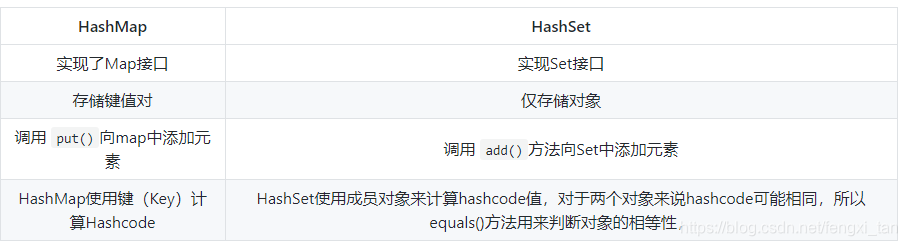
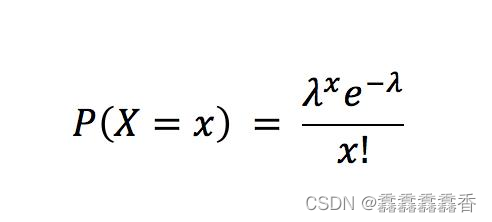目录
- 1. 基于Arraylist集合方式实现
- 2. 基于数组+链表方式实现(Jdk)
- 3. HashMap底层是有序存放的吗?
- 4. LinkedHashMap实现缓存淘汰框架
- 5. HashMap如何降低Hash冲突概率
- 6. HashMap源码解读
- 6.1 modCount的作用
- 6.2 HashMap7扩容产生死循环问题
- 6.3 HashMap8扩容底层原理
- 6.4 HashMap加载因子为什么是0.75而不是1或者0.5
- 6.5 HashMap如何存放1万条key效率最高
- 6.6 为什么JDK官方不承认Jdk7扩容死循环Bug问题
- 7. ConcurrentHashMap源码解读
- 7.1 JDK1.7ConcurrentHashMap源码解读
- 7.1.1 简单实现ConcurrentHashMap
- 7.1.2 核心参数分析
- 7.1.3 核心Api
- 7.2 JDK1.8ConcurrentHashMap源码解读
- 7.2.1 源码解读
- 8. Arraylist集合源码解读
- 9. [HashMap源码注释](https://blog.csdn.net/qq_30999361/article/details/124806516)
1. 基于Arraylist集合方式实现
public class ArraylistHashMap<K, V> {private List<Entry<K, V>> entries = new ArrayList<Entry<K, V>>();class Entry<K, V> {K k;V v;Entry next;public Entry(K k, V v) {this.k = k;this.v = v;}}public void put(K k, V v) {entries.add(new Entry<>(k, v));}public V get(K k) {for (Entry<K, V> entry :entries) {if (entry.k.equals(k)) {return entry.v;}}return null;}public static void main(String[] args) {ArraylistHashMap<String, String> arraylistHashMap = new ArraylistHashMap<>();arraylistHashMap.put("demo", "123");arraylistHashMap.put("123", "demo");System.out.println(arraylistHashMap.get("123"));}
}根据key查询时间复杂度为o(n),效率非常低。
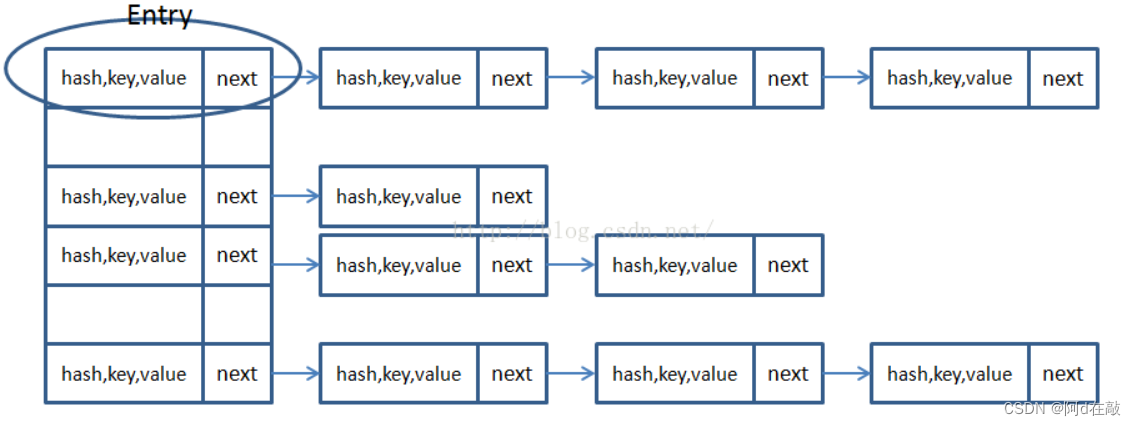
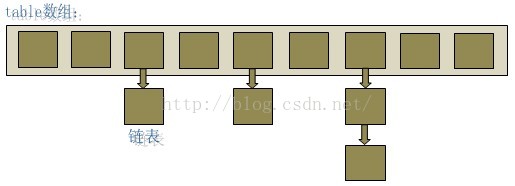
