tar 命令可以将许多文件一起保存至一个单独的磁带或磁盘归档,并能从归档中单独还原所需文件。
示例
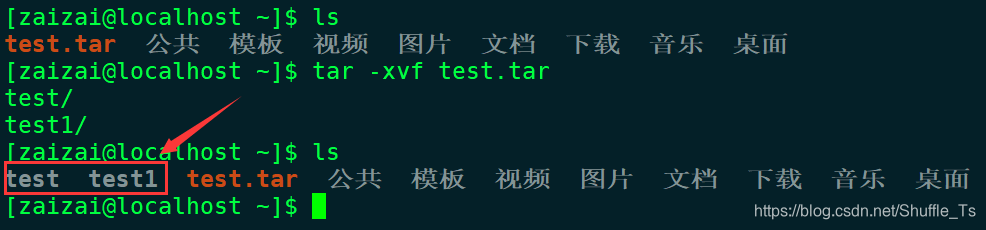
以test文件为例
压缩命令
tar -cvf test.tar test test1

解压命令
tar -xvf test.tar
主操作模式:
-A, --catenate, --concatenate 追加 tar 文件至归档
-c, --create 创建一个新归档-d, --diff, --compare 找出归档和文件系统的差异--delete 从归档(非磁带!)中删除-r, --append 追加文件至归档结尾-t, --list 列出归档内容--test-label 测试归档卷标并退出-u, --update 仅追加比归档中副本更新的文件-x, --extract, --get 从归档中解出文件
操作修饰符:
–check-device 当创建增量归档时检查设备号(默认)
-g, --listed-incremental=FILE 处理新式的 GNU 格式的增量备份-G, --incremental 处理老式的 GNU 格式的增量备份--ignore-failed-read当遇上不可读文件时不要以非零值退出--level=NUMBER 所创建的增量列表归档的输出级别
-n, --seek 归档可检索--no-check-device 当创建增量归档时不要检查设备号--no-seek 归档不可检索--occurrence[=NUMBER] 仅处理归档中每个文件的第 NUMBER个事件;仅当与以下子命令 --delete,--diff, --extract 或是 --list中的一个联合使用时,此选项才有效。而且不管文件列表是以命令行形式给出或是通过-T 选项指定的;NUMBER 值默认为 1--sparse-version=MAJOR[.MINOR]设置所用的离散格式版本(隐含--sparse)-S, --sparse 高效处理离散文件
重写控制:
-k, --keep-old-files don't replace existing files when extracting,treat them as errors--keep-directory-symlink preserve existing symlinks to directories whenextracting--keep-newer-files不要替换比归档中副本更新的已存在的文件--no-overwrite-dir 保留已存在目录的元数据--overwrite 解压时重写存在的文件--overwrite-dir 解压时重写已存在目录的元数据(默认)-U, --unlink-first 在解压要重写的文件之前先删除它们
-W, --verify 在写入以后尝试校验归档
选择输出流:
--ignore-command-error 忽略子进程的退出代码--no-ignore-command-error 将子进程的非零退出代码认为发生错误-O, --to-stdout 解压文件至标准输出--to-command=COMMAND 将解压的文件通过管道传送至另一个程序
操作文件属性:
–atime-preserve[=METHOD]
在输出的文件上保留访问时间,要么通过在读取(默认 METHOD=‘replace’)后还原时间,要不就不要在第一次(METHOD=‘system’)设置时间
--delay-directory-restore直到解压结束才设置修改时间和所解目录的权限--group=名称 强制将 NAME作为所添加的文件的组所有者--mode=CHANGES 强制将所添加的文件(符号)更改为权限CHANGES--mtime=DATE-OR-FILE 从 DATE-OR-FILE 中为添加的文件设置mtime
-m, --touch 不要解压文件的修改时间--no-delay-directory-restore取消 --delay-directory-restore 选项的效果--no-same-owner将文件解压为您所有(普通用户默认此项)--no-same-permissions从归档中解压权限时使用用户的掩码位(默认为普通用户服务)--numeric-owner 总是以数字代表用户/组的名称--owner=名称 强制将 NAME作为所添加的文件的所有者
-p, --preserve-permissions, --same-permissions解压文件权限信息(默认只为超级用户服务)--preserve 与 -p 和 -s 一样--same-owner尝试解压时保持所有者关系一致(超级用户默认此项)
-s, --preserve-order, --same-order member arguments are listed in the same order as the files in the archive
Handling of extended file attributes:
--acls Enable the POSIX ACLs support--no-acls Disable the POSIX ACLs support--no-selinux Disable the SELinux context support--no-xattrs Disable extended attributes support--selinux Enable the SELinux context support--xattrs Enable extended attributes support--xattrs-exclude=MASK specify the exclude pattern for xattr keys--xattrs-include=MASK specify the include pattern for xattr keys
设备选择和切换:
-f, --file=ARCHIVE 使用归档文件或 ARCHIVE 设备--force-local 即使归档文件存在副本还是把它认为是本地归档
-F, --info-script=名称--new-volume-script=名称在每卷磁带最后运行脚本(隐含 -M)
-L, --tape-length=NUMBER 写入 NUMBER × 1024 字节后更换磁带
-M, --multi-volume 创建/列出/解压多卷归档文件--rmt-command=COMMAND 使用指定的 rmt COMMAND 代替 rmt--rsh-command=COMMAND 使用远程 COMMAND 代替 rsh--volno-file=FILE 使用/更新 FILE 中的卷数
设备分块:
-b, --blocking-factor=BLOCKS 每个记录 BLOCKS x 512 字节
-B, --read-full-records 读取时重新分块(只对 4.2BSD 管道有效)
-i, --ignore-zeros 忽略归档中的零字节块(即文件结尾)--record-size=NUMBER 每个记录的字节数 NUMBER,乘以 512
