浅谈数据仓库维度建模流程
谈到Big Data就离不开数据仓库、数据集市等概念,而谈到数据仓库、数据集市,就又离不开数据仓库设计的方法,维度建模则是其中的典型。与维度建模相对立的则是范式建模,范式建模常用于传统的DB关系型数据库中。范式建模讲究三范式,讲究原子性,一致性,隔离性,持久性。讲究最小原子列不可再分,讲究消除部分依赖,y=f(x),y依赖于x,且x的任一真子集x’不满足对应唯一y。讲究消除传递依赖,当x---->y(y!------>x),z------>x(x!------>z)时则不满足3FN。而维度建模则是与之相对,维度建模不讲究范式,不讲究关系型,不讲究事务,讲究主题域,讲究总线矩阵,讲究维度和事实,讲究…
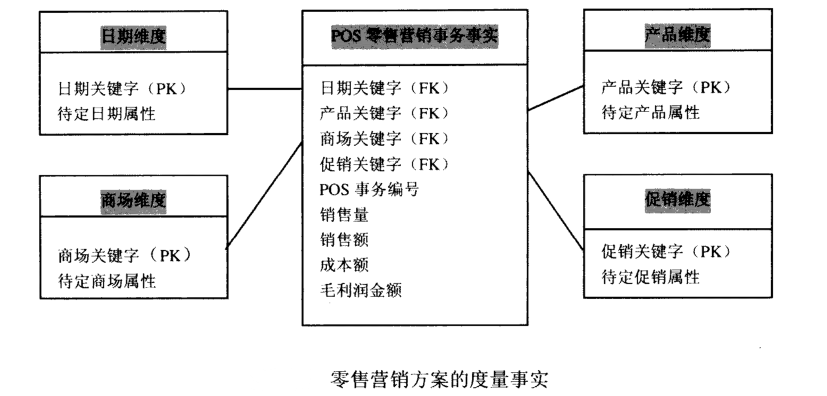
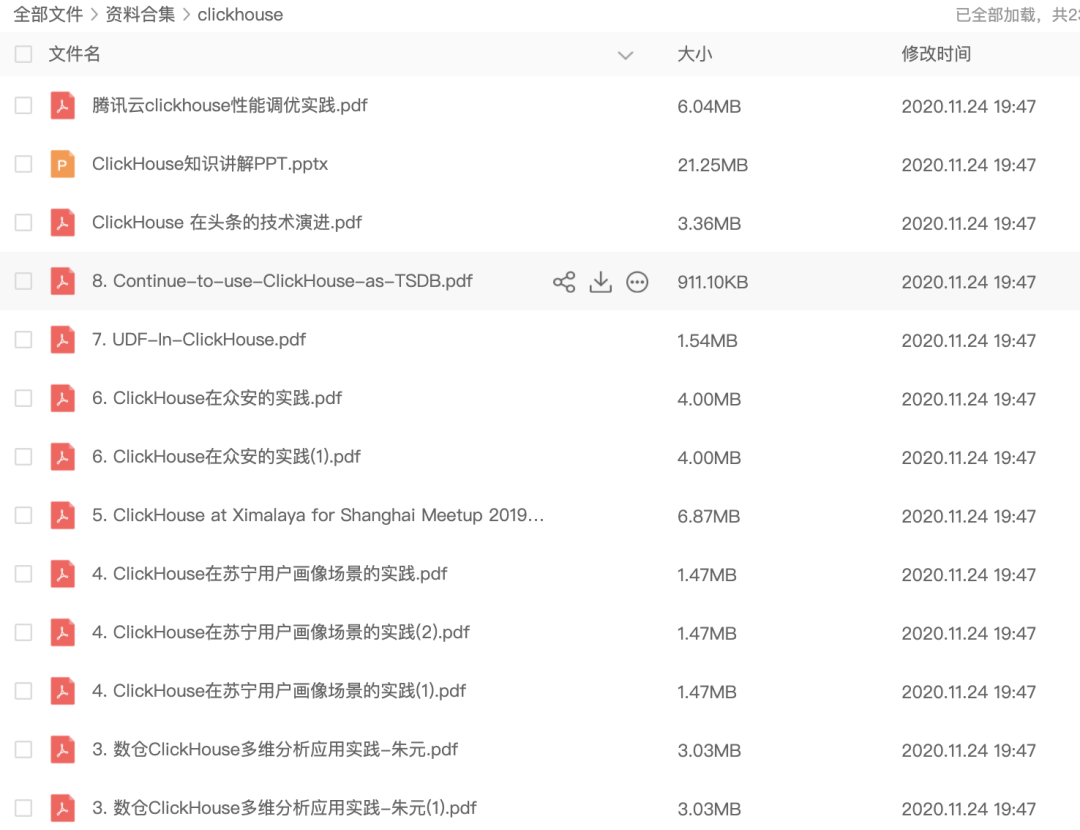
附上之前所画一张流程图
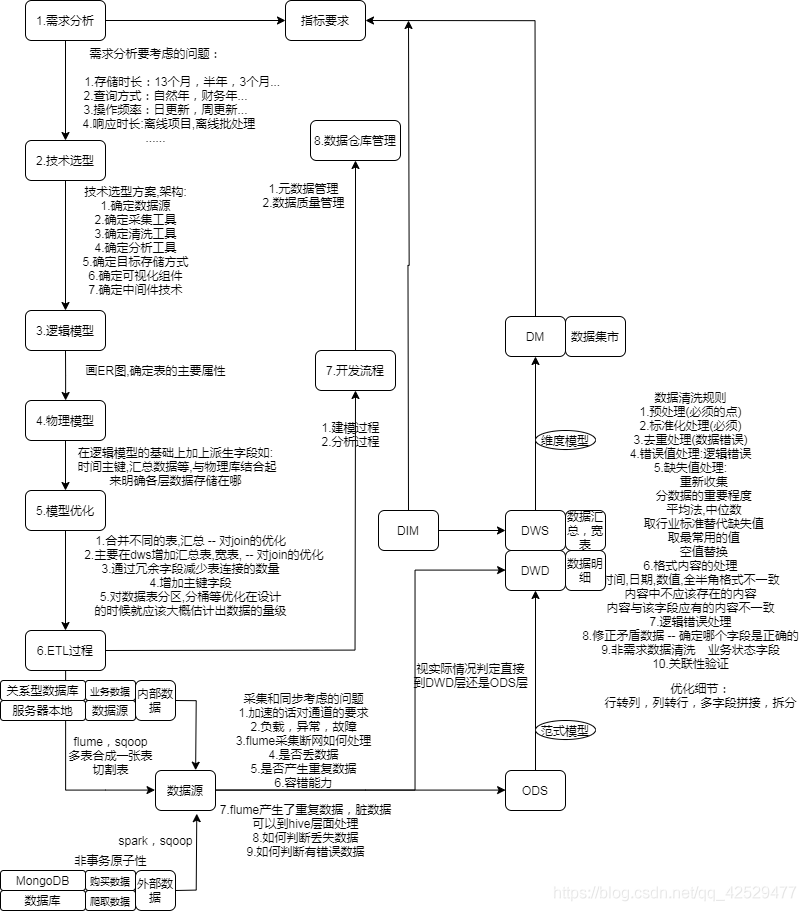
之前画此图时是在前辈的帮助下画出,但也是一知半解,其中很多东西不能完全理解,直至现在也是大概明白其中流程,但更多细节值得深入学习。今日不谈后面的ETL过程、数据治理等,就谈谈前期的维度建模。近日又购得Kimball的维度建模,和阿里大数据之路二书,希望能够沉下心深入学习,数据产品要想打造的好,令人满意,则数据内容一定要质量过关。数据内容过关了,面对怎样的数据产出都会有自信,自己的数据没有问题。
维度建模以用户的可理解性和查询性能为目标,建立始终如一服务于组织的分析需求设计。维度建模是DW/BI系统项目成功的关键。是一种趋向于最终用户对数据仓库进行查询的设计技术,是围绕性能和易理解性构建的。
谈到维度建模则一定要说到两个较为核心的概念则是维度和事实。维度表和事实表经常听说,那能否对维度和事实有个更好的定义呢。
