文章目录
- 1. 声纹识别系统框架
- 1.0 声纹识别系统
- 1.0.1 不太清晰的两个阶段:训练阶段和测试阶段
- 1.0.2 只讲了一个阶段:测试/应用阶段(包括注册和验证)
- 1.0.3 声纹识别系统的三个阶段
- 1.1 特征提取
- 1.2 模型建立
- 1.3 打分判决
- 1.3.1 判决方式
- 1.3.2 分数规整(正则化)
- 1.4 主流的声纹识别建模技术
- i-vector 模型框架
- 1.5 评价指标
- 2. 应用
- 2.1 1:1 对比
- 2.2 1:N 检索
- 2.3 N:N 聚类
1. 声纹识别系统框架
1.0 声纹识别系统
目前常见的声纹识别有以下两种表达:
(个人不太直观和清楚,不仅“阶段”没有讲清楚,还容易混淆“模型”——实质上有三个阶段、至少连个“模型”的概念)
1.0.1 不太清晰的两个阶段:训练阶段和测试阶段
 上图这种系统框架图并没有直观地反应出测试阶段的两种情况:注册和验证
上图这种系统框架图并没有直观地反应出测试阶段的两种情况:注册和验证
或者这种:
 也没有具体细化。
也没有具体细化。
1.0.2 只讲了一个阶段:测试/应用阶段(包括注册和验证)

上图这种方式又很容易让人忽视一个前提:声纹建模模型是已知的,或者说已经经过了模型训练阶段。
1.0.3 声纹识别系统的三个阶段
个人认为比较合理的说话人识别系统框架:
实际上,声纹识别系统有三个阶段:
- 训练阶段(training):训练特征提取模型(声纹编码器模型)
- 注册阶段(enrollment):录入底库数据(形成所谓的“说话人模型”,每个人都有一个)
在这个阶段,每个说话人每一条音频都会形成一个声纹模型,最后对所有模型进行聚合(比如取平均等),最终形成这个说话人的说话人模型 - 测试/评估阶段(evaluation):读入测试数据,进行识别(相似度匹配)
The speaker verification, in general, consists of three stages: Training, enrollment, and evaluation. In training, the universal background model is trained using the gallery of speakers. In enrollment, based on the created background model, the new speakers will be enrolled in creating the speaker model. Tech- nically, the speakers’ models are generated using the universal background model. In the evaluation phase, the test utterances will be compared to the speaker models for further identification or verifica- tion.
1.1 特征提取
特征主要分为两大类:
- 一是基于短时频谱的声学特征
- 二是基于音素、韵律等的高层特征。
由于声学特征提取相对容易、性能优越等特点,一直被作为主要的特征使用。
说话人识别中,声学特征参数通常有梅尔倒谱特征(MFCC)
和感知线性预测特征(PLP)等。

(高层特征暂略)
1.2 模型建立
训练产生模型,后续的测试利用保留的模型参数即可直接识别。
模型分为三大类:
- 生成式模型:GMM等
- 判别式模型:SVM等
- 向量模型:i-vector等
1.3 打分判决
来自测试集的音频特征与各个说话人模型特征进行相似度匹配,其结果为(匹配)分数,其分值越高,表示测试的音频更大可能是来自于该说话人。
1.3.1 判决方式
打分判决的方式根据建模时候所选择的模型,常见的有:
- 似然计算——生成式模型
- 欧氏距离、余弦相似度和神经网络等——判别式模型
1.3.2 分数规整(正则化)
似乎忽略了一个问题,不同说话人得到的验证分数的分布可能会存在差异,主要体现在两方面:
(1)特殊性
- 说话人的声音太独特:容易造成错误拒绝
- 说话人的声音太“大众”:容易造成错误接受
(2)稳定性
- 说话人的声音富于变化:容易造成错误拒绝
- 说话人的声音非常稳定:容易造成错误接受
分数正则化则是将上述不同说话人验证分数的差异化考虑到判别过程中,从而减轻全局阈值所带来的问题。
主要的正则化方法如下:
- Z-norm 正则化(零正则化)
- T-norm 正则化(测试正则化)
- TZ-norm 正则化
- S-norm(对称正则化)
1.4 主流的声纹识别建模技术
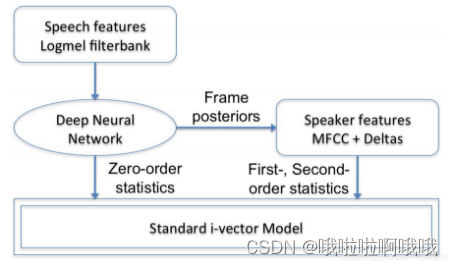
i-vector 模型框架
当前主流的说话人识别系统采用模型框架是 i-vector 模型框架,其重要的意义在与将高斯混合 - 通用背景模型 GMM-UBM、总体变化模型 i-vector 和线性判别分析模型 LDA 统一到同一个算法框架下,并取得的巨大的成功,已成为当前主流的说话人识别模型框架。
(1)高斯混合 - 通用背景模型
高斯混合 - 通用背景模型: GMM-UBM
由高斯混合模型(GMM)和通用背景模型(UBM)合并构成,前者(GMM)的思想是通过对多个高斯密度函数进行加权平均来逼近任意空间分布,后者(UBM)是由大量说话人数据通过极大似然估计(MLE)得到的GMM模型,代表所有说话人的“共性”。

