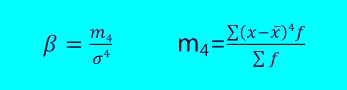在上一篇文章中(baiziyu:模型评价——训练误差与测试误差、过拟合与欠拟合、混淆矩阵)主要介绍了模型评价涉及的基本概念,本节给出一些常用的评价指标。这些指标大致可以分为三类,第一大类是普通的准确率评价指标,它给出了模型在验证集或测试集上的一个大致准确性,在sklearn中可以通过调用模型实例的score方法获得。第二大类是精确率与召回率以及宏平均与微平均。这部分指标在一般的论文实验部分都会使用。它们比起准确率能更精细地描述模型效果。并且这些指标也是信息检索中常用的指标。在sklearn中可以通过classification_report方法获得这些指标,该方法会给出每一个类别的三个具体指标,使我们能更清晰地了解系统在哪一个类别上效果比较好,在哪一个类别上还需要进行分析改进。第三大类是ROC曲线与AUC值,这两个指标主要作为不平衡分类的评价指标。当然第二大类中涉及的指标也会作为不平衡分类的可选评价指标。第三大类由于涉及作图,因此大家要拿出一点点耐心,仔细琢磨一下图线各关键点的意义,必要时可以先自己手算一下。
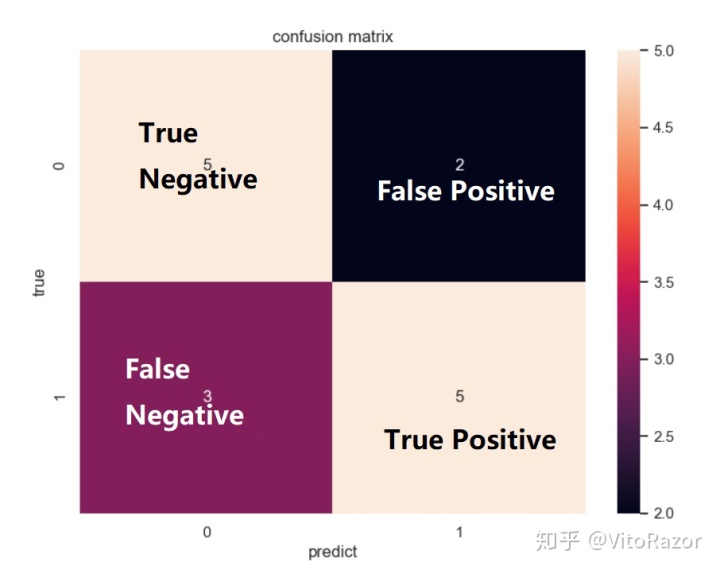
为了定义指标,我们引入上一篇文章中的混淆矩阵。这里以二分类为例

准确率
- 准确率
从计算公式,我们可以看到它计算的是整体的平均准确性。对于不平衡分类,准确率并不是一个好的衡量指标。这是因为一个将所有文档都不归于小类的分类器会获得很高的准确率,但是这显然并不能说明系统实际的准确性。因此对于不平衡分类来说,精确率、召回率和F值才是更好的衡量指标。
精确率、召回率、F值
- 精确率
度量分类器对某一类别预测结果的准确性,对所有类别求和取均值后可以得到整体精确率。
- 召回率
度量分类器对某一类别预测结果的覆盖面,对所有类别求和取均值后可以得到整体覆盖面。
- F值
度量分类器对某一个类别预测结果的精确性和覆盖面。它是精确率和召回率的调和平均值。
宏平均与微平均
当评价多类目分类器的效果时,还经常采用宏平均和微平均两个度量方法。下表以两个类别为例说明计算方法。

- 宏平均
度量常见类效果
- 微平均
度量稀有类效果
在sklearn中使用classification_report计算上边提到的5个指标的时候,需要说明一下类别名称和类别标记的对应关系,因此这里直接把示例代码列出了。
>>> y_true = [-1, 0, 1, 1, -1] # 实际类别值
>>> y_pred = [-1, -1, 1, 0, -1] # 预测类别值
