文章目录
- 一 CDC简介
- 1 什么是CDC
- 2 CDC的种类
- 3 Flink-CDC
- 二 准备业务数据-DWD层
- 1 主要任务
- (1)接收Kafka数据,过滤空值数据
- (2)实现动态分流功能
- (3)把分好的流保存到对应表、主题中
- 2 接收Kafka数据,过滤空值数据
- (1)代码
- (2)测试
- 3 根据MySQL的配置表,进行动态分流
- (1)准备工作
- a 引入pom.xml 依赖
- b 在Mysql中创建数据库
- c 在gmall2022_realtime库中创建配置表table_process
- d 创建配置表实体类
- e 在MySQL Binlog添加对配置数据库的监听,并**重启**MySQL
- (2)FlinkCDC的使用 -- DataStream
- a 导入依赖
- b 代码编写
- c 测试
- d 端点续传案例测试
- (3)FlinkCDC的使用 -- FlinkSQL
- a 导入依赖
- b 基础信息配置
- c 代码编写
一 CDC简介
1 什么是CDC
CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
2 CDC的种类
CDC主要分为基于查询和基于Binlog两种方式,主要了解一下这两种之间的区别:
| 基于查询的CDC | 基于Binlog的CDC | |
|---|---|---|
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、Maxwell、Debezium |
| 执行模式 | Batch | Streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
3 Flink-CDC
Flink社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,参考网址。
二 准备业务数据-DWD层
业务数据的变化,可以通过Maxwell采集到,但是MaxWell是把全部数据统一写入一个Topic中, 这些数据包括业务数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从Kafka的业务数据ODS层读取数据,经过处理后,将维度数据保存到Hbase,将事实数据写回Kafka作为业务数据的DWD层。
1 主要任务
(1)接收Kafka数据,过滤空值数据
对Maxwell抓取数据进行ETL,有用的部分保留,没用的过滤掉。
(2)实现动态分流功能
由于MaxWell是把全部数据统一写入一个Topic中,这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表在某种情况下既是事实表也是维度表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是作为Flink实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
可以将上面的内容放到某一个地方,集中配置。这样的配置不适合写在配置文件中,因为业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
- 一种是用Zookeeper存储,通过Watch感知数据变化。
- 另一种是用mysql数据库存储,周期性的同步,使用FlinkCDC读取。
这里选择第二种方案,主要是mysql对于配置数据初始化和维护管理,用sql都比较方便。
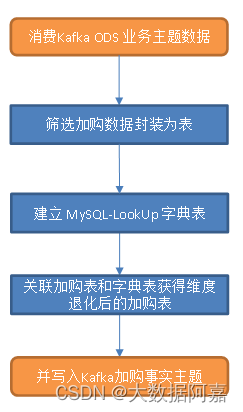
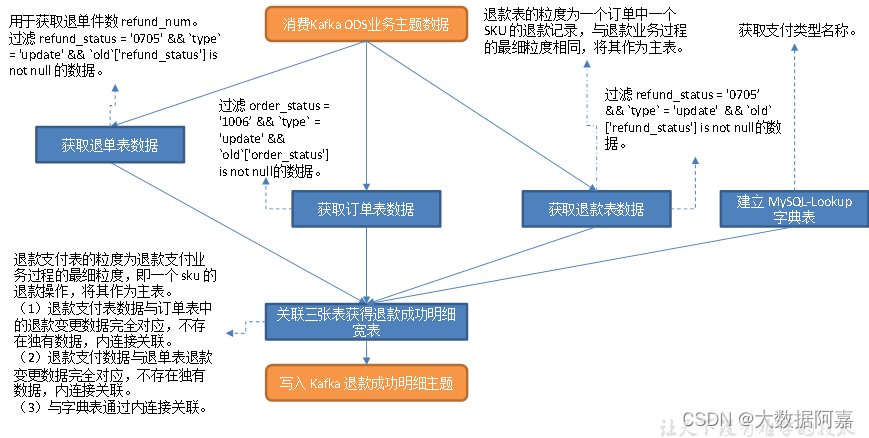
所以就有了如下图:

配置表字段说明:
- sourceTable:原表名。
- sinkType:输出的类型。
- sinkTable:写出到哪个表。
- sinkpk:主键。
- sinkcolum:保留哪些字段。
- ext:建表语句的扩展,如引擎,主键增长方式,编码方式等。
- operateType:操作类型,不记录数据的删除操作。
(3)把分好的流保存到对应表、主题中
业务数据保存到Kafka的主题中。
维度数据保存到Hbase的表中。
2 接收Kafka数据,过滤空值数据
整体工作流程:

(1)代码
public class BaseDBApp {public static void main(String[] args) throws Exception {//TODO 1 基本环境准备//流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度env.setParallelism(1);//TODO 2 检查点设置//开启检查点env.enableCheckpointing(5000L,CheckpointingMode.EXACTLY_ONCE);// 设置检查点超时时间env.getCheckpointConfig().setCheckpointTimeout(60000L);// 设置重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,3000L));// 设置job取消后,检查点是否保留env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 设置状态后端 -- 基于内存 or 文件系统 or RocksDBenv.setStateBackend(new FsStateBackend("hdfs://hadoop101:8020/ck/gmall"));// 指定操作HDFS的用户System.setProperty("HADOOP_USER_NAME","hzy");//TODO 3 从kafka中读取数据//声明消费的主题以及消费者组String topic = "ods_base_db_m";String groupId = "base_db_app_group";// 获取消费者对象FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId);// 读取数据,封装成流DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);//TODO 4 对数据类型进行转换 String -> JSONObjectSingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject);//TODO 5 简单的ETLSingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.filter(new FilterFunction<JSONObject>() {@Overridepublic boolean filter(JSONObject jsonobj) throws Exception {boolean flag =jsonobj.getString("table") != null &&jsonobj.getString("table").length() > 0 &&jsonobj.getJSONObject("data") != null &&jsonobj.getString("data").length() > 3;return flag;}});filterDS.print("<<<");//TODO 6 动态分流//TODO 7 将维度侧输出流的数据写到Hbase中//TODO 8 将主流数据写回kafka的dwd层env.execute();}
}
(2)测试
业务数据总体流程如下:

开启zookeeper
开启kafka
开启maxwell
开启nm,等待安全模式关闭
开启主程序
模拟生成业务数据,查看主程序输出内容
3 根据MySQL的配置表,进行动态分流
通过FlinkCDC动态监控配置表的变化,以流的形式将配置表的变化读到程序中,并以广播流的形式向下传递,主流从广播流中获取配置信息。
(1)准备工作
a 引入pom.xml 依赖
<!--lomback插件依赖-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.12</version><scope>provided</scope>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version>
</dependency>
<dependency><groupId>com.alibaba.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>1.2.0</version>
</dependency>
b 在Mysql中创建数据库
注意和gmall2022业务库区分开

