文章目录
- 一、贝叶斯简介
- 二、贝叶斯公式推导
- 三、拼写纠正案例
- 四、垃圾邮件过滤案例
- 4.1 问题描述
- 4.2 朴素贝叶斯引入
- 五、基于朴素贝叶斯的垃圾邮件过滤实战
- 5.1 导入相关库
- 5.2 邮件数据读取
- 5.3 构建语料表(字典)
- 5.4 构建训练集的特征向量
- 5.5 朴素贝叶斯算法计算概率
- 5.6 贝叶斯公式的对数变换 + 邮件类别预测
- 5.7 完整代码 + 运行输出
一、贝叶斯简介

贝叶斯主要解决的问题是“逆概”问题,那么什么是正向概率什么是逆向概率呢,下面给出解释:

二、贝叶斯公式推导
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。如上公式也可变形为:P(A|B)=P(B|A)*P(A)/P(B)。
下面举一个例子来推导贝叶斯公式:

解答如下:




最终得到贝叶斯公式如下:
P ( A ∣ B ) = P ( A ) × P ( B ∣ A ) P ( B ) P(A|B)=\frac{P(A)×P(B|A)}{P(B)} P(A∣B)=P(B)P(A)×P(B∣A)
三、拼写纠正案例
问题描述如下:
例如,用户拼写 thr ,我们猜测他可能想拼写 the

根据贝叶斯公式,我们可以得到如下结论:

由于用户实际输入的单词是已知的,所以P(D)是一个常数,所以上式的P(D)其实可以忽略。
P(h)是我们猜测词可能出现的概率,这个概率可以通过从一个庞大的语料库中统计获取
P(D|h)是当用户实际像输入的词是h时,用户输入D的概率。假设D是thr,h是the,那么P(D|h)我们可以通过计算thr要通过多少步的增删改操作才能变为the,所需要的步数越少,P(D|h)概率越大。

其中,P(h)又叫先验概率,是我们从庞大语料库中可以获取到的已知概率

贝叶斯和最大似然的区别在于,最大似然的结果由数据决定,而贝叶斯的结果由先验概率决定。例如,抛硬币游戏,前一百次都抛了正面,最大似然会认为下一次抛肯定还是正面。但是贝叶斯由于有先验概率的存在,无论如何他都认为下一次抛出正面的概率是0.5。

四、垃圾邮件过滤案例
4.1 问题描述
问题的相关描述如下:

4.2 朴素贝叶斯引入
一封邮件里有很多单词,从实际出发,第二个词出现的概率其实是受第一个词的影响的。所以将P(d1,d2,…,dn|h+)扩展之后的公式如下所示:

像上面那样展开的话就会导致计算非常复杂,为了简化计算,我们可以假设相邻词之间是独立无关的,这样就可以将展开后的式子简化为下图所示的式子(朴素贝叶斯就是比贝叶斯多了独立无关这个假设):

五、基于朴素贝叶斯的垃圾邮件过滤实战
本章节的完整代码和邮件数据集的链接为:Python代码实现基于朴素贝叶斯算法的垃圾邮件分类
5.1 导入相关库
import numpy as np
import re
import random
5.2 邮件数据读取
下面是数据集的截图(每一行代表一封邮件),格式为:邮件类别
\t邮件内容

