引出: 条件概率 理解为 一对应无限 的函数 上的一个自变量点的情况
p ( x ∣ y ) p(x|y) p(x∣y)是有多种解释的 或者 是隐含了具体应用情况的,
以下内容大概在说:
条件概率 p ( x ∣ y ) p(x|y) p(x∣y) 是 一对应无限映射x(y) 的 一种数学定量描述办法。
( 一对应无限映射x(y) 这种函数并不那么容易描述吧,对比之下 一 一映射当然更容易描述 )
详细展开:
以下将条件概率分布 p ( x ∣ y ) p(x|y) p(x∣y)解释为
以一 对应 无穷 的函数
且
给任意某一对(x,y)一个数值来描述其可能性(该可能性即概率,该可能性实际上是描述该x对应到该y却不对应到其他y的程度)
函数映射一般是单射或有限射, y=f(x) : 一个x只能对应有限个y,这才是函数(一个x对应多个y 可以用分段函数来表达, 但是总不能写无限个分段来表达无限吧);
但是如果y=f(x)中 一个x对应了无穷多个y,应该用什么来描述? 比如x=a点对应了无穷多个y,如何表达?就用 p ( y ∣ x = a ) p(y|x=a) p(y∣x=a)这样一个条件概率分布来表达。由此可见条件概率分布是对函数的扩展和弥补。
以下HMM中隐状态转移概率 p ( h t ∣ h t − 1 = b ) p(h_t|h_{t-1}=b) p(ht∣ht−1=b)表达的其实就是在 h t − 1 = b h_{t-1}=b ht−1=b点的 一对应无穷 的函数f: q t = f ( h t − 1 ) q_t=f(h_{t-1}) qt=f(ht−1), 所以条件概率的条件部分 h t − 1 h_{t-1} ht−1其实相当于函数f的自变量 而条件概率的随机变量部分 h t h_t ht其实相当于函数f的应变量
在这里准确的描述是: 条件概率分布 p ( h t ∣ h t − 1 = b ) p(h_t|h_{t-1}=b) p(ht∣ht−1=b)可以描述 一对应无穷 的函数f: h t = f ( h t − 1 ) h_t=f(h_{t-1}) ht=f(ht−1) 在 自变量的一个点 h t − 1 = b h_{t-1}=b ht−1=b处 应变量 h t h_t ht取哪些值及各取值的可能性
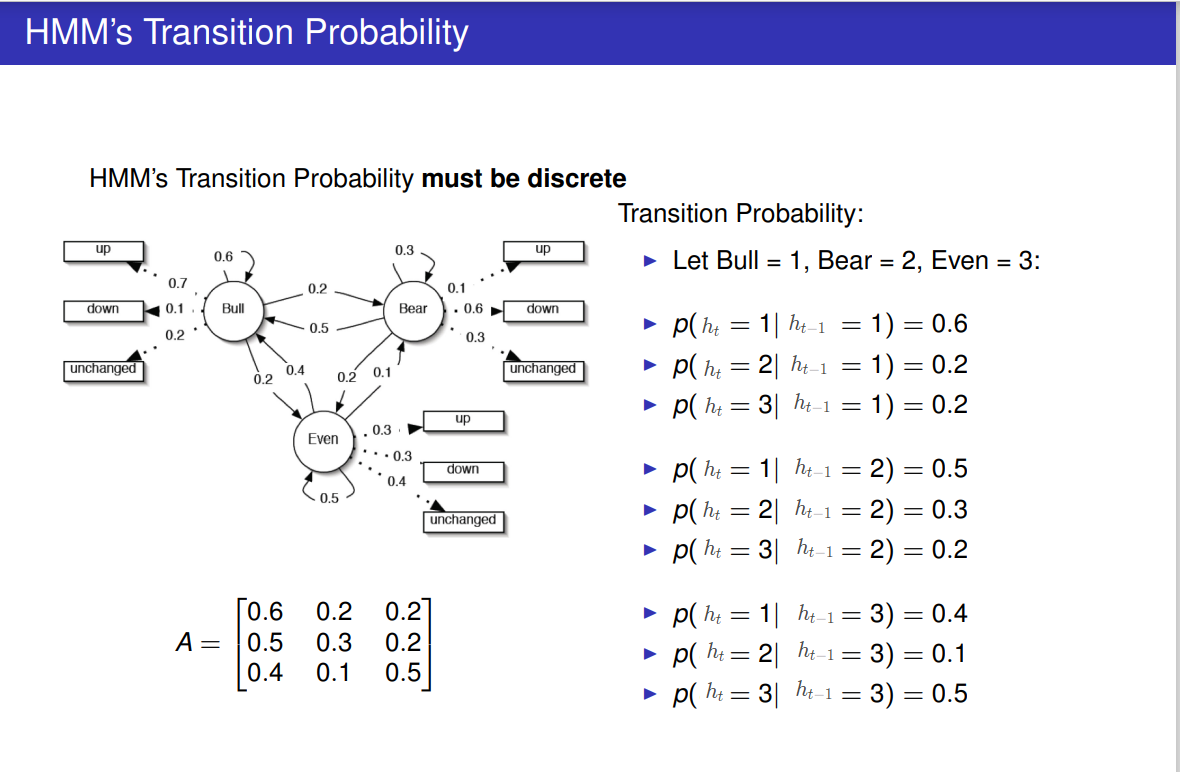
注意 上图我做过修改 ,
在原图中: q i q_i qi是 随机变量 (隐变量), 1、2、3是 该随机变量 的取值
而这里: h i h_i hi 是 随机变量(隐变量) , 1、2、3依然是 该随机变量 的取值
本文后续部分: h i h_i hi 是 随机变量(隐变量) , 而 s i s_i si 是 该随机变量 的取值 ; 即 q i q_i qi -> h i h_i hi,1、2、3 -> s i s_i si
条件概率 理解为 一对应无限 的函数 上的一个自变量点的情况
p ( x , y ) = p ( x ∣ y ) p ( y ) p(x,y)=p(x|y)p(y) p(x,y)=p(x∣y)p(y) ;条件概率定义
p ( x , y ) = p ( x ( y ) , y ) = p ( x ∣ y ) p ( y ) p(x,y)=p(x(y),y)=p(x|y)p(y) p(x,y)=p(x(y),y)=p(x∣y)p(y) ;上式条件概率定义 式子 是把x当成了y的 一对应无限 的函数:x=x(y), y是自变量,x是应变量
需要考虑的问题是,假如x并不是y的函数呢?
上式其实隐含了 :p(x(y)) 其实是 p(x|y)的另一个写法而已; p(x(z), y(z)) 其实是 p(x,y|z)的另一个写法而已;
即 : “x(y)” 即 “x|y” , “x(z), y(z)” 即 “x,y|z”
插入自由变量式:
p ( y ) = Σ x p ( y , x ) p(y)=\Sigma_{x} p(y,x) p(y)=Σxp(y,x) ; x是任意一个自由变量, x取遍所有x能取的值;
条件下插入自由变量式:
p ( y ( z ) ) = Σ x ( z ) p ( y ( z ) , x ( z ) ) p(y(z))=\Sigma_{x(z)} p(y(z),x(z)) p(y(z))=Σx(z)p(y(z),x(z)) ; 如果x、y均是z的 一对应无限 的函数: x=x(z), y=y(z) , 依然有类似 “插入自由变量式” 的式子