在基于 GMM-UBM 框架的说话人识别系统中,先通过计算得出测试语音与目标说话人 GMM 模型匹配的输出似然度,然后再计算出测试语音与 UBM 模型匹配的输出似然度,最后计算出这两个似然度的比值。
(2)总体变化模型
GMM-UBM建模方法得到的高斯超向量将不定长的语音特征转换为定长的高维特征,一定程度上模糊了每个语音样本的时长信息,削弱了信道差异对说话人识别性能的影响。
由于整条语音通过 MAP (最大后验概率)转换为高斯超向量,所以超向量中除了蕴含说话人信息外,同时也包含了语音中的通道、背景噪音、语种等信息。那么如何去除超向量中的说话人无关信息成为研究的重点。
在不断尝试对高斯超向量建模去除说话人无关信息的过程中,联合因子分析 ( Joint Factor Analysis , JFA )建模技术 取得了巨大成功。 JFA 的原理是对语音的高斯超向量进行因子分解,得到说话人因子和通道因子,进而去除通道因子, 强化说话人因子。实验表明, JFA 在性能上远远优于传统 GMM-UBM 建模方法。
根据 JFA 的模型假设,通道因子应该只包含语音中的传输通道、录音设备等与说话人无关的信息。但是,研究发现通道因子中还存在有用的说话人信息,进 而也反映出 JFA 模型假设存在着一些问题。既然在高维的超向量空间中强制分离说话人空间和通道空间有可能会因为分离的不正确而丢失重要的信息, Dehak 和 Kenny 对其进行了改善,提出了一个简化 的 JFA 模型 —— 总体变化模型( Total Variability Model , TVM ) ,由于其提取的特征为 i-vector,故总体变化模型也称为 i-vector 模型。
i-vector 模型与 JFA 模型的不同之处在于,它不在高斯超向量空间中区分说话人信息和通道信息,而是将说话人与通道作为一个整体,并且假定这个整体在一个 低维子空间 T 中变化,这一点类似于主成分分析( Principal Component Analysis )。 利用降维的方法,先将高维超向量降到低维 i-vector ,然后在低维的 i-vector 空间里 分离说话人和通道信息,这是 i-vector 模型的基本思想。
相比 JFA , i-vector 模型在性能及算法复杂度方面都更具优势,这主要得益于 i-vector 系统将定长的高维高斯超向量转化为定长的低维向量,从而使得在通道补偿及最终的打分判决阶段能够利用许多机器学习的技术和方法。
(3)线性判别分析模型
