ICLR2021 Oral《Free Lunch for Few-Shot Learning: Distribution Calibration》
利用一个样本估计类别数据分布 9行代码提高少样本学习泛化能力
原论文:https://openreview.net/forum?id=JWOiYxMG92s
源码:https://github.com/ShuoYang-1998/ICLR2021-Oral_Distribution_Calibration
知乎:https://zhuanlan.zhihu.com/p/344531704
什么是少样本学习(few-shot)
假设你有如下目的:你想用VGG网络训练一个通用的花分类器。你手上只有10种常见花分类的数据集,每个类有成千上万充足的样本,但是,除此10类花以外,其他类别的花,每一类你只有个位数的样本,如果直接将这些数据给VGG去分类,结果几乎将是过拟合那10种样本充足的类。那如何解决这个问题呢?这就是few-shot问题,即少样本学习。
本篇论文怎么做的?
- 训练特征提取器(或分类器):先使用“base数据”集训练一个分类器,比如训练一个VGG分类模型。(base数据指样本量很充足的数据,比如你手上充足的10种常见花的数据集)
- 计算base数据每一个类别所有样本的总均值和总协方差:分类器训练好后,将上述所有base数据输入分类网络,计算base数据中每一类的所有样本在网络特征输出层(注意不是全连接层的输出,而是尾端卷积层的输出特征图,后续把特征图拉成了一维向量。)的总均值和总协方差。
- 校正novel数据的特征分布:将“novel数据”每一类的1张或5张样本(“novel数据”就是你那些样本极少的类,注意“novel数据”中类别和base数据中没有重复的类,“novel数据”中可能有N个类,但评价few-shot算法性泛化能力时,一般是5个类,每一个类仅可用1张或5张去充当训练集,5个类每类1张训练的叫 5-way-1-shot,5个类每类5张的叫 5-way-5-shot),输入上述分类器获得样本的特征输出,然后使用第2步中获得的“base数据”的均值和协方差,校正“novel数据”中每一类的特征分布。
- 训练一个线性分类器:使用“novel数据”(训练集)每一类的特征数据(注意:“novel数据”每一个类就1个或5个样本),以及从“novel数据”校正后的特征分布中随机抽样生成(具体生成多少是一个超参数)的新特征数据,两者一起去训练一个线性分类器(LR)。
- 特征提取器+线性分类器,实现少样本的分类:先推理阶段,先将????????????
本论文的前提是什么?
论文的本质是根据base数据的特征分布去校正novel数据的特征分布,所以,如果base数据和novel数据类间距离越小,效果一般会越好,因为理论上它们经过特征提取器后的特征分布更相似。反之,如果类间距越大,效果越不好。当然,这种类间距很大的问题,本篇文章之外的其他few-shot方法同样感到更棘手。
摘要