上式子可以写作: p ( y ∣ z ) = Σ x p ( y , x ∣ z ) p(y|z)=\Sigma_{x} p(y,x|z) p(y∣z)=Σxp(y,x∣z)
条件概率画图

hmm
变量用词说明
以 h表示隐状态随机变量,
h 1 h_1 h1即时刻1的隐状态随机变量 ,
h 2 h_2 h2即时刻2的隐状态随机变量 ,
…
h n h_n hn即时刻n的隐状态随机变量 ,
以 s 1 , s 2 , . . . , s k s_1, s_2, ..., s_k s1,s2,...,sk表示k个隐状态的取值
h i h_i hi可以取 s 1 , s 2 , . . . , s k s_1, s_2, ..., s_k s1,s2,...,sk中的任意一个值
如何表示 p ( y 1 , y 2 ) p(y_1,y_2) p(y1,y2), 答案是:
p ( y 1 , y 2 ) = Σ h 1 = q 1 q k Σ h 2 = q 1 q k ( p ( y 2 ∣ h 2 ) p ( y 1 ∣ h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=q_1}^{q_k} \Sigma_{h_2=q_1}^{q_k} ( p(y_2|h_2 )p(y_1|h_1 )p(h_2|h_1 )p(h_1) ) p(y1,y2)=Σh1=q1qkΣh2=q1qk(p(y2∣h2)p(y1∣h1)p(h2∣h1)p(h1)); 推导过程如下:
;推导 p ( y 1 ) p(y_1) p(y1):
p ( y 1 ) = Σ h 1 = s 1 s k p ( y 1 , h 1 ) = Σ h 1 = s 1 s k p ( y 1 ( h 1 ) , h 1 ) = Σ h 1 = s 1 s k ( p ( y 1 ∣ h 1 ) p ( h 1 ) ) p(y_1)=\Sigma_{h_1=s_1}^{s_k} p(y_1,h_1)=\Sigma_{h_1=s_1}^{s_k} p(y_1(h_1), h_1)=\Sigma_{h_1=s_1}^{s_k} ( p(y_1|h_1) p(h_1) ) p(y1)=Σh1=s1skp(y1,h1)=Σh1=s1skp(y1(h1),h1)=Σh1=s1sk(p(y1∣h1)p(h1)) ; 即:
p ( y 1 ) = Σ h 1 = s 1 s k ( p ( y 1 ∣ h 1 ) p ( h 1 ) ) p(y_1)=\Sigma_{h_1=s_1}^{s_k} ( p(y_1|h_1) p(h_1) ) p(y1)=Σh1=s1sk(p(y1∣h1)p(h1))
“推导 p ( y 1 ) p(y_1) p(y1)” 在 “推导 p ( y 1 , y 2 ) p(y_1, y_2) p(y1,y2)” 中并没有被直接用到,这里只是写在这而已
;推导 p ( y 1 , y 2 ) p(y_1, y_2) p(y1,y2):
;在 p ( y 1 , y 2 ) p(y_1, y_2) p(y1,y2) 中插入自由变量 h 2 h_2 h2,得:
p ( y 1 , y 2 ) = Σ h 2 = s 1 s k p ( y 1 ( h 2 ) , y 2 ( h 2 ) , h 2 ) p(y_1, y_2)=\Sigma_{h_2=s_1}^{s_k} p(y_1(h_2), y_2(h_2), h_2) p(y1,y2)=Σh2=s1skp(y1(h2),y2(h2),h2);再插入自由变量 h 1 h_1 h1,得:
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k p ( y 1 ( h 1 , h 2 ) , y 2 ( h 1 , h 2 ) , h 2 ( h 1 ) , h 1 ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} p(y_1(h_1,h_2), y_2(h_1,h_2), h_2(h_1),h_1 ) p(y1,y2)=Σh1=s1skΣh2=s1skp(y1(h1,h2),y2(h1,h2),h2(h1),h1);抽出 h 1 h_1 h1,得:
