第一章 计算机抽象及相关技术
1.1 引言
1.1.1 传统的计算机应用分类及其特点
个人计算机(Personal Computer, PC) 通用,各种软件;受成本、性能权衡
服务器(Sever Computer) 基于网络;高容量、性能、可靠性;范围从小型服务器到建筑规模;用于为多个用户并行运行大型程序的计算机
超级计算机(Supercomputer) 高端科学和工程计算;最高的能力,但代表了整个计算机市场的一小部分
嵌入式计算机(Embedded Computer) 隐藏为系统的组件;严格的功率、性能、成本约束
1.1.2 欢迎来到后 PC 时代
个人移动设备(Personal Mobile Device, PMD) 电池驱动;连接到互联网;数百美元的;智能手机,平板电脑,电子眼镜
云计算(Cloud Computing) 仓库规模计算机(WSC);软件即服务(SaaS);软件的部分运行在PMD上,部分运行在云;Amazon和谷歌
1.1.3 下面将介绍
- 程序如何被翻译成机器语言 (以及硬件如何执行它们)
- 硬件/软件接口
- 什么决定程序性能 (和如何改进)
- 硬件设计人员如何提高性能
- 什么是并行处理
1.2 计算机体系结构中的 8 个伟大思想
面向摩尔定律的设计、使用抽象简化设计、加速经常性事件、通过并行提高性能、通过流水线提高性能、通过预测调高性能、存储层次、通过冗余提高可靠性
1.3 程序表象之下


1.4 箱盖后的硬件

一个典型的计算机包括 控制通路(Control)、算术逻辑单元(Arithmetic Logical Unit, ALU)、内存(Memory)、输入/输出(I/O) 五个部分
1.4.1 显示器

1.4.2 触摸屏
电阻和电容式:大多数平板电脑,智能手机使用电容式;电容式允许同时多次触摸 (取代键盘和鼠标)
1.4.3 打开机箱
CPU之中 数据通路(Datapath):对数据执行操作 控制(Control):序列数据路径,内存,…缓存内存(Cache Memory) 小快速SRAM(静态随机访问存储器 Static Random Access Memory)内存,用于立即访问数据
1.4.4 数据安全
易失性主存:在断电时丢失指令和数据。非易失性次存:磁盘、闪存、光盘(CDROM,DVD)
1.4.5 与其他计算机通信
1.5 处理器和存储制造技术
用以下三个公式来计算晶片价格
每 晶 片 的 价 格 = 每 晶 圆 的 价 格 每 晶 圆 的 晶 片 数 × 良 率 每晶片的价格=\dfrac{每晶圆的价格}{每晶圆的晶片数\times 良率} 每晶片的价格=每晶圆的晶片数×良率每晶圆的价格
每 晶 圆 的 晶 片 数 ≈ 晶 圆 面 积 晶 片 面 积 每晶圆的晶片数\approx \dfrac{晶圆面积}{晶片面积} 每晶圆的晶片数≈晶片面积晶圆面积 工 艺 良 率 = 1 ( 1 + 单 位 面 积 的 缺 陷 数 × 芯 片 面 积 2 ) 2 工艺良率=\dfrac{1}{(1+\dfrac{单位面积的缺陷数\times 芯片面积}{2})^2} 工艺良率=(1+2单位面积的缺陷数×芯片面积)21
1.6 性能
1.6.1 性能的定义
我们强调
性 能 X = 1 执 行 时 间 X 性 能 Y = 1 执 行 时 间 Y 性能_X=\dfrac{1}{执行时间_X}\qquad性能_Y=\dfrac{1}{执行时间_Y} 性能X=执行时间X1性能Y=执行时间Y1
若 有 性 能 X 性 能 Y = 执 行 时 间 Y 执 行 时 间 X = n 称 X 的 执 行 速 度 是 Y 的 n 倍 若有\quad \dfrac{性能_X}{性能_Y}=\dfrac{执行时间_Y}{执行时间_X}=n \quad 称 X 的执行速度是 Y 的 n 倍 若有性能Y性能X=执行时间X执行时间Y=n称X的执行速度是Y的n倍
1.6.2 性能的度量
运行时间:总响应时间,包括所有方面。处理,I/O,操作系统开销,空闲时间。决定系统性能。
CPU 时间:不同程序影响不同的CPU和系统性能
1.6.3 CPU 性能及其度量因素
程 序 的 C P U 执 行 时 间 = 程 序 的 C P U 时 钟 周 期 数 时 钟 频 率 = 程 序 的 C P U 时 钟 周 期 数 × 时 钟 周 期 时 间 程序的\mathrm{CPU} 执行时间=\dfrac{程序的\mathrm{CPU}时钟周期数}{时钟频率}=程序的\mathrm{CPU}时钟周期数\times 时钟周期时间 程序的CPU执行时间=时钟频率程序的CPU时钟周期数=程序的CPU时钟周期数×时钟周期时间
1.6.4 指令性能
C P U 时 钟 周 期 数 = 指 令 数 × C P I \mathrm{CPU}时钟周期数=指令数\times \mathrm{CPI} CPU时钟周期数=指令数×CPI
1.6.5 经典的 CPU 性能公式