事实:既成事实,表示对业务数据的度量,事实很多时候是数字类型的,可以进行计算和聚合。维度:观察数据事物的角度,维度通常是一组层次关系或者描述信息,用来定义事实。
维度建模最开始要定好主题域,而建立主题域更多时候按业务流程来建立。不同的主题域可能共享一些维度,则这些维度也称为一致性维度。术语“一致性维度”源自Kimball,指的是具有相同属性和内容的维度,拥有这些一致性维度,可以提高数据操作的性能和数据一致性,如几个主题域之间共享维度的复制。维度建模将客观世界划分为度量和上下文,维度建模按照业务流程即主题域建立。
维度数据模型建模过程
1.选择业务流程
确认哪些业务处理流程是数据仓库应该涵盖到的,也是第一步的基础。比如要设计一家公司的销售情况,则与该公司的销售相关的业务流程都应该关注到,然后描述业务流程(如何描述也是一个问题BPMN?UML?),这个时候产出可以有业务流程图。
2.声明粒度
再确认哪些业务流程应该是涵盖到的之后,则应该声明粒度,声明粒度应该在确认维度和事实之前,因为只有先定义好粒度后面的维度和事实才能与定义的粒度保持一致,(他们说)一个事实所对应的所有维度设计中强制实行粒度一致性是保证数据仓库应用性能和易用性的关键。这里的粒度用于确认事实中表示的是什么,要定义好粒度大小。在给定业务获取数据时,原始粒度是最低级别的粒度,(他们说)建议从原始粒度数据开始设计,因为原始记录能够满足无法预期的用户查询。轻汇总和重度汇总后的数据粒度对优化查询性能很重要,但这样的粒度设计往往不能满足对细节数据的查询需求。不同的事实可以有不同的粒度,但同一事实中也不要混用多种不同的粒度。
3.确认维度
确认模型的维度是第三步,维度的粒度需要和第二步声明的粒度保持一致。维度表是事实表设计的基础。典型的维度都是名称(标签),如日期、商店、用户等。维度表存储了某一维度所有相关的数据。例如日期维度应该包含年、季、月、周等。城市维度表包含所有城市等。
4.确认事实