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k ( p ( y 1 ( h 2 ) , y 2 ( h 2 ) , h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \bigg( p(y_1(h_2), y_2(h_2), h_2|h_1 ) \quad p(h_1) \bigg) p(y1,y2)=Σh1=s1skΣh2=s1sk(p(y1(h2),y2(h2),h2∣h1)p(h1));再抽出 h 2 h_2 h2,得:
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k ( p ( y 1 , y 2 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \bigg( p(y_1, y_2|h_2,h_1 ) \quad p(h_2|h_1 ) \quad p(h_1) \bigg) p(y1,y2)=Σh1=s1skΣh2=s1sk(p(y1,y2∣h2,h1)p(h2∣h1)p(h1));将 y 2 y_2 y2当成 y 2 ( y 1 ) y_2(y_1) y2(y1) ,得:
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k ( p ( y 1 , y 2 ( y 1 ) ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \bigg( p(y_1, y_2(y_1)|h_2,h_1 ) \quad p(h_2|h_1 ) \quad p(h_1) \bigg) p(y1,y2)=Σh1=s1skΣh2=s1sk(p(y1,y2(y1)∣h2,h1)p(h2∣h1)p(h1));抽出 y 1 y_1 y1,得:
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k ( p ( y 2 ∣ h 2 , h 1 , y 1 ) p ( y 1 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \bigg( p(y_2|h_2,h_1,y_1 ) \quad p(y_1|h_2,h_1 ) \quad p(h_2|h_1 ) \quad p(h_1) \bigg) p(y1,y2)=Σh1=s1skΣh2=s1sk(p(y2∣h2,h1,y1)p(y1∣h2,h1)p(h2∣h1)p(h1)) ;根据hmm假设,有 “ y 2 ∣ y 1 , h 1 , h 2 y_2|y_1,h_1,h_2 y2∣y1,h1,h2” 即 “ y 2 ∣ h 2 y_2|h_2 y2∣h2” ,有 “ y 1 ∣ h 1 , h 2 y_1|h_1,h_2 y1∣h1,h2” 即 “ y 1 ∣ h 1 y_1|h_1 y1∣h1” :
p ( y 1 , y 2 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k ( p ( y 2 ∣ h 2 ) p ( y 1 ∣ h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2)= \Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \bigg( p(y_2|h_2 ) \quad p(y_1|h_1 ) \quad p(h_2|h_1 ) \quad p(h_1) \bigg) p(y1,y2)=Σh1=s1skΣh2=s1sk(p(y2∣h2)p(y1∣h1)p(h2∣h1)p(h1)) ;这里每一项都是hmm已知的;

;推导 p ( y 1 , y 2 , y 3 ) p(y_1, y_2, y_3) p(y1,y2,y3):
;在 p ( y 1 , y 2 , y 3 ) p(y_1, y_2, y_3) p(y1,y2,y3) 中 插入自由变量 h 3 h_3 h3,得:
p ( y 1 , y 2 , y 3 ) = Σ h 3 = s 1 s k p ( y 1 ( h 3 ) , y 2 ( h 3 ) , y 3 ( h 3 ) , h 3 ) p(y_1, y_2, y_3)=\Sigma_{h_3=s_1}^{s_k} p(y_1(h_3),y_2(h_3),y_3(h_3),h_3) p(y1,y2,y3)=Σh3=s1skp(y1(h3),y2(h3),y3(h3),h3);插入自由变量 h 2 h_2 h2,得:
p ( y 1 , y 2 , y 3 ) = Σ h 2 = s 1 s k Σ h 3 = s 1 s k p ( y 1 ( h 2 , h 3 ) , y 2 ( h 2 , h 3 ) , y 3 ( h 2 , h 3 ) , h 3 ( h 2 ) , h 2 ) p(y_1, y_2, y_3)=\Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} p(y_1(h_2,h_3),y_2(h_2,h_3),y_3(h_2,h_3),h_3(h_2),h_2) p(y1,y2,y3)=Σh2=s1skΣh3=s1skp(y1(h2,h3),y2(h2,h3),y3(h2,h3),h3(h2),h2);插入自由变量 h 1 h_1 h1,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k p ( y 1 ( h 1 , h 2 , h 3 ) , y 2 ( h 1 , h 2 , h 3 ) , y 3 ( h 1 , h 2 , h 3 ) , h 3 ( h 1 , h 2 ) , h 2 ( h 1 ) , h 1 ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} p(y_1(h_1,h_2,h_3),y_2(h_1,h_2,h_3),y_3(h_1,h_2,h_3),h_3(h_1,h_2),h_2(h_1),h_1) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1skp(y1(h1,h2,h3),y2(h1,h2,h3),y3(h1,h2,h3),h3(h1,h2),h2(h1),h1);抽出 h 1 h_1 h1,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 1 ( h 2 , h 3 ) , y 2 ( h 2 , h 3 ) , y 3 ( h 2 , h 3 ) , h 3 ( h 2 ) , h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg( p(y_1(h_2,h_3),y_2(h_2,h_3),y_3(h_2,h_3),h_3(h_2),h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y1(h2,h3),y2(h2,h3),y3(h2,h3),h3(h2),h2∣h1)p(h1));抽出 h 2 h_2 h2,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 1 ( h 3 ) , y 2 ( h 3 ) , y 3 ( h 3 ) , h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg( p(y_1(h_3),y_2(h_3),y_3(h_3),h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y1(h3),y2(h3),y3(h3),h3∣h2,h1)p(h2∣h1)p(h1));抽出 h 3 h_3 h3,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 1 , y 2 , y 3 ∣ h 3 , h 2 , h 1 ) p ( h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_1,y_2,y_3|h_3,h_2,h_1) \quad p(h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y1,y2,y3∣h3,h2,h1)p(h3∣h2,h1)p(h2∣h1)p(h1));将 y 3 y_3 y3当成 y 3 ( y 1 ) y_3(y_1) y3(y1) , y 2 y_2 y2当成 y 2 ( y 