从有限数量的样本中学习是具有挑战性的,因为只有少数训练样本形成的偏倚分布,模型很容易过拟合。在本文中,我们对这些样本较少的类的分布进行了校正,通过转移具有足够样本的类的统计信息,然后从校正后的分布中抽取足够数量的样本来扩展分类器的输入。我们假设特征表示中的每个维都服从高斯分布(即正态分布),这样分布的均值和方差可以借用类似类的统计数据,这些统计数据可以用足够的样本数来更好地估计。我们的方法可以建立在现成的预训练特征提取器和分类模型之上,不需要额外的参数。我们展示了一个简单的逻辑回归分类器,使用从我们的校准分布中采样的特征训练,可以在两个数据集上优于最先进的精度(在miniImageNet上比次之的提高了5%)。这些生成的特征的可视化表明,我们的校准分布是一个准确的估计。
1 介绍
由于收集和注释大量数据的高成本,从有限数量的训练样本中学习越来越受到关注。研究人员已经开发出算法,以提高模型的性能,这些模型是用很少的数据进行训练的。Finn等人(2017);Snell等人(2017)以元学习的方式训练模型,使模型能够在只有少量训练样本可用的情况下快速适应任务。Hariharan,Girshick (2017);Wang等人(2018)试图通过学习生成模型来综合数据或特征,以缓解数据不足的问题。Ren等人(2018)提出利用未标记数据和预测伪标记来提高少样本学习的性能。
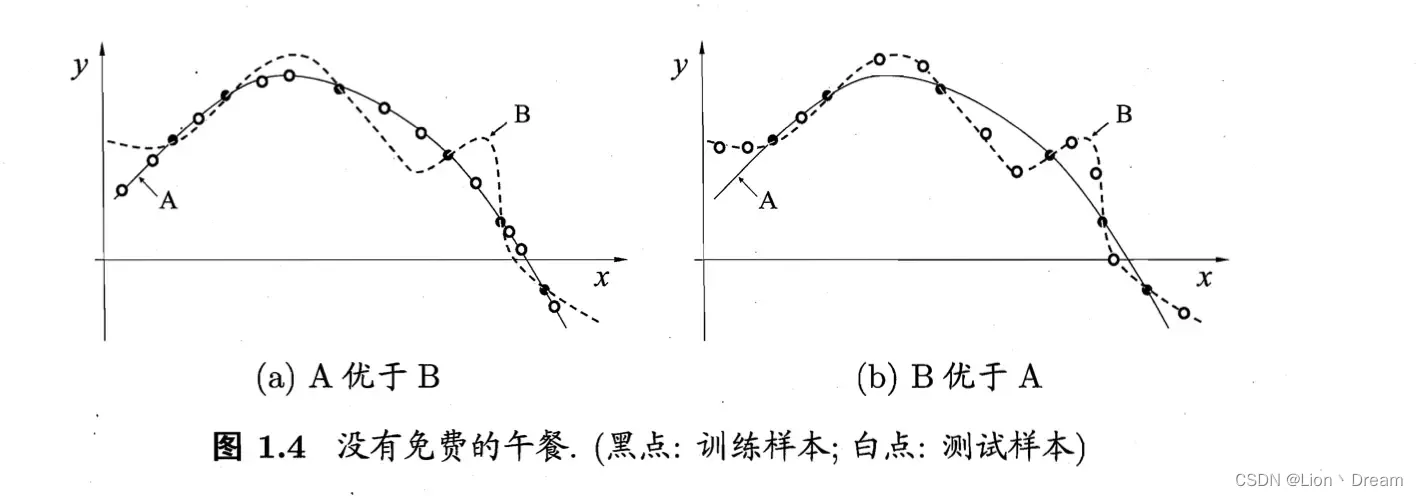
虽然以前的大多数工作都专注于开发更强的模型,但很少关注数据本身的特性。自然,随着数据数量的增加,ground truth分布可以更准确地揭示出来。在评估过程中,用大范围数据训练的模型具有很好的泛化性。另一方面,当训练一个只有少量训练集的模型时,模型倾向于通过尽量减少对这些样本的训练损失来对这些样本进行过拟合。这些现象如图1所示。这种基于少数数据集的偏倚分布会损害模型的泛化能力,因为它远远不能反映评估过程中测试用例抽样的真实分布。
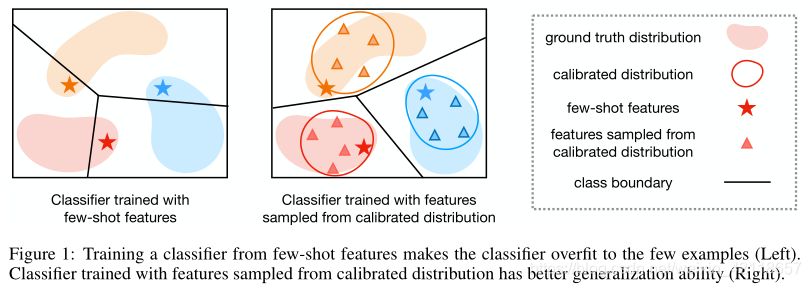
在这里,我们考虑将这个有偏差的分布校准成一个更准确的ground truth分布的近似。这样,用从校准分布中采样的输入训练的模型可以从更精确的分布中概括出更广泛的数据,而不仅仅是拟合那些少数的样本。我们没有对原始数据空间的分布进行校准,而是尝试对特征空间中的分布进行校准,特征空间的维数更低,更容易校准(Xian et al.(2018))。我们假设特征向量的每个维都服从高斯分布,观察到相似类的特征表示通常有相似的均值和方差,如表1所示。因此,高斯分布的均值和方差可以在相似的类之间转移(Salakhutdinov等人(2012))。同时,当该类有足够的样本时,可以更准确地估计统计量。基于这些观察,我们重用来自 many-shot类的统计数据,并根据类相似性将它们转移到更好地估计 few-shot 类的分布。根据估计的分布生成更多的样本,为分类模型的训练提供了充分的监督。

在实验中,我们证明用我们的策略训练的简单逻辑回归分类器可以在两个数据集上达到最先进的精度。我们的分布校准策略可以与任何分类器和特征提取器配对,不需要额外的可学习参数。在5way1shot任务中,从标定后的分布中选取样本进行训练,与仅使用少量样本进行训练的基线相比,训练的准确率提高了12%。我们还将校准过的分布可视化,并表明它是 ground truth的精确近似,可以更好地覆盖测试用例。
2 相关工作
