用Java爬取网页图片——爬虫爬取数据
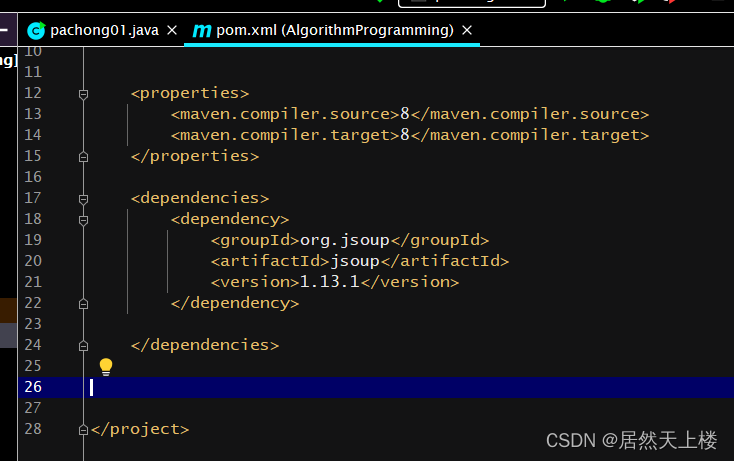
1、在创建项目中导入jsoup
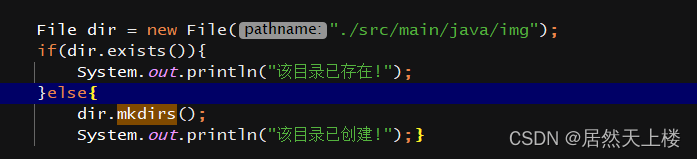
2、创建一个保存下载图片的路径
3、使用URL读取网页路径,jsoup读取网页内容
4、利用属性标签获取图片连接块
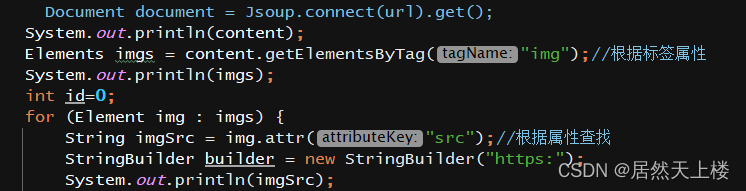
5、因为该路径没有http:头,用StringBuilder增加
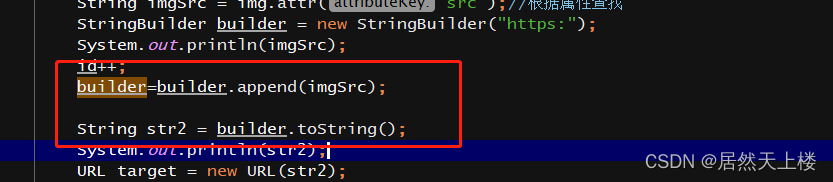
5、完善下载路径
## 点个关注、不迷路!!!
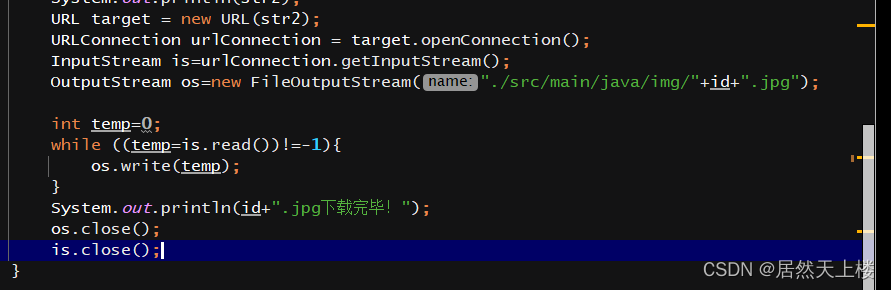
6、完整代码
public static void main(String[] args) throws IOException {File dir = new File("./src/main/java/img");if(dir.exists()){System.out.println("该目录已存在!");}else{dir.mkdirs();System.out.println("该目录已创建!");}String url ="https://www.nipic.com/topic/show_27202_1.html";Document document = Jsoup.parse(new URL(url), 100000);Element content = document.getElementById("img-list-outer");
// Document document = Jsoup.connect(url).get();System.out.println(content);Elements imgs = content.getElementsByTag("img");//根据标签属性System.out.println(imgs);int id=0;for (Element img : imgs) {String imgSrc = img.attr("src");//根据属性查找StringBuilder builder = new StringBuilder("https:");System.out.println(imgSrc);id++;builder=builder.append(imgSrc);String str2 = builder.toString();System.out.println(str2);URL target = new URL(str2);URLConnection urlConnection = target.openConnection();InputStream is=urlConnection.getInputStream();OutputStream os=new FileOutputStream("./src/main/java/img/"+id+".jpg");int temp=0;while ((temp=is.read())!=-1){os.write(temp);}System.out.println(id+".jpg下载完毕!");os.close();is.close();}}