1 ) y_2(y_1) y2(y1) 得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 1 , y 2 ( y 1 ) , y 3 ( y 1 ) ∣ h 3 , h 2 , h 1 ) p ( h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_1,y_2(y_1),y_3(y_1)|h_3,h_2,h_1) \quad p(h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y1,y2(y1),y3(y1)∣h3,h2,h1)p(h3∣h2,h1)p(h2∣h1)p(h1));抽出 y 1 y_1 y1,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 2 , y 3 ∣ y 1 , h 3 , h 2 , h 1 ) p ( y 1 ∣ h 3 , h 2 , h 1 ) p ( h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_2,y_3|y_1,h_3,h_2,h_1) \quad p(y_1|h_3,h_2,h_1) \quad p(h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y2,y3∣y1,h3,h2,h1)p(y1∣h3,h2,h1)p(h3∣h2,h1)p(h2∣h1)p(h1));将 y 3 y_3 y3当成 y 3 ( y 2 ) y_3(y_2) y3(y2) ,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 2 , y 3 ( y 2 ) ∣ y 1 , h 3 , h 2 , h 1 ) p ( y 1 ∣ h 3 , h 2 , h 1 ) p ( h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_2,y_3(y_2)|y_1,h_3,h_2,h_1) \quad p(y_1|h_3,h_2,h_1) \quad p(h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y2,y3(y2)∣y1,h3,h2,h1)p(y1∣h3,h2,h1)p(h3∣h2,h1)p(h2∣h1)p(h1));抽出 y 2 y_2 y2,得:
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 3 ∣ y 2 , y 1 , h 3 , h 2 , h 1 ) p ( y 2 ∣ y 1 , h 3 , h 2 , h 1 ) p ( y 1 ∣ h 3 , h 2 , h 1 ) p ( h 3 ∣ h 2 , h 1 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_3|y_2,y_1,h_3,h_2,h_1) \quad p(y_2|y_1,h_3,h_2,h_1) \quad p(y_1|h_3,h_2,h_1) \quad p(h_3|h_2,h_1) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y3∣y2,y1,h3,h2,h1)p(y2∣y1,h3,h2,h1)p(y1∣h3,h2,h1)p(h3∣h2,h1)p(h2∣h1)p(h1));根据hmm假设 :
p ( y 1 , y 2 , y 3 ) = Σ h 1 = s 1 s k Σ h 2 = s 1 s k Σ h 3 = s 1 s k ( p ( y 3 ∣ h 3 ) p ( y 2 ∣ h 2 ) p ( y 1 ∣ h 1 ) p ( h 3 ∣ h 2 ) p ( h 2 ∣ h 1 ) p ( h 1 ) ) p(y_1, y_2, y_3)=\Sigma_{h_1=s_1}^{s_k} \Sigma_{h_2=s_1}^{s_k} \Sigma_{h_3=s_1}^{s_k} \bigg ( p(y_3|h_3) \quad p(y_2|h_2) \quad p(y_1|h_1) \quad p(h_3|h_2) \quad p(h_2|h_1) \quad p(h_1) \bigg) p(y1,y2,y3)=Σh1=s1skΣh2=s1skΣh3=s1sk(p(y3∣h3)p(y2∣h2)p(y1∣h1)p(h3∣h2)p(h2∣h1)p(h1));这里每一项都是hmm已知的;