Few-shot分类是一个具有挑战性的机器学习问题,研究人员探索了学习学习(learning to learn)或元学习(meta-learning)的思想,以提高快速适应能力,缓解Few-shot的挑战。元学习最普遍的算法之一是基于优化的算法。Finn等人(2017)和Li等人(2017)提出学习如何优化梯度下降过程,使学习者有良好的初始化、更新方向和学习速率。针对分类问题,研究人员提出了简单而有效的基于度量学习的算法。MatchingNet (Vinyals等人,2016年)和ProtoNet (Snell等人,2017年)通过比较每个类别代表的距离来对样本进行分类。我们的分布校准和特征采样过程不包括任何可学习的参数,分类器是用传统的监督学习方式训练的。
另一种算法是通过代偿来弥补可用样本数量的不足。大多数方法使用生成对抗网络(GANs) (Goodfellow等人,2014年)或自动编码器(Rumelhart等人,1986年)的思想来生成样本(Zhang等人(2018年);Chen等(2019b);Schwartz等人(2018);Gao等人(2018))或特征(Xian等人(2018);Zhang et al.(2019))扩充训练集。具体来说,Zhang et al.(2018)和Xian et al.(2018)提出通过引入基于任务的对抗生成器来合成数据。Zhang等人(2019)试图学习一种变分自编码器来近似分布,并根据估计的统计数据预测标签。自动编码器还可以通过投射视觉空间和语义空间(Chenetal.,2019b)或rencodingtheintraclassoldings (Schwartz等人,2018)来增强样本。Liu et al. (2019b)和Liu et al. (2019a)提出通过类层次来生成特征。虽然这些方法可以生成额外的样本或特征用于训练,但它们需要设计一个复杂的模型和损失函数来学习如何生成。然而,我们的分布校准策略很简单,不需要额外的可学习参数。
数据增强是增加训练样本数量的一种传统而有效的方法。Qin等(2020)和Antoniou &Storkey(2019)提出利用传统的数据增强技术构建无监督Few-shot学习的前置任务。Wang等人(2018)和Hariharan &Girshick(2017)利用了数据增强的一般思想,他们设计了一个幻觉模型,以生成图像的增强版本,为模型s的输入提供不同的选择,即图像和噪声(Wang et al., 2018)或多个特征的连接(Hariharan &Girshick, 2017)。Park等人(2020)试图通过从估计方差中采样来增强特征表示。当我们试图估计类级分布时,这些方法学习从原始样本或它们的特征表示中增加,从而消除单个样本的感应偏差,并从校准分布中提供更多的世代。
3 主要方法
在本节中,我们将在3.1节中介绍Few-shot分类问题的定义,在3.2节中介绍我们提出的方法的细节。
3.1 问题定义
我们遵循一个典型的 few-shot分类设置。给定一个数据标签对D = {(x i, y i)}的数据集,其中![]() 为样本的特征向量,
为样本的特征向量,![]() ,其中C为类的集合。这组类分为基类(base classes)
,其中C为类的集合。这组类分为基类(base classes)![]() 和新类(novel classes)
和新类(novel classes)![]() ,他们具有
,他们具有![]() 和
和![]() 。目标是在基类数据上训练的模型,能够很好地在新类的数据上应用。为了评估模型的快速适应能力或泛化能力,每个任务T只有少量可用的标记样本。最常见的构建任务的方法被称为N-way-K-shot任务(Vinyals et al.(2016)),其中N个类从 novel 集合中采样,每个类只提供K个(如1或5个)标记的样本。少数可用的标记数据称为支持集(support set)