>>> from sklearn.metrics import classification_report
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))precision recall f1-score supportclass 0 0.67 1.00 0.80 2class 1 0.00 0.00 0.00 1class 2 1.00 0.50 0.67 2micro avg 0.60 0.60 0.60 5macro avg 0.56 0.50 0.49 5
weighted avg 0.67 0.60 0.59 5classification_report中target_names列表中的类别名称依次对应的是预测值去重升序排列后对应的类别整数值。因此’class 0’对应的类别是-1,’class 1’对应的类别是0,’class 2’对应的类别是1。
ROC曲线与AUC值
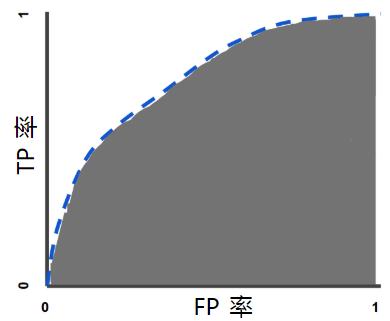
ROC曲线和AUC值是处理不平衡分类问题的评价方法。显示分类器真正率tpr和假正率fpr之间折中的一种图形化方法(fpr为横坐标,tpr为纵坐标)。真正率和假正率的定义将在下边介绍。一个好的分类模型的ROC曲线应尽可能靠近面积为1的正方形的左上角。AUC值是ROC曲线下的面积。AUC值越大,分类器效果越好。
- 真正率
- 假正率
介绍了真正率和假真率以及ROC曲线后,你应该能回答下边两个问题了。
问题1 一个随机预测正、负类别的分类器的ROC曲线是什么样的?
答:是连接(0,0)点和(1,1)点之间的对角线。
问题2 ROC曲线上的每一个点都对应于一个分类器归纳的模型。那么把每个实例都预测为正类的模型所对应的点的坐标是什么呢?把每个实例都预测为负类的模型所对应的点的坐标是什么呢?一个理想的分类模型所对应的点的坐标是什么呢?
答:TPR=1,FPR=1的点对应的模型为把每个实例都预测为正类。TPR=0,FPR=0的点对应的模型为把每个实例都预测为负类。TPR=1,FPR=0的点对应的模型为理想模型。
- ROC曲线的绘制过程
为了能够绘制ROC曲线,分类器需要能提供预测类别的得分值,用来对预测为正类的实例按得分生序排列,最不肯定的排在前,最肯定的排在后。需要注意的是,这个得分是预测为正类(稀有类)的分值,而不是正、负类中得分最高的值。具体绘制过程如下:
(1)让模型对每一个实例进行预测,记录正类得分,并按得分将实例升序排列。