垃圾箱:
p ( y 1 , y 2 ) = Σ h 1 = q 1 q k Σ h 2 = q 1 q k p ( y 1 ( h 1 , h 2 ) , y 2 ( h 1 , h 2 ) , h 1 , h 2 ) p(y_1, y_2)=\Sigma_{h_1=q_1}^{q_k} \Sigma_{h_2=q_1}^{q_k} p(y_1(h_1,h_2), y_2(h_1,h_2), h_1,h_2) p(y1,y2)=Σh1=q1qkΣh2=q1qkp(y1(h1,h2),y2(h1,h2),h1,h2); 忽略
p ( y 1 , y 2 ) = Σ h 1 = q 1 q k Σ h 2 = q 1 q k ( p ( y 1 , y 2 ∣ h 1 , h 2 ) p ( h 1 , h 2 ) ) p(y_1, y_2)=\Sigma_{h_1=q_1}^{q_k} \Sigma_{h_2=q_1}^{q_k} ( p(y_1, y_2|h_1,h_2) p(h_1,h_2) ) p(y1,y2)=Σh1=q1qkΣh2=q1qk(p(y1,y2∣h1,h2)p(h1,h2)); 忽略
p ( y 1 , y 2 ) = Σ h 1 = q 1 q k p ( y 1 , y 2 ∣ h 1 ) p ( h 1 ) p(y_1, y_2)=\Sigma_{h_1=q_1}^{q_k} p(y_1, y_2|h_1)p( h_1) p(y1,y2)=Σh1=q1qkp(y1,y2∣h1)p(h1); 忽略
那么 请问 p ( y ∣ θ ) p(y|\theta) p(y∣θ) 也是相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ)) 吗?
问: p ( y ∣ θ ) p(y|\theta) p(y∣θ) 也是相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ)) ?
答: 是
目前所知道的 :
在 训练一个概率模型 的 过程中, 模型的参数 θ \theta θ 是变化的 , 即 θ \theta θ是变量 ,此时 p ( y ∣ θ ) p(y|\theta) p(y∣θ) 有讨论价值 。 p ( y ∣ θ ) p(y|\theta) p(y∣θ) 相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ))
即在训练过程中, p ( y ∣ θ ) p(y|\theta) p(y∣θ) 相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ)) 且 其中的 θ \theta θ不可省略 (因 θ \theta θ是变量)
当 模型训练完后 使用该模型 时, θ \theta θ 是 不变的,即 θ \theta θ是常量, 此时 p ( y ∣ θ ) p(y|\theta) p(y∣θ) 也相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ))。 很显然 y ( θ ) y(\theta) y(θ)中的 θ \theta θ是自变量,而此时该自变量 θ \theta θ是不变的 因此 该自变量 θ \theta θ可以省略。
即在验证或测试过程中, p ( y ∣ θ ) p(y|\theta) p(y∣θ) 也相当于 p ( y ( θ ) ) p(y(\theta)) p(y(θ)) 但 其中的 θ \theta θ可省略 (因 θ \theta θ是常量)





![[Pyhon疫情大数据分析] 四.微博话题抓取及新冠肺炎疫情文本挖掘和情感分析](https://img-blog.csdnimg.cn/20200321143724497.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Vhc3Rtb3VudA==,size_16,color_FFFFFF,t_70#pic_center)