C P U 时 钟 周 期 数 = ∑ i = 1 n ( C P I i × 指 令 数 i ) 平 均 C P I = ∑ i = 1 n ( C P I i × 指 令 数 i 总 指 令 数 ) \mathrm{CPU}时钟周期数=\sum_{i=1}^n (\mathrm{CPI}_i\times 指令数_i) \\平均\mathrm{CPI}=\sum_{i=1}^n(\mathrm{CPI}_i\times\dfrac{指令数_i}{总指令数}) CPU时钟周期数=i=1∑n(CPIi×指令数i)平均CPI=i=1∑n(CPIi×总指令数指令数i)
1.7 功耗墙
功 耗 ∝ 1 2 × 负 载 电 容 × 电 压 2 × 开 关 频 率 功耗\propto \dfrac{1}{2}\times 负载电容 \times 电压^2 \times 开关频率 功耗∝21×负载电容×电压2×开关频率
1.8 沧海巨变:从单处理器向多处理器转变
1.9 评测性能
1.10 谬误与陷阱
Amdahl 定律
改 进 后 的 执 行 时 间 = 受 改 进 影 响 的 执 行 时 间 改 进 量 + 不 受 影 响 的 执 行 时 间 改进后的执行时间=\dfrac{受改进影响的执行时间}{改进量}+不受影响的执行时间 改进后的执行时间=改进量受改进影响的执行时间+不受影响的执行时间
MIPS(每秒百万条指令数 Million Instructions Per Second):CPU 每秒执行几百万条指令
第二章 指令:计算机的语言
2.1 引言
Risc-v 指令系统(Instruction Set) 使用大端法存储数据,不要求字地址对齐
寄存器类型。64位-双字;32位-字
- x0:定值为0
- x1:返回地址
- x2:栈指针
- x3:全局指针
- x4:线程指针
- x5-x7,x28-x31:临时值
- x8:帧指针
- x9,x18-x27:过程调用保存
- x10-x11:函数参数与返回值
- x12-x17:函数参数
2.2 计算机硬件的操作
设计原则1:简单源于规整
2.3 计算机硬件的操作数
设计原则2:更少则更快
寄存器操作数:x0-31(00000-11111)
存储器操作数:imm(x?)
立即数操作数:addi x22,x22,4
2.4 无符号数和有符号数
2.5 计算机的指令表示
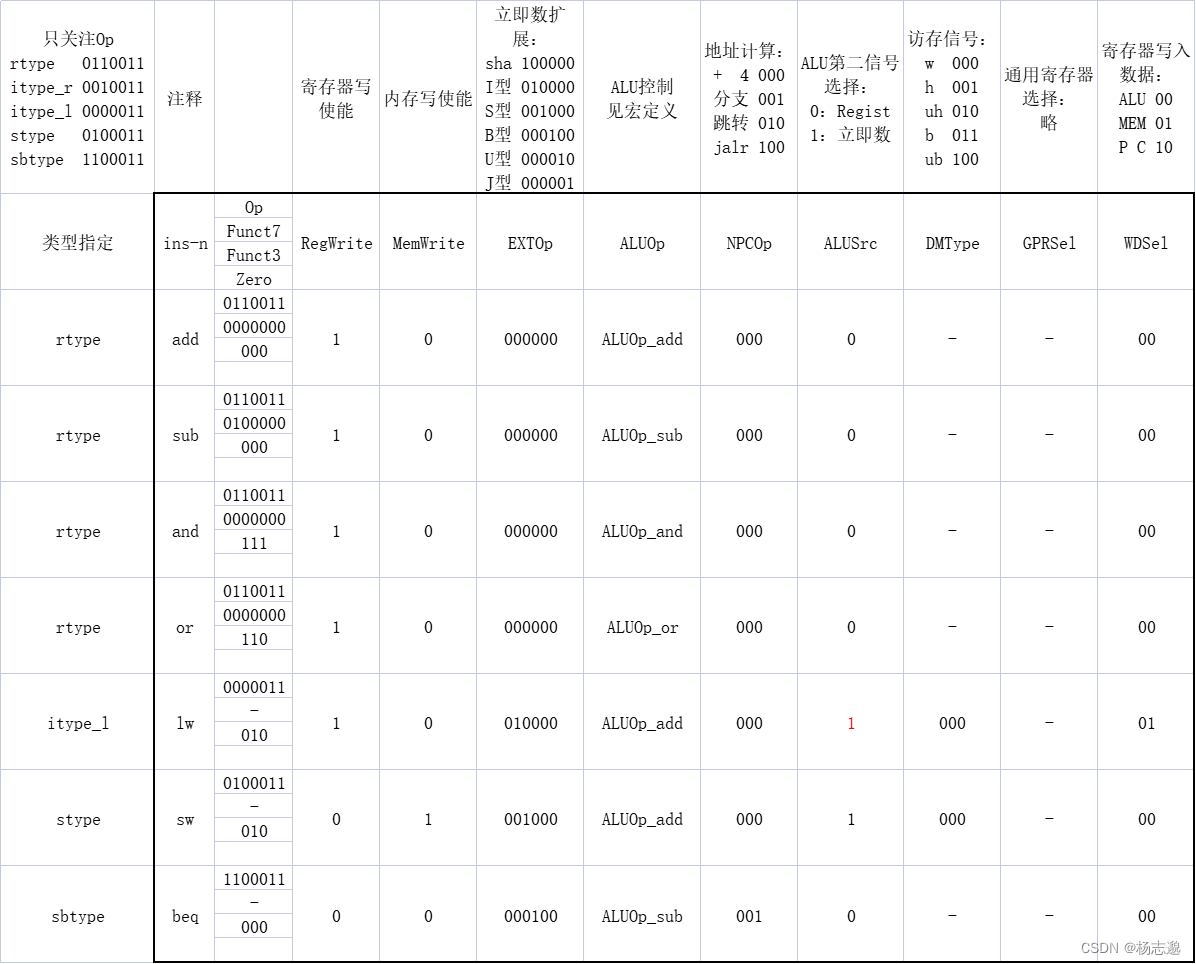
设计原则3:优秀的设计需要适当的折中
R-型指令

R-型指令包含:所有的不含立即数的算术逻辑运算指令
I-型指令

I-型指令包含:所有的含立即数的算术逻辑运算指令,所有的 load 指令,jalr指令
S-型指令

S-型指令包含:所有的 store 指令
2.6 逻辑操作
所有含有立即数的移位操作只需要少量的立即数位数,它们也是I-型指令
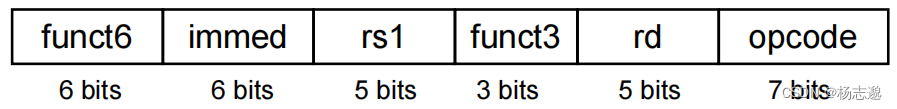
2.7 用于决策的指令
SB-型指令

SB-型指令包含:所有的条件分支指令
注意:SB-型指令没有第 0 位立即数,这意味着第 0 位缺省为 0 。只能跳转到偶数的位置。
条件分支指令采用 PC 相对寻址,跳转到 P C + i m m × 2 \mathrm{PC}+\mathrm{imm}\times 2 PC+imm×2
可以实现 循环 switch/case语句
2.8 计算机对于过程的支持
UJ-型指令

UJ-型指令包含:jal 指令
例 jal x1,L1
采用 PC 相对寻址,并且将返回地址 PC+4 赋值给 x1
另例 jalr x0,0(x1)
跳转到 0+x1 的位置,此处 x0 = 0 ,效果是丢弃返回地址
2.8.1 使用更多寄存器
2.8.2 嵌套过程
2.8.3 在栈中为新数据分配空间
2.8.4 在堆中为新数据分配空间
2.9 人机交互
我们分析一个例子
void strcpy (char x[], char y[])
{size_t i;i = 0;while ((x[i] = y[i]) != '/0') /* copy & test byte*/i += 1
}
strcpy:addi sp,sp,-8 // adjust stack for 1 doublewordsd x19,0(sp) // push x19add x19,x0,x0 // i=0
L1: add x5,x19,x11 // x5 = addr of y[i]lbu x6,0(x5) // x6 = y[i]add x7,x19,x10 // x7 = addr of x[i]sb x6,0(x7) // x[i] = y[i]beq x6,x0,L2 // if y[i] == 0 then exitaddi x19,x19, 1 // i = i + 1jal x0,L1 // next iteration of loop
L2: ld x19,0(sp) // restore saved x19addi sp,sp,8 // pop 1 doubleword from stackjalr x0,0(x1) // and return
2.10 对大立即数的 Risc-v 编址和寻址
2.10.1 大立即数
U-型指令

U-型指令包括 lui 指令 auipc 指令
U 型指令用来设置寄存器高位
2.11 指令与并行性:同步