2. 基于数组+链表方式实现(Jdk)
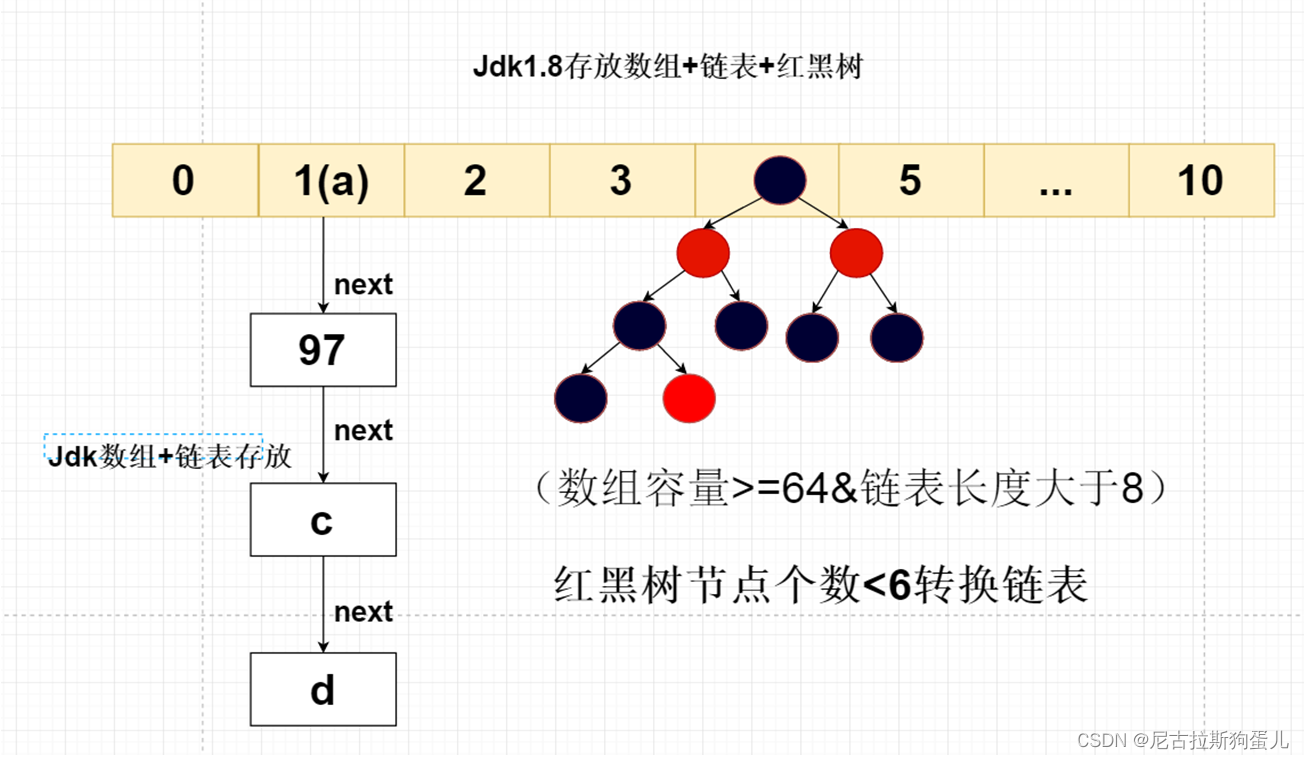
HashMap1.7底层是如何实现的 基于数组+链表实现
同一个链表中存放的都是hashCode值可能相同,但是内容值却不同
public class ExtHashMap<K, V> {private Entry[] objects = new Entry[10000];class Entry<K, V> {public K k;public V v;Entry next;public Entry(K k, V v) {this.k = k;this.v = v;}}public void put(K k, V v) {int index = k == null ? 0 : k.hashCode() % objects.length;Entry<K, V> oldEntry = objects[index];// 判断是否存在if (oldEntry == null) {objects[index] = new Entry<>(k, v);} else {// 发生hash碰撞则存放到链表后面oldEntry.next = new Entry<>(k, v);}}public V get(K k) {
// if (k == null) {
// for (Entry<K, V> oldEntry = objects[0]; oldEntry != null; oldEntry = oldEntry.next) {
// if (oldEntry.k.equals(k)) {
// return oldEntry.v;
// }
// }
// }int index = k == null ? 0 : k.hashCode() % objects.length;for (Entry<K, V> oldEntry = objects[index]; oldEntry != null; oldEntry = oldEntry.next) {if (oldEntry.k == null || oldEntry.k.equals(k)) {return oldEntry.v;}}return null;}public static void main(String[] args) {ExtHashMap<Object, String> hashMap = new ExtHashMap<>();hashMap.put("a", "a");hashMap.put(97, "97");hashMap.put(null, "nulldemo");System.out.println(hashMap.get(97));}
}3. HashMap底层是有序存放的吗?
无序、散列存放
遍历的时候从数组0开始遍历每个链表,遍历结果存储顺序不保证一致。
如果需要根据存储顺序保存,可以使用LinkedHashMap底层是基于双向链表存放
LinkedHashMap基于双向链表实现
HashMap基本单向链表实现
4. LinkedHashMap实现缓存淘汰框架
LRU(最近少使用)缓存淘汰算法
