论文传送门:YOLO9000: Better, Faster, Stronger
Yolov2的改进:
1.批标准化(Batch Normalization):在conv后加入BN(conv不再使用bias),改善模型的收敛性,同时去掉dropout;
2.高分辨率分类器(High Resolution Classifier):使用448x448的完整分辨率对分类网络(主干网络)进行10epoch的预训练;
3.锚框(Convolutional With Anchor Boxes):引入anchor的概念来预测bbox,每个anchor单独预测目标和类别,目标预测先验框(anchor)与真实框之间的IOU,类别预测存下目标的前提下,该类别的条件概率;
4.尺寸聚类(Dimension Clusters):使用k-means聚类的方法获得anchor的预设尺寸;
5.直接位置预测(Direct location prediction):将网络输出的中心坐标偏移参数 t x t_x tx、 t y t_y ty和置信度(IOU) t o t_o to通过sigmoid激活函数,将其值压缩在(0,1);
6.细粒的特征(Fine-Grained Features):在backbone中提取浅层特征,经过passthrough layer(focus)后与深层特征相接(concat);
7.多尺度训练(Multi-Scale Training):每10个batches,随机改变网络输入图像尺寸,从 [ 320 , 352 , . . . , 608 ] [320,352,...,608] [320,352,...,608]中选取(32的整数倍,因为图像经过网络缩减了32倍),增强模型的鲁棒性;
Yolov2的结构:
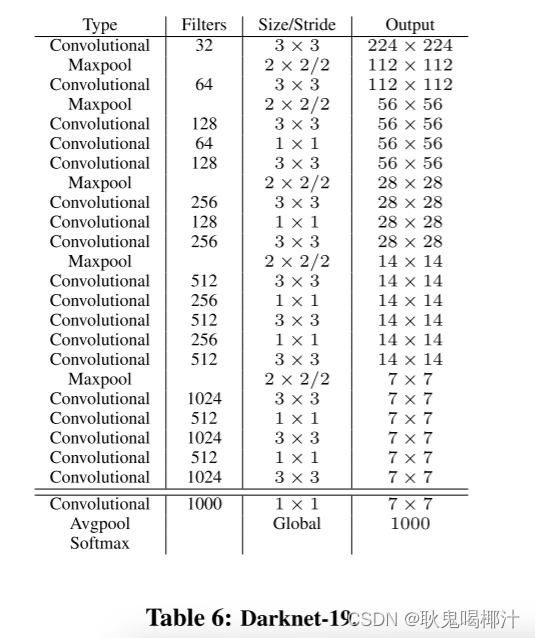
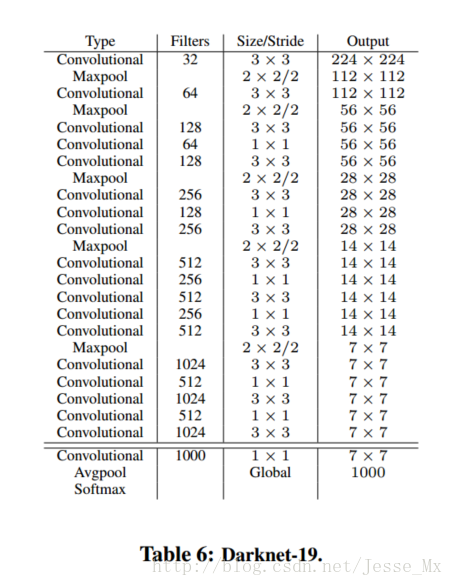
使用Darknet19(去掉分类部分)作为backbone提取特征,使用卷积和passthrough layer处理浅层特征,使用两层卷积处理深层特征,并对两层特征进行Concat,最后经过卷积变换得到通道数为125的输出。
图示Darknet19的输入图像尺寸为224,但在Yolov2中作backbone,输入图像尺寸为 [ 320 , 352 , . . . , 608 ] [320,352,...,608] [320,352,...,608]。

Yolov2的输出:
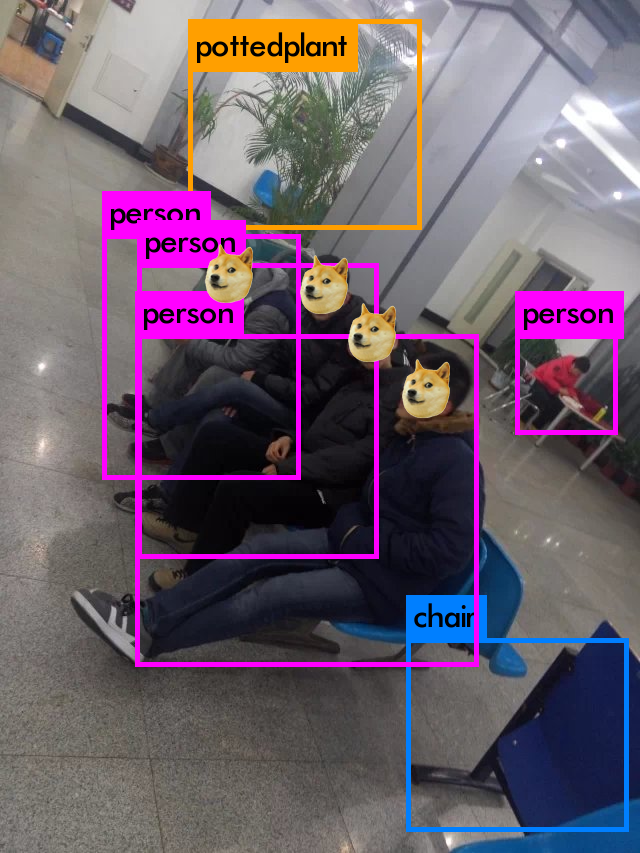
对于VOC数据集,当输入图像尺寸为416时,网络输出为(125,13,13),其中13x13代表169个anchor位置; 125 = ( 4 + 1 + 20 ) ∗ 5 125=(4+1+20)*5 125=(4+1+20)∗5,4代表目标回归参数,1代表目标置信度,20代表20个类别的条件概率,最后一个5代表anchor的尺寸数,即每个位置存在5种尺寸的anchor。
Yolo9000的含义:
作者采用一种联合训练的方式,使得模型可以同时检测超过9000个类别,故取名为Yolo9000。
(代码仅实现模型结构部分)
import torch
import torch.nn as nn
import randomdef conv(in_channels, out_channels, kernel_size): # conv+bn+leakyrelupadding = 1 if kernel_size == 3 else 0return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, 1, padding, bias=False),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.1))class Darknet19(nn.Module): # darknet19def __init__(self):super(Darknet19, self).