。目标是在基类数据上训练的模型,能够很好地在新类的数据上应用。为了评估模型的快速适应能力或泛化能力,每个任务T只有少量可用的标记样本。最常见的构建任务的方法被称为N-way-K-shot任务(Vinyals et al.(2016)),其中N个类从 novel 集合中采样,每个类只提供K个(如1或5个)标记的样本。少数可用的标记数据称为支持集(support set)![]() 并且模型在另一个查询集(query set)上进行评估
并且模型在另一个查询集(query set)上进行评估![]() ,任务中的每个类都有q个test用例。因此,模型的性能是根据从新类中采样的多个任务(查询集)的平均精度来评估的。
,任务中的每个类都有q个test用例。因此,模型的性能是根据从新类中采样的多个任务(查询集)的平均精度来评估的。

3.2 分布校准
正如3.1节所介绍的,基类有足够的数据量,而从新类中采样的评估任务只有有限数量的标记样本。基类分布统计量的估计比基于 few-shot样本的估计更准确,而 few-shot样本的估计是一个不适定( ill-posed )问题。如表1所示,我们观察到,假设特征分布为高斯分布,每个类的均值和方差与每个类的语义相似度相关。记住这一点,如果我们知道基类和新类有多么相似,统计数据就可以从基类转移到新类。在以下几节中,我们将讨论如何利用基类的统计数据(第3.2.1节),在仅使用几个样本(第3.2.2节)的情况下校准类的分布估计。我们还将详细说明如何利用校准分布来提高 few-shot学习的性能(第3.2.3节)。
请注意,我们的分布校准策略超过了特征级别,并且与任何特征提取器无关。因此,它可以建立在任何预先训练的特征提取器之上,而无需进一步昂贵的微调。在我们的实验中,我们根据他人之前的工作 (Mangla等人(2020))使用了预先训练的 WideResNet。WideResNet被训练来分类基类,以及一个自我监督的前置任务来学习适合于图像理解任务的通用表示。关于训练特征提取器的更多细节请参考他们的论文。
3.2.1 基类的统计信息
我们假设基类的特征分布为高斯分布。基类 i 的特征向量的均值计算为该向量中每个维度的均值:

其中![]() 是基类 i 中第 j 个样本的特征向量,
是基类 i 中第 j 个样本的特征向量,![]() 是基类 i 中样本的总数。由于特征向量x j是多维的,我们使用协方差来更好地表示特征向量中任意一对元素之间的方差。第 i 类特征的协方差矩阵
是基类 i 中样本的总数。由于特征向量x j是多维的,我们使用协方差来更好地表示特征向量中任意一对元素之间的方差。第 i 类特征的协方差矩阵![]() 计算为:
计算为:
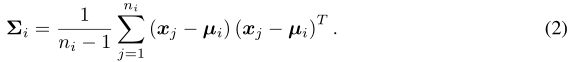
3.2.2 校正新类的统计数据
这里,我们考虑一个从新类中采样的n - way - k -shot任务。
Tukey’s Ladder of Powers Transformation(Tukey的幂阶变换)
为了使特征分布更像高斯分布,我们首先使用Tukey的幂阶变换(Tukey(1977))对目标任务中的支持集和查询集的特征进行变换。Tukey幂阶变换是一类幂变换,它可以减小分布的偏态,使分布更接近高斯分布。Tukey的幂阶变换公式为