LFU(最不经常使用算法)缓存淘汰算法
ARC(自适应缓存替换算法)缓存淘汰算法
FIFO(先进先出算法)缓存淘汰算法
MRU(最近最常使用算法)缓存淘汰算法
LinkedHashMap基于双向链表实现,可以分为插入或者访问顺序两种,采用双链表的形式保证有序
可以根据插入或者读取顺序
LinkedHashMap是HashMap的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。LinkedHashMap支持两种顺序插入顺序 、 访问顺序
插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序
执行get/put操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
其中参数accessOrder就是用来指定是否按访问顺序,如果为true,就是访问顺序,false根据新增顺序
public class LruCache<K, V> extends LinkedHashMap<K, V> {/*** 容量*/private int capacity;public LruCache(int capacity) {super(capacity, 0.75f, true);this.capacity = capacity;}/*** 如果超过存储容量则清除第一个** @param eldest* @return*/@Overrideprotected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > capacity;}public static void main(String[] args) {LruCache<String, String> lruCache = new LruCache<>(3);lruCache.put("a", "a");lruCache.put("b", "b");lruCache.put("c", "c");// ca elruCache.get("a");//caelruCache.put("e", "demo");lruCache.forEach((k, v) -> {System.out.println(k + "," + v);});}
}5. HashMap如何降低Hash冲突概率
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
((p = tab[i = (n - 1) & hash])1、保证不会发生数组越界
首先我们要知道的是,在HashMap,数组的长度按规定一定是2的幂。因此,数组的长度的二进制形式是:10000…000, 1后面有偶数个0。 那么,length - 1 的二进制形式就是01111.111, 0后面有偶数个1。最高位是0, 和hash值相“与”,结果值一定不会比数组的长度值大,因此也就不会发生数组越界。一个哈希值是8,二进制是1000,一个哈希值是9,二进制是1001。和1111“与”运算后,结果分别是1000和1001,它们被分配在了数组的不同位置,这样,哈希的分布非常均匀。