__init__()self.maxpool = nn.MaxPool2d(2, 2)self.conv1 = conv(3, 32, 3)self.conv2 = conv(32, 64, 3)self.bottleneck1 = nn.Sequential(conv(64, 128, 3),conv(128, 64, 1),conv(64, 128, 3))self.bottleneck2 = nn.Sequential(conv(128, 256, 3),conv(256, 128, 1),conv(128, 256, 3))self.bottleneck3 = nn.Sequential(conv(256, 512, 3),conv(512, 256, 1),conv(256, 512, 3),conv(512, 256, 1),conv(256, 512, 3))self.bottleneck4 = nn.Sequential(conv(512, 1024, 3),conv(1024, 512, 1),conv(512, 1024, 3),conv(1024, 512, 1),conv(512, 1024, 3))def forward(self, x):x = self.conv1(x)x = self.maxpool(x)x = self.conv2(x)x = self.maxpool(x)x = self.bottleneck1(x)x = self.maxpool(x)x = self.bottleneck2(x)x = self.maxpool(x)shallow_x = self.bottleneck3(x) # 浅层特征deep_x = self.maxpool(shallow_x)deep_x = self.bottleneck4(deep_x) # 深层特征return shallow_x, deep_xclass Yolov2(nn.Module):def __init__(self):super(Yolov2, self).__init__()self.backbone = Darknet19()self.deep_conv = nn.Sequential(conv(1024, 1024, 3),conv(1024, 1024, 3))self.shallow_conv = conv(512, 64, 1)self.final_conv = nn.Sequential(conv(1280, 1024, 3),nn.Conv2d(1024, 125, 1, 1, 0))def passthrough(self, x): # passthrough layerreturn torch.cat([x[:, :, ::2, ::2], x[:, :, ::2, 1::2], x[:, :, 1::2, ::2], x[:, :, 1::2, 1::2]], dim=1)def forward(self, x):shallow_x, deep_x = self.backbone(x) # (B,512,26,26)、(B,1024,13,13)shallow_x = self.shallow_conv(shallow_x) # (B,512,26,26)-->(B,64,26,26)shallow_x = self.passthrough(shallow_x) # (B,64,26,26)-->(B,256,13,13)deep_x = self.deep_conv(deep_x) # (B,1024,13,13)-->(B,1024,13,13)feature = torch.cat([deep_x, shallow_x], dim=1) # (B,1024,13,13)cat(B,256,13,13)-->(B,1280,13,13)return self.final_conv(feature) # (B,1280,13,13)-->(B,1024,13,13)-->(B,125,13,13)if __name__ == "__main__":batch_size = 8image_channels = 3image_size = random.randrange(320, 608 + 32, 32) # [320,352,...,608]images = torch.randn(batch_size, image_channels, image_size, image_size)print(images.shape)yolov2 = Yolov2()print(yolov2(images).shape)