其中λ是一个超参数来调整如何纠正分布。将λ设为1,可以恢复原始特征。λ减小使分布的正偏度减小,反之亦然。
Calibration through statistics transfer(通过统计迁移校准)
利用3.2.1节中介绍的基类的统计信息,我们将基类的统计信息从在充足数据下估计得更准确的类中转移到新类中。迁移是基于新类的特征空间与基类i的特征均值之间的欧氏距离,如公式1所示。具体来说,我们从 支持集合 中选择与样本x的特征距离最近的 前k个基类:
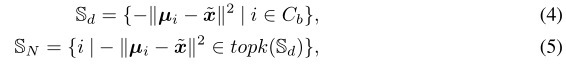
其中topk(·)是从输入距离集![]() 中选择顶部元素的运算符。
中选择顶部元素的运算符。![]() 根据一个特征向量x存储k个最近的基类,然后通过最近基类的统计量来校准分布的均值和协方差:
根据一个特征向量x存储k个最近的基类,然后通过最近基类的统计量来校准分布的均值和协方差:
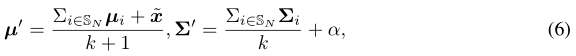
其中α是一个超参数,它决定了从标定分布中采样的特征的分散程度。
同比one shot的few-shot学习,上述的分布校准过程需要多次进行,每次使用支持集中的一个特征向量。这避免了一个特定样本所提供的偏差,并有可能实现更多样化和更准确的分布估计。因此,为了简单起见,我们将校准后的分布表示为一组统计数据。对于类y∈C n,我们将统计数据集表示为![]() ,
,![]() 是校准的均值和协方差,分别根据类y的支持集中的第i个特征计算。在这里,集合的大小是N-way-K-shot任务中的K值。
是校准的均值和协方差,分别根据类y的支持集中的第i个特征计算。在这里,集合的大小是N-way-K-shot任务中的K值。
3.2.3 如何利用已校准的分布?
在对于类y的目标任务中,我们使用一组校准数据![]() ,从校准高斯分布中采样,生成一组标注y的特征向量:
,从校准高斯分布中采样,生成一组标注y的特征向量:
![]()
这里,将每个类生成的特征总数设置为超参数,它们对![]() 中的每个校准分布都是平均分布的。然后,生成的特征和原始支持集特征一起作为特定任务分类器的训练数据。我们通过最小化支持集
中的每个校准分布都是平均分布的。然后,生成的特征和原始支持集特征一起作为特定任务分类器的训练数据。我们通过最小化支持集![]() 特征和生成特征
特征和生成特征![]() 特征上的交叉熵损失来训练分类器:
特征上的交叉熵损失来训练分类器:
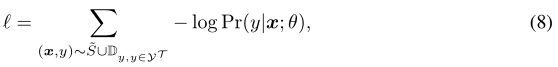
其中![]() 是任务
是任务![]() 的类集。
的类集。![]() 表示特征转换经Tukey幂阶变换后的支持集,分类器模型以θ参数化。
表示特征转换经Tukey幂阶变换后的支持集,分类器模型以θ参数化。
4 实验
在本节中,我们将回答以下问题:
- 与最先进的方法相比,我们的分布校准策略表现如何?
- 校准分配看起来像什么?这对这门课来说是一个准确的近似值吗?
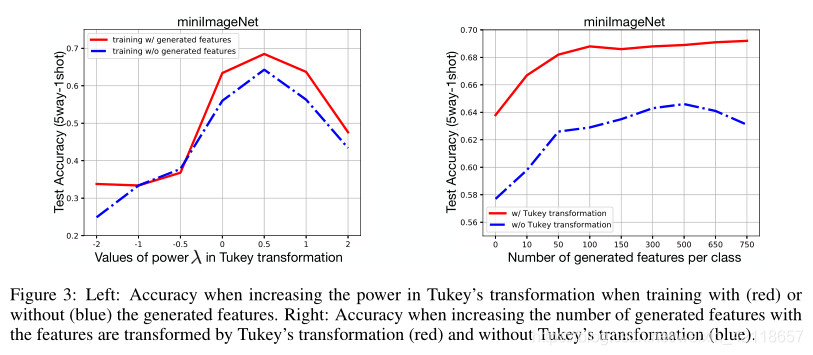
- Tukey幂阶变换如何与特征生成(feature generations)互相影响? 它们对性能有多重要?
