包括MAE、Pre、Rec、F-measure、Auc、CC、Nss
MAE:
平均绝对误差MAE(mean absolute error),范围[0,+∞),当预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。
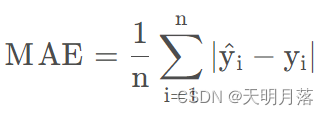
Pre、Rec、F-measure
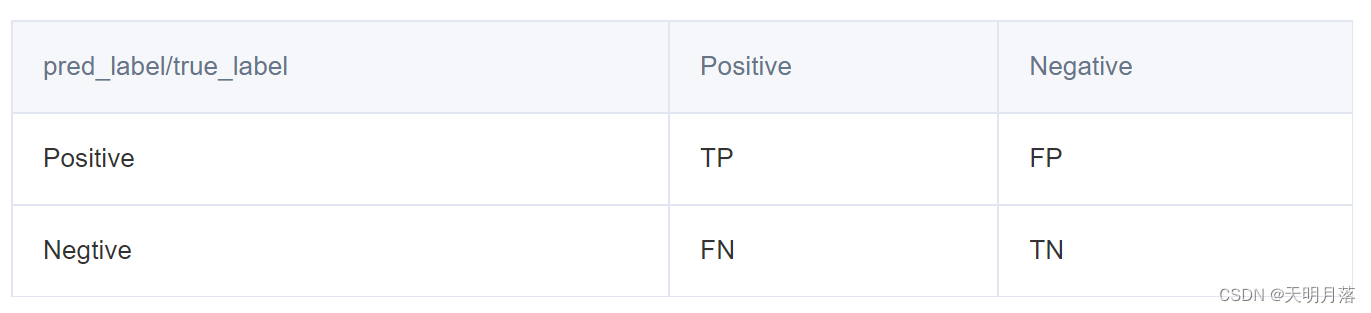
行表示预测的label值,列表示真实label值。TP,FP,FN,TN分别表示如下意思:
- TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;
- FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;
- FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;
- TN(true negative):表示样本的真实类别为负,最后预测得到的结果也为负.
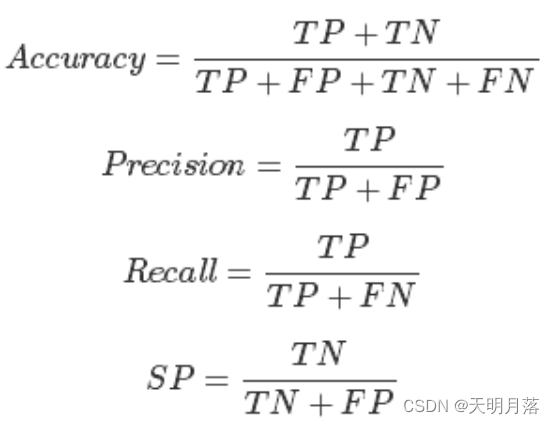
- Accuracy:表示预测结果的精确度,预测正确的样本数除以总样本数。
- precision,准确率,表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;
- recall,召回率,表示在原始样本的正样本中,最后被正确预测为正样本的概率;
- specificity,常常称作特异性,它研究的样本集是原始样本中的负样本,表示的是在这些负样本中最后被正确预测为负样本的概率。
F-Measure又称为F-Score,F-Measure是Precision和Recall加权调和平均
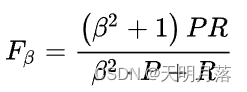
其中是参数,P是精确率(Precision),R是召回率(Recall)。当参数
=1时,就是最常见的F1-Measure了:
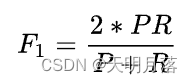
Auc
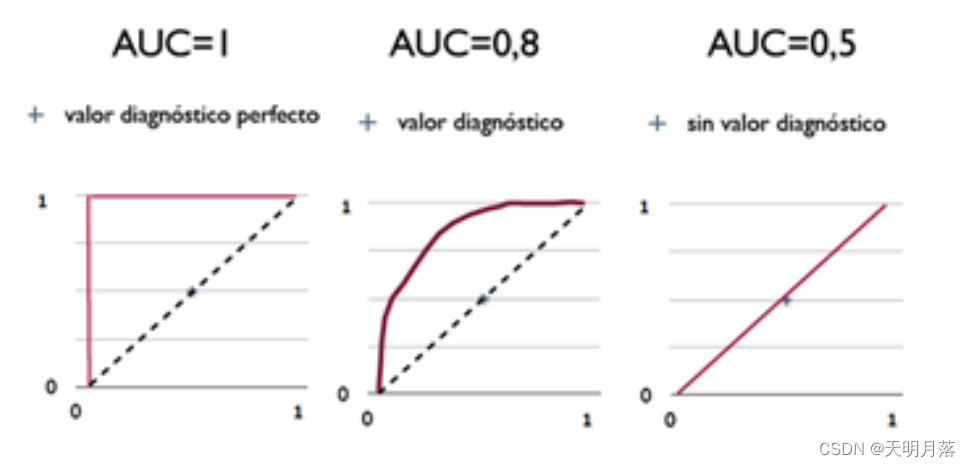
ROC曲线下方的面积(Area under the Curve of ROC (AUC ROC)),其意义是:
因为是在1x1的方格里求面积,AUC必在0~1之间。
假设阈值以上是阳性,以下是阴性;
若随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本之机率=AUC
简单说:AUC值越大的分类器,正确率越高。
CC
CC是指皮尔逊相关系数,用来评价预测的眼关注点显著图和参考图ground truth之间的线性相关性,CC越大说明该模型性能越好。
NSS
NSS是指标准化扫描路径显着性,用来评价两者之间的差异值,NSS越大说明模型性能越好。
Python代码
import numpy as np
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score
from sklearn.preprocessing import Binarizer
from scipy.stats import pearsonrdef mask_normalize(mask):mask = (mask - np.min(mask))/(np.max(mask) - np.min(mask) + 1e-8)return maskdef compute_mae(mask,label):h, w = mask.shape[0], mask.shape[1]sumError = np.sum(np.absolute((mask.astype(float) - label.astype(float))))maeError = sumError/(float(h)*float(w)+1e-8)return maeErrordef compute_p_r_f(mask,label):pre = precision_score(mask, label, average='binary')rec = recall_score(mask, label, average='binary')f_1 = f1_score(mask, label, average='binary')return pre, rec, f_1def compute_auc(mask,label):auc = roc_auc_score(mask,label)return aucdef compute_cc(mask,label):mask = mask - np.mean(mask)label = label - np.mean(label)cov = np.sum(mask * label)d1 = np.sum(mask * mask)d2 = np.sum(label * label)cc = cov / (np.sqrt(d1) * np.sqrt(d2) + 1e-8)return ccdef compute_nss(mask,label):std=np.std(mask)u=np.mean(mask)mask=(mask-u)/stdnss=mask*labelnss=np.sum(nss)/np.sum(label)return nssdef evaluate(mask,label):if len(mask.shape)==3:mask = mask[0]if len(label.shape)==3:label = label[0]mask = mask_normalize(mask)label = mask_normalize(label)mae = compute_mae(mask,label)binarizer = Binarizer(threshold=0.5)mask_b = binarizer.transform(mask)label_b = binarizer.transform(label)mask_br = np.reshape(mask_b, newshape=(-1))label_br = np.reshape(label_b, newshape=(-1))pre, rec, f_1 = compute_p_r_f(mask_br,label_br)auc = compute_auc(mask_br,label_br)cc = compute_cc(mask,label)nss = compute_nss(mask,label_b)return mae, pre, rec, f_1, auc, cc, nssfrom trans_evaluate import *
import glob
from skimage import io, transformdata_dir = '/data3/QHL/HSOD/output/SUDF/batch_bsal_result/'
gt_dir = '/data3/QHL/DATA/SOD/HL-SOD/ground_truth/'name_list = glob.glob(data_dir+'/'+'*.png')
img_num = len(name_list)mae, pre, rec, f_1, auc, cc, nss = 0, 0, 0, 0, 0, 0, 0
for i in range(img_num):name = name_list[i].split("/")[-1].split(".")[-2]image = io.imread(name_list[i])if len(image.shape) == 2:h,w = image.shape[0],image.shape[1]image = np.swapaxes(image, 1, 0)image = image.astype(np.float32)if len(image.shape) == 3:h,w,c = image.shape[0],image.shape[1],image.shape[2]image = np.swapaxes(image, 2, 0)image = image.astype(np.float32)label = io.imread(gt_dir + name + '.jpg')label = transform.resize(label, (h,w,3))label = np.swapaxes(label, 2, 0)label = label.astype(np.float32)mae_, pre_, rec_, f_1_, auc_, cc_, nss_ = evaluate(image, label)mae = mae + mae_pre = pre + pre_rec = rec + rec_f_1 = f_1 + f_1_auc = auc + auc_cc = cc + cc_nss = nss + nss_len = img_num
mae = mae / len
pre = pre / len
rec = rec / len
f_1 = f_1 / len
auc = auc / len
cc = cc / len
nss = nss / lenprint('pre, rec, f_1', pre, rec, f_1)
print('auc, cc, nss', auc, cc, nss)
print('mae',mae)