在并行中避免数据竞争:两个处理器共享的内存。P1写,然后P2读取。数据竞争如果P1和P2不同步
需要使用原子操作,如下
保留加载:lr.d rd,(rs1) 从地址 rs1 加载,(rs1) -> rd
条件存储:sc.d rd,rs2,(rs1) rs2->(rs1) 存储,成功则设置 rd=0,失败则 rd=1。成功条件:内存值在上一次 lr.d 之后未更改。
可以通过该方案来对并行进程进行锁操作
addi x12,x0,1 // copy locked value
again: lr.d x10,(x20) // read lockbne x10,x0,again // check if it is 0 yetsc.d x11,x12,(x20) // attempt to storebne x11,x0,again // branch if fails
Unlock:sd x0,0(x20) // free lock
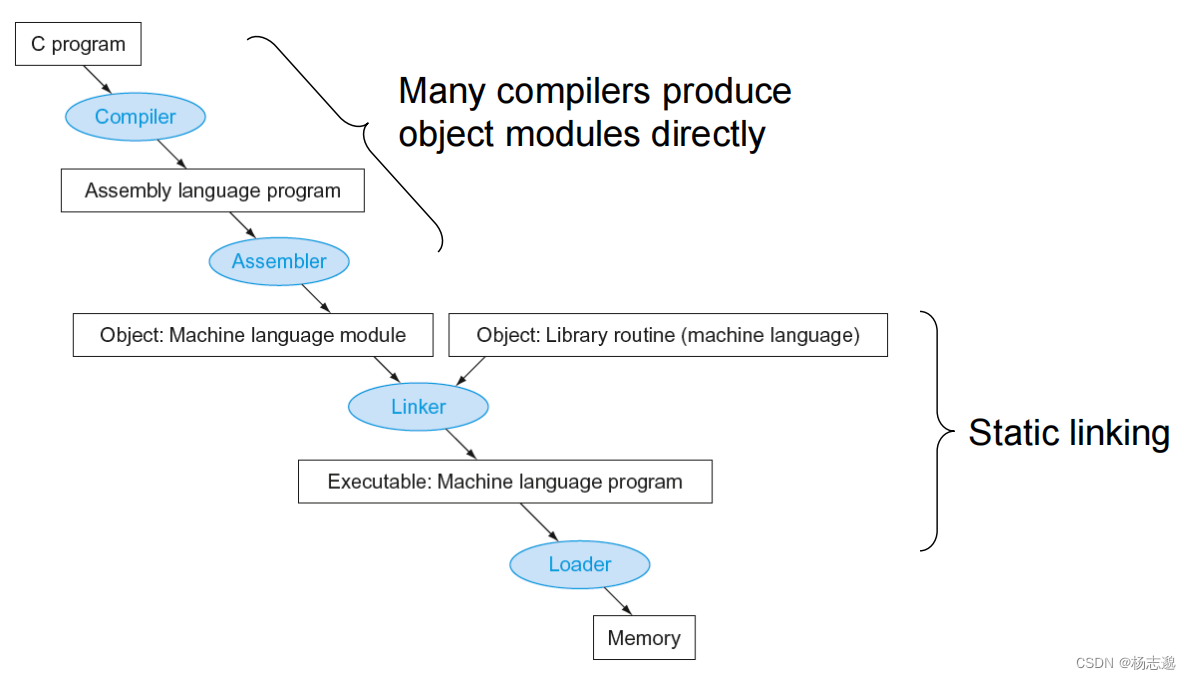
2.12 翻译并启动程序
第三章 计算机的算术运算
3.1 引言
本章包含,加减法,乘法,浮点运算,运算器
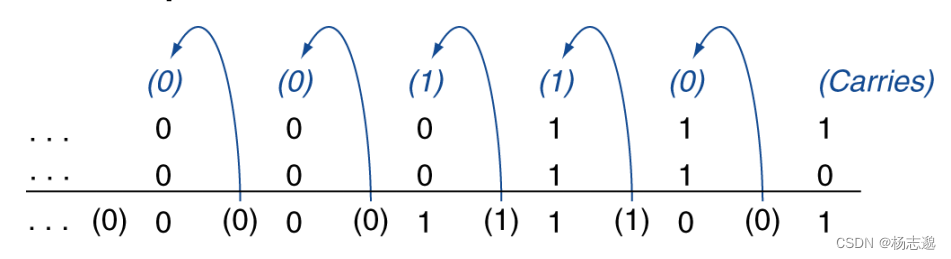
3.2 加法和减法
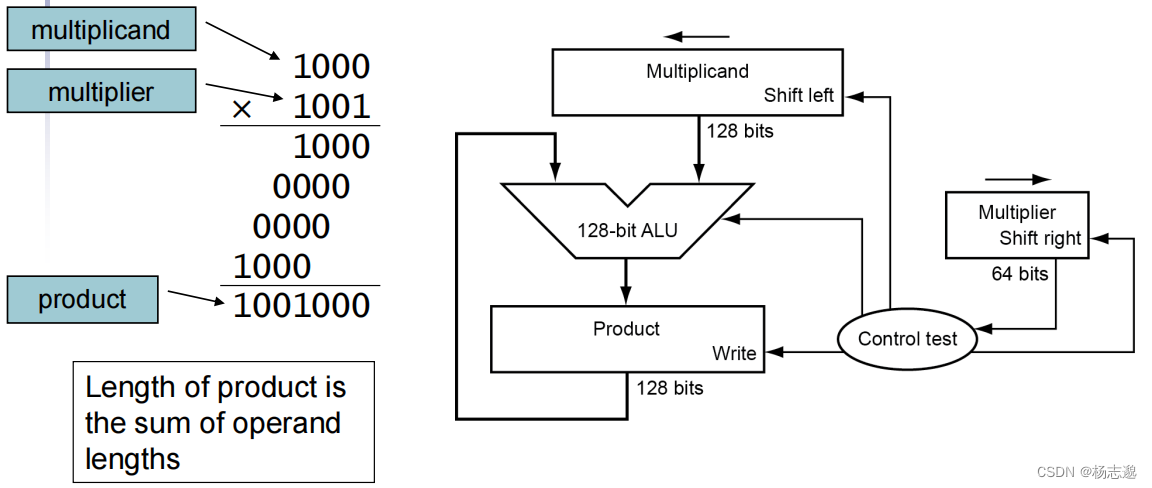
3.3 乘法
3.3.1 串行版的乘法运算及其硬件实现
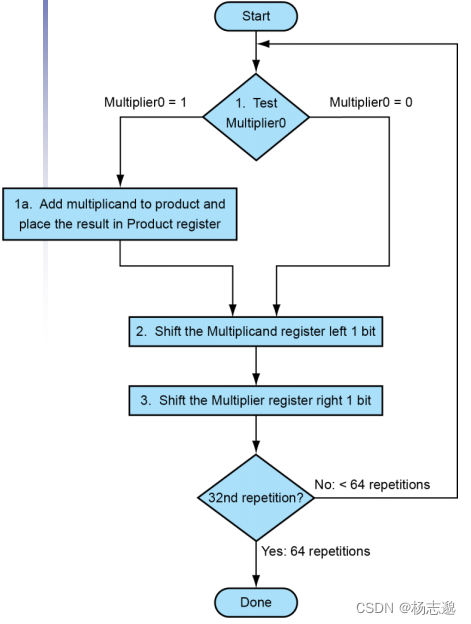
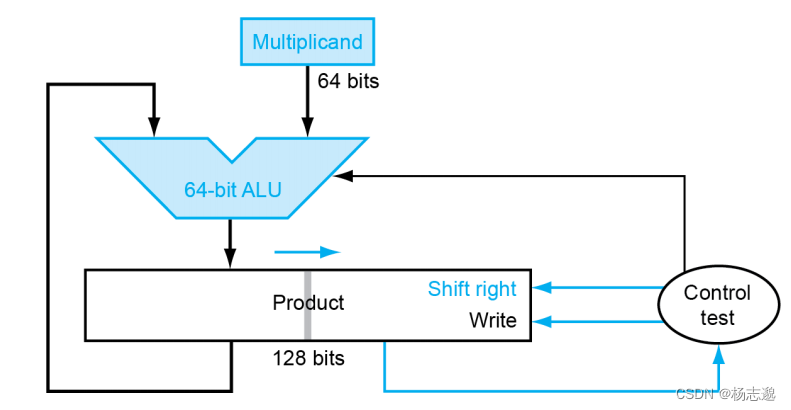
3.3.2 带符号的乘法
3.3.3 快速乘法
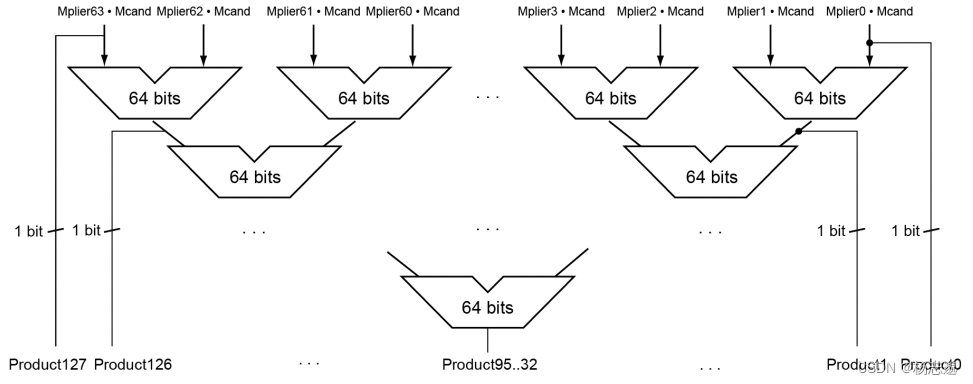
3.4 除法
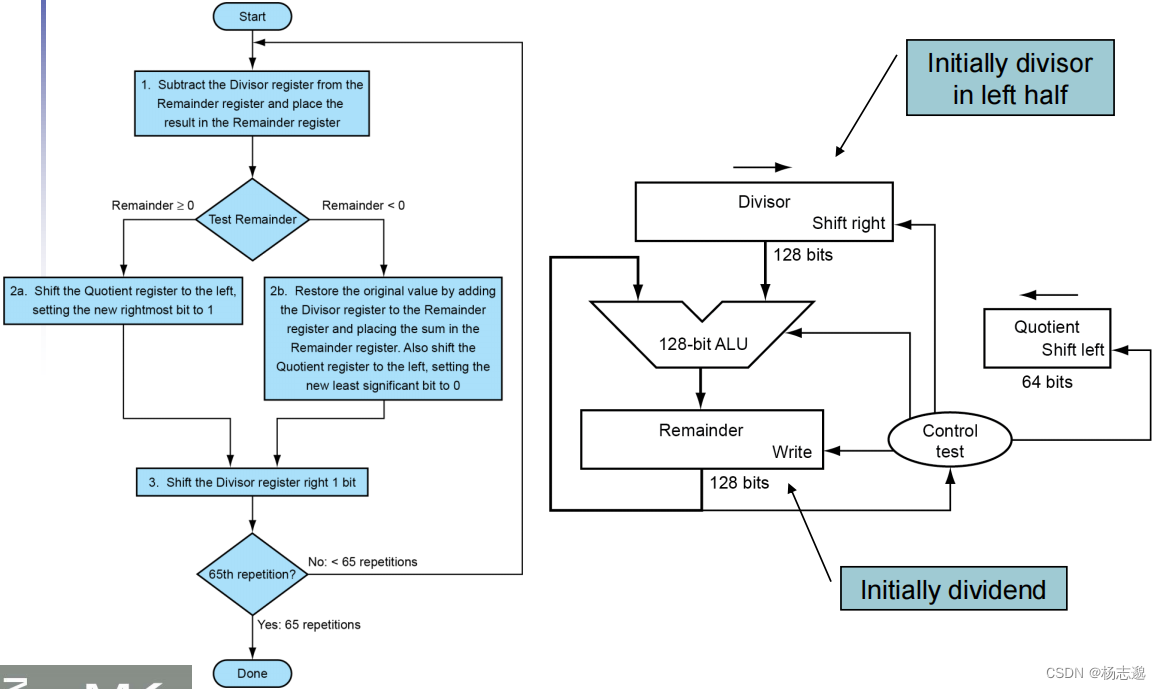
3.5 浮点运算
3.5.1 浮点表示
IEEE 浮点标准用 V = ( − 1 ) s × M × 2 E V=(-1)^s\times M\times 2^E V=(−1)s×M×2E 的形式来表示一个数(s 符号,M 尾数,E 阶码)

有三种对应情况
-
规格化的值
最普遍的情况,当 exp 位既不全为 0,也不全为 1 时。这种情况下:
阶码的值 E = e − B i a s E=e-Bias E=e−Bias 其中 B i a s = 2 k − 1 − 1 Bias = 2^{k-1}-1 Bias=2k−1−1,在单精度中对应为 127,双精度对应为 1023。最终阶码的取值范围为 − 126 ∼ + 127 -126\sim+127 −126∼+127(单精度), − 1022 ∼ + 1023 -1022\sim+1023 −1022∼+1023
尾数值为 M = 1 + f M=1+f M=1+f 其中 f = 0. f n − 1 … f 1 f 0 f=0.f_{n-1}\dots f_1f_0 f=0.fn−1…f1f0 ,尾数的取值范围是 1 ≤ M < 2 1\le M<2 1≤M<2
-
非规格化的值
当阶码域全为 0 时,这种情况下,阶码值是 E = 1 − B i a s E=1-Bias E=1−Bias ,尾数值是 M = f M=f M=f
-
特殊值
当阶码域全为 1 时,当小数域全为 0,表示无穷,当小数域非 0 时,表示 “NaN”
3.5.2 浮点加法
所以,浮点加法需要先将位数对齐高次,相加后在恢复规范化表示。
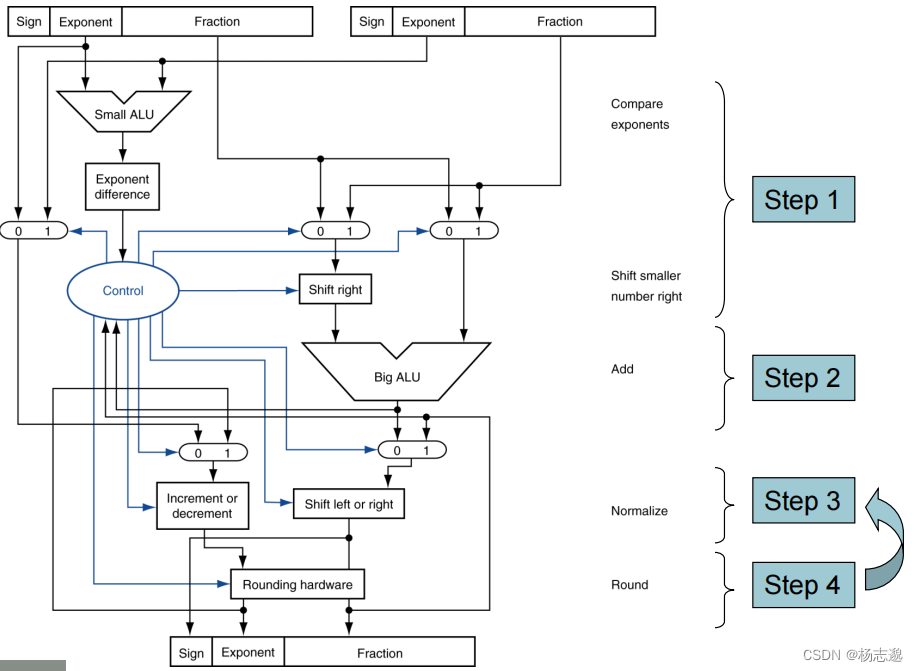
- 第一步 将指数较小的数的小数点和指数较大的小数点对齐
- 第二步 将两个数的有效数位相加
- 第三步 调整结果
- 第四步 舍入
第四章 处理器
4.1 引言
本章介绍,实现单周期处理器和五级流水线处理器
4.1.1 一种基本的 Risc-v 实现
本章的例子将实现 ld sd add sub and or beq 指令
同时,基于最后的设计图来进行解析。
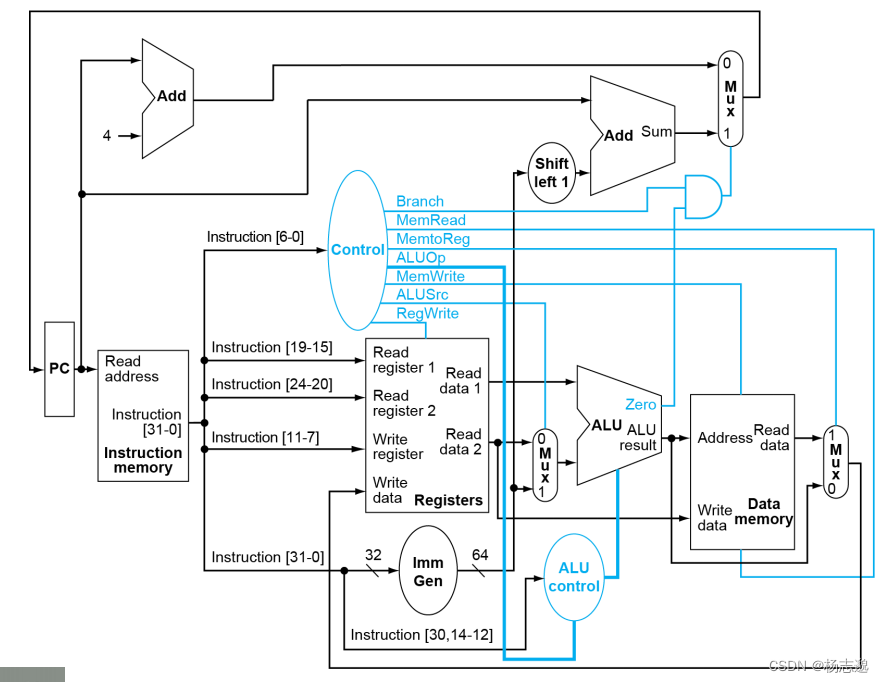
组合逻辑单元:一旦输入改变,输出立即改变,例如 ALU 数据选择器,Control
时序逻辑单元:采用时钟同步方法,如 PC Reg Mem
4.3 建立数据通路
对每一个指令进行拆分,标记使用的组合逻辑单元和时序逻辑单元。
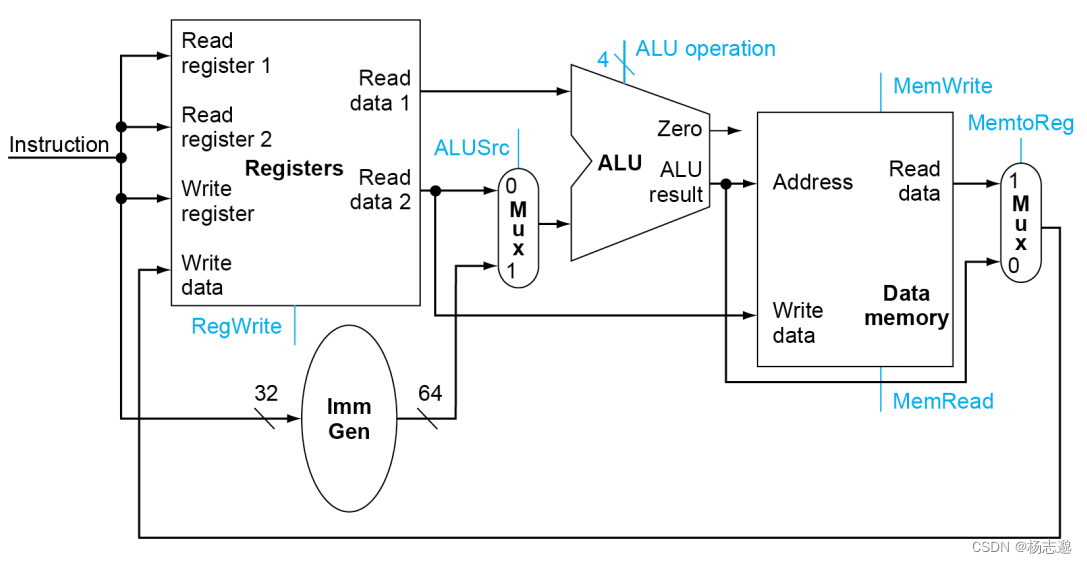
4.4 一个简单的实现方案
本节讨论控制通路
4.5 流水线概述
Risc-v 指令执行:
- 从存储器中取出指令(IF)
- 读寄存器并译码指令(ID)
- 执行操作或计算地址(EX)
- 访问数据存储器中的操作数(如有必要)(MEM)
- 将结果写入寄存器(如有必要)(WB)
例:
有一个单周期处理器,采用上述五个执行阶段,若其五个接待执行分别需要 200,100,200,200,100ps 则总的时钟周期是 800ps
而对于同样配置的五级流水线处理器,则需要 200*5 = 1000ps 来执行单个指令。但是对于多个指令,流水线处理器通过提高指令吞吐率来提高性能,在理想的流水线处理器上,指令执行时间为