4.1 实验设置
4.1.1 数据集
我们评估我们的分布校正策略在miniImageNet (Ravi &Larochelle(2017))、tieredImageNet (Ren等人(2018))和CUB (Welinder等人(2010))。miniImageNet和tieredImageNet有一系列的类,包括各种动物和对象,而CUB是一个更细粒度的数据集,包括各种鸟类。不同粒度级别的数据集的特征空间可能有不同的分布。我们希望在所有三个数据集上展示我们的策略的有效性和通用性。
- miniImageNet来源于ILSVRC-12数据集(Russakovsky et al., 2014)。它包含100个不同的类,每个类有600个样本。图像大小为84 84 3。我们使用前人工作中的数据切分方法(Ravi &Larochelle, 2017),它将数据集分为64个基类、16个验证类和20个新类。
- tieredImageNet是ILSVRC-12数据集的一个较大子集(Russakovsky et al., 2014),该数据集包含608个从分层类别结构中采样的类。每个类属于从ImageNet的高级节点中抽样的34个高级类别中的一个。每个类的平均图像数量为1281张。我们分别使用351、97和160个类进行培训、验证和测试。
- CUB是一个细粒度的少量的分类基准。它包含200个不同类别的鸟类,总共11788张大小为84 84 3的图片。根据之前的工作(Chen等人,2019a),我们将数据集分为100个基类、50个验证类和50个新类。
4.1.2 评价指标
我们使用top-1的准确性作为评价指标来衡量我们的方法的性能。我们报告5way1shot和5way5shot设置miniImageNet, tieredImageNet和CUB的准确性。报告的结果是超过10,000个任务的平均分类精度。
4.1.3 实现的细节
对于特征提取器,我们使用(Mangla等人(2020))训练的WideResNet。对于每个数据集,我们使用基类训练特征提取器,并使用新类测试性能。注意,特征表示是从特征提取器的倒数第二层(带有ReLU激活函数)提取的,因此值都是非负的,因此方程3中对Tukey幂阶变换的输入是有效的。在分布校准阶段,我们计算基类统计量,并将它们转移到每个数据集上,对新的类分布进行校准。我们使用了scikit-learn的LR和SVM实现(Pedregosa等人(2011))和默认设置。除了α,我们对所有数据集使用相同的超参数值。具体来说,生成的特性数量为750个;k = 2,λ= 0.5。对于miniImageNet、tieredImageNet和CUB,α分别是0.21, 0.21和0.3。源代码可在以下地址获得: https://github.com/ShuoYang-1998/ICLR2021-Oral_Distribution_Calibration
4.2 与最先进技术的比较
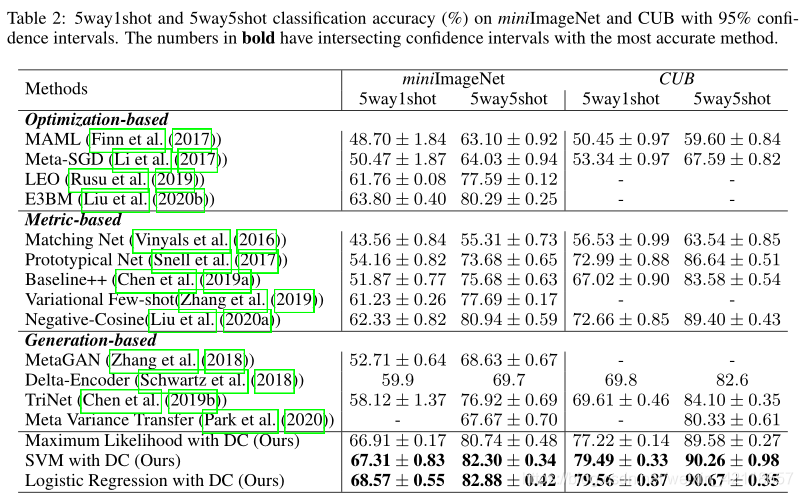
