Nanopore测序技术
Shaoqian_Ma已关注
0.1142020.04.14 10:59:30字数 2,727阅读 360
纳米孔测序解析新型冠状病毒全基因组
本文的参考视频为:https://www.bilibili.com/video/BV13T4y15727?p=9
简介
官网:https://nanoporetech.com/
优势如下:
- Direct sequencing of native DNA/RNA, or samples that have been amplified with PCR/other methods 直接测序
- REAL Real-time 真正的实时性
- No capital cost required 无需对测序设备的资金投入
- Read any length of DNA/RNA - short to ultra-long 超长读长
- Scalable to portable or desktop 可扩展性,便携式或台式测序仪
- Simple & rapid, or automated, library prep 10分钟文库制备
- High yields for large genomes 对大基因组的高数据量测序
任何人、任何地点、能对任何生物进行分析
MinION is the only portable, real-time device for DNA and RNA sequencing, putting you in control of your sequence data. 只有手机大小,测序速度快

MinIon.jpg
可以应用到太空、海底的测序工作,可以说是世界上最高科技的产物
MinION一次最多可以产出30G的数据,这是人基因组的10倍(我们一般认为,当一个测序仪一次测序能够覆盖人的全基因组时,这个测序仪就合格了)目前MinION测序长度达到150kb。在未来一段时间,可以期许其测序长度可以得到更大提升。