指 令 执 行 时 间 流 水 线 = 指 令 执 行 时 间 非 流 水 线 流 水 线 级 数 指令执行时间_{流水线}=\dfrac{指令执行时间_{非流水线}}{流水线级数} 指令执行时间流水线=流水线级数指令执行时间非流水线
4.5.1 面向流水线的指令系统设计
4.5.2 流水线冒险
结构冒险:由于缺乏硬件支持而导致指令不能在预定的时间周期内执行的情况
例如,若分支跳转计算使用主 ALU 来计算,会导致结构冒险。若 指令存储器 和 数据存储器 放在一起,会导致结构冒险
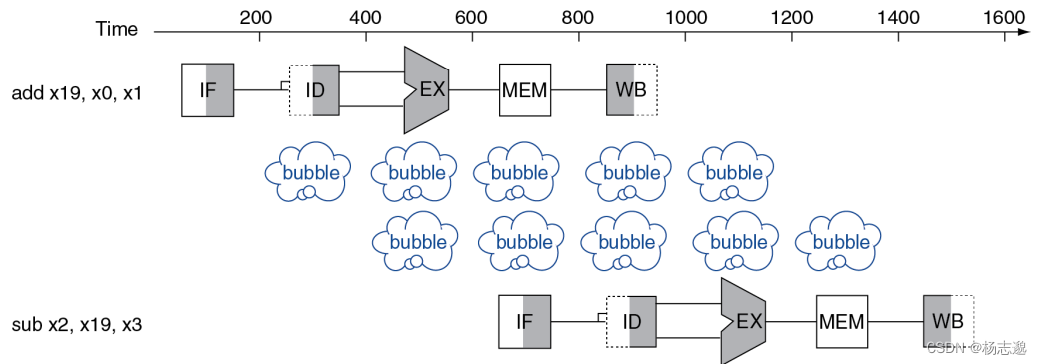
数据冒险:因无法提供指令执行所需数据而导致指令不能在预期的时钟内执行
例如
add x19,x0,x1
sub x2,x19,x3
该指令中 sub 使用了 add 中产生的结果,因而导致 sub 在 ID 阶段无法取到正确的值(此时 add 处于EX 阶段)
使用三种方式来解决数据冒险:
流水线停顿:也称为气泡,通过停顿指令执行来确保 ID 阶段取到正确的值(当 WB 与 ID 在同一个周期执行,总是先写入再读取)
前递或旁路:通过提前从内部缓冲中得到数据,而不是等到写回阶段
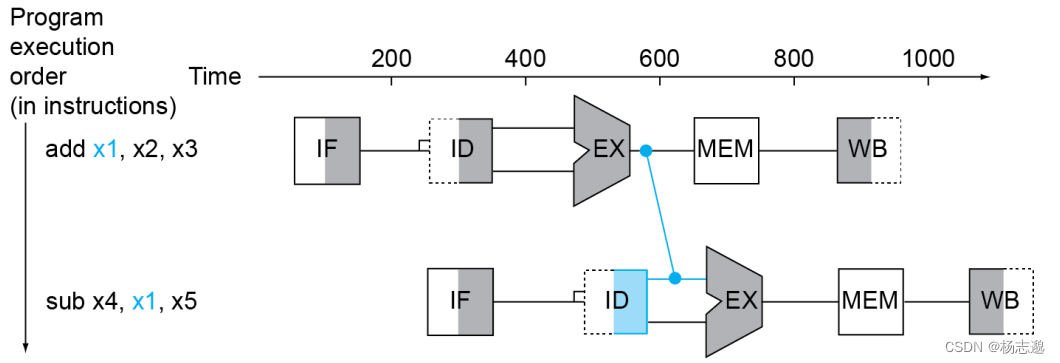
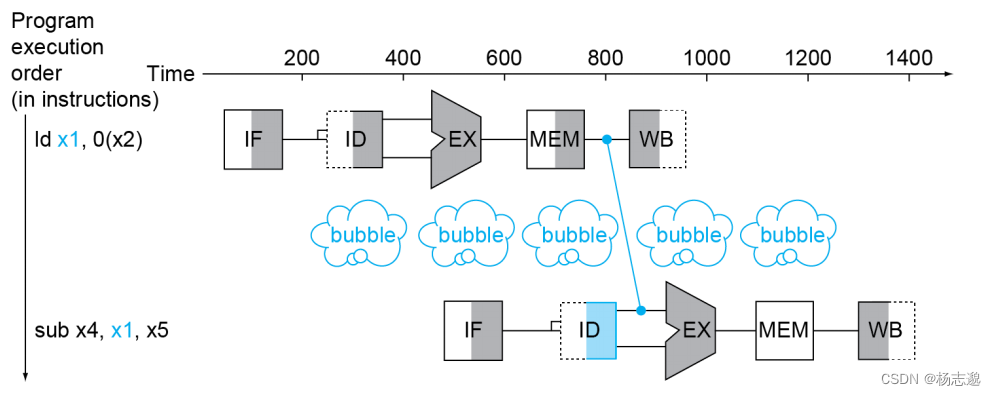
当数据冒险是因为 load 指令产生时,我们需要同时使用前递与流水线停顿措施
编译器预处理:通过重排代码顺序来避免数据冒险
控制冒险:也称为分支冒险,由于取到的指令并不是所需要的,或者地址的流向不是流水线所预期的,导致正确的指令无法在正确的时钟周期内完成。介绍两种解决方案。
阻塞方法:遇到条件分支指令就停顿以避免控制冒险
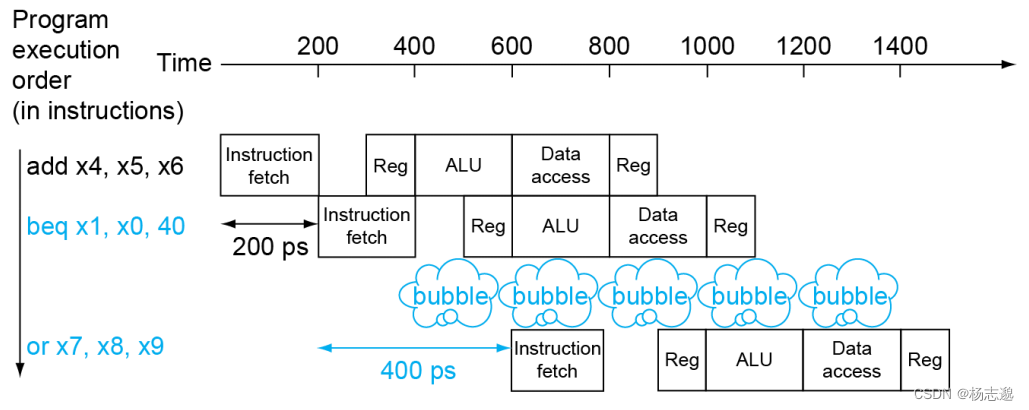
分支预测:预测分支的结果并沿预测方向执行。分为动态预测与静态预测。
4.6 流水线数据通路和控制
和单周期处理器一样,同样直接给出完整通路,在后面补充。流水线处理器比较复杂,部分结构会在后面更详细地给出。
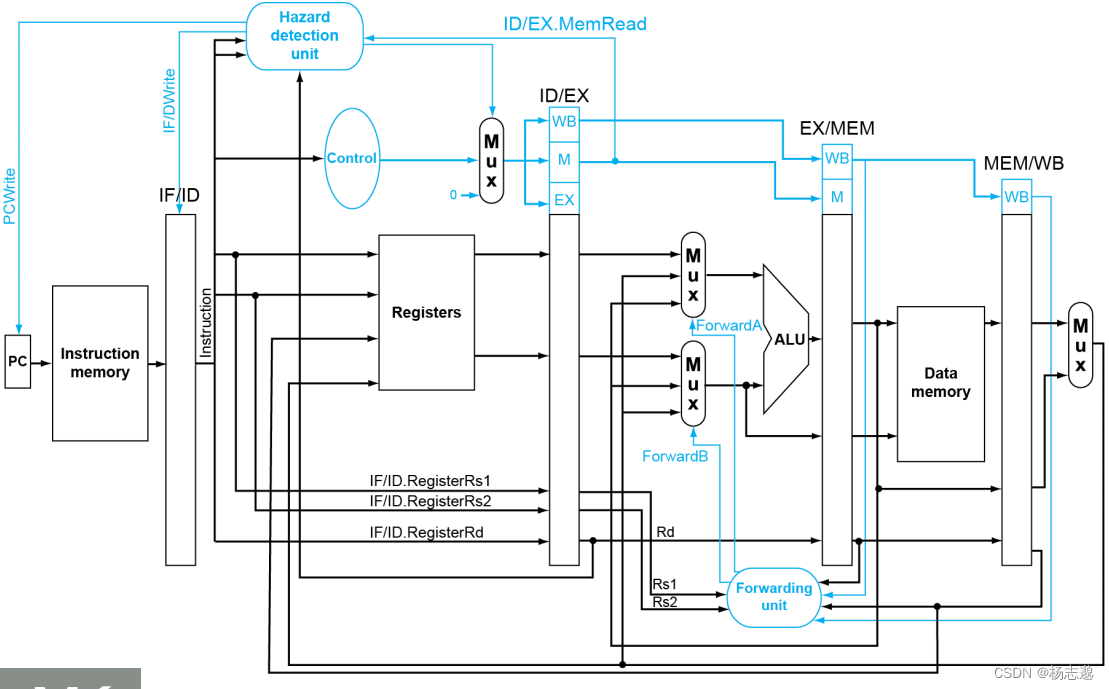
为了保留在指令执行过程中的指令的值,需要把从指令存储器中读取的数据保存在寄存器中,如 IF/ID、ID/EX、EX/MEM、MEM/WB
分析全部五个步骤
- 取指过程:从PC寄存器读出地址,在指令存储器中取出,写入IF/ID,PC+4,为下一指令做准备,同时需要将 PC 写入 IF/ID 以备用
- 指令译码和读寄存器堆:从 IF/ID 中取出数据,读寄存器堆,取出值写入 ID/EX(包含PC) ,译码生成控制信号写入 ID/EX
- 执行或地址计算:从 ID/EX 中读出数据,进行立即数扩展与ALU计算将数据写入 EX/MEM
- 存储器访问:从EX/MEM 中读出数据,按控制信号写入存储器,数据写入 MEM/WB
- 写回:从 MEM/WB 中读出数据,写入寄存器组
上述过程不包含冒险检测与处理,可以用如下数据通路表示
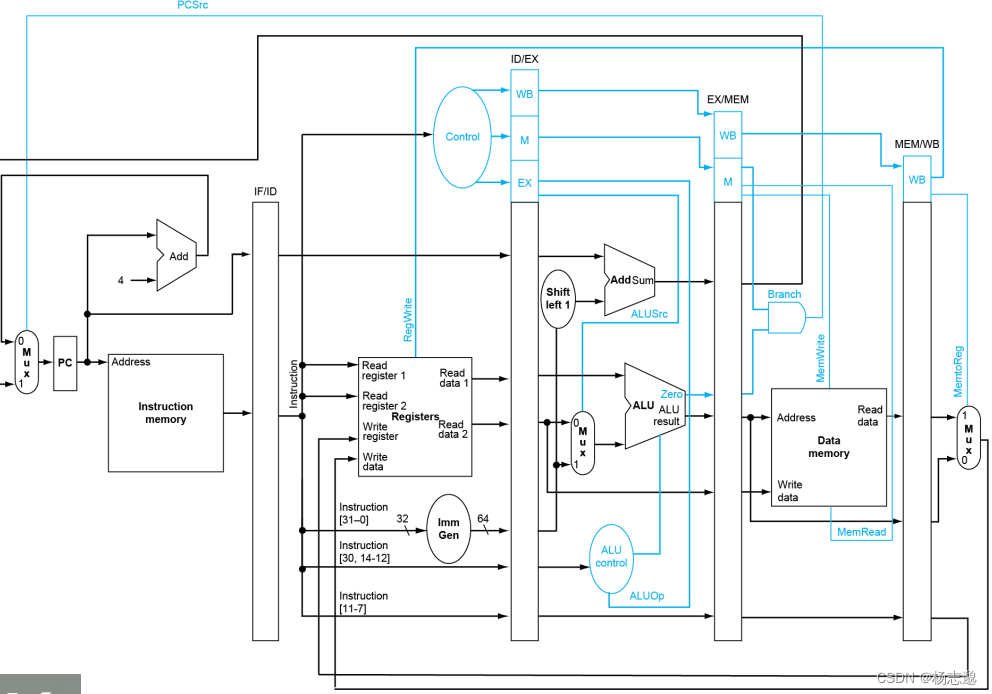
4.6.1 流水线的图形化表示
在分析过程中,我们常使用如下的多周期流水线图来进行图形化表示
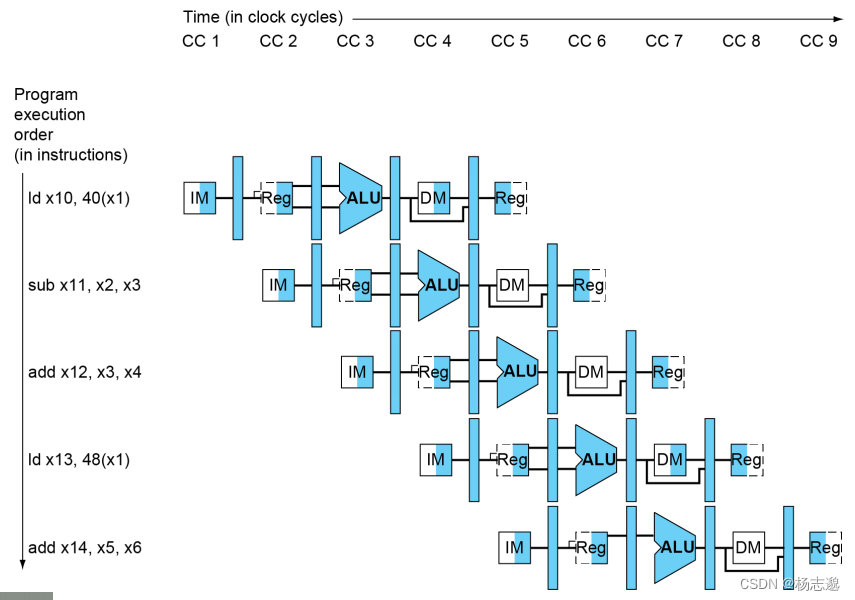
4.6.2 流水线控制
4.7 数据冒险:前递与停顿
对例子
sub x2, x1,x3
and x12,x2,x5
or x13,x6,x2
add x14,x2,x2
sd x15,100(x2)
通过以下多周期流水线图分析
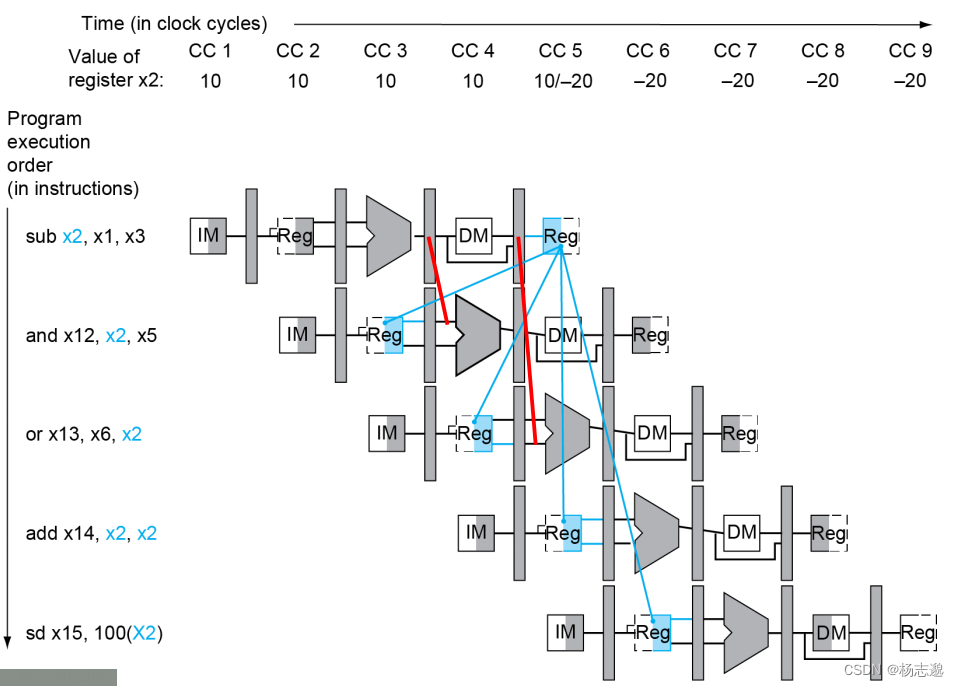
要避免冒险,就要实现如红线所表示的旁路与前递
为此,我们需要设置 Forwarding unit 该控制单元的输入有在 MEM 阶段与 WB 阶段的指令的目的寄存器:EX/MEM.RegisterRd 与 MEM/WB.RegisterRd。在 EX 阶段的寄存器地址 ID/EX.RegisterRs1 与 ID/EX.RegisterRs2。在 MEM 阶段与 WB 阶段的指令的寄存器写使能 EX/MEM.RegWrite 与 MEM/WB.RegWrite。输出有两个 ALU 操作数的选择信号 ForwardA 与 ForwardB 并基于以下原则进行设置
**EX 冒险 ** 这种情况下,ALU操作数来自上一个 EX 阶段的结果,即当前的 MEM 阶段
#define
fromMEM 10;if (EX/MEM.RegWrite && (EX/MEM.RegisterRd != 0) && (EX/MEM.RegisterRd == ID/EX.RegisterRs1) ForwardA = fromMEM;
if (EX/MEM.RegWrite && (EX/MEM.RegisterRd != 0) && (EX/MEM.RegisterRd == ID/EX.RegisterRs2) ForwardB = fromMEM;