i-vector 模型的作用仅仅是通过点估计( Point estimate )的方式得到一段语音的 低维向量表示,模型本身并不包括分类或者分数计算的功能。通常是将 i-vector 交 给另外的分类器,由分类器来完成最终的识别功能。
i-vector 后续的通道补偿通常使用线性判别分析模型( Linear Discriminant Analysis, LDA ) ,它通过投影的方式将原始数据投影到维度更低的空间中,从而使得训练样本在新的子空间有最大的类间距离和最小的类内距离。即在变换后的空间里,同一个说话人的不同 i-vector 尽量靠近,而不同的说话人尽量分开。
1.5 评价指标
NIST 说话人识别评测( SRE )是由美国国家标准技术局 (National Institute of Standard and Technology , NIST) 承办的国际上最有影响力的、最权威的说话人识别 技术评测。 SRE 评测的技术水平代表了当前与说话人识别技术的国际最高水准。
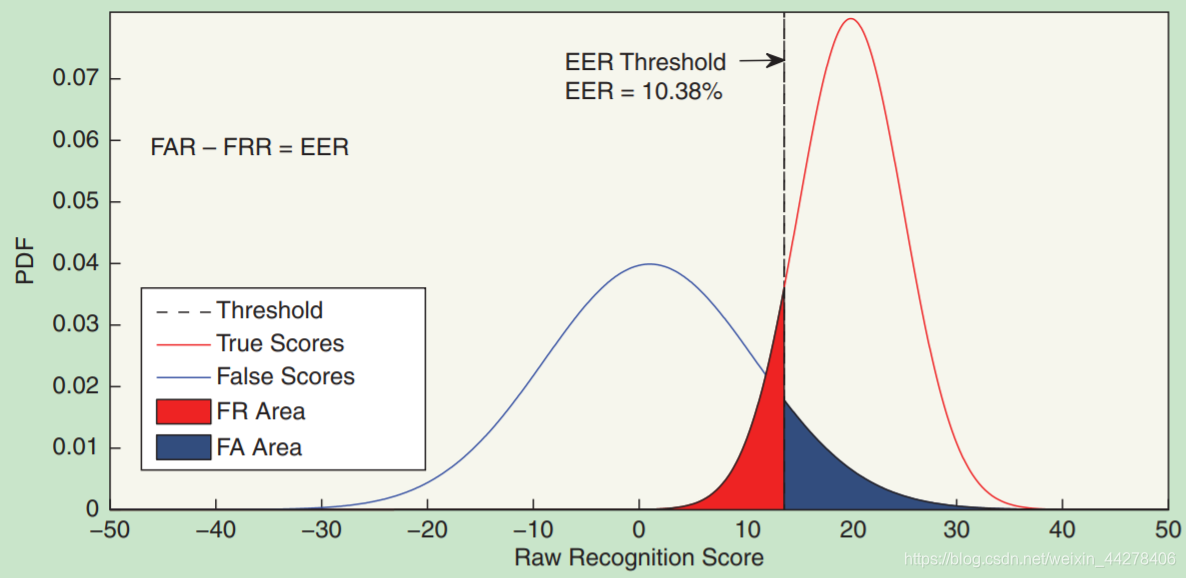
说话人确认系统需要判断一条测试语音是否由某个已知说话人所说,一般是 通过提前设定的置信度门限来做判决,因此总是会存在两类错误:误报( False Alarm ) 和漏报( Miss )。误报是指错误地接受了冒认者的语音,而漏报是指错误的拒绝 了真正说话人的语音。
误报 = 错误接受
漏报 = 错误拒绝

- DET 曲线
- 等错误率
- 检测代价函数
在实际应用中误报和漏报所对应的代价不同,比如监听任务希望漏报足够低, 而身份认证则更关心误报情况。然而等错误率指标是应用无关的,它对误报和漏 报统一对待。因此可以对不同的错误进行加权,而权重的设置跟应用联系起来。
2. 应用
2.1 1:1 对比

又称说话人确认,指有了一段未知的语音,来判断这段语音是否来源于这个目标用户,是一个1对1的二分类问题。
2.2 1:N 检索

又称说话人辨识,指有了一段待测的语音,将这段语音与已知的一个集合内的一干说话人进行对比,选取最匹配的那个说话人,是一个1对多的判别问题。
2.3 N:N 聚类

又称说话人聚类,通过声纹相似度检测,将属于同一个说话人的多个语音片段合并为一类,达到分人整理的目的,可应用于金融团案稽查、会议发言人标记等。
参考:
- 平安云-声纹识别
- 《基于深度学习的说话人识别建模研究》
![[声纹识别]基于MFCC的声纹识别算法](https://img-blog.csdnimg.cn/408da1548faa47ac8f1d922457bc268f.png)