而PromethION的规模更大,比如群体范围的、植物基因组的,一次可以运行48张芯片。每一张芯片都能按需要全部或独立运行。单张测序芯片内部最高通量200G左右,这样一次最多就可以产出9.6T的数据。假设每个人测30G数据,那么PromethION一次就可以测320个人的全基因组。

promethION.jpg
纳米孔技术三大难题
纳米孔材料:单链DNA直径只有1nm左右
碱基识别精度:碱基是非常小的分子
控制碱基流动速度
不同于HiSeq2000这种设备依赖复杂的光学系统,MinION基于电信号,因此可以做到很小的体积
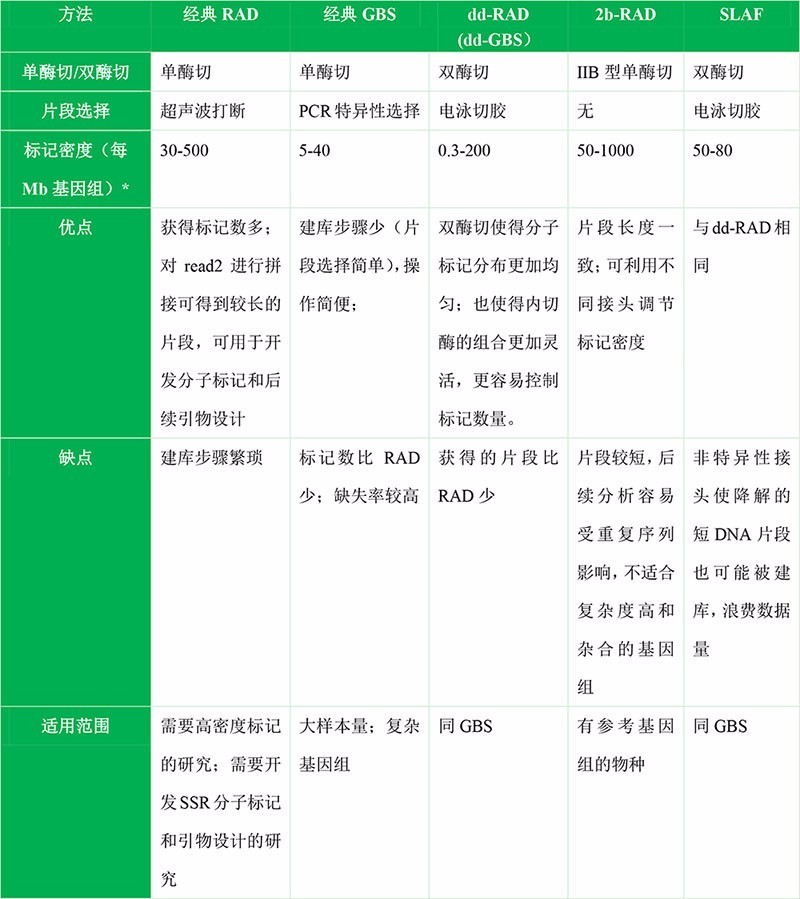
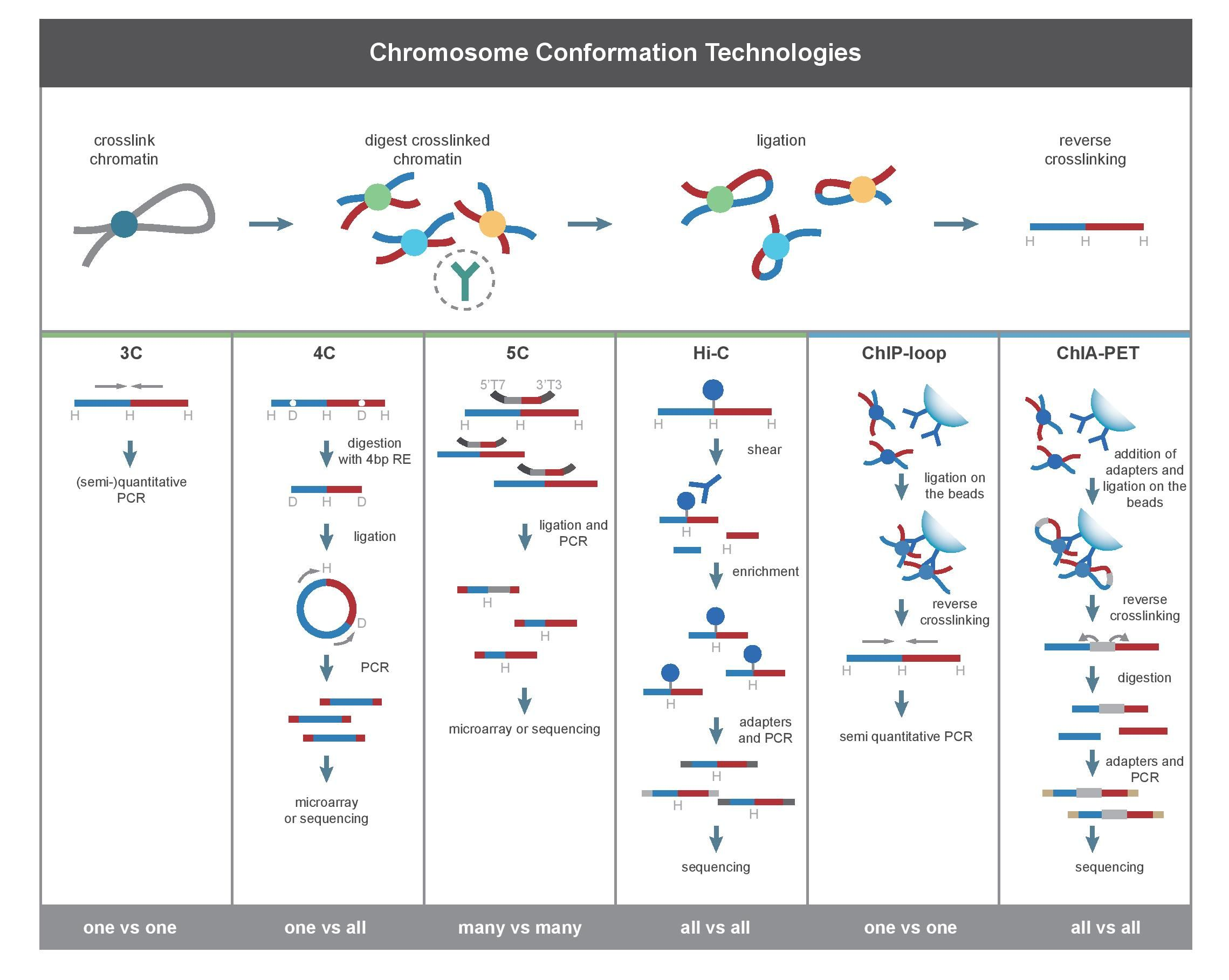
几种测序方案的比较
许多二代测序技术基于荧光信号,但单个碱基的荧光信号非常弱,因此需要进行扩增(一般要PCR),PCR带来的技术局限就是PCR限制了测序读长,PCR带来扩增的偏向性,比如GC的偏向
不过光信号的优点是,碱基一个一个识别(解决同聚物的问题,纳米孔测序可能存在同聚物识别问题),信号足够强,准确率相对高。
Pacbio的文库比较特殊,是环状的,它虽然是基于光信号但测序错误率还是比较高的因为是单分子信号,可以通过增加环状测序cycle增加覆盖度来尽可能弥补。测序数据分析参考:https://zhuanlan.zhihu.com/p/77547922
视频可以参考:https://www.bilibili.com/video/BV1f7411n7zU?p=23
如下是Pacbio的文库结构,聚合酶在分子上可以反复跑多次,充分反映了长读长的特点。
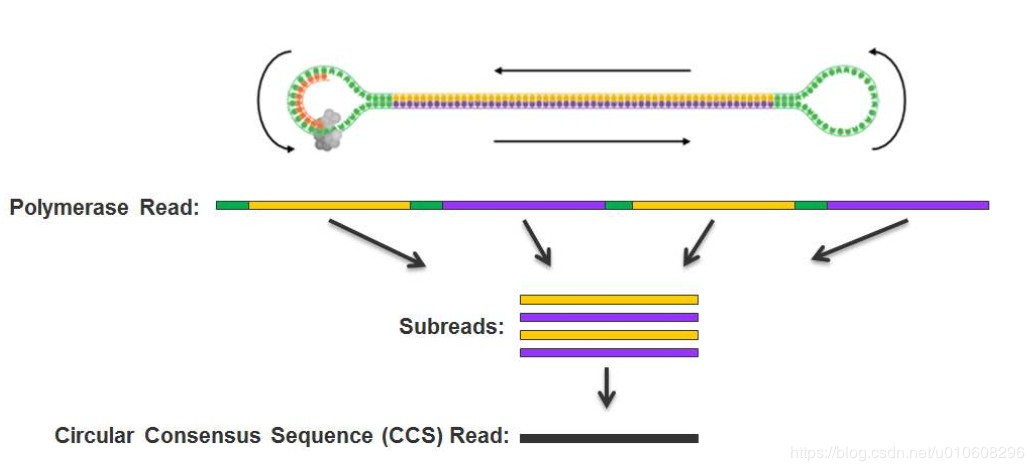
PacBio.jpg
纳米孔测序是目前唯一使用电信号进行测序的设备。速度快(比如大大节省建库的时间),其他优势在简介中也提到过,而且也只有这个技术可以实现RNA的直接测序(也可以直接识别U,不用反转录)[甚至以后氨基酸序列直接测序也可以实现]
