看了下JAVA里面有HashMap、Hashtable、HashSet三种hash集合的实现源码,这里总结下,理解错误的地方还望指正
HashMap和Hashtable的区别
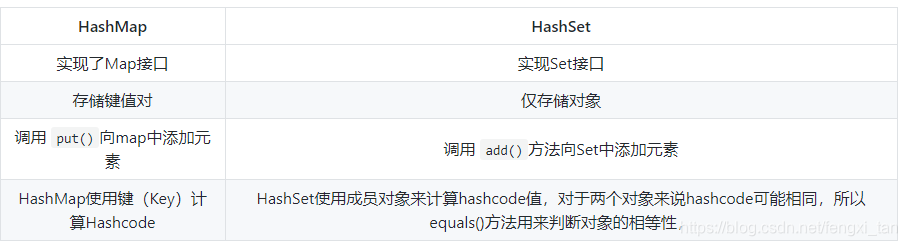
HashSet和HashMap、Hashtable的区别
HashMap和Hashtable的实现原理
HashMap的简化实现MyHashMap
HashMap和Hashtable的区别
- 两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全
Hashtable的实现方法里面都添加了synchronized关键字来确保线程同步,因此相对而言HashMap性能会高一些,我们平时使用时若无特殊需求建议使用HashMap,在多线程环境下若使用HashMap需要使用Collections.synchronizedMap()方法来获取一个线程安全的集合(Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的HashMap实例,简单的说就是Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理) - HashMap可以使用null作为key,而Hashtable则不允许null作为key
虽说HashMap支持null值作为key,不过建议还是尽量避免这样使用,因为一旦不小心使用了,若因此引发一些问题,排查起来很是费事
HashMap以null作为key时,总是存储在table数组的第一个节点上 - HashMap是对Map接口的实现,HashTable实现了Map接口和Dictionary抽象类
- HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1 - 两者计算hash的方法不同
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸

static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}static int indexFor(int h, int length) {return h & (length-1);} - HashMap和Hashtable的底层实现都是数组+链表结构实现
HashSet和HashMap、Hashtable的区别
除开HashMap和Hashtable外,还有一个hash集合HashSet,有所区别的是HashSet不是key value结构,仅仅是存储不重复的元素,相当于简化版的HashMap,只是包含HashMap中的key而已
通过查看源码也证实了这一点,HashSet内部就是使用HashMap实现,只不过HashSet里面的HashMap所有的value都是同一个Object而已,因此HashSet也是非线程安全的,至于HashSet和Hashtable的区别,HashSet就是个简化的HashMap的,所以你懂的
下面是HashSet几个主要方法的实现
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();public HashSet() {map = new HashMap<E,Object>();}public boolean contains(Object o) {return map.containsKey(o);}public boolean add(E e) {return map.put(e, PRESENT)==null;}public boolean add(E e) {return map.put(e, PRESENT)==null;}public boolean remove(Object o) {return map.remove(o)==PRESENT;}public void clear() {map.clear();}
HashMap和Hashtable的实现原理
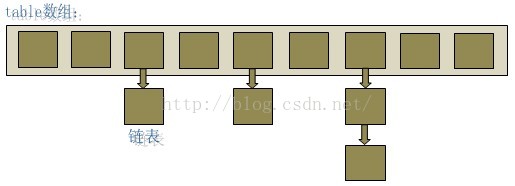
HashMap和Hashtable的底层实现都是数组+链表结构实现的,这点上完全一致
添加、删除、获取元素时都是先计算hash,根据hash和table.length计算index也就是table数组的下标,然后进行相应操作,下面以HashMap为例说明下它的简单实现
/*** HashMap的默认初始容量 必须为2的n次幂*/static final int DEFAULT_INITIAL_CAPACITY = 16;/*** HashMap的最大容量,可以认为是int的最大值 */static final int MAXIMUM_CAPACITY = 1 << 30;/*** 默认的加载因子*/static final float DEFAULT_LOAD_FACTOR = 0.75f;/*** HashMap用来存储数据的数组*/transient Entry[] table;- HashMap的创建
HashMap默认初始化时会创建一个默认容量为16的Entry数组,默认加载因子为0.75,同时设置临界值为16*0.75
/*** Constructs an empty <tt>HashMap</tt> with the default initial capacity* (16) and the default load factor (0.75).*/public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);table = new Entry[DEFAULT_INITIAL_CAPACITY];init();} - put方法
HashMap会对null值key进行特殊处理,总是放到table[0]位置
put过程是先计算hash然后通过hash与table.length取摸计算index值,然后将key放到table[index]位置,当table[index]已存在其它元素时,会在table[index]位置形成一个链表,将新添加的元素放在table[index],原来的元素通过Entry的next进行链接,这样以链表形式解决hash冲突问题,当元素数量达到临界值(capactiy*factor)时,则进行扩容,是table数组长度变为table.length*2 -
public V put(K key, V value) {if (key == null)return putForNullKey(value); //处理null值int hash = hash(key.hashCode());//计算hashint i = indexFor(hash, table.length);//计算在数组中的存储位置//遍历table[i]位置的链表,查找相同的key,若找到则使用新的value替换掉原来的oldValue并返回oldValuefor (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}//若没有在table[i]位置找到相同的key,则添加key到table[i]位置,新的元素总是在table[i]位置的第一个元素,原来的元素后移modCount++;addEntry(hash, key, value, i);return null;}void addEntry(int hash, K key, V value, int bucketIndex) {//添加key到table[bucketIndex]位置,新的元素总是在table[bucketIndex]的第一个元素,原来的元素后移Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//判断元素个数是否达到了临界值,若已达到临界值则扩容,table长度翻倍if (size++ >= threshold)resize(2 * table.length);} - get方法
