卡方分布
定义:设 X1…Xn是服从标准正态分布的随机变量,则称统计量

服从自由度为n的卡方分布,自由度为n时,他的期望是n,方差为2n
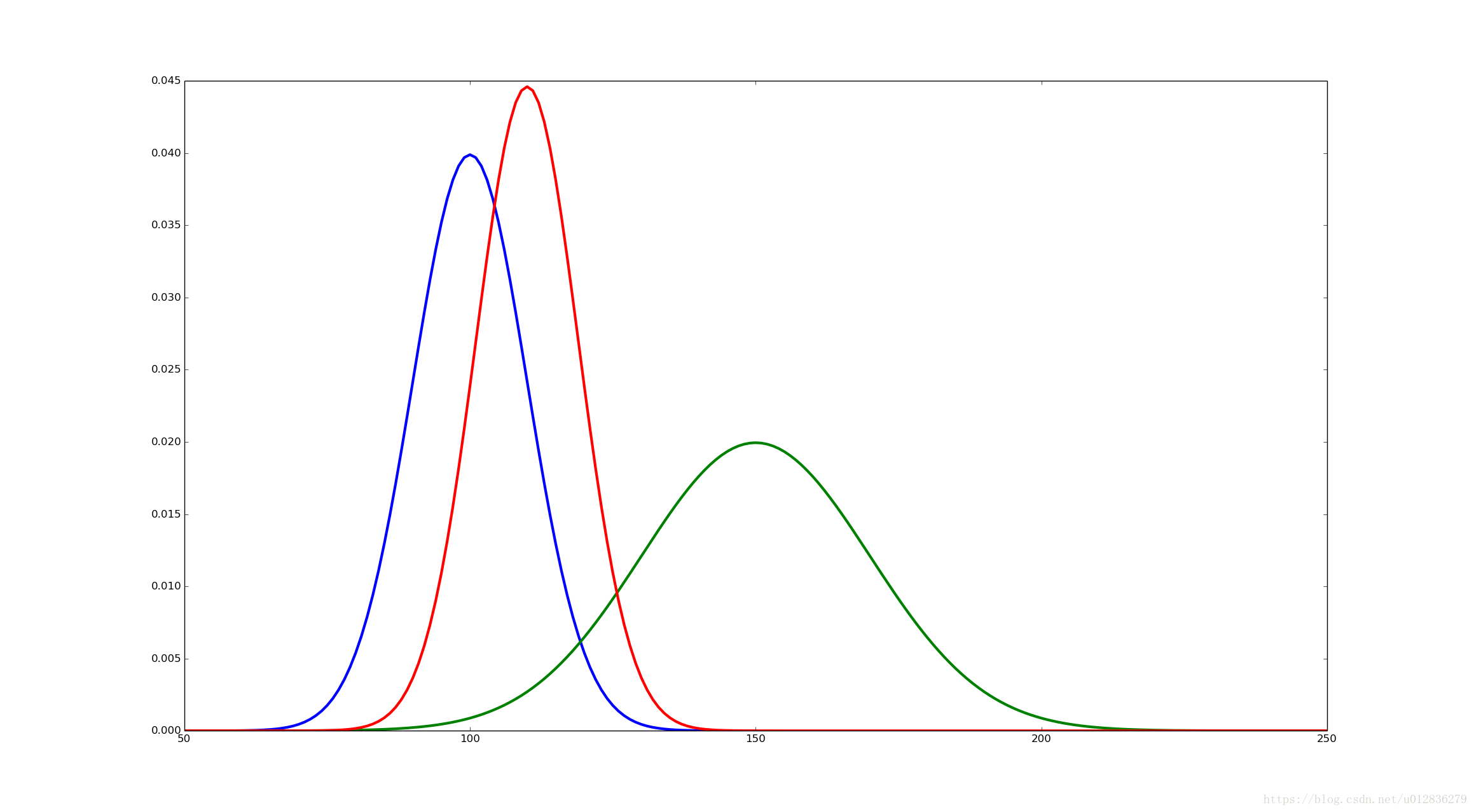
他是标准正态分布变量的平方和,网上找了一张概率密度图:

然后我很好奇的是,这张图怎么画出来的呢?
既然是正态分布的平方和,我就试一下弄几个正态分布平方和,看看图形是不是这个样子。
用Python代码
# 产生服从N(0,1)分布的1000个数
x1 = np.random.randn(1000)
y1 = np.power(x1,2)
一个一个产生太慢了,,用循环生产随机数:
# 给定一个正数n,产生n个正太分布的平方和
def product(n):n = np.ceil(n).astype(int)if n <=0:return Noney = np.power(np.random.randn(1000),2)for i in range(1,n):y += np.power(np.random.randn(1000),2)return y
画什么图?对于正态分布图,数据都会集中在一个点附近,所以我们用直方图最容易看出数据的分布情况
plt.figure(figsize=(10,10))
for i in range(9):plt.subplot(3,3,i+1)plt.xticks([])plt.yticks([])plt.hist(product(i+1),bins=100)plt.xlabel("n = %d"%(i+1))
plt.show()
结果如下:

这里数据量不是很多,所以好像能大概的看出来跟卡方分布有一点像,可以测试当n慢慢变大时,他的重心是往坐标轴右偏离的,也会越来越接近正太分布的曲线。
但是我们不知道图中的概率分布,这里用核密度图来近似趋近他的概率分布:
for i in range(9):y = pd.Series(product(i+1),name=i+1)y.plot(kind="kde",legend="best",figsize=(8,6))
plt.axvline(linestyle="--",linewidth=2, color='black')
plt.axhline(linestyle="--",linewidth=2, color='black')
plt.show()