6. HashMap源码解读
6.1 modCount的作用
我们知道 java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount 顾名思义就是修改次数,对HashMap 内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount。在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map:
6.2 HashMap7扩容产生死循环问题
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}
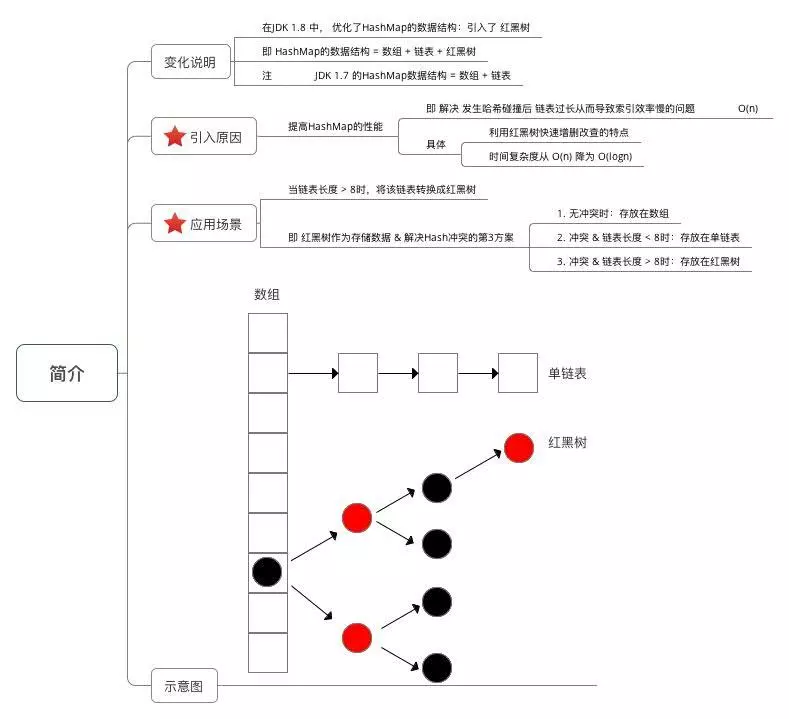
}6.3 HashMap8扩容底层原理
将原来的链表拆分两个链表存放; 低位还是存放原来index位置 高位存放index=j+原来长度
if ((e.hash & oldCap) == 0) { 由于oldCap原来的容量没有减去1 所以所有的hash&oldCap
为0或者1;
6.4 HashMap加载因子为什么是0.75而不是1或者0.5
产生背景:减少Hash冲突index的概率;
查询效率与空间问题;
简单推断的情况下,提前做扩容:
- 如果加载因子越大,空间利用率比较高,有可能冲突概率越大;
- 如果加载因子越小,有可能冲突概率比较小,空间利用率不高;
空间和时间上平衡点:0.75
统计学概率:泊松分布是统计学和概率学常见的离散概率分布
6.5 HashMap如何存放1万条key效率最高
参考阿里巴巴官方手册:

6.6 为什么JDK官方不承认Jdk7扩容死循环Bug问题
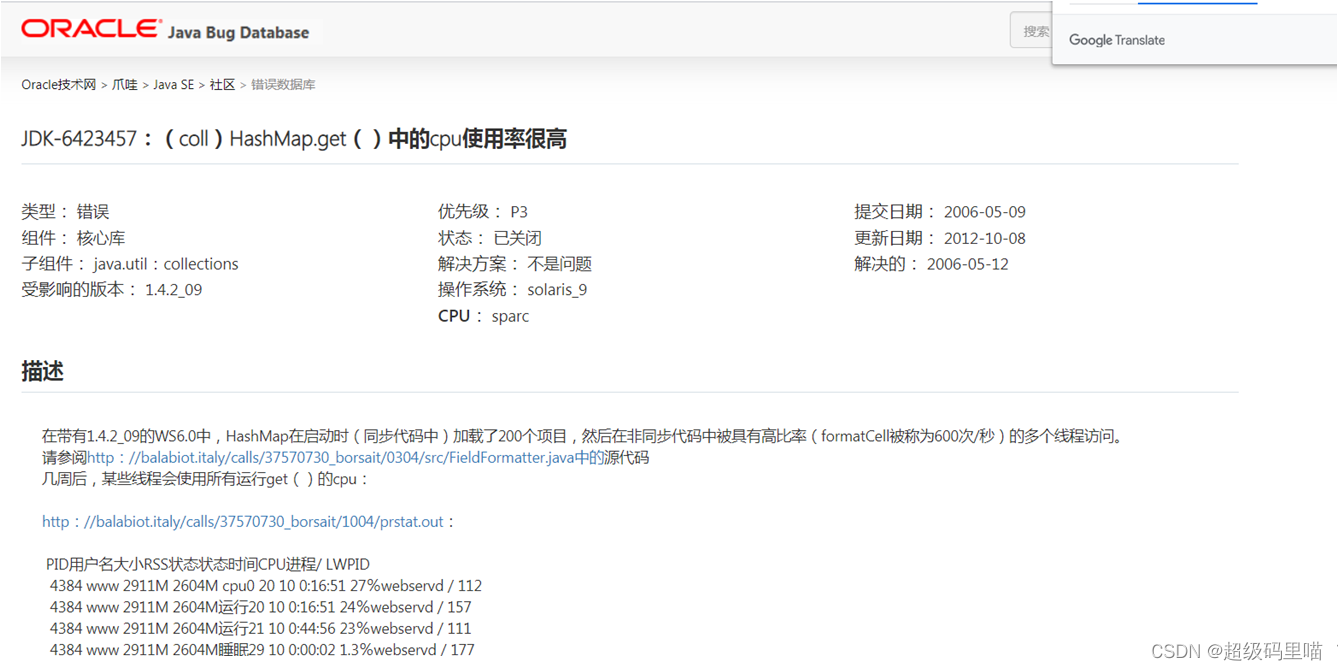
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6423457
7. ConcurrentHashMap源码解读
7.1 JDK1.7ConcurrentHashMap源码解读
使用传统HashTable保证线程问题,是采用synchronized锁将整个HashTable中的数组锁住,
在多个线程中只允许一个线程访问Put或者Get,效率非常低,但是能够保证线程安全问题。
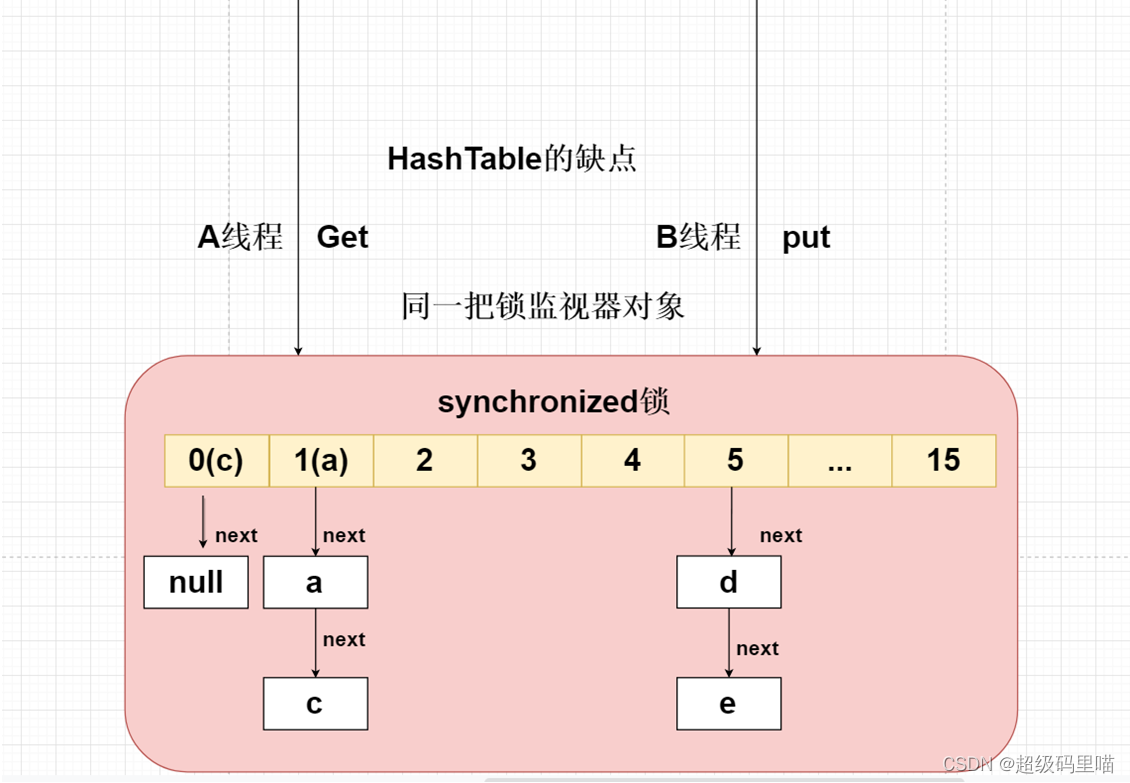
Jdk官方不推荐在多线程的情况下使用HashTable或者HashMap,建议使用ConcurrentHashMap分段HashMap。
效率非常高。
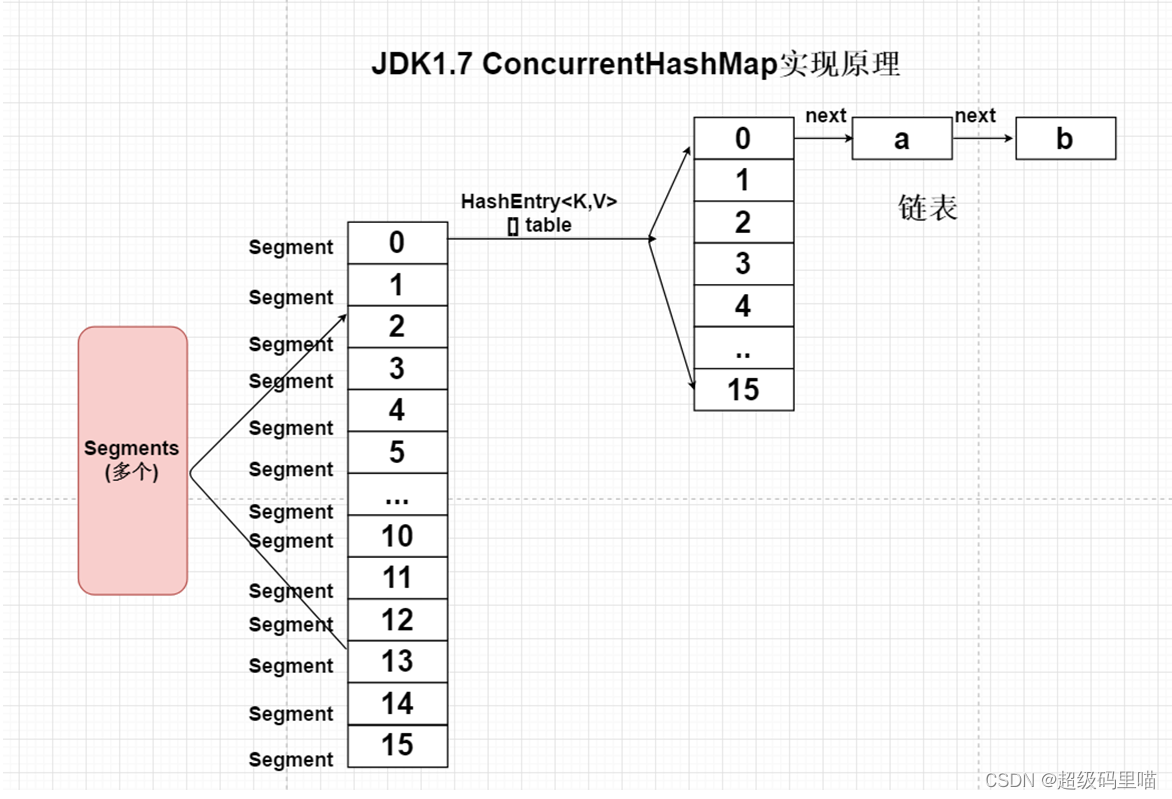
ConcurrentHashMap将一个大的HashMap集合拆分成n多个不同的小的HashTable(Segment),默认的情况下是分成16个不同的
Segment。每个Segment中都有自己独立的HashEntry<K,V>[] table;
7.1.1 简单实现ConcurrentHashMap