同样当key为null时会进行特殊处理,在table[0]的链表上查找key为null的元素
get的过程是先计算hash然后通过hash与table.length取摸计算index值,然后遍历table[index]上的链表,直到找到key,然后返回
public V get(Object key) {if (key == null)return getForNullKey();//处理null值int hash = hash(key.hashCode());//计算hash//在table[index]遍历查找key,若找到则返回value,找不到返回nullfor (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k)))return e.value;}return null;} - remove方法
remove方法和put get类似,计算hash,计算index,然后遍历查找,将找到的元素从table[index]链表移除
public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);return (e == null ? null : e.value);}final Entry<K,V> removeEntryForKey(Object key) {int hash = (key == null) ? 0 : hash(key.hashCode());int i = indexFor(hash, table.length);Entry<K,V> prev = table[i];Entry<K,V> e = prev;while (e != null) {Entry<K,V> next = e.next;Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {modCount++;size--;if (prev == e)table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}return e;} - resize方法
resize方法在hashmap中并没有公开,这个方法实现了非常重要的hashmap扩容,具体过程为:先创建一个容量为table.length*2的新table,修改临界值,然后把table里面元素计算hash值并使用hash与table.length*2重新计算index放入到新的table里面
这里需要注意下是用每个元素的hash全部重新计算index,而不是简单的把原table对应index位置元素简单的移动到新table对应位置
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(newTable);table = newTable;threshold = (int)(newCapacity * loadFactor);}void transfer(Entry[] newTable) {Entry[] src = table;int newCapacity = newTable.length;for (int j = 0; j < src.length; j++) {Entry<K,V> e = src[j];if (e != null) {src[j] = null; do {Entry<K,V> next = e.next;
//重新对每个元素计算index int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;} while (e != null);}}} - clear()方法
clear方法非常简单,就是遍历table然后把每个位置置为null,同时修改元素个数为0
需要注意的是clear方法只会清楚里面的元素,并不会重置capactiy
public void clear() {modCount++;Entry[] tab = table;for (int i = 0; i < tab.length; i++)tab[i] = null;size = 0;} - containsKey和containsValue
containsKey方法是先计算hash然后使用hash和table.length取摸得到index值,遍历table[index]元素查找是否包含key相同的值
public boolean containsKey(Object key) {return getEntry(key) != null;} final Entry<K,V> getEntry(Object key) {int hash = (key == null) ? 0 : hash(key.hashCode());for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;} containsValue方法就比较粗暴了,就是直接遍历所有元素直到找到value,由此可见HashMap的containsValue方法本质上和普通数组和list的contains方法没什么区别,你别指望它会像containsKey那么高效
public boolean containsValue(Object value) {if (value == null)return containsNullValue();Entry[] tab = table;for (int i = 0; i < tab.length ; i++)for (Entry e = tab[i] ; e != null ; e = e.next)if (value.equals(e.value))return true;return false;} - hash和indexFor
indexFor中的h & (length-1)就相当于h%length,用于计算index也就是在table数组中的下标
hash方法是对hashcode进行二次散列,以获得更好的散列值
为了更好理解这里我们可以把这两个方法简化为 int index= key.hashCode()/table.length,以put中的方法为例可以这样替换int hash = hash(key.hashCode());//计算hash int i = indexFor(hash, table.length);//计算在数组中的存储位置 //上面这两行可以这样简化 int i = key.key.hashCode()%table.length; -
static int hash(int h) {// This function ensures that hashCodes that differ only by// constant multiples at each bit position have a bounded// number of collisions (approximately 8 at default load factor).h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}static int indexFor(int h, int length) {return h & (length-1);}
HashMap的简化实现MyHashMap
为了加深理解,我个人实现了一个简化版本的HashMap,注意哦,仅仅是简化版的功能并不完善,仅供参考

package cn.lzrabbit.structure;/*** Created by rabbit on 14-5-4.*/