MEM 冒险 这种情况下,ALU操作数来自 MEM 或者上上个 EX 阶段的结果,即当前的 WB 阶段
#define
fromWB 01;if (MEM/WB.RegWrite && (MEM/WB.RegisterRd != 0) &&!(EX/MEM.RegWrite && (EX/MEM.RegisterRd != 0) && (EX/MEM.RegisterRd == ID/EX.RegisterRs1))&& (MEM/WB.RegisterRd == ID/EX.RegisterRs1) ForwardA = fromWB;
if (MEM/WB.RegWrite && (MEM/WB.RegisterRd != 0) &&!(EX/MEM.RegWrite && (EX/MEM.RegisterRd != 0) && (EX/MEM.RegisterRd == ID/EX.RegisterRs2))&& (MEM/WB.RegisterRd == ID/EX.RegisterRs2) ForwardB = fromWB;
注意 MEM 冒险 要先满足不符合 EX 冒险
因 load 引起的数据冒险的停顿
对下面的例子,上述的解决冒险的方法不再适用。为此,我们需要在 and 处进行停顿一个周期。
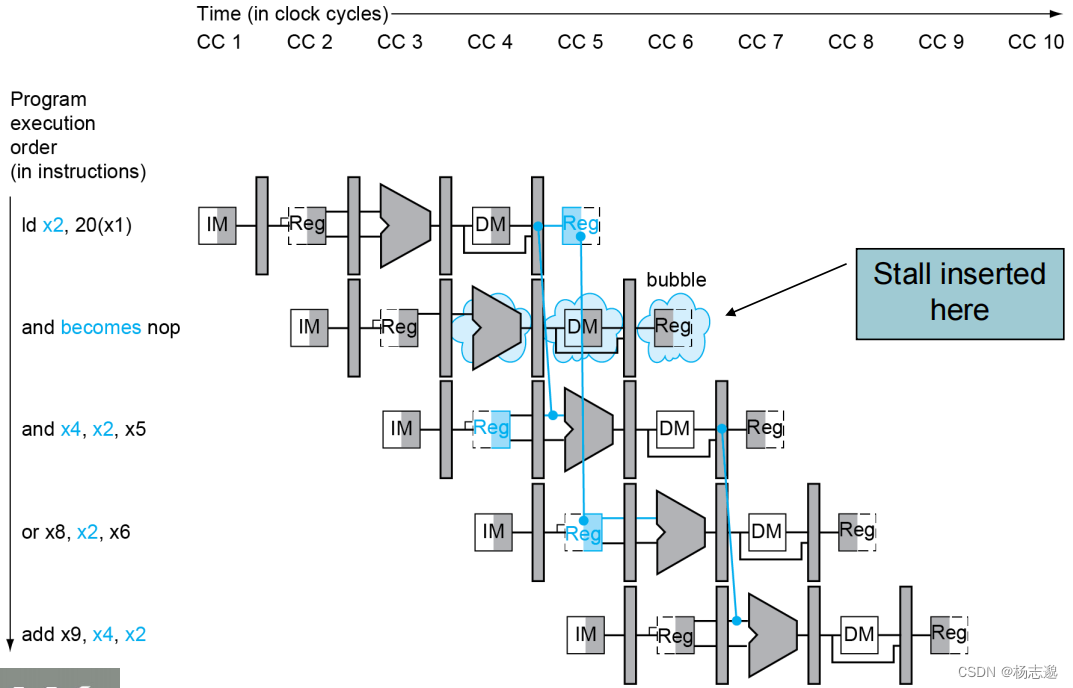
为满足停顿,我们需要设计 Hazard detection unit 该控制单元的输入有 当前 EX 阶段的内存读使能 ID/EX.MemRead 。当前 EX 阶段的目的寄存器 ID/EX.RegisterRd 。当前 ID 阶段的 寄存器地址 IF/ID.RegisterRs1 与 IF/ID.RegisterRs2 输出有 PC 寄存器写使能 PCWrite,IF/ID 寄存器写使能 IF/IDWrite 控制信号写使能 ControlMux
if (ID/EX.MemRead &&((ID/EX.RegisterRd==IF/ID.RegisterRs1)||(ID/EX.RegisterRd==IF/ID.RegisterRs2)))stall the pipeline
上面,通过禁止 PC 改变,IF/ID 改变,将当前 ID 阶段的控制信号置零,就可以使流水线停顿一个周期。
对于上述例子进行分析:
- 在第三个周期的时候,ld 进行到 EX 阶段(ld的目的寄存器信号储存在 ID/EX 中),同时 add 在 ID 阶段,此时满足 ld 的目的寄存器与 add 的操作数寄存器冲突,冒险控制单元发出控制信号,停止 PC+4(此时 PC 应当在 or 指令的位置,or指令执行到 IF 阶段),将当前的add 指令的控制信号置零,不让 IF/ID 写入(此时 IF/ID 中即将写入 or 的数据而未写入,仍然保存 add 的数据)
- 继续加载流水线到第四周期。由于add 的控制信号置零,本该出现在 EX 阶段的 add 指令无效,变为 nop。ID 阶段读 IF/ID 得到 add 的数据, add 进行 ID 阶段。PC现在可写,读 PC 得到 or 的地址,or 进行 IF 阶段
- 继续加载流水线到第五周期。此时 add 到 EX 阶段,通过 MEM 前递,add 得到 ld 阶段从内存读到的值并进行计算。
4.8 控制冒险
分支代价:
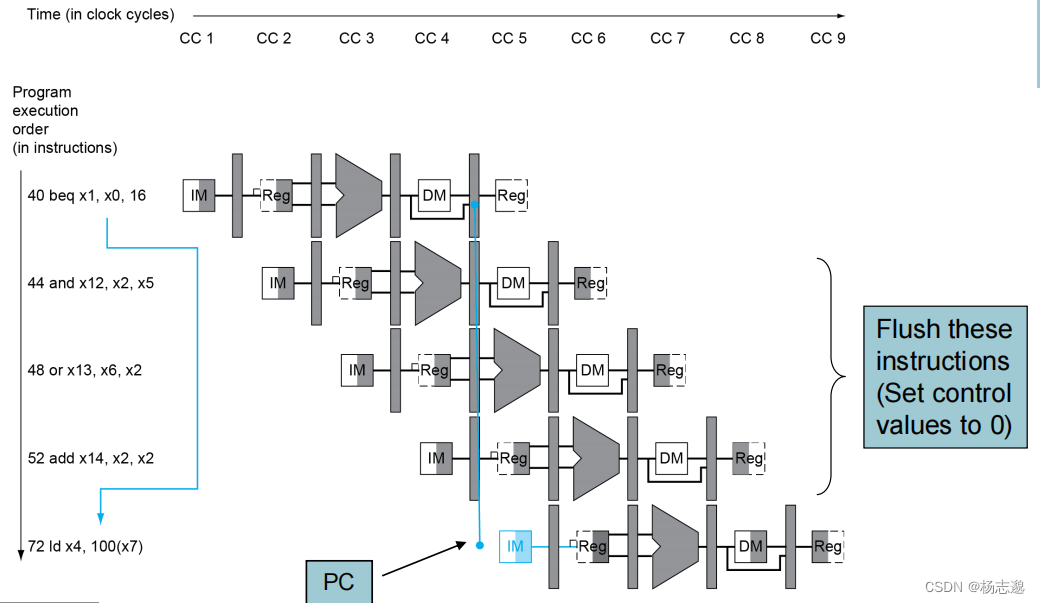
通过设置控制信号为 0 来将分支失败的指令无效化(设置 ID/EX,EX/MEM 寄存器中的控制信号以及 IF/ID 的写使能)
4.8.1 假设分支不发生
4.8.2 缩短分支延迟
在 ID 阶段就进行分支检测,此时只需要对 IF/ID 进行处理即可
4.8.3 动态分支预测
一个 2 位预测机制的状态转换器
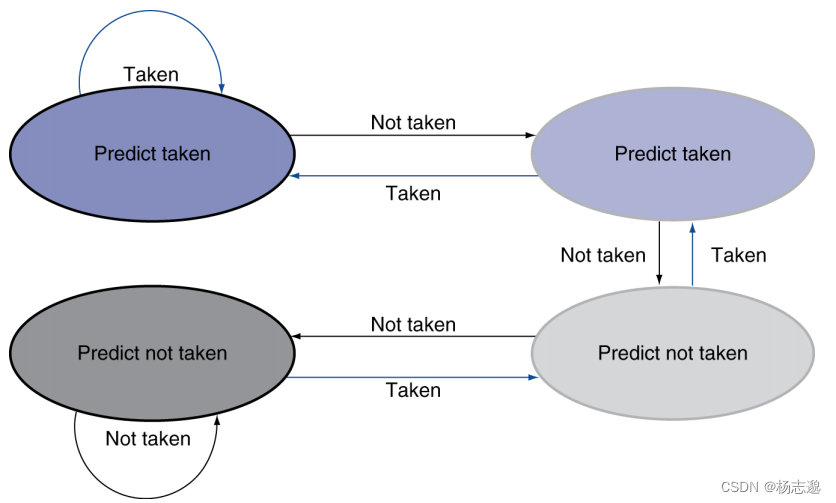
例如,我们设 11,10 表示发生跳转,01,00 表示不发生跳转。当在一个循环中,初始值为 00 不发生跳转而跳转了,将值 +1 = 01,之后又不发生跳转而跳转了,+1 = 10,发生跳转而跳转, +1 = 11,之后的每一次都跳转,而最后一次预测失败,末尾值为 10。总共出现3次预测失败。
4.9 例外
Risc-v 中的例外
系统重启,I/O 设备请求,用户程序进行操作系统调用,未定义指令,硬件故障
4.9.1 Risc-v 中如何处理例外
增加两个额外的处理器
- SEPC:64 为寄存器,用来保存引起例外的地址
- SCAUSE:用来记录例外原因的寄存器
4.9.2 流水线实现中的例外
一般的例外处理程序地址为 1c090000
出现例外时,停止所有后续指令的执行,进入例外处理程序
4.10 指令间的并行性
指令级并行(ILP)
- 通过将提高流水线的级数来提高吞吐量,让更多指令重叠进行
- 使用多发射技术:一个时钟周期内可以发射多条指令
- 静态多发射:由编译器进行预处理,完成发射相关判断
- 动态多发射:在动态执行过程中由硬件完成发射相关判断
需要解决的问题:
- 将指令打包并放入发射槽,判断本周期发射多少指令?发射哪些指令?
