元素追加子节点的话,会使用appendChild()方法,appendChild()方法接收的参数类型为单个的节点类型对象,如果想要添加多个子节点时,只能通过循环来实现。对DOM的操作次数越多,性能消耗会越大,循环添加节点,循环了多少次,就对DOM操作了多少次,性能消耗是很大的。我们可以用createDocumentFragment把要插入的节点进行打包,然后一次性添加。
DocumentFragments是DOM节点,不是主DOM树的一部分。通常的用例是创建文档片段,将元素附加到文档片段,然后将文档片段附加到DOM树。文档片段存在于内存中,不在DOM树中,所以将子元素插入到文档片段时不会引起页面回流。
116、如何判断一个元素是否在可视区域内?(DOM)
(1)滚动监听+scrollTop+offsetTop+innerHeight
scrollTop是指网页元素被滚动条卷去的部分。
offsetTop:元素相对于父元素的位置。
innerHeight:当前浏览器窗口的大小。(需要注意兼容性问题,IE8及更早以前没有提供取得浏览器窗口大小的属性,不过提供了API:document.documentElement.clientHeight/clientWidth,它可以返回元素内容及其内边距所占据的空间大小。)
三个属性的关系如图所示,所以当scrollTop+innerHeight>offsetTop时,在视口内,否则在可视区域外。
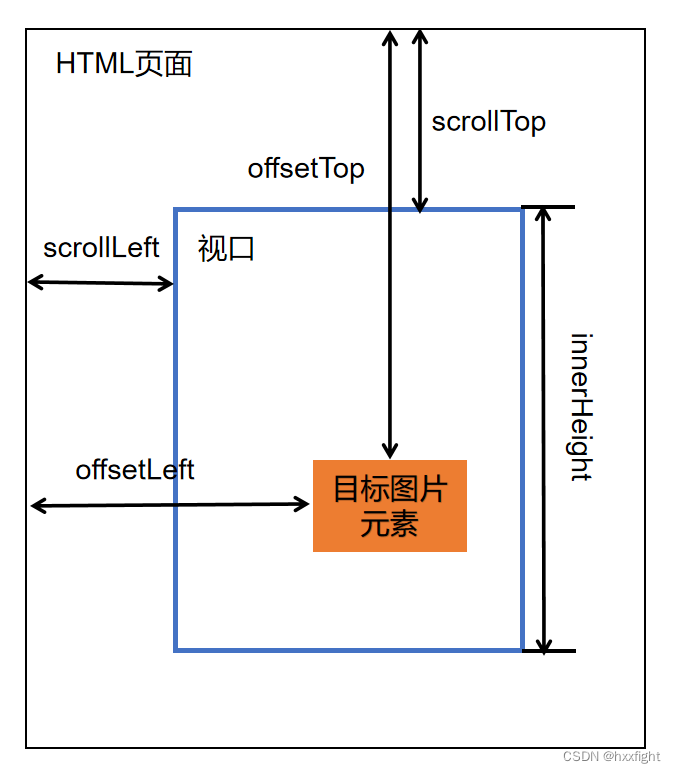
(2)滚动监听+getBoundingClientRect()
getBoundingClientRect方法返回元素的大小及其相对视口的位置。返回一个对象,对象属性包括top,right,bottom,left,width,height等属性。
所以当getBoundingClientRect().top>=0或者<offsetHeight时,元素就处于可视区域。
117、获取页面中第一个span的字体颜色
A:getComputedStyle(document.querySelector(‘span’)).color
118、ES6 代码转成 ES5 代码的实现思路是什么?
A:答出解析成AST,转化代码即可。
Babel是一个JS编译器,是一个工具链。主要用于将采用ES2015+语法编写的代码转换为向后兼容的JS语法,从而在老版本的浏览器中执行。Babel的本质就是操作AST来完成代码的转义。
解析(将模板解析成AST)---->转换(将高版本语法的AST转换成支持低版本语法的AST)---->生成(将AST转换成字符串形式的低版本代码);经过这三个阶段,代码就被babel转译成功了。
AST(抽象语法树Abstract syntax tree):
用JS中的对象来表示节点树,对象中的属性用来保存节点所需的各种数据,和vnode很像。
{
Tag:’div’,
Type:1,
Parent:undefined,
Children:[
{
Ta**加粗样式**g:’p’,
Type:1,
}
]
}
119、webpack打包有什么优化手段可以让打包出的内容尽量小或打包速度加快
(1)减少打包时间:
1.1优化loader,首先优化babel,babel会将代码转成模板字符串并生成AST,然后继续转换成新的代码,转换的代码越多,效率越低。可以优化一下loader的搜索范围,只对js文件使用babel,只在src文件夹下查找,不去查找node_modules下的代码,因为它是编译过的。
module.exports = {module: {rules: [test: /\.js$/, // 对js文件使用babelloader: 'babel-loader',include: [resolve('src')],// 只在src文件夹下查找// 不去查找的文件夹路径,node_modules下的代码是编译过得,没必要再去处理一遍exclude: /node_modules/ ]}
}
1.2可以将babel编译过的文件缓存起来,主要在于设置cacheDirectory.