public class MyConcurrentHashMap<K, V> {private Hashtable<K, V>[] segments;public MyConcurrentHashMap() {segments = new Hashtable[16];}public void put(K k, V v) {int segmentIndex = k.hashCode() & segments.length - 1;Hashtable hashtable = segments[segmentIndex];if (hashtable == null) {hashtable = new Hashtable<K, V>();}hashtable.put(k, v);segments[segmentIndex] = hashtable;}public V get(K k) {int segmentIndex = k.hashCode() & segments.length - 1;Hashtable<K, V> hashtable = segments[segmentIndex];if (hashtable != null) {return hashtable.get(k);}return null;}public static void main(String[] args) {MyConcurrentHashMap<String, String> concurrentHashMap = new MyConcurrentHashMap<>();
// concurrentHashMap.put("a", "a");
// concurrentHashMap.put("97", "97");for (int i = 0; i < 10; i++) {concurrentHashMap.put(i + "", i + "");}
// System.out.println(concurrentHashMap.get("97"));for (int i = 0; i < 10; i++) {System.out.println(concurrentHashMap.get(i + ""));}}}7.1.2 核心参数分析
##1.无参构造函数分析:
initialCapacity ---16
loadFactor HashEntry<K,V>[] table; 加载因子0.75
concurrencyLevel 并发级别 默认是16
##2. 并发级别是能够大于2的16次方
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
##3.sshift 左移位的次数 ssize 作用:记录segment数组大小int sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}
##4. segmentShift segmentMask:ssize - 1 做与运算的时候能够将key均匀存放;this.segmentShift = 32 - sshift;this.segmentMask = ssize - 1;
##5. 初始化Segment0 赋值为下标0的位置
Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);
##6.采用CAS修改复制给Segment数组UNSAFE.putOrderedObject(ss, SBASE, s0); // or Put方法底层的实现 简单分析Segment<K,V> s;if (value == null)throw new NullPointerException();###计算key存放那个Segment数组下标位置;int hash = hash(key);int j = (hash >>> segmentShift28) & segmentMask15;###使用cas 获取Segment[10]对象 如果没有获取到的情况下,则创建一个新的segment对象if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegments = ensureSegment(j);### 使用lock锁对put方法保证线程安全问题return s.put(key, hash, value, false);0000 0000 00000 0000 0000 0000 0000 00110000 0000 00000 0000 0000 0000 0000 0011深度分析:
Segment<K,V> ensureSegment(int k) private Segment<K,V> ensureSegment(int k) {final Segment<K,V>[] ss = this.segments;long u = (k << SSHIFT) + SBASE; // raw offsetSegment<K,V> seg;### 使用UNSAFE强制从主内存中获取 Segment对象,如果没有获取到的情况=nullif ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {## 使用原型模式 将下标为0的Segment设定参数信息 赋值到新的Segment对象中Segment<K,V> proto = ss[0]; // use segment 0 as prototypeint cap = proto.table.length;float lf = proto.loadFactor;int threshold = (int)(cap * lf);HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];#### 使用UNSAFE强制从主内存中获取 Segment对象,如果没有获取到的情况=nullif ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheck###创建一个新的Segment对象Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {###使用CAS做修改if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;