选择归档格式:
-H, --format=FORMAT 创建指定格式的归档
FORMAT 是以下格式中的一种:
gnu GNU tar 1.13.x 格式
oldgnu GNU 格式 as per tar <= 1.12
pax POSIX 1003.1-2001 (pax) 格式
posix 等同于 pax
ustar POSIX 1003.1-1988 (ustar) 格式
v7 old V7 tar 格式--old-archive, --portability等同于 --format=v7--pax-option=关键字[[:]=值][,关键字 [[:]=值]]...控制 pax 关键字--posix 等同于 --format=posix
-V, --label=TEXT 创建带有卷名TEXT的归档;在列出/解压时,使用 TEXT作为卷名的模式串
压缩选项:
-a, --auto-compress 使用归档后缀名来决定压缩程序
-I, --use-compress-program=PROG通过 PROG 过滤(必须是能接受 -d选项的程序)
-j, --bzip2 通过 bzip2 过滤归档
-J, --xz 通过 xz 过滤归档--lzip 通过 lzip 过滤归档--lzma 通过 lzma 过滤归档--lzop--no-auto-compress 不使用归档后缀名来决定压缩程序
-z, --gzip, --gunzip, --ungzip 通过 gzip 过滤归档
-Z, --compress, --uncompress 通过 compress 过滤归档
本地文件选择:
--add-file=FILE 添加指定的 FILE 至归档(如果名字以 -开始会很有用的)--backup[=CONTROL] 在删除前备份,选择 CONTROL 版本
-C, --directory=DIR 改变至目录 DIR--exclude=PATTERN 排除以 PATTERN 指定的文件--exclude-backups 排除备份和锁文件--exclude-caches 除标识文件本身外,排除包含CACHEDIR.TAG 的目录中的内容--exclude-caches-all 排除包含 CACHEDIR.TAG 的目录--exclude-caches-under 排除包含 CACHEDIR.TAG 的目录中所有内容
--exclude-tag=FILE 除 FILE 自身外,排除包含 FILE的目录中的内容--exclude-tag-all=FILE 排除包含 FILE 的目录--exclude-tag-under=FILE 排除包含 FILE 的目录中的所有内容--exclude-vcs 排除版本控制系统目录
-h, --dereference 跟踪符号链接;将它们所指向的文件归档并输出--hard-dereference 跟踪硬链接;将它们所指向的文件归档并输出
-K, --starting-file=MEMBER-NAMEbegin at member MEMBER-NAME when reading thearchive--newer-mtime=DATE 当只有数据改变时比较数据和时间--no-null 禁用上一次的效果 --null 选项--no-recursion 避免目录中的自动降级--no-unquote 不以 -T 读取的文件名作为引用结束--null -T 读取以空终止的名字,-C 禁用
-N, --newer=DATE-OR-FILE, --after-date=DATE-OR-FILE 只保存比 DATE-OR-FILE 更新的文件--one-file-system 创建归档时保存在本地文件系统中
-P, --absolute-names 不要从文件名中清除引导符‘/’--recursion 目录递归(默认)--suffix=STRING 在删除前备份,除非被环境变量SIMPLE_BACKUP_SUFFIX覆盖,否则覆盖常用后缀(‘’)
-T, --files-from=FILE 从 FILE中获取文件名来解压或创建文件--unquote 以 -T读取的文件名作为引用结束(默认)
-X, --exclude-from=FILE 排除 FILE 中列出的模式串
文件名变换:
--strip-components=NUMBER 解压时从文件名中清除 NUMBER个引导部分--transform=EXPRESSION, --xform=EXPRESSION使用 sed 代替 EXPRESSION来进行文件名变换
文件名匹配选项(同时影响排除和包括模式串):
--anchored 模式串匹配文件名头部--ignore-case 忽略大小写--no-anchored 模式串匹配任意‘/’后字符(默认对exclusion 有效)--no-ignore-case 匹配大小写(默认)--no-wildcards 逐字匹配字符串--no-wildcards-match-slash 通配符不匹配‘/’--wildcards use wildcards (default)--wildcards-match-slash通配符匹配‘/’(默认对排除操作有效)
提示性输出:
--checkpoint[=NUMBER] 每隔 NUMBER个记录显示进度信息(默认为 10 个)--checkpoint-action=ACTION 在每个检查点上执行 ACTION--full-time print file time to its full resolution--index-file=FILE 将详细输出发送至 FILE
-l, --check-links只要不是所有链接都被输出就打印信息--no-quote-chars=STRING 禁用来自 STRING 的字符引用--quote-chars=STRING 来自 STRING 的额外的引用字符--quoting-style=STYLE 设置名称引用风格;有效的 STYLE值请参阅以下说明
-R, --block-number 每个信息都显示归档内的块数--show-defaults 显示 tar 默认选项--show-omitted-dirs 列表或解压时,列出每个不匹配查找标准的目录--show-transformed-names--show-stored-names 显示变换后的文件名或归档名--totals[=SIGNAL] 处理归档后打印出总字节数;当此SIGNAL 被触发时带参数-打印总字节数;允 许的信号为:SIGHUP,SIGQUIT,SIGINT,SIGUSR1 和SIGUSR2;同时也接 受不带 SIG前缀的信号名称--utc 以 UTC 格式打印文件修改时间
-v, --verbose 详细地列出处理的文件--warning=KEYWORD 警告控制:
-w, --interactive--confirmation 每次操作都要求确认兼容性选项:
-o 创建归档时,相当于--old-archive 展开归档时,相当于--no-same-owner
其他选项
-?, --help 显示帮助列表--restrict 禁用某些潜在的有危险的选项--usage 显示简短的用法说明--version 打印程序版本