loader: ‘babel-loader?cacheDirectory=true’
1.3happyPack
因为受限于Node的单线程运行,所以webpack的打包也是单线程的,使用happyPack可以将loader的同步转为并行,从而执行loader的编译等待时间。
module: {loaders: [test: /\.js$/,include: [resolve('src')],exclude: /node_modules/,loader: 'happypack/loader?id=happybabel' //id对应插件下的配置的id]
},
plugins: [new HappyPack({id: 'happybabel',loaders: ['babel-loader?cacheDirectory'],threads: 4, // 线程开启数})
]
(2)减少打包大小:
2.1按需加载
首页加载文件越小越好,将每个页面单独打包为一个文件,(同样对于loadsh类库也可以使用按需加载),原理即是使用的时候再去下载对应的文件,返回一个promise,当promise成功后再去执行回调。
路由组件按需加载;第三方组件和插件也按需加载引入;对于一些插件,如果只是在个别组件中用到,也可以不在main.js中引入,而是在组件中按需引入。
const router = [{path: '/index',component: resolve => require.ensure([], () => resolve(require('@/components/index')))},{path: '/about',component: resolve => require.ensure([], () => resolve(require('@/components/about')))}
]
2.2代码压缩
120、实现限制fetch并发数

批量请求:要实现批量请求,而且不需要按顺序发起请求,所以可以存到数组里面,然后进行遍历,取出数组中的每一项去fetch中进行调用。
可控制并发度:控制并发数的同时,每结束一个请求就发起一个新的请求。可以添加一个请求队列,只要维护这个队列,每次发起一个请求就添加进去,结束一个就丢出来。
全部请求结束,就执行callback。不能按照正常的顺序在函数调用之后执行,但是每次fetch有返回结果会调用then或者catch,我们可以在这个时候判断请求数组是否为空就可以知道是否全部被调用完。
(1)递归
function sendResquest(urls, max, callback) {let urlsCopy = [... urls];//防止影响外部urls变量function request() {function Handle () {count--;console.log('end 当前并发数为: '+count);if(urlsCopy.length) {//还有未请求的则递归request();} else if (count === 0) {//并发数为0则表示全部请求完成callback()}}count++;console.log('start 当前并发数为: '+count);//请求fetch(urlsCopy.shift()).then(Handle).catch(Handle);//并发数不足时递归count < max && request();}let count = 0;//几率并发数request();
}let urls = Array.from({length: 10}, (v, k) => k);let fetch = function (idx) {return new Promise(resolve => {let timeout = parseInt(Math.random() * 1e4);setTimeout(() => {resolve(idx)}, timeout)})
};let max = 4;let callback = () => {console.log('run callback');
};
//执行
sendResquest(urls, max, callback)(2)Promise
function sendResquest(urls, max, callback) { let pending_count = 0, //并发数idx = 0;//当前请求的位置while (pending_count < max) { _fetch(urls[idx++])} async function _fetch(url) { if (!url) return; pending_count++; console.log(url + ':start','并发数: '+pending_count); await fetch(url) pending_count--; console.log(url + ':done','并发数: '+pending_count); _fetch(urls[idx++]); pending_count || callback && callback()}
}let urls = Array.from({length: 10}, (v, k) => k);let fetch = function (idx) {return new Promise(resolve => {let timeout = parseInt(Math.random() * 1e4);setTimeout(() => {resolve(idx)}, timeout)})
};let max = 4;let callback = () => {console.log('run callback');
};
//执行
sendResquest(urls, max, callback)121、数组乱序
A:https://www.cnblogs.com/guolao/p/10173537.html
122、判断二叉树是否对称
A:
var isSymmetric = function(root) { if(root === null) return true; const dfs = (left, right) => { if (!left && !right) { return true; } else if (!left && right || left && !right) { return false; } return left.val === right.val && dfs(left.left, right.right) && dfs(left.right, right.left); } return dfs(root.left, root.right)}
124、手写Loadash中的get函数
125、断点续传如何实现
126、图片的上传接口如何写
127、如何保证上传的图片在服务器上不重复
128、上传的进度条如何得到
129、短链UUID算法
130、算法题,倒置N阶矩阵
131、给定一个数组,没有重复数字,输出全部排列组合
132、什么是dom和bom?
DOM是文档对象模型,它指的是把文档当做一个对象,这个对象主要定义了处理网页内容的方法和接口。
BOM是浏览器对象模型,它指的是把浏览器当做一个对象来对待,这个对象主要定义了与浏览器进行交互的方法和接口。