最后一步则是确认事实,这一步识别数字化的度量,构成事实表的记录。用户可直接通过事实表的访问获取数据仓库存储的数据。大部分事实表的度量都是数字类型的,可进行计算。
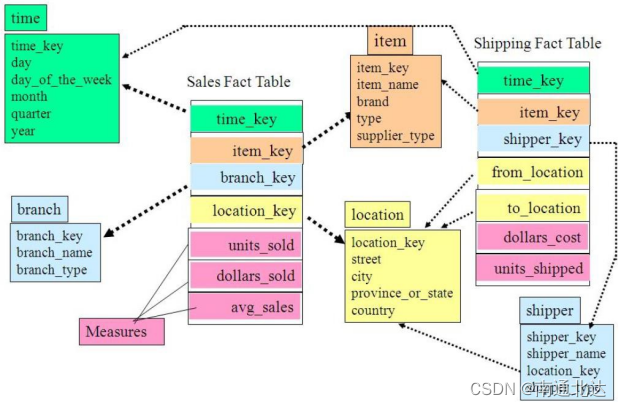
星型模型和雪花模型
谈到维度建模也不能不谈到星型模型和雪花模型了。之前一直以为两者差不多,雪花模型不过是星型模型的拓展而已。最近才发现二者思想挺不一样的。星型模型(容易想到一星四射)事实表关联维度表,维度表与维度表之间没有关联,这样的设计,冗余大(秉持着能用钱解决的问题都不是问题的原则,这一点反而被鼓励),查询快,扩展性差,是反规范化数据。而雪花模型是把星型模型中的维度表进行规范化处理,进一步分解到附加表中。把维度表规范化的具体做法:把低基数的属性从从维度表中移除并形成单独的表。(性别属于低基数,主键具有唯一值是高基数)在雪花模式中,一个维度被规范化成多个关联的维度表,而在星型模式中,每一个维度由一个单一的维度表所表示。一个规范化的维度对应一组具有层次关系的维度表,而事实表作为雪花模式的子表,存在具有层次关系的多个父表。
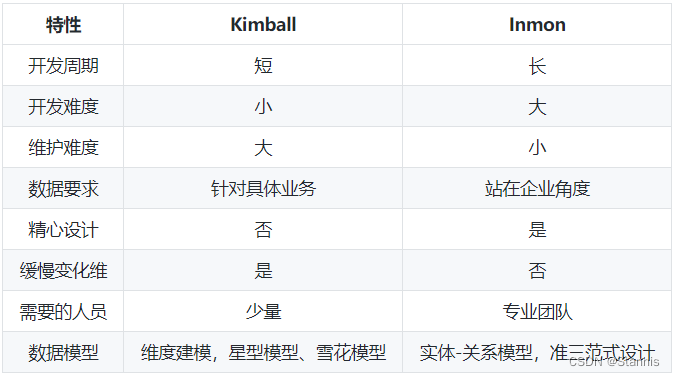
星型模型和雪花模型的对比
1.数据优化
星形模型:实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。不能保证数据完整性,一次性地插入或更新操作可能会造成数据异常。对于分析需求不够灵活。它更偏重于为特定目的建造数据视图。
雪花模型:使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。规范化后的多层次维度表,可以很方便支持业务实体多对多关系,很容易进行全面的数据分析。
2.业务模型
星型模型:主键是一个单独的唯一键(数据属性),为特殊数据所选择。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。