(2)从排序列表中按顺序选择第1个得分最小的记录,从该记录开始到列表结束的所有记录都被指定为正类,其他实例被指定为负类(此时显然所有实例都被指定为正类),计算混淆矩阵并计算TPR,FPR。此时,TPR=FPR=1。
(3) 从排序列表中选择下1个记录,从该记录开始到列表结束的所有记录都被指定为正类,其他实例指定为负类,计算混淆矩阵并计算TPR,FPR
(4) 重复步骤(3),直到列表中所有实例都被选择过。
(5) 以FPR为横轴,TPR为纵轴,描点绘制ROC曲线。
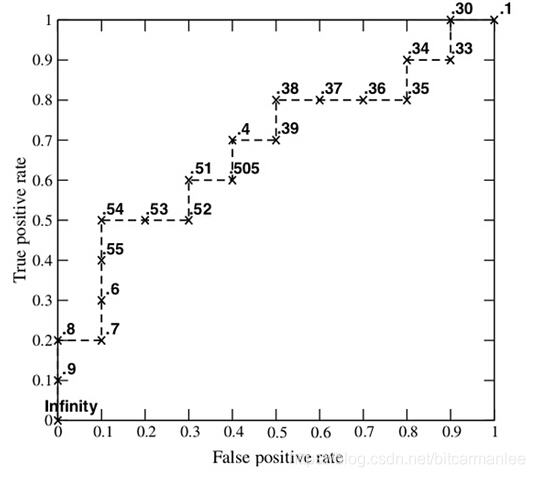
示例:
下表中,每一列表示一个实例,已经按照预测为正类的得分升序排列。第1行为实例的实际类别,第2行为实例被模型预测为正类的得分。请计算出第2行之后的各行表示的混淆矩阵元素值以及TPR、FPR值。

解:首先选择第1个实例,按照绘制过程的第(2)个步骤,此时所有实例都被指定为+,则比较表中第1行的实际类别,可以计算出TP=5, FP=5, TN=0, FN=0, TPR=1, FPR=1。将计算得到的值填入表中第1列相应位置。接着按照第(3)个步骤,选择第2个实例,此时从第2到第10的8个实例指定为正类,其余实例即第1个实例指定为负类,计算TP=4,FP=5,TN=0,FN=1,TPR=4/(4+1)=0.8, FPR=5/(5+0)=1。依次类推计算第3-8列的各行元素值。接下来便可以FPR为横轴,TPR为纵轴,描出表中给(fpr,tpr)点,绘制模型的ROC曲线。
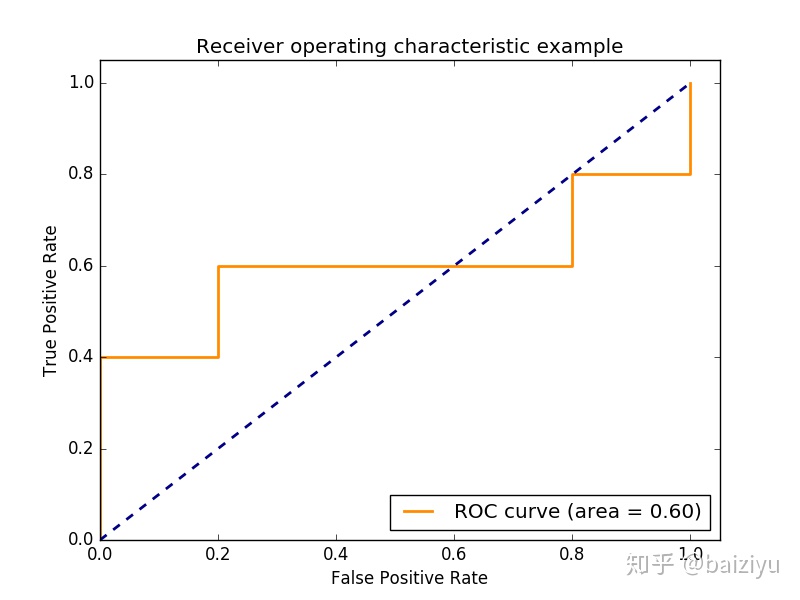
示例代码
https://github.com/baiziyuandyufei/text_classification_tradition/blob/master/sklearn示例/sklearn-roc_curve和auc.ipynbgithub.com好了,今天的内容有些多就介绍到这里了。模型评价的全部内容都已介绍完毕,如果后续还有补充会再续补文章。接下来会用很快的时间把朴素贝叶斯,线性SVC,SGD Classifier写出来,这三个分类器的示例先不打算写呢,因为我觉得我们还是先把基本原理记清楚再去实践会好一些。后边在介绍了特征工程初步后会写3个文本分类的应用示例,分别是新闻文本分类,影评情感分类,英文垃圾邮件分类,3个应用示例都基于朴素贝叶斯,语言都是英语。朴素贝叶斯,线性SVC,SGD Classifier这三个分类器都是sklearn官网关于模型选择的推荐流图,我在另一篇文章(baiziyu:文本分类模型比较与选择)中介绍过,大家可以再回过头去温习一下。谢谢大家关注。