- 处理数据和控制冒险。
4.10.1 推测的概念
4.10.2 静态多发射
4.10.3 动态多发射处理器
第五章 大而快:层次化存储
5.1 引言
在本章中,我们将基于下图介绍存储层次结构。观察如何基于局部性原理(空间局部性、时间局部性)来设计更加高效的存储结构
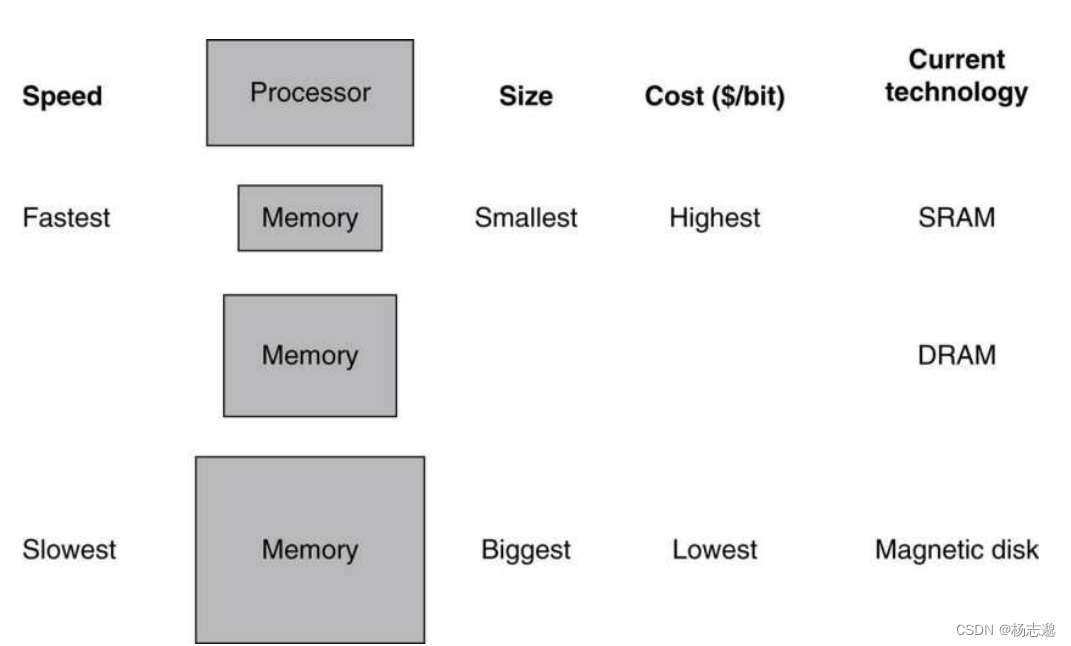
上图中,我们将存储器由上至下称为 高速缓冲存储器(cache) 主存(memory) 磁盘(disk)
我们称处理器所需数据在本层找到为命中反之称为缺失
提高命中率,降低缺失率时设计存储器的一大目的
5.2 存储技术
5.2.1 SRAM 存储技术
SRAM(静态随机存储器) 存储是一种存储阵列结构的简单集成电路。使用单个 Moss 管的导通与截止来表示数据,一旦断电,数据就会丢失
5.2.2 DRAM 存储技术
DRAM(动态随机存储器) 使用电容保存电荷的方式存储数据,每个单元仅有一个晶体管,密度更高。但也不能长期保存数据。
SDRAM(同步DRAM) 进行突发传输时无需指定额外地址位。
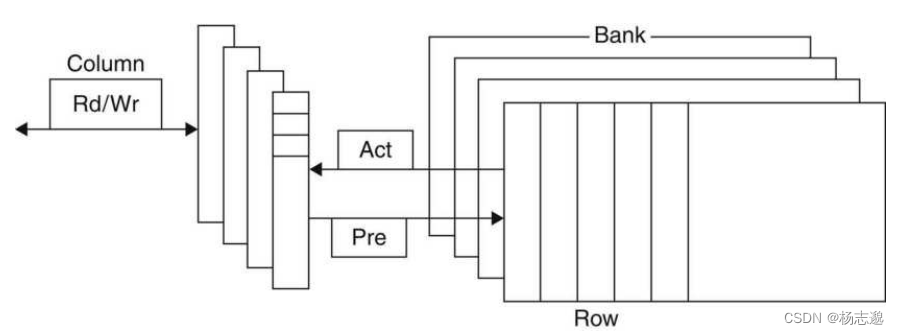
现代 DRAM 使用 bank 的方式来组织结构。根据地址的最低位来决定读 1 个、2 个、4 个存储单元
5.2.3 闪存
闪存是一种电可擦除的可编程只读存储器。
大多数闪存产品都包括一个控制器,用来将发生多次写的块重新映射到较少背写的块,从而使得写操作尽量分散。该技术被称为耗损均衡
5.2.4 磁盘
每个磁盘表面被分为若干的同心圆,称为磁道。每个盘面通常有数万条磁道。每条磁道依次被划分为上千个保存信息的扇区
对磁盘的访问:
- 将磁头定位在正确的磁道上方。称为寻道
- 等待所需扇区旋转到读写磁头下。这段时间被称为旋转延时
- 传输数据块。时间称为传输时间
上述参数中,寻道时间和传输时间通常由磁盘与数据决定。平均旋转延时通常假设为旋转半圈的时间。
5.3 cache 基础
memory 的 地址表示
从高位到低位分别为 块地址 以及 块内地址(块内地址位数取决于块的大小)
直接映射 cache
使用如下方式来将主存放入块中。
( 块 地 址 ) m o d ( c a c h e 中 数 据 块 数 量 ) (块地址)\mathrm{mod}(\mathrm{cache} 中数据块数量) (块地址)mod(cache中数据块数量)
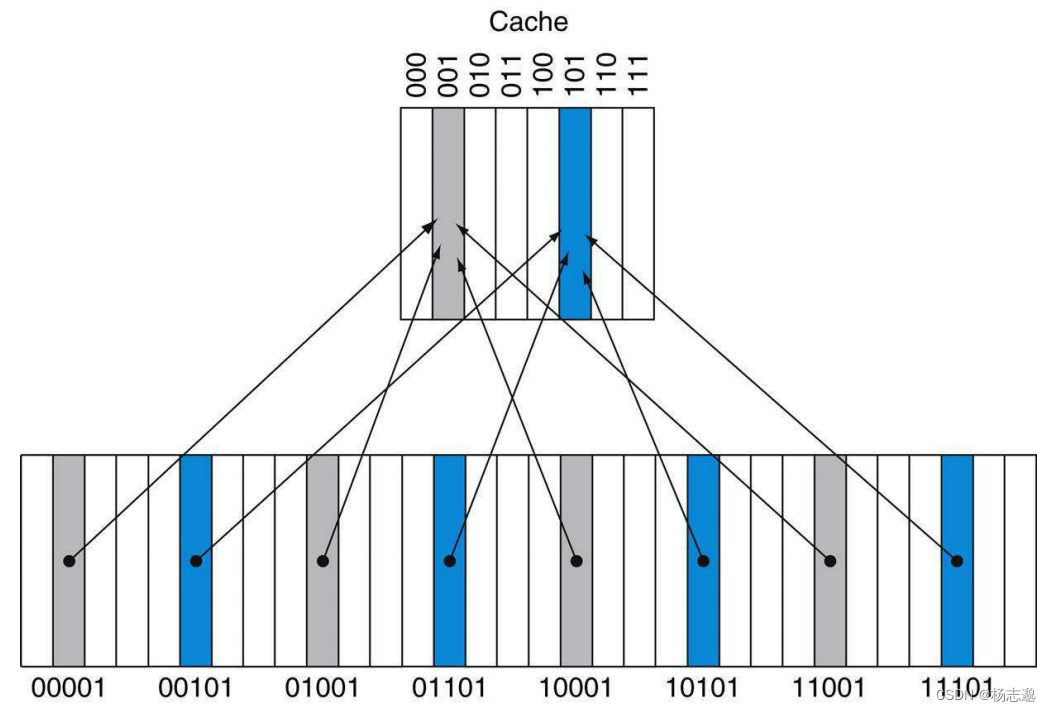
在索引过程中,通常需要在 cache 中添加一组标签(标签位数为内存块地址位数-cache 块地址位数,如上图中的内存高两位)
另外,为了保证块内数据有效,需要添加有效位
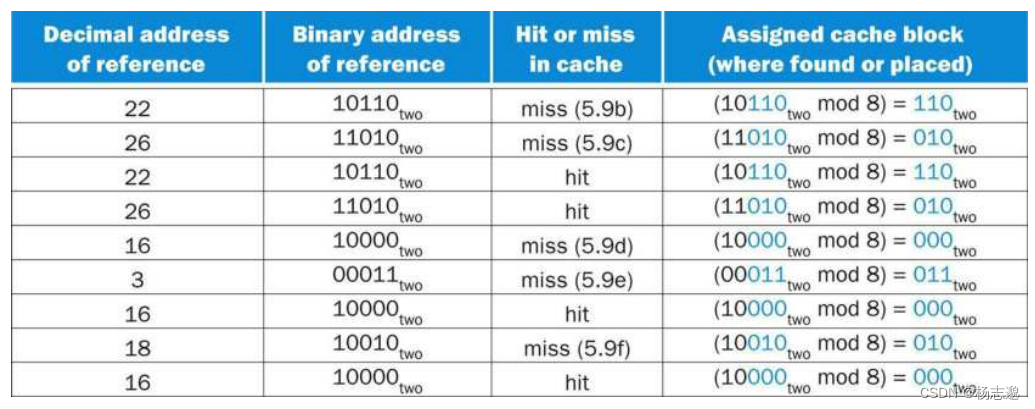
5.3.1 cache 访问
如图的例子
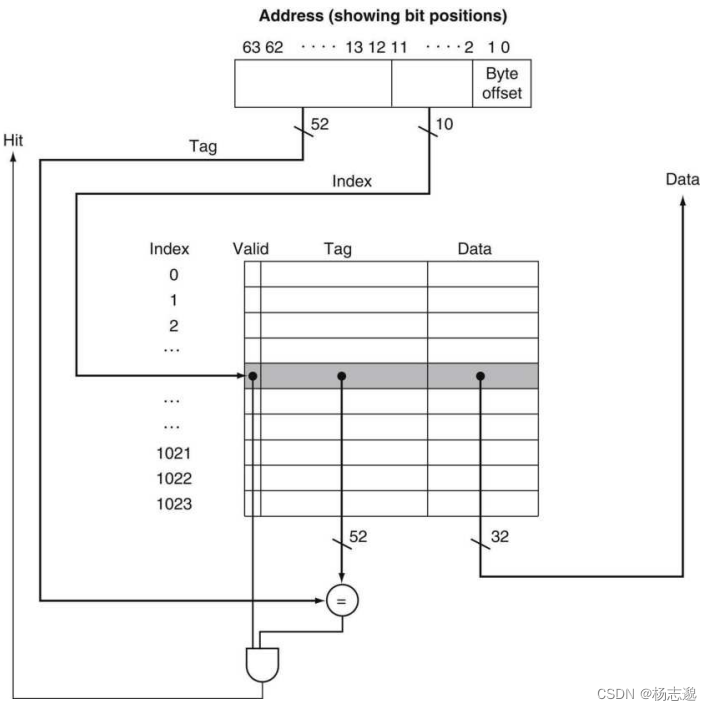
计算 cache 总容量
2 n × ( 单 个 数 据 块 容 量 + 标 签 字 段 大 小 + 有 效 位 大 小 ) 2^n\times(单个数据块容量+标签字段大小+有效位大小) 2n×(单个数据块容量+标签字段大小+有效位大小)
5.3.2 处理 cache 缺失
一旦指令 cache 缺失,按以下方式处理
- 将 PC 的原始值(当前 PC - 4)发送当内存(停顿)