雪花模型:数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
3.性能
星型模型:星形模型在维度表、事实表之间的连接较少,所以简化了查询,相应的简化了业务报表的逻辑。获得查询性能、能更快速的进行聚合。
雪花模型:雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。(但是,规范化的维度属性可以节省存储空间。)
4.ETL
星型模型:星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
雪花模型:雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。
5.总结
星型模型:星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?
雪花模型:雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”
部分名词:
总线矩阵的必要性
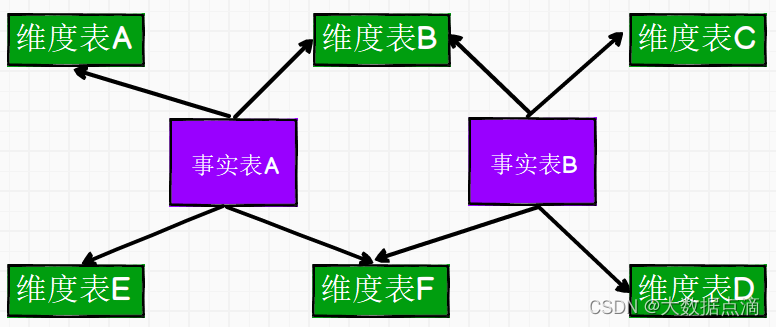
企业数据仓库总线矩阵是DW/BI系统的一个总体数据架构,如果我们在建立数据仓库的时候,只考虑单独的某个业务系统的数据建设,则无法满足一致性的目标,例如:相互有联系的系统数据的维度不同导致关联复杂或者关联不上,数据之间互相成为了孤岛,对于后期的扩展或者整个数仓的建设都是巨大的阻碍。
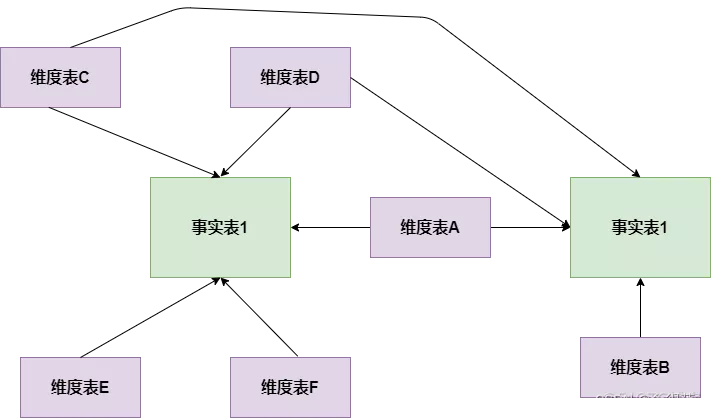
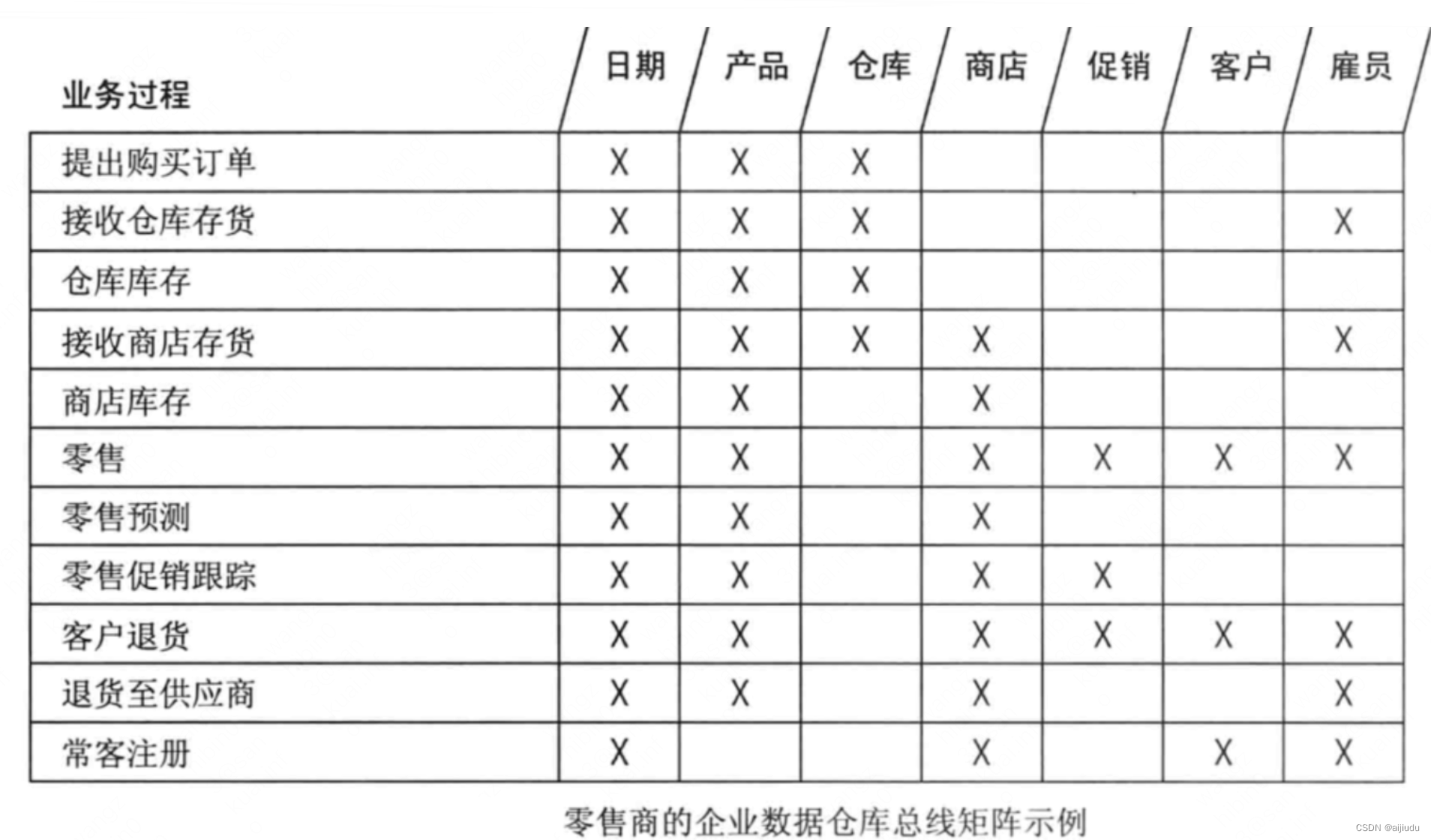
总线矩阵举例:
那么总线矩阵就给我们提供了这么一个工具,每一行是一个业务过程,每一列是这个业务过程可能涉及到的一些维度,比如说上图中的零售业务过程,这块涉及到的公用维度包括:日期维度,产品维度,商店维度,促销维度,客户维度,雇员(销售员)维度。
再看仓库库存业务过程,包含了日期维度,产品维度,仓库维度。
通过日期维度或者产品维度或者仓库维度,我们可以将每天的某种商品的库存数据和销售数据关联起来进行分析,这就是一致性维度的好处,假设这两部分数据没有经过提前规划,各部分数据都有不同的维表,那这两部分数据想要联系起来太难了。
退化维度
退化维度的维度表可以被剔除,从而简化维度数据仓库的模式。因为简单的模式比复杂的更容易理解,也有更好的查询性能。
当一个维度没有数据仓库需要的任何数据时就可以退化此维度。需要把退化维度的相关数据迁移到事实表中,然后删除退化的维度。
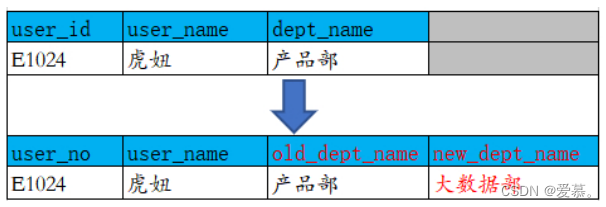
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为“退化维度”。与其他存储在维表中的维度一样 ,退化维度也可以用来进行事实表的过滤查询、实现聚合操作等。那么究竟怎么定义退化维度呢?比如说订单id,这种量级很大的维度,没必要用一张维度表来进行存储,而我们进行数据查询或者数据过滤的时候又非常需要,所以这种就冗余在事实表里面,这种就叫退化维度,citycode这种我们也会冗余在事实表里面,但是它有对应的维度表,所以它不是退化维度。
kimball书中描述退化维度如下:操作型事务控制号码,例如:订单号码、发票号码、提货单号码通常产生空的维度并且宝石为事务事实表中的退化维度。退化维度是没有对应维度表的维度键。
维度退化在事实表中有利于使用,一般一个维度键都有对应的维表,如果退化在事实表中,可以减少关联次数,并且退化维可以用于group by操作,进行分组统计。