}final V put(K key, int hash, V value, boolean onlyIfAbsent) {###尝试获取锁,如果获取到的情况下则自旋HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {HashEntry<K,V>[] tab = table;###计算该key存放的index下标位置int index = (tab.length - 1) & hash;HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {K k;###查找链表如果链表中存在该key的则修改if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;}else {if (node != null)node.setNext(first);else###创建一个新的node结点 头插入法node = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;###如果达到阈值提前扩容if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);elsesetEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}} finally {###释放锁unlock();}return oldValue;}7.1.3 核心Api
GetObjectVolatile
此方法和上面的getObject功能类似,不过附加了’volatile’加载语义,也就是强制从主存中获取属性值。类似的方法有getIntVolatile、getDoubleVolatile等等。这个方法要求被使用的属性被volatile修饰,否则功能和getObject方法相同。
tryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,这个方法无论如何都会立即返回。在拿不到锁时不会一直在那等待。
7.2 JDK1.8ConcurrentHashMap源码解读
ConcurrentHashMap1.8的取出取消segment分段设计,采用对CAS + synchronized保证并发线程安全问题,将锁的粒度拆分到每个index
下标位置,实现的效率与ConcurrentHashMap1.7相同。
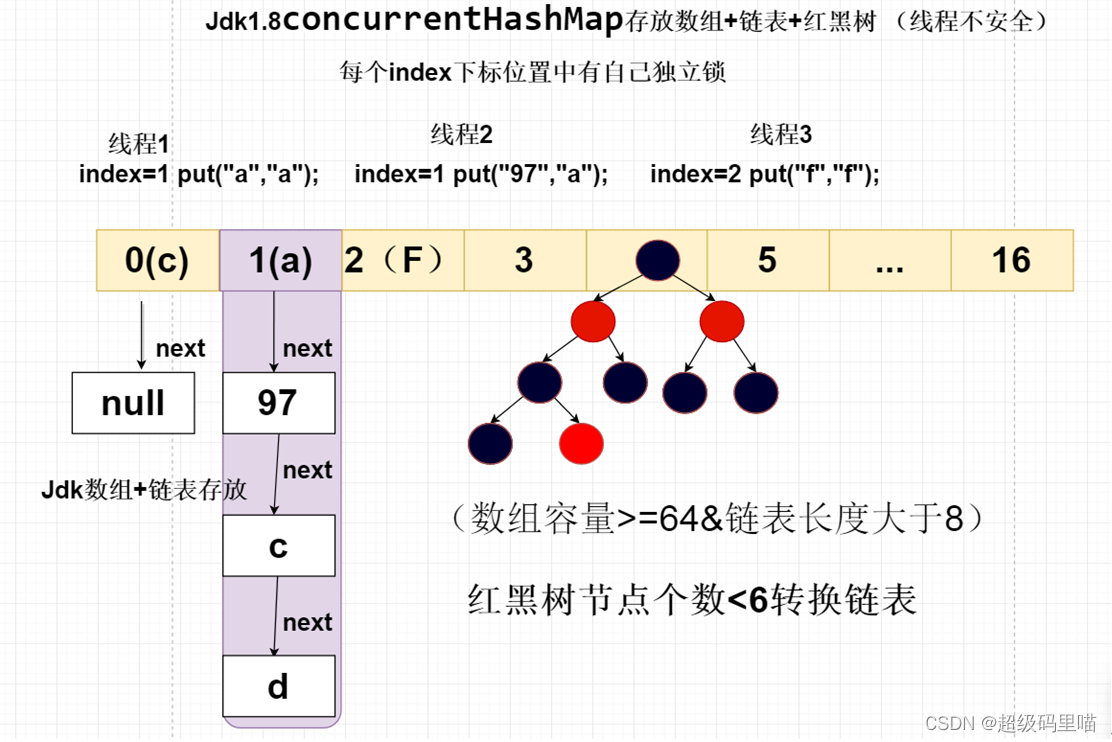
7.2.1 源码解读
sizeCtl :默认为0,用来控制table的初始化和扩容操作,具体应用在后续会体现出来。
-1 代表table正在初始化
N 表示有N-1个线程正在进行扩容操作
其余情况:
1、如果table未初始化,表示table需要初始化的大小。 0
2、如果table初始化完成,表示table的容量,默认是table大小的0.75倍,居然用这个公式算0.75(n - (n >>> 2))。
CounterCells 记录每个线程size++的次数
8. Arraylist集合源码解读
Arraylist底层是基于数组实现