使用电信号的缺点:只测序单个分子,目前准确性较低。无法准确识别同聚物的重复碱基个数,存在插入确实错误
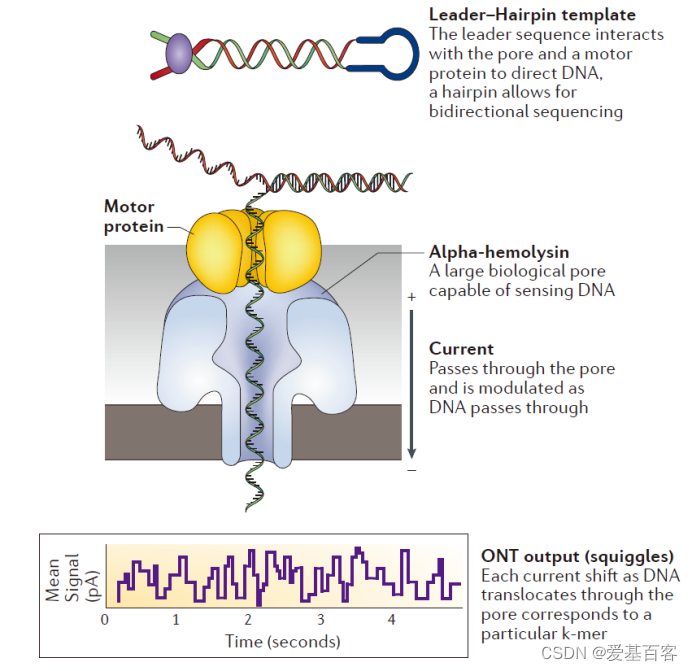
Nanopore测序原理
在一个高电阻膜上嵌入一个蛋白通道,只容许一个DNA分子通过
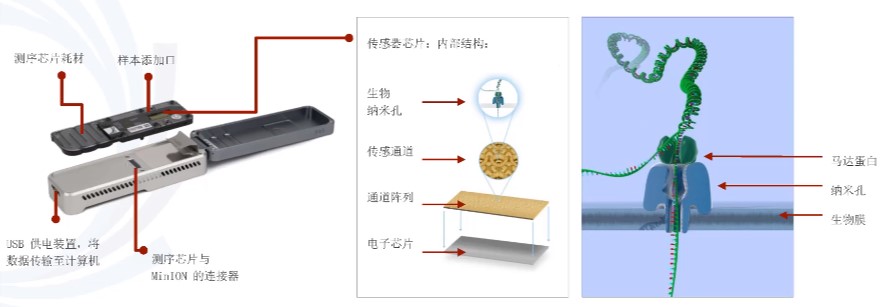
原理.jpg
纳米孔两侧存在电压,DNA链在马达蛋白的牵引下解螺旋,当有碱基通过时引起电流变化,不同的分子通过纳米孔时会对电流产生不同的干扰。
建库就是在DNA接头的两端加上马达蛋白,马达蛋白控制DNA的流速,这个速度是可以控制的
1D测序就是测单独一条链,2D测序类似illumina的PE测序,pairwise alignment, 它们组合成2D read
1D2连接试剂盒的特殊接头可以使得正义链测完以后互补链随之进入同一个纳米孔进行测序,用于序列的自我校正。
文库构建
建库需要弄清几个问题:
- DNA还是RNA?
- 是否要PCR? 稀有样本只能PCR,达不到input要求
- 是否加barcode?混样测序降低成本,数据最大化利用,而且可以避免芯片的批次效应
-
1D测序,2D测序还是1D2测序?
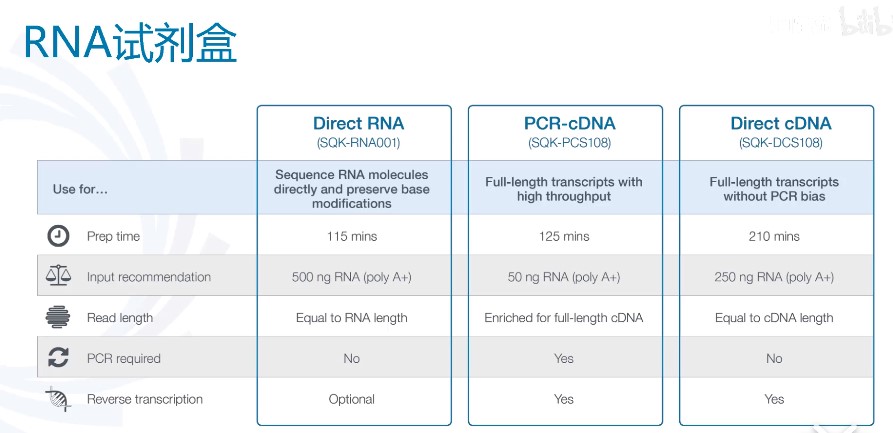
RNA试剂盒.jpg
Basecalling
Basecalling就是把碱基的电信号值转换成我们需要的碱基序列
信号值长这样:“剪不断,理还乱”

squigle.jpg
每秒可以流过450个碱基,5个碱基为一组(kmer),也就是这一组共同产生一个信号值,4的5次方,1024种组合,结合训练集,像破译密码一样,破译序列。但实际情况更复杂,可能4个一组或者6个一组,还可能有甲基化对信号的干扰。
这就是用已知信息推测未知信息的方法,机器学习。比如可以考虑HMM(隐马模型),观测值是信号,隐状态是对应碱基。
basecalling的算法准确性在逐渐提升