还可以这么理解:就是这个东西没有对应的维表,没有修饰它的属性,但是呢,通过它你可以获取一些内容,一些事实,比如说订单编号,你可以获得这个订单里面包含哪些商品,对应的付款人是谁之类的。
缓慢变化维:维度建模的数据仓库中,有一个概念叫Slowly Changing Dimensions,中文一般翻译成“缓慢变化维”,经常被简写为SCD。缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。这种随时间发生变化的维度我们一般称之为缓慢变化维,并且把处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,有时也简称为处理SCD的问题。
处理缓慢变化维的方法通常分为三种方式:
第一种方式是直接覆盖原值。这样处理,最容易实现,但是没有保留历史数据,无法分析历史变化信息。第一种方式通常简称为“TYPE 1”。
第二种方式是添加维度行。这样处理,需要代理键的支持。实现方式是当有维度属性发生变化时,生成一条新的维度记录,主键是新分配的代理键,通过自然键可以和原维度记录保持关联。第二种方式通常简称为“TYPE 2”。
第三种方式是添加属性列。这种处理的实现方式是对于需要分析历史信息的属性添加一列,来记录该属性变化前的值,而本属性字段使用TYPE 1来直接覆盖。这种方式的优点是可以同时分析当前及前一次变化的属性值,缺点是只保留了最后一次变化信息。第三种方式通常简称为“TYPE 3”。
在实际建模中,我们可以联合使用三种方式,也可以对一个维度表中的不同属性使用不同的方式,这些,都需要根据实际情况来决定,但目的都是一样的,就是能够支持方便的分析历史变化情况。
维度建模对数据内容的建设,思想大于技术,思想引导技术。目前大部分理解来源书本、文章、讲解。来自项目实战、自己经验的部分少之又少、很多时候只是一个别人思想、别人文章、别人技术、别人讲解的搬运工、尚不能理解搬运的财富。望后面能有自己的理解。