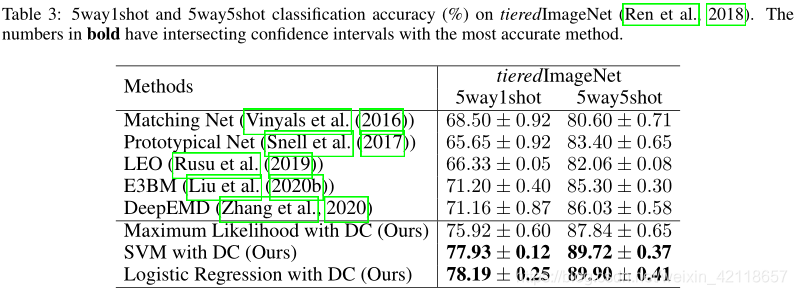
表2 和 表3 给出了我们的方法在miniImageNet、tieredImageNet和CUB上的5way1shot和5way5shot分类结果。我们将我们的方法与三组few-shot学习方法、基于优化的、基于度量的和基于生成的进行比较。我们的方法可以建立在任何分类器的基础上,我们使用SVM和LR这两个流行且简单的分类器来证明我们方法的有效性。我们的方法所配备的简单线性分类器比最先进的few-shot分类方法表现更好,在 1-shot和 5-shot设置的miniImageNet, tieredImageNet和CUB的表现最好。在5way1shot设置方面,我们的分布校准性能比最先进的基于生成的方法高出10%,这证明我们的方法能够更好地处理极低 low-shot的分类任务。其他基于生成的方法需要设计生成模型,并对可学习参数进行额外的训练,相比之下,简单的DC机器学习分类器简单、有效、灵活,可以配置任何特征提取器和分类器模型结构。具体来说,我们在表2和表3中显示了三个变量,即DC的最大似然,DC的SVM, DC的Logistic回归。基于校准分布的简单最大似然分类器的性能优于之前的基线,使用校准分布的样本训练SVM分类器或Logistic回归分类器可以进一步提高性能。
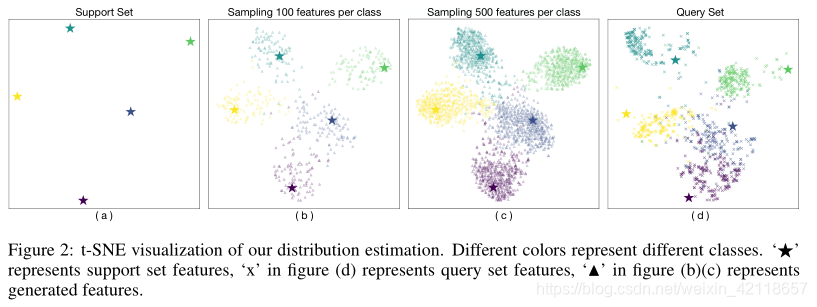
4.3 生成样本的可视化
我们通过可视化从分布中采样生成的特征来显示校准分布的样子。在图2中,我们给出了原始支持集(a)的t-SNE表示(van der Maaten & Hinton (2008)),生成的特征(b,c)和查询集(d)。在校准分布的基础上,采样特征形成一个高斯分布和更多的样本(c)可以更全面地表示分布。由于支持集中的示例数量有限(在本例中只有1个),查询集中的示例通常覆盖更大的区域,与支持集不匹配。这种不匹配在一定程度上可以通过生成的特性来修复,例如,(c)中生成的特性可以重叠查询集的区域。因此,使用这些生成的特征进行训练可以缓解仅由 few-shot样本估计的分布与 ground truth 分布之间的不匹配。
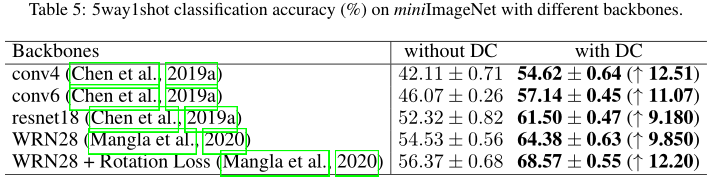
4.4 分布校准的适用性
在不同的backbones上应用分布校准
我们的分布校准策略对主干/特征提取器是不可知的。表5显示了在不同特征提取器上应用分布校准时性能的一致提升,例如4个卷积层(conv4)、6个卷积层(conv6)、resnet18、WRN28和经过旋转loss训练的WRN28。与使用不同基线训练的骨干相比,分布校准的精度提高了10%左右。
在其他基线上应用分布校准
利用我们的分布校准策略生成的特征进行训练,可以使各种工作受益。我们将我们的分布校准策略应用于两种简单的 few-shot分类算法,Baseline (Chen et al., 2019a)和Baseline++ (Chen et al., 2019a)。表6显示,我们的分布校准为两者带来了超过10%的精度提高。