- 对主存进行读操作,等待主存完成本次操作
- 写 cache 表项,将从内存获得的数据写入数据部分,地址高位写入标签字段,置有效位为 1
5.3.3 处理写操作
写直达(write-throug):同时更新 cache 和下一级存储,保持两者的数据一致。可通过写缓冲来减少停顿时间。
写返回(write-back):当发生写操作时,新值只被写入 cache 中;当被改写的块在替换出 cache 时才被写到下一级存储。
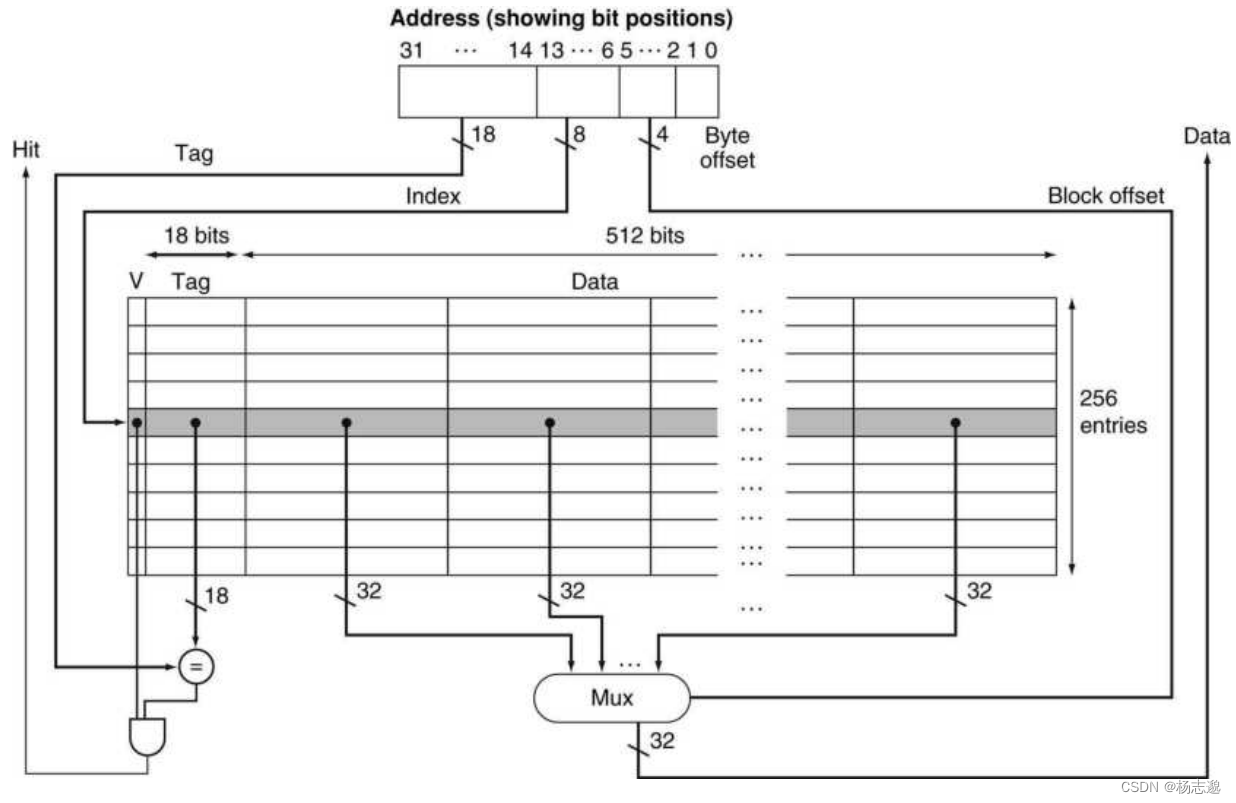
5.3.4 cache 实例:Intrinsity FastMATH 处理器
5.4 cache 的性能评估和改进
读 操 作 带 来 的 停 顿 周 期 数 = 读 操 作 数 目 程 序 × 读 缺 失 率 × 读 缺 失 代 价 写 操 作 带 来 的 停 顿 周 期 数 写 操 作 数 目 程 序 × 写 缺 失 率 × 写 缺 失 代 价 + 写 缓 冲 满 时 的 停 顿 周 期 读操作带来的停顿周期数=\dfrac{读操作数目}{程序}\times 读缺失率\times 读缺失代价 \\写操作带来的停顿周期数\dfrac{写操作数目}{程序}\times 写缺失率\times 写缺失代价+写缓冲满时的停顿周期 读操作带来的停顿周期数=程序读操作数目×读缺失率×读缺失代价写操作带来的停顿周期数程序写操作数目×写缺失率×写缺失代价+写缓冲满时的停顿周期
例如:一个指令 cache 缺失率为 2%,数据 cache 缺失率为 4%,理想 CPI 为 2,缺失代价为 100 个周期。设 load 与 store 占 36%
则考虑缺失代价的 C P I = I × 2 % × 100 + I × 36 % × 4 % × 100 I = 5.44 \mathrm{CPI}=\dfrac{I\times2\%\times100+I\times36\%\times4\%\times100}{I}=5.44 CPI=II×2%×100+I×36%×4%×100=5.44
平均访存时间(AMAT) A M A T = 命 中 时 间 + 缺 失 率 × 缺 失 代 价 \mathrm{AMAT}=命中时间+缺失率\times缺失代价 AMAT=命中时间+缺失率×缺失代价
5.4.1 使用更灵活的替换策略降低 cache 失效率
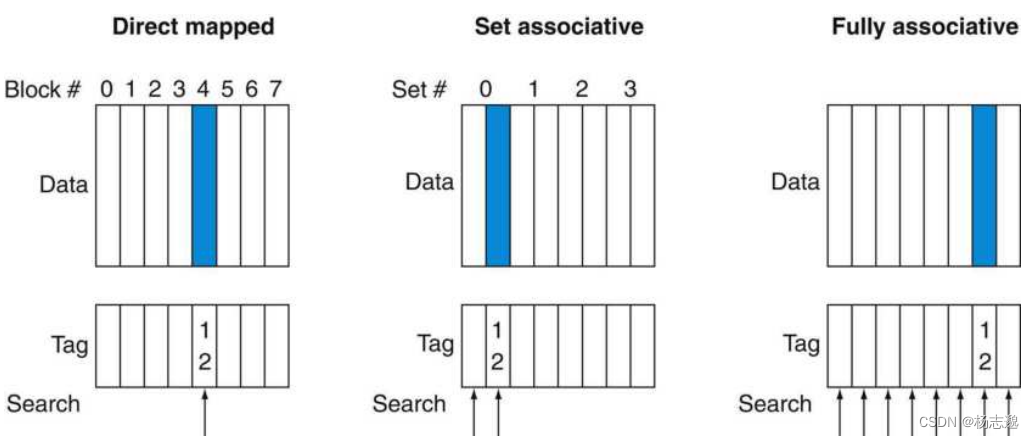
全相联(Fully associative):主存中的某个数据块和 cache 中的任意表项都可以有关联。基于此,cache 中的标签位数 = 主存地址位数 - 块大小位数。并且这样的 cache 需要与块数相同的比较器。
组相联(Set associative):每个数据块可以存放的位置数量是固定的。每个数据块有 n 个位置可放的组相联 cache 称为 n 路组相联 cache。基于此,cache 中的标签位数 = 主存地址位数 - 块大小位数 - 组的索引位数。并且需要 n 个比较器。
组号为 ( 数 据 块 号 ) m o d ( c a c h e 中 的 组 数 ) (数据块号)\mathrm{mod}(\mathrm{cache}中的组数) (数据块号)mod(cache中的组数)
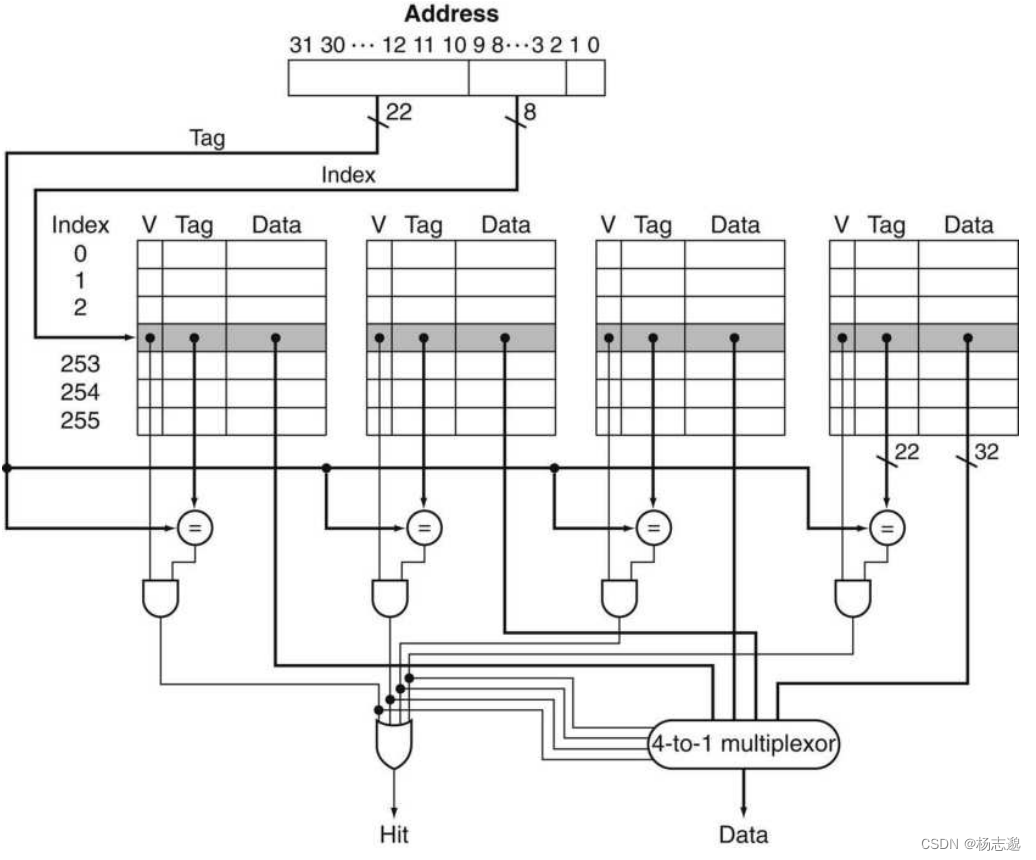
5.4.2 在 cache 中查找数据块
