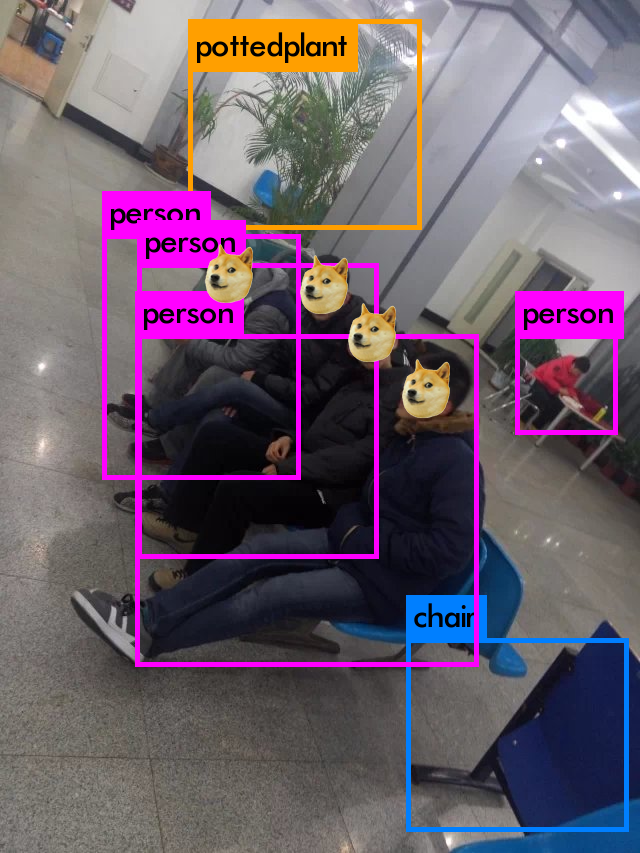
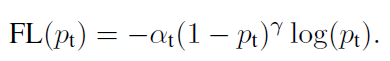1.Batch Normalization
Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。
2.High Resolution Classifier
YOLO 对应训练过程分为两步,第一步是通过 ImageNet 训练集 进行高分辨率的预训练,这一步训练的是分类网络;第二步是训练检测网络,是在分类网络的基础上进行 fine tune。
之前的 YOLO v1以分辨率224*224训练分类网络,YOLO v2 将分类网络的分辨率提高到 448*448,高分辨率样本对于效果有一定的提升(文中mAp提高了约4%)。
3.k-means聚类获取anchor先验信息
详见博客k-mean聚类获取anchor的先验大小
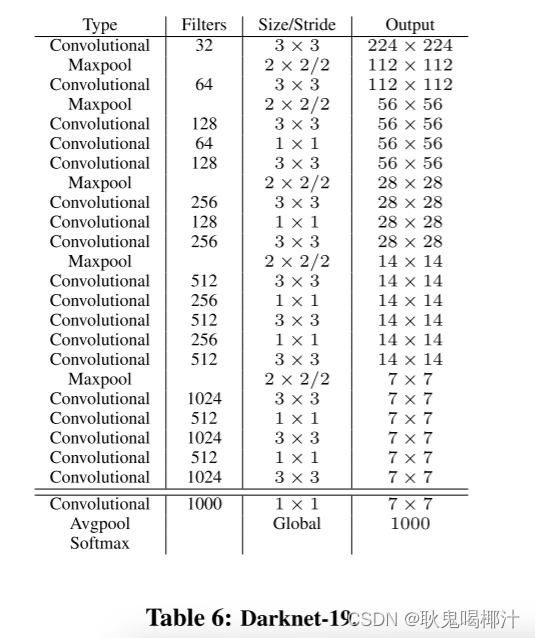
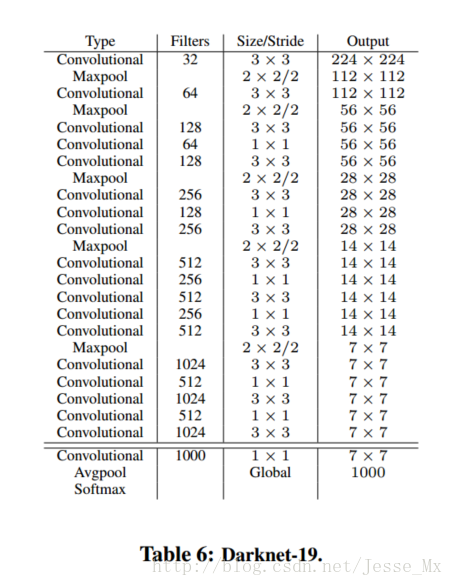
4.网络结构-Darknet-19
YOLOv2使用了DarkNet-19作为骨干网络(图2),需要注意两点:
- YOLOv2输入大小为416×416,不是下图中的224×224。考虑到很多情况下待检测物体的中心点容易出现在图像的中央,所以经过5次降采样之后生成的Feature Map的尺寸是13×13,这种奇数尺寸的Feature Map获得的中心点的特征向量更准确。其实这也YOLOv1产生7×7 的理念是相同的。;
- 在3×3的卷积中间添加了1×1的卷积,一方面用于channel reduction,另一方面Feature Map之间的一层非线性变化提升了模型的表现能力;
- Darknet-19进行了5次降采样,但是在最后一层卷积并没有添加池化层,目的是为了获得更高分辨率的Feature Map;