public class MyHashMap {//默认初始化大小 16private static final int DEFAULT_INITIAL_CAPACITY = 16;//默认负载因子 0.75private static final float DEFAULT_LOAD_FACTOR = 0.75f;//临界值private int threshold;//元素个数private int size;//扩容次数private int resize;private HashEntry[] table;public MyHashMap() {table = new HashEntry[DEFAULT_INITIAL_CAPACITY];threshold = (int) (DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);size = 0;}private int index(Object key) {//根据key的hashcode和table长度取模计算key在table中的位置return key.hashCode() % table.length;}public void put(Object key, Object value) {//key为null时需要特殊处理,为简化实现忽略null值if (key == null) return;int index = index(key);//遍历index位置的entry,若找到重复key则更新对应entry的值,然后返回HashEntry entry = table[index];while (entry != null) {if (entry.getKey().hashCode() == key.hashCode() && (entry.getKey() == key || entry.getKey().equals(key))) {entry.setValue(value);return;}entry = entry.getNext();}//若index位置没有entry或者未找到重复的key,则将新key添加到table的index位置
add(index, key, value);}private void add(int index, Object key, Object value) {//将新的entry放到table的index位置第一个,若原来有值则以链表形式存放HashEntry entry = new HashEntry(key, value, table[index]);table[index] = entry;//判断size是否达到临界值,若已达到则进行扩容,将table的capacicy翻倍if (size++ >= threshold) {resize(table.length * 2);}}private void resize(int capacity) {if (capacity <= table.length) return;HashEntry[] newTable = new HashEntry[capacity];//遍历原table,将每个entry都重新计算hash放入newTable中for (int i = 0; i < table.length; i++) {HashEntry old = table[i];while (old != null) {HashEntry next = old.getNext();int index = index(old.getKey());old.setNext(newTable[index]);newTable[index] = old;old = next;}}//用newTable替tabletable = newTable;//修改临界值threshold = (int) (table.length * DEFAULT_LOAD_FACTOR);resize++;}public Object get(Object key) {//这里简化处理,忽略null值if (key == null) return null;HashEntry entry = getEntry(key);return entry == null ? null : entry.getValue();}public HashEntry getEntry(Object key) {HashEntry entry = table[index(key)];while (entry != null) {if (entry.getKey().hashCode() == key.hashCode() && (entry.getKey() == key || entry.getKey().equals(key))) {return entry;}entry = entry.getNext();}return null;}public void remove(Object key) {if (key == null) return;int index = index(key);HashEntry pre = null;HashEntry entry = table[index];while (entry != null) {if (entry.getKey().hashCode() == key.hashCode() && (entry.getKey() == key || entry.getKey().equals(key))) {if (pre == null) table[index] = entry.getNext();else pre.setNext(entry.getNext());//如果成功找到并删除,修改sizesize--;return;}pre = entry;entry = entry.getNext();}}public boolean containsKey(Object key) {if (key == null) return false;return getEntry(key) != null;}public int size() {return this.size;}public void clear() {for (int i = 0; i < table.length; i++) {table[i] = null;}this.size = 0;}@Overridepublic String toString() {StringBuilder sb = new StringBuilder();sb.append(String.format("size:%s capacity:%s resize:%s\n\n", size, table.length, resize));for (HashEntry entry : table) {while (entry != null) {sb.append(entry.getKey() + ":" + entry.getValue() + "\n");entry = entry.getNext();}}return sb.toString();}
}class HashEntry {private final Object key;private Object value;private HashEntry next;public HashEntry(Object key, Object value, HashEntry next) {this.key = key;this.value = value;this.next = next;}public Object getKey() {return key;}public Object getValue() {return value;}public void setValue(Object value) {this.value = value;}public HashEntry getNext() {return next;}public void setNext(HashEntry next) {this.next = next;}
}