下面是一个 4 路组相联的 cache,含有 2 8 2^8 28 个组
5.4.3 旋转替换的数据块
最近最少使用(LRU):最长时间未被使用的数据块将被替换
随机替换:旋转随机的数据块替换
5.4.4 使用多级 cache 减少失效代价
5.4.5 通过分块进行软件优化
5.5 可靠的存储器层次
5.5.1 缺失的定义
5.5.2 纠正 1 位错、检测两位错的汉明编码
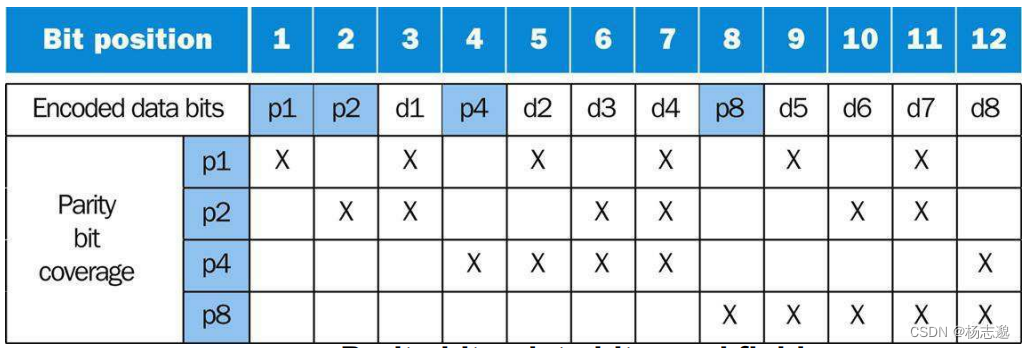
步骤:
- 从左到右由 1 开始编号。
- 将编号为 2 的整数幂的位标记为奇偶校验位 (1,2,4,……)
- 剩余其他位用于数据位
- 奇偶校验规则:编号为00……1……00,第 i 位为 1 的检查对应第 i 位为 1 的对应位
例:对于 8 位数据 10011010 的汉明编码为 011100101010
5.6 虚拟机
5.7 虚拟存储
虚拟存储:一种将主存看做辅助存储的 cache 技术
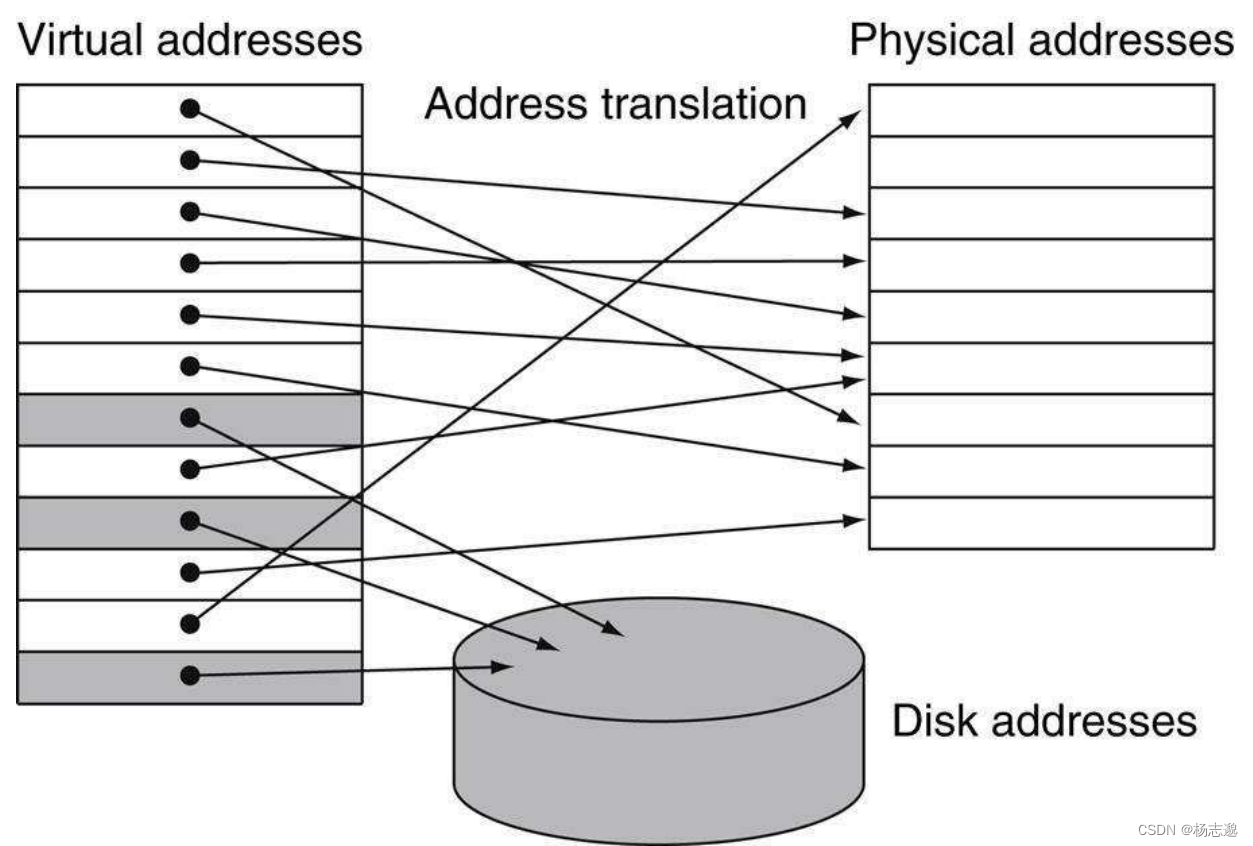
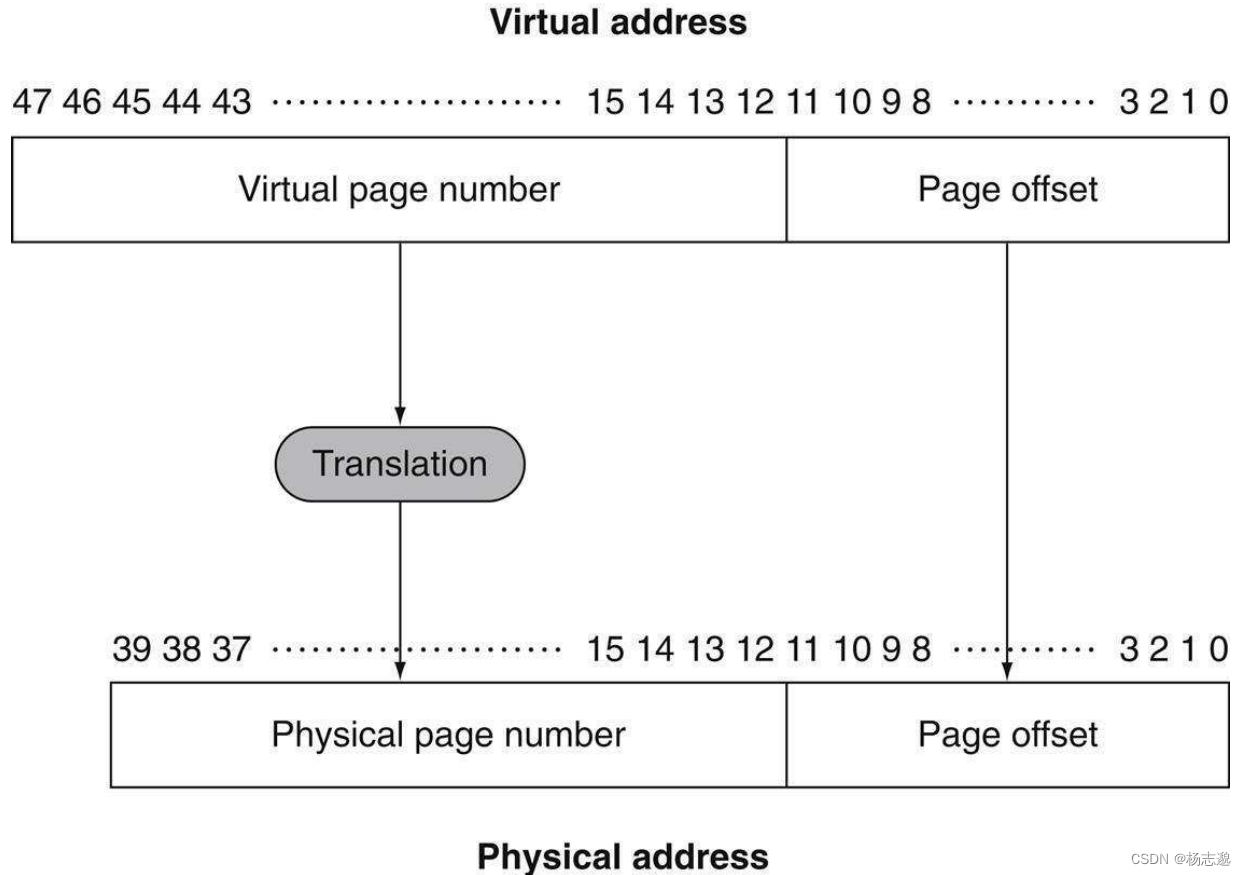
虚拟存储块定义为页,为了访存,处理器需要将虚拟页号(Virtual page number,VPN) 转换为物理页号(Physical page number,PPN)
此处页大小为 2 12 = 4 K i B 2^{12}=4\mathrm{KiB} 212=4KiB
5.7.1 页的存放和查找
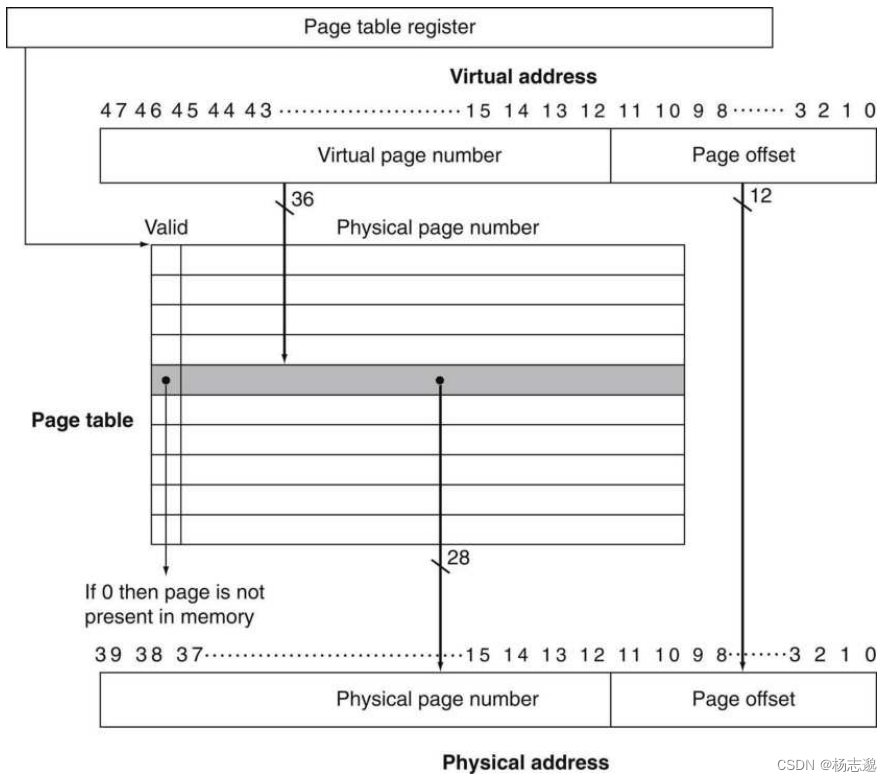
页表寄存器:指向当前进程的页表首地址。
5.7.2 缺页失效
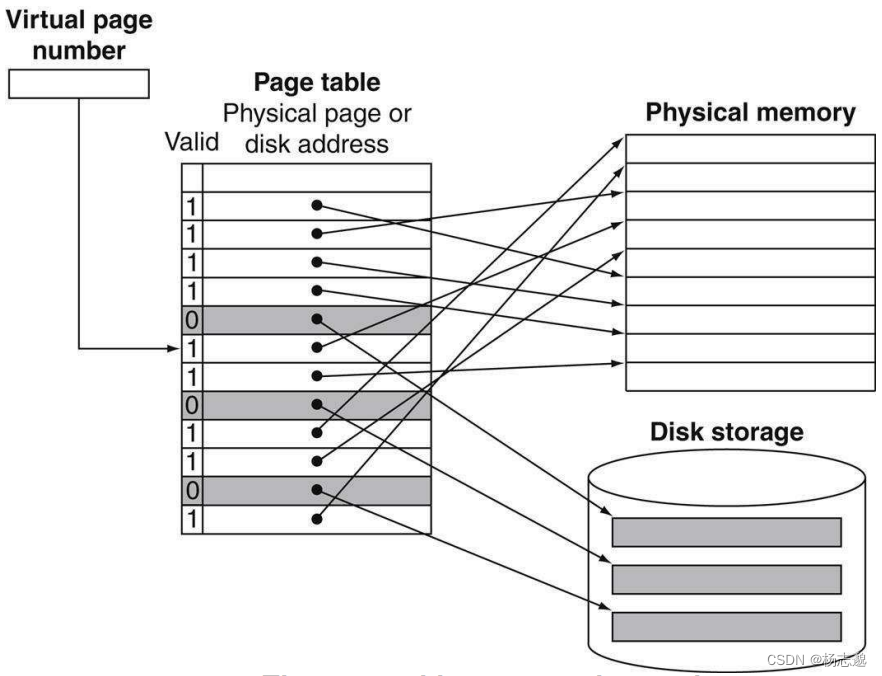
该过程非常类似于 cache 缺失
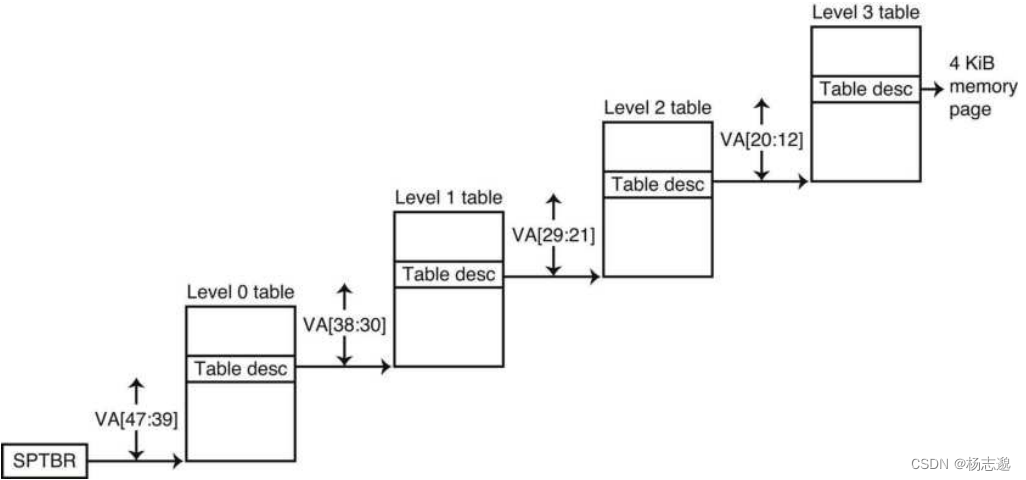
5.7.3 支持大虚拟地址空间的虚拟存储
- 反向页表:对虚拟地址使用哈希函数,使页表容量等于主存中物理页的数量
- 多级页表:采用层层查找的方式存储页表(下面是一个 4 级页表)
5.6.4 关于写
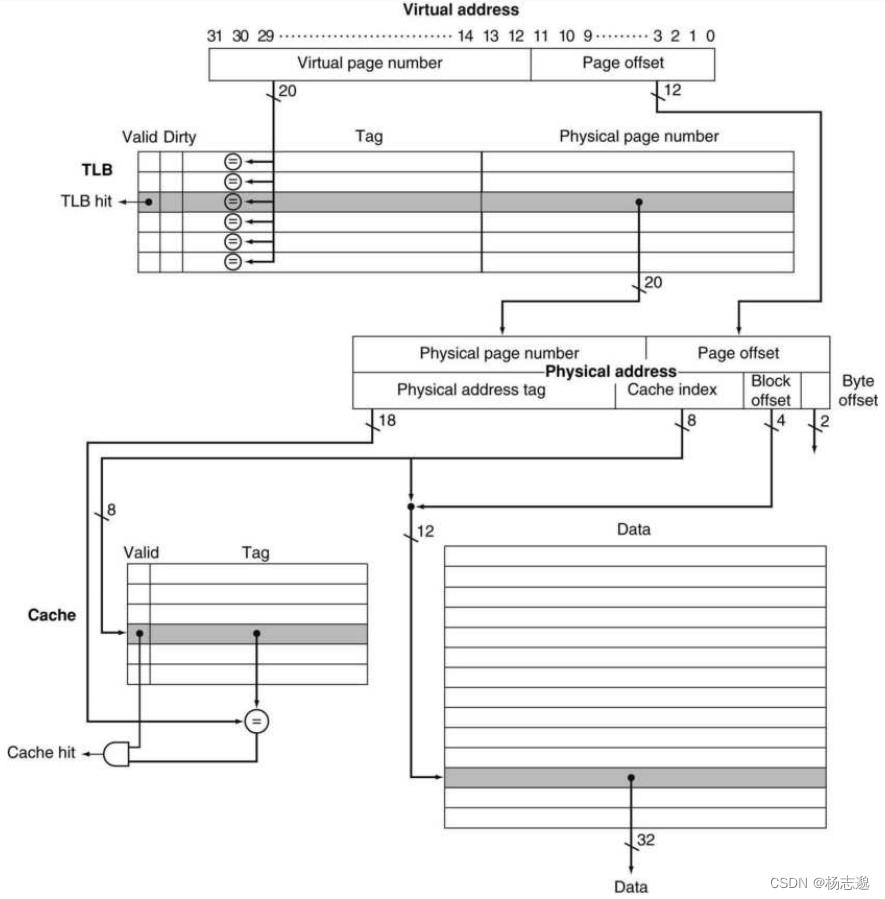
5.4.5 加快地址转换:TLB
快表(TLB):用于记录最近使用的地址映射信息的 cache
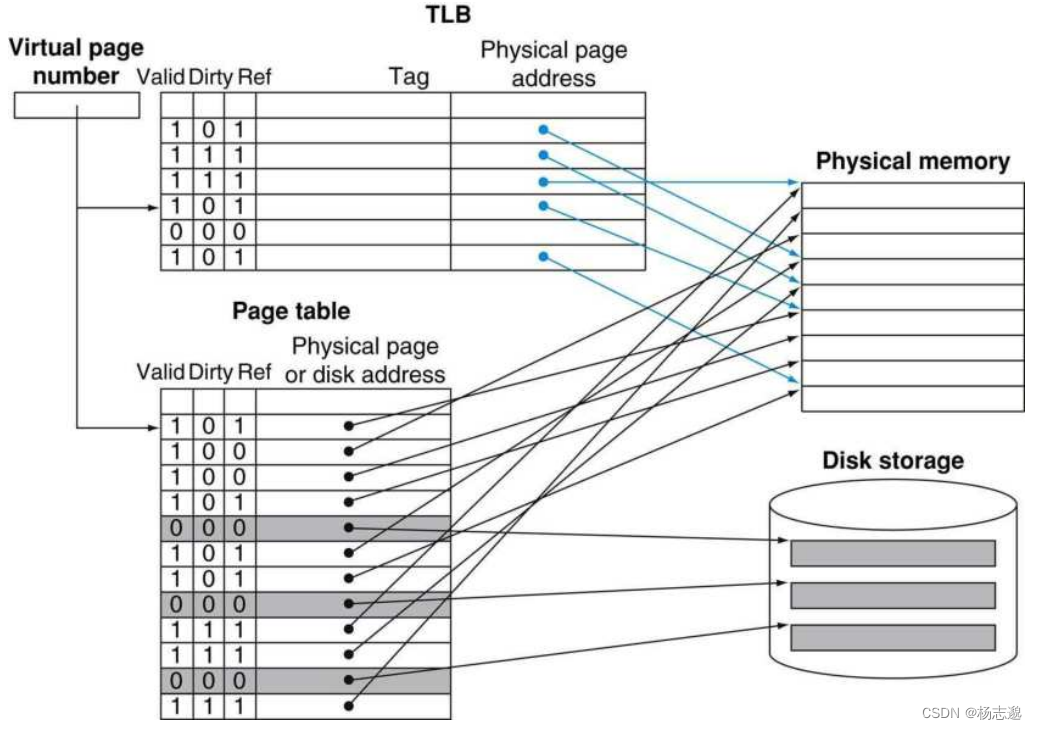
在含有 TLB 的存储系统中,典型的读写过程可以如下描述:
读过程
- 通过程序得到虚拟地址
- 查 TLB 得到物理地址(在此步中,若 TLB 缺失则需要到主存中访问页表,找到页表后更改 TLB 表项( LRU 或随机替换))
- 若缺页,则需要到磁盘找到页,转移至主存,修改页表,修改TLB
- 基于物理地址访存 (在此步中,若 cache 缺失则需要到主存中访问数据,找到数据后更改 cache 块)
写过程
- 通过程序得到虚拟地址
- 查 TLB 得到物理地址(在此步中,若 TLB 缺失则需要到主存中访问页表,找到页表后更改 TLB 表项( LRU 或随机替换))
- 若缺页,则需要到磁盘找到页,转移至主存,修改页表,修改TLB
- 基于物理地址访存 (在此步中,若 cache 缺失则需要到主存中访问数据,找到数据后更改 cache 块)
- 写 cache (写返回或写直达)