- Darknet-19中并不含有全连接,使用的是全局平均池化的方式产生长度固定的特征向量(GAP可以使网络的输入不用再是一个固定值)。
5.边框回归
前面讲到,YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。边界框的实际中心位置,需要根据预测的坐标偏移值
,先验框的尺度
以及中心坐标
(特征图每个位置的中心点)来计算:
但是上面的公式是无约束的,预测的边界框很容易向任何方向偏移,如当tx=1时边界框将向右偏移先验框的一个宽度大小,而且tx=−1时边界框将向左偏移先验框的一个宽度大小,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。
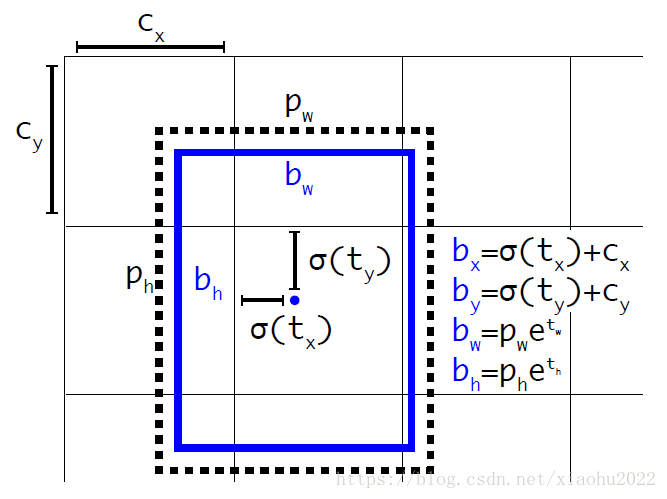
所以,YOLOv2弃用了这种预测方式,而是沿用YOLOv1的方法,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。总结来看,根据边界框预测的4个offsets ,可以按如下公式计算出边界框实际位置和大小:
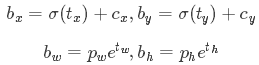
- 公式中
和
表示当前cell距离feature maps左上角的距离。
表示网络预测的在x方向和y方向上的偏移量。
6.细粒度特征
修改后的网络最终在13x13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,但如果用上细粒度特征的话可能对小尺度的物体检测有帮助。
YOLOv2使用了一种不同的方法,简单添加一个passthrough layer,把浅层特征图(分辨率为26x26)连接到深层特征图。
具体操作如下:
1.叠加相邻空间位置的特征到不同通道,将26x26x512的特征图叠加成13x13x2048的特征图。
2.将浅层特征图(13x13x2048)和深层特征图(13x13x1024)合并为一个(13x13x3072)tensor。

5.损失函数
详见博客yolo-V2损失函数理解