[sklearn]性能度量之AUC值
(from sklearn.metrics import roc_auc_curve)
1.AUC
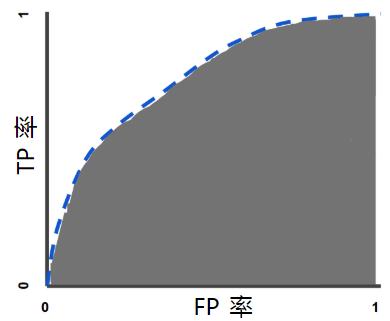
AUC(Area Under ROC Curve),即ROC曲线下面积。
2.AUC意义
若学习器A的ROC曲线被学习器B的ROC曲线包围,则学习器B的性能优于学习器A的性能;若学习器A的ROC曲线和学习器B的ROC曲线交叉,则比较二者ROC曲线下的面积大小,即比较AUC的大小,AUC值越大,性能越好。
3.sklearn中计算AUC值的方法
形式:
from sklearn.metrics import roc_auc_score
auc_score = roc_auc_score(y_test,y_pred)
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print(roc_auc_score(y_true, y_scores))
0.75
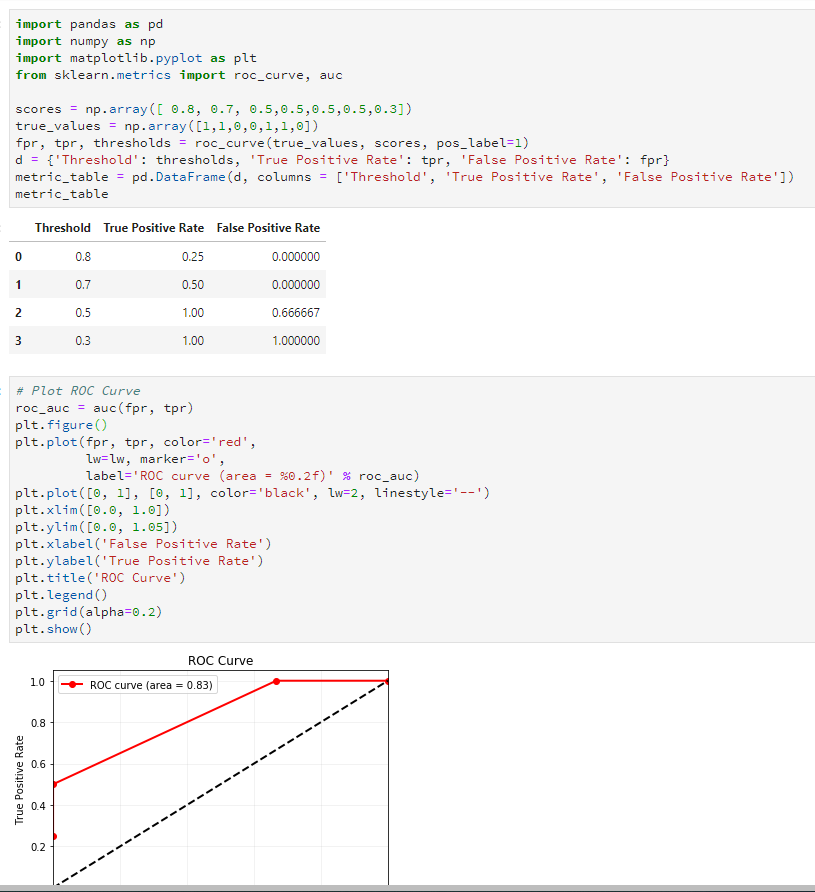
fpr,tpr,thresholds=metrics.roc_curve(y_true,y_scores,pos_label=1)
print(metrics.auc(fpr,tpr))
0.75
说明:
y_pred即可以是类别,也可以是概率。
roc_auc_score直接根据真实值和预测值计算auc值,省略计算roc的过程。
案例

#(1)导库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np#测试样本的数量
parameter=30# (2)随机生成结果集
data=pd.DataFrame(index=range(0,parameter),columns=('probability','The true label'))
data['The true label']=np.random.randint(0,2,size=len(data))
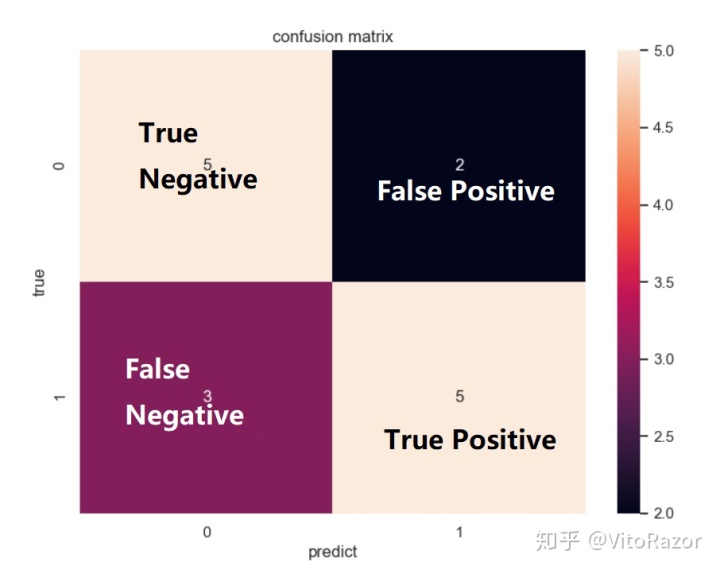
data['probability']=np.random.choice(np.arange(0.1,1,0.1),len(data['probability']))# (3)计算混淆矩阵
cm=np.arange(4).reshape(2,2)
cm[0,0]=len(data[data['The true label']==0][data['probability']<0.5])#TN
cm[0,1]=len(data[data['The true label']==0][data['probability']>=0.5])#FP
cm[1,0]=len(data[data['The true label']==1][data['probability']<0.5]) #FN
cm[1,1]=len(data[data['The true label']==1][data['probability']>=0.5])#TP# (4)计算假正率和真正率
# 首先,画出混淆矩阵。import itertools
classes = [0,1]
plt.figure()
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
tick_marks = np.arange(len(classes))
print(tick_marks)#[0,1]
plt.xticks(tick_marks, classes,rotation=0)
plt.yticks(tick_marks, classes)
print(cm.shape)
print('cm',cm)#显示中间数字
thresh = cm.max() / 2.