c 在gmall2022_realtime库中创建配置表table_process
CREATE TABLE `table_process` (`source_table` varchar(200) NOT NULL COMMENT '来源表',`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
d 创建配置表实体类
@Data
public class TableProcess {//动态分流Sink常量,改为小写和脚本一致public static final String SINK_TYPE_HBASE = "hbase";public static final String SINK_TYPE_KAFKA = "kafka";public static final String SINK_TYPE_CK = "clickhouse";//来源表String sourceTable;//操作类型 insert,update,deleteString operateType;//输出类型 hbase kafkaString sinkType;//输出表(主题)String sinkTable;//输出字段String sinkColumns;//主键字段String sinkPk;//建表扩展String sinkExtend;
}
e 在MySQL Binlog添加对配置数据库的监听,并重启MySQL
sudo vim /etc/my.cnf
# 添加
binlog-do-db=gmall2022_realtime
# 重启
sudo systemctl restart mysqld
(2)FlinkCDC的使用 – DataStream
新建maven项目gmall2022-cdc。
a 导入依赖
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><dependency><groupId>com.alibaba.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>1.2.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version></dependency>
</dependencies>
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
b 代码编写
/*** 通过FlinkCDC动态读取MySQL表中的数据 -- DataStreamAPI*/
public class FlinkCDC01_DS {public static void main(String[] args) throws Exception {//TODO 1 准备流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//TODO 2 开启检查点 Flink-CDC将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断点续传,// 需要从Checkpoint或者Savepoint启动程序// 开启Checkpoint,每隔5秒钟做一次CK,并指定CK的一致性语义env.enableCheckpointing(5000L, CheckpointingMode.EXACTLY_ONCE);// 设置超时时间为1分钟env.getCheckpointConfig().setCheckpointTimeout(60000);// 指定从CK自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2,2000L));// 设置任务关闭的时候保留最后一次CK数据env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 设置状态后端env.setStateBackend(new FsStateBackend("hdfs://hadoop101:8020/ck/flinkCDC"));// 设置访问HDFS的用户名System.setProperty("HADOOP_USER_NAME", "hzy");//TODO 3 创建Flink-MySQL-CDC的SourceProperties props = new Properties();props.setProperty("scan.startup.mode","initial");SourceFunction<String> sourceFunction = MySQLSource.<String>builder().hostname("hadoop101").port(3306).username("root").password("123456")// 可配置多个库.databaseList("gmall2022_realtime")///可选配置项,如果不指定该参数,则会读取上一个配置中指定的数据库下的所有表的数据//注意:指定的时候需要使用"db.table"的方式.tableList("gmall2022_realtime.t_user").debeziumProperties(props).deserializer(new StringDebeziumDeserializationSchema()).build();//TODO 4 使用CDC Source从MySQL读取数据DataStreamSource<String> mysqlDS = env.addSource(sourceFunction);//TODO 5 打印输出mysqlDS.print();//TODO 6 执行任务env.execute();}
}
c 测试
在gmall2022_realtime添加表,执行程序,添加数据,可以看到以下信息

d 端点续传案例测试
# 打包并将带依赖的jar包上传至Linux
# 启动HDFS集群
start-dfs.sh
# 启动Flink集群
bin/start-cluster.sh
# 启动程序
bin/flink run -m hadoop101:8081 -c com.hzy.gmall.cdc.FlinkCDC01_DS ./gmall2022-cdc-1.0-SNAPSHOT-jar-with-dependencies.jar
# 观察taskManager日志,会从头读取表数据
# 给当前的Flink程序创建Savepoint
bin/flink savepoint JobId hdfs://hadoop101:8020/flink/save
# 在WebUI中cancelJob
# 在MySQL的gmall2022_realtime.t_user表中添加、修改或者删除数据
# 从Savepoint重启程序
bin/flink run -s hdfs://hadoop101:8020/flink/save/JobId -c com.hzy.gmall.cdc.FlinkCDC01_DS ./gmall2022-cdc-1.0-SNAPSHOT-jar-with-dependencies.jar
# 观察taskManager日志,会从检查点读取表数据
(3)FlinkCDC的使用 – FlinkSQL
使用FlinkCDC通过sql的方式从MySQL中获取数据。
a 导入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>1.12.0</version>
</dependency>
b 基础信息配置
修改语言级别

修改编译级别

c 代码编写
public class FlinkCDC02_SQL {public static void main(String[] args) throws Exception {//TODO 1.准备环境//1.1流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//1.2 表执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//TODO 2.创建动态表tableEnv.executeSql("CREATE TABLE user_info (" +" id INT," +" name STRING," +" age INT" +") WITH (" +" 'connector' = 'mysql-cdc'," +" 'hostname' = 'hadoop101'," +" 'port' = '3306'," +" 'username' = 'root'," +" 'password' = '123456'," +" 'database-name' = 'gmall2022_realtime'," +" 'table-name' = 't_user'" +")");tableEnv.executeSql("select * from user_info").print();//TODO 6.执行任务env.execute();}}



![[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念](https://img-blog.csdnimg.cn/img_convert/523af9b199c957a94f22907cc0df07b1.png)