这就大概的画出了卡方分布的概率密度图,当然数据量不大,也就只能近似的画出。这里只是让自己知道卡方分布有正态分布怎么演变而来的。对他也就不再神秘了。
卡方分布还具有可加性,用程序验证一下也是可以画出两条曲线相加的情况的。这里就不赘述了。
卡方验证
讲完卡方分布,我们说卡方验证。
卡方验证-百度百科传送门
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
百度百科里有好几个例子,都说明了卡方检验的方法,以及步骤。
也引用一个很好的帖子,讲述了卡方检验:如何学习和理解卡方检验。
这个帖子很好的诠释了卡方验证的步骤和注意的问题。很详细。
-
利用分布进行假设检验步骤
确定H0和H1
计算期望频数和自由度
通过自由度和显著水平确定拒绝域
计算检验统计量
查看统计量是否位于拒绝域内 -
自由度v
自由度值 = 独立的期望频数 - 限制条件数 = (行数-1)* (列数-1) -
计算拒绝域
分布进行检验为单侧检验,右侧作为拒绝域,临界值 (查表可得)
Pearson卡方为什么符合卡方分布
很多时候我们用的都是Pearson卡方验证,来看两组数据的差异性。
但是为什么可以用呢?为什么称之为卡方验证呢,我们知道只有符合这种分布的才可以用这种验证。
所以我网上找了很多资料,都是告诉你怎么用卡方验证,没有说明为什么Pearson卡方就符合卡方分布。这也是我一直纠结的问题。
后来才知道Pearson早就已经证明了这个问题。而且以我的水平肯定证明不了,所以我纠结了半天的问题,是我们站在了巨人的肩膀上。
附另外一个大神的帖子,证明Pearson分布符合卡方分布
Python处理卡方验证
# stats里有很多概率分布的函数,包括正太分布,卡方分布,t分布,f分布等等
from scipy import stats
百分点函数:
- Percent point function
# 计算99%的置信水平,自由度为1,的临界值。拒绝阈的边界值。
stats.chi2.ppf(q=0.99,df=1)# out:6.6348966010212145
累计分布概率 :
- Cumulative Distribution Function
# 计算自由度为1,当x为4时,4的左边的概率面积和。左尾
stats.chi2.cdf(x=4,df=1)
#out:0.9544997361036415
# 即:4的左边占了95.45%
概率分布函数:
- Probability Distribution Function
# 计算自由度为1的x=4时候对应的概率值。这个是单一的一个值得概率。不是面积。
stats.chi2.pdf(x=4,df=1)# out: 0.026995483256594024
生存函数:
- Survival function
# 给定一个x的值,计算这个值的存活几率。就是这个值右边的概率面积,右尾的大小
stats.chi2.sf(x=11.07,df=5)# out:0.050009618622405425
逆生存函数:
- inverse of
sf
# 这个函数和百分点函数ppf很相似,前者是给置信区间,计算左尾。
# 这个函数是给显著性水平,计算右尾。
# 是sf的逆函数,给一个显著性水平,查看这个水平的拒绝阈边界值。
stats.chi2.isf(0.05,5)# out:11.070497693516355
卡方验证方法:
1.卡方拟合性检验:
假设现在掷骰子,共120次,实验的结果是1-6点出现的次数为:[23,20,18,19,24,16],
假设骰子是公平的,那么他理论值为[20,20,20,20,20,20]
用Python计算卡方值
stats.chisquare([23,20,18,19,24,16],[20,20,20,20,20,20])
out:Power_divergenceResult(statistic=2.3, pvalue=0.8062668698851285)
结果计算出卡方值为2.3,概率为80.6%,他不小于5%,所以这个筛子的结果是可以接受的。
注意:这个80.6%概率是右尾面积。一般卡方求的也都是右尾。
那么如果筛子的结果是:[31,26,18,1,24,10]
stats.chisquare([31,26,18,1,24,10],[20,20,20,20,20,20])
最后计算出为
out:Power_divergenceResult(statistic=31.900000000000002, pvalue=6.218386333781248e-06)
卡方值31.9,概率特别小,远远小于5%显著性水平,那么这次掷骰子的结果我们持怀疑态度。很大的可能是作弊了。
另外通过公式验证
a = np.array([31,26,18,1,24,10])
b = np.array([20,20,20,20,20,20])
((a-b)**2/b).sum()
out: 31.900000000000002
# 取右尾,所以要用1减去它1 - stats.chi2.cdf(31.900000000000002,df=5)
out: 6.218386333745052e-06
和上面直接计算出的一模一样。在这里自由度是 5(即n-1)。
注:卡方拟合性检验,是值检验一组数据和期望值之间是否一致的问题。观测数据是测试样本的实际数据,而期望值一般是根据经验或者理论人为计算出来的。这里的自由度一般是分类个数减去1。
调用函数的时候可以:stats.chisquare([31,26,18,1,24,10])。不写期望值,他会根据数数值计算一个期望着。也就是加起来除以个数。如果期望值不平均,如[20,20,20,10,20,30] ,那就要写了。否则默认是平均的。
2.卡方独立性检验:
就用百度百科的例子。
如两组大白鼠在不同致癌剂作用下的发癌率如下表,问两组发癌率有无差别?
我们假设发病率没有差别。那么根据没有差别取计算期望值。这时候发病率我们不看,因为我们假设他们是一样的。那么甲组发病数应该是(91/113)*71,甲组不发病为71-(91/113)*71,乙组也是类似。
然后根据公式计算残差平方除以期望再求和。得到统计量。这种计算就不算了。
我们用Python的库来方便计算他们。
# 这个函数有四个返回值。第一个是统计量,第二个是p值,第三个是自由度,第四个是期望,就是我们上面算的那个期望值
# 另外这个函数的参数correction(修正)默认是True。默认使用修正,下面会说
stats.chi2_contingency(np.array([[52,19],[39,3]]),correction=False)# out: (6.477664689435311, 0.010923841556032656, 1, array([[57.17699115, 13.82300885],
# [33.82300885, 8.17699115]]))
P值不大于百分之五显著性水平,此时不能接受原假设,即发病率是有差别的。
我们在看另一种使用修正的:
stats.chi2_contingency(np.array([[52,19],[39,3]]),correction=True)# out:(5.286846662726942, 0.021487093299070083, 1, array([[57.17699115, 13.82300885],
# [33.82300885, 8.17699115]]))
可以看出他们两的统计量(卡方值)和P值都不一样。因为他们的公式不一样。
不使用修正的就是我们平时用的Pearson公式。
而使用修正值的公式:

a = np.array([52,19,39,3])
b = np.array([57.17699115, 13.82300885,33.82300885, 8.17699115])
((np.abs(a-b)-0.5)**2/b).sum()
out: 5.286846661815195
结果和上面使用连续修正值为True的结果是一样的
对于样本总频数大于40,且样本期望频数大于等于5,使用Pearson卡方值
对于样本总频数大于40,且样本期望频数小于5且大于等于1,使用连续修正值的卡方检验
注:卡方独立性检验,是看两个变量抽出来的观察值是否相互独立。也就是研究两个变量之间的关联性,如果无关,则相互独立,就是最终的P值很大,大于5%。如果有关则相反。
以上就是我对卡方分布和卡方检验的理解。难免有不足的地方。