4.5 用生成的特征进行特征转换和训练的效果
烧蚀研究
表4显示了表现,在训练我们的模型时,没有对特征进行Tukey幂阶变换,以及在训练时,在没有生成特征的情况下进行训练。很明显,如果在5way1shot设置中不使用这两种方法,性能会严重下降10%以上。在5way1shot设置中,任何一个的消融都会导致性能下降约5%。

在Tukey幂阶变换中幂的选择(0.5最好)
图3左侧显示了使用生成的特征(红色)和不使用生成的特征(蓝色)训练分类器时,对公式3中的Tukey s变换选择不同幂时的5way1shot精度。注意,当λ= 1时,变换保持原始的特征表示。对于有和没有这些特征的训练,我们发现λ= 0.5是最优的选择。通过Tukey变换,目标任务中查询集特征的分布与校正后的高斯分布更加一致,从而有利于根据校正后的高斯分布采样特征训练分类器。
生成的特性数量(不能太多,也不能太少)
图3的右侧分析了在两种情况下,是否生成更多的特性会导致一致的改进,即支持和查询集的特性通过Tukey变换(红色)进行转换时,以及它们不进行转换时(蓝色)。我们发现,当生成的特性数量低于500时,两种情况都可以从生成的特性中获益。然而,当采样的特征更多时,测试的分类器在未转换特征上的性能开始下降。通过使用生成的样本进行训练,简单逻辑回归分类器在一次分类设置中有12%的相对性能提高。
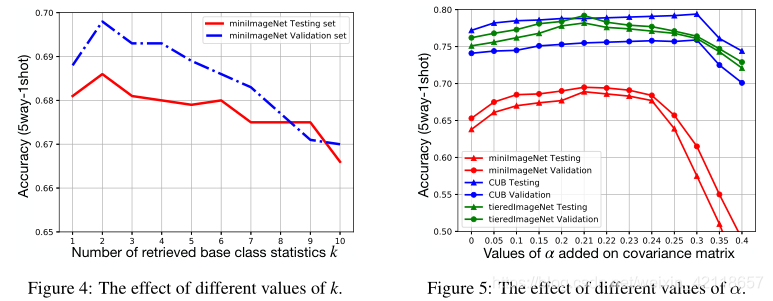
4.6 其他超参数
我们根据验证集的性能选择超参数。公式5中校正新类分布的k基类统计量设为2。图4显示了k不同值的影响。方程6中的α是在估计协方差矩阵的每个元素上添加的一个常数,它可以确定从校准分布中采样的特征的分散程度。适当的α值可以保证分类器具有良好的决策边界。不同的数据集有不同的统计量,适当的α值可能因不同的数据集而不同。图5探讨了α对三个数据集的影响,即miniImageNet、tieredImageNet和CUB。我们观察到,在每个数据集中,验证集和新(测试)集的性能通常具有相同的趋势,这表明方差是依赖于数据集的,并不是对特定集的过拟合。
5 总结与未来工作
我们提出了一种简单而有效的分布校准策略来进行few-shot分类。在miniImageNet上,没有复杂的生成模型、训练loss和额外的学习参数,用我们的策略生成的特征训练的简单逻辑回归比目前最先进的方法高出5%。对校准后的分布进行了可视化,证明了对特征分布的准确估计。未来的工作将探索分布校准在更多问题设置中的适用性,如多域few-shot分类,以及更多方法,如基于度量的元学习算法。





![[TIST 2022] No Free Lunch Theorem for Security and Utility in Federated Learning](https://img-blog.csdnimg.cn/14d1e6b8669545c4b1bec1b6055cc7e4.png)