fast5文件格式
fast5格式是nanopore测序输出的结果文件格式,扩展名为.fast5。fast5是hdf5文件格式的一种变种,而HDF(Hierarchical Data Format),是一种设计用于存储和组织大量数据的文件格式,一般扩展名为.hdf5或.h5,表示现在使用的版本是第五个版本。这是一种分级的数据文件,可以存储不同类型的图像和数码数据的文件格式,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。fast5里面可以包含很多的内容,并且可以继续添加。简单理解,这种文件类似于一个经过压缩的文件夹,里面包含很多文件,如下图所示:
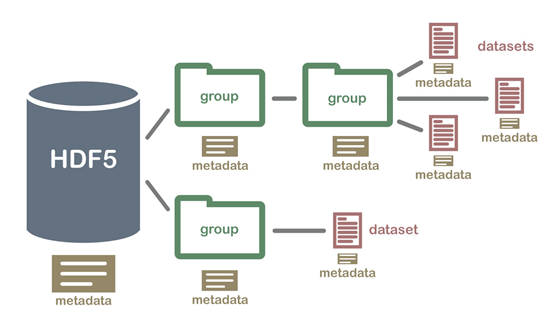
fast5.jpg
nanopore测序过程中,一个纳米孔测序完一条序列,则可以输出一个fast5文件,一个MinION的flowcell就生成10-20Gb的数据量,有几百万的条reads,这百万千万级别的文件处理就是一个大麻烦,需要反复打开关闭IO,完成一次文件拷贝和统计要花很长时间。19年以前的fast5文件是一条序列一个fast5文件,现在新的MinKNOW做了升级,可以设定生成multi_fast5文件,一个fast5包含的reads数目可以自己设定,一般4,000。
参考:http://www.360doc.com/content/19/1108/07/52645714_871804718.shtml
- fast5格式作为Nanopore测序直接的输出格式,记录电流随时间变化的情况。还包括纳米孔的状况比如电压、温度
- 电流的变化记录了通过的碱基,及碱基上的修饰信息
- 修饰信息和碱基通过速度对识别精度有影响
- 可以使用HDFview软件直接打开
- 实时分析使用GUI软件MinKNOW,其中的碱基识别模块GUPPY具备命令行版本可单独进行本地basecalling,输出fastq文件
- 碱基识别算法基于机器学习进行训练,更新速度很快