print('thresh',thresh)
print(cm.shape[0])
print(cm.shape[1])
# product(A, B)函数,返回A、B中的元素的笛卡尔积的元组。听起来有点绕,先看代码吧:
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="green" if cm[i,j] > thresh else "black")# tight_layout会自动调整子图参数,使之填充整个图像区域plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()

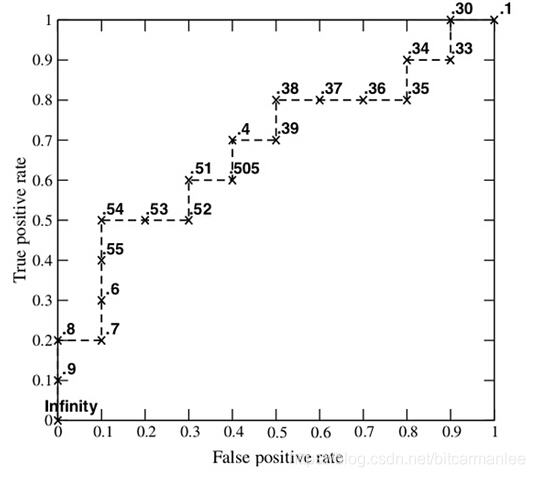
# 三、ROC曲线和AUC值
#
# ROC曲线是一系列threshold下的(FPR,TPR)数值点的连线。此时的threshold的取值分别为测试数据
# 集中各样本的预测概率。但,取各个概率的顺序是从大到小的。
# (1)按概率值排序 首先,按预测概率从大到小的顺序排序:
data.sort_values('probability',inplace=True,ascending=False)
# 此时,threshold依次取0.9,0.9,0.9,0.9,0.9,0.9,0.8,0.8,0.7,...。 比如,
# 当threshold=0.9(第3个0.9),一个”0“预测错误,两个”1“预测正确,FPR=1/11=0.09,
# TPR=2/19=0.11。 当threshold=0.9(第5个0.9),一个”0“预测错误,四个”1“预测正确,
# FPR=1/11=0.09,TPR=4/19=0.21。 当threshold=0.6(第1个0.6),三个”0“预测错误,
# 九个”1“预测正确,FPR=3/11=0.27,TPR=9/19=0.47。# (2)计算全部概率值下的FPR和TPR
TPRandFPR=pd.DataFrame(index=range(len(data)),columns=('TP','FP'))
for j in range(len(data)):data1=data.head(n=j+1)FP=len(data1[data1['The true label']==0][data1['probability']>=data1.head(len(data1))['probability']])/float(len(data[data['The true label']==0]))TP=len(data1[data1['The true label']==1][data1['probability']>=data1.head(len(data1))['probability']])/float(len(data[data['The true label']==1]))TPRandFPR.iloc[j]=[TP,FP]
print(TPRandFPR)
# (3)画出最终的ROC曲线和计算AUC值
#
from sklearn.metrics import auc
AUC= auc(TPRandFPR['FP'],TPRandFPR['TP'])
plt.scatter(x=TPRandFPR['FP'],y=TPRandFPR['TP'],label='(FPR,TPR)',color='k')
plt.plot(TPRandFPR['FP'], TPRandFPR['TP'], 'k',label='AUC = %0.2f'% AUC)plt.legend(loc='lower right')
plt.title('Receiver Operating Characteristic')
plt.plot([(0,0),(1,1)],'r--')
#定义x轴长度和y轴长度
plt.xlim([-0.01,1.01])
plt.ylim([-0.01,01.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()# AUC(Area Under roc Cure),顾名思义,其就是ROC曲线小的面积,在此例子中AUC=0.62。AUC越大,说明分类效果越好。