System.arraycopy(elementData, index+1, elementData, index, numMoved);
Object src : 原数组
int srcPos : 从元数据的起始位置开始
Object dest : 目标数组
int destPos : 目标数组的开始起始位置
int length : 要copy的数组的长度
public class DemoArraylist<T> {/*** 存放数据元素*/private Object[] elementData;/*** 记录存放的个数*/private int size = 0;/*** 默认容量为10*/private static final int DEFAULT_CAPACITY = 10;public void add(T t) {if (elementData == null) {elementData = new Object[10];}// 判断是否需要扩容if ((size + 1) - elementData.length > 0) {// 原来容量10int oldCapacity = elementData.length;// 新的容量 10+5;int newCapacity = oldCapacity + (oldCapacity >> 1);// 扩容elementData = Arrays.copyOf(elementData, newCapacity);}elementData[size++] = t;}public T get(int index) {return (T) elementData[index];}public boolean remove(T value) {for (int i = 0; i < size; i++) {T oldValue = (T) elementData[i];if (oldValue.equals(value)) {int numMoved = size - i - 1;if (numMoved > 0)//removeSystem.arraycopy(elementData, i + 1, elementData, i,numMoved);elementData[--size] = null;return true;}}return false;}public static void main(String[] args) {DemoArraylist<String> arraylist = new DemoArraylist<>();for (int i = 0; i < 100; i++) {arraylist.add("demo" + i);}arraylist.remove("demo2");
// arraylist.add("demo11");for (int i = 0; i < arraylist.size; i++) {System.out.println(arraylist.get(i));}
//
// System.out.println(arraylist.get(0));}
}