fast5相比fastq非常消耗存储。这是最大缺点,因为有很多meta信息
纳米孔测序错误率高吗
错误率从最开始的40%现在最少已降低到5%
错误来源
- ATCG碱基化学结构相似,通过电信号不易区分
- 每个碱基只测一次(顶多再测到互补链,2次)
- 每次检测到的信号不是单个碱基,而是几个碱基共同的信号
- 发生了甲基化会对电流产生干扰,这使得碱基识别更加复杂,前面有提到
- 化学反应体系影响,考虑到ATP酶,马达蛋白的活性问题
减少错误
- 提高纳米孔性能,比如R10新型纳米孔芯片有助于解决同聚物错误率的问题
- 建库方法
- 改善碱基识别算法
- 开发测序后的碱基纠错算法
纳米孔测序黑科技
怎么获得想要的基因区域的序列信息,比如肿瘤研究,不需要基因组全测
获得病毒的基因组,但是测的大部分都是宿主的序列
PCR扩增,外显子捕获,CRISPR-Cas9技术捕获目标序列(Targeted nanopore sequencing with Cas9-guided adapter ligation,不过可能脱靶,需要很多时间来测试)
纳米孔有一种灵活性采样方法(Adaptive sampling),没有感兴趣区域时可以反向电压让DNA链弹出,空出的纳米孔用于下一条序列分析,有感兴趣的则继续测下去。
因为是实时的,所以可以实时比对产出的序列,如果能比对上感兴趣的目标序列则继续,否则弹出。比如选择性富集外显子。但碱基识别一定要快(450bp/s),不然纳米孔里已经产生很多数据了。当然还有直接使用原始信号进行富集的UNCALLED。
纳米孔测序价格
这个价格以后可能会变,新手套餐目前是17000多元,包括一台小测序仪、2张测序芯片、快速建库试剂盒等,可以上官网查看。新手套餐每个用户只能领取一次。
其实最值钱的还是测序芯片,8000-9000一张,做的好2张芯片够测一个人的基因组,做的不好可能2张芯片浪费了(质检出问题、测序过程出问题,纳米孔被堵塞导致有活性的纳米孔大大较少等等),就只剩下一个测序仪玩具。