# 数据预处理操作(词的切分、词转化为小写)
def text_parse(input_str):word_list = re.split(r"\W+", input_str)return [word.lower() for word in word_list if len(word_list) > 2 and len(word) > 0]# 获取数据
def read_data():doc_list = []class_list = []with open("./data/SMS.txt", "r", encoding="utf-8") as file:datas = file.read()# print(data)datas = datas.split("\n")for data in datas:# label = ham 代表 正常邮件 , label = spam 代表垃圾邮件label, text = data.split("\t")doc_list.append(text_parse(text))# 0:正常邮件,1:垃圾邮件class_list.append(0 if label == "ham" else 1)return doc_list, class_list
5.3 构建语料表(字典)
# 构建语料表
def create_vocabulary_list(doc_list):vocabulary_set = set([])for document in doc_list:vocabulary_set = vocabulary_set | set(document)return list(vocabulary_set)
5.4 构建训练集的特征向量
# 将一篇邮件转化为 类似 One-Hot 的向量,长度和 vocabulary_list 一样,为 1 的位置代表该单词在该邮件中出现了
def set_of_word2vector(vocabulary_list, document):vec = [0 for _ in range(len(vocabulary_list))]for word in document:index = vocabulary_list.index(word)if index >= 0:vec[index] = 1return vectrain_matrix = []
train_class = []
for train_index in train_index_set:train_matrix.append(set_of_word2vector(vocabulary_list, doc_list[train_index]))train_class.append(class_list[train_index])
5.5 朴素贝叶斯算法计算概率
回顾一下,我们用贝叶斯算法进行垃圾邮件分类时,其实就是比较 P ( h + ∣ D ) P(h_+|D) P(h+∣D) 和 P ( h − ∣ D ) P(h_-|D) P(h−∣D) 的大小,如果 P ( h + ∣ D ) P(h_+|D) P(h+∣D) 大,则表示该邮件更有可能是垃圾邮件,否则更有可能是正常邮件。
P ( h + ∣ D ) = P ( h + ) × P ( D ∣ h + ) ÷ P ( D ) P ( h − ∣ D ) = P ( h − ) × P ( D ∣ h − ) ÷ P ( D ) P(h_+|D)=P(h_+)×P(D|h_+)\div P(D) \\ P(h_-|D)=P(h_-)×P(D|h_-)\div P(D) P(h+∣D)=P(h+)×P(D∣h+)÷P(D)P(h−∣D)=P(h−)×P(D∣h−)÷P(D)
又因为,在针对某封邮件做预测时, P ( D ) P(D) P(D) 可以看作常数,因而可以忽略,从而得到简化后的公式如下(其实下面式子写等号不严谨,应该是正比于,但是为了方便,后面都将正比于简化为等号):
P ( h + ∣ D ) = P ( h + ) × P ( D ∣ h + ) P ( h − ∣ D ) = P ( h − ) × P ( D ∣ h − ) P(h_+|D)=P(h_+)×P(D|h_+) \\ P(h_-|D)=P(h_-)×P(D|h_-) P(h+∣D)=P(h+)×P(D∣h+)P(h−∣D)=P(h−)×P(D∣h−)
其中, P ( h + ) P(h_+) P(h+) 为训练集中垃圾邮件的比率, P ( h − ) P(h_-) P(h−)为训练集中正常邮件的比率,它们两个就是先验概率。
显然, P ( h + ) + P ( h − ) = 1 P(h_+) + P(h_-) = 1 P(h+)+P(h−)=1,因此,下面我们可以只计算 P ( h + ) P(h_+) P(h+),用变量 p_spam 表示, P ( h + ) P(h_+) P(h+) 可以根据训练集很轻易地得到
又因为朴素贝叶斯假设任意两个词之间是独立无关的,所以可以将 P ( D ∣ h + ) P(D|h_+) P(D∣h+) 和 P ( D ∣ h − ) P(D|h_-) P(D∣h−) 展开如下:
P ( D ∣ h + ) = P ( d 1 ∣ h + ) × P ( d 2 ∣ h + ) × . . . × P ( d n ∣ h + ) P ( D ∣ h − ) = P ( d 1 ∣ h − ) × P ( d 2 ∣ h − ) × . . . × P ( d n ∣ h − ) P(D|h_+) = P(d_1|h_+)×P(d_2|h_+)×...×P(d_n|h_+)\\ P(D|h_-) = P(d_1|h_-)×P(d_2|h_-)×...×P(d_n|h_-) P(D∣h+)=P(d1∣h+)×P(d2∣h+)×...×P(dn∣h+)P(D∣h−)=P(d1∣h−)×P(d2∣h−)×...×P(dn∣h−)
其中 d n d_n dn 代表邮件 D D D中的第 n n n 个单词。 P ( d n ∣ h + ) P(d_n|h_+) P(dn∣h+) 表示邮件 D D D中的第 n n n 个单词在垃圾邮件中出现的概率。所以有:
P ( d n ∣ h + ) = C ( d n ∣ h + ) C ( h + ) P ( d n ∣ h − ) = C ( d n ∣ h − ) C ( h − ) P(d_n|h_+)=\frac{C(d_n|h_+)}{C(h_+)} \\ P(d_n|h_-)=\frac{C(d_n|h_-)}{C(h_-)} P(dn∣h+)=C(h+)C(dn∣h+)P(dn∣h−)=C(h−)C(dn∣h−)
其中 C ( d n ∣ h + ) C(d_n|h_+) C(dn∣h+) 表示邮件 D D D中的第 n n n 个单词在垃圾邮件中出现的次数; C ( d n ∣ h − ) C(d_n|h_-) C(dn∣h−) 表示表示邮件 D D D中的第 n n n 个单词在正常邮件中出现的次数; C ( h + ) C(h_+) C(h+) 表示垃圾邮件中的总单词数, C ( h − ) C(h_-) C(h−) 表示正常邮件中的总单词数。根据上式,可以推导出:
P ( D ∣ h + ) = C ( d 1 ∣ h + ) C ( h + ) × C ( d 2 ∣ h + ) C ( h + ) × . . . × C ( d n ∣ h + ) C ( h + ) P ( D ∣ h − ) = C ( d 1 ∣ h − ) C ( h − ) × C ( d 2 ∣ h − ) C ( h − ) × . . . × C ( d n ∣ h − ) C ( h − ) P(D|h_+) = \frac{C(d_1|h_+)}{C(h_+)}×\frac{C(d_2|h_+)}{C(h_+)}×...×\frac{C(d_n|h_+)}{C(h_+)}\\ P(D|h_-) = \frac{C(d_1|h_-)}{C(h_-)}×\frac{C(d_2|h_-)}{C(h_-)}×...×\frac{C(d_n|h_-)}{C(h_-)} P(D∣h+)=C(h+)C(d1∣h+)×C(h+)C(d2∣h+)×...×C(h+)C(dn∣h+)P(D∣h−)=C(h−)C(d1∣h−)×C(h−)C(d2∣h−)×...×C(h−)C(dn∣h−)
下面的代码中,我并没有直接计算出 P ( D ∣ h + ) P(D|h_+) P(D∣h+) 和 P ( D ∣ h − ) P(D|h_-) P(D∣h−),而是计算出了 C ( d 1 ∣ h + ) C ( h + ) 、 C ( d 2 ∣ h + ) C ( h + ) 、 . . . 、 C ( d n ∣ h + ) C ( h + ) \frac{C(d_1|h_+)}{C(h_+)}、\frac{C(d_2|h_+)}{C(h_+)}、...、\frac{C(d_n|h_+)}{C(h_+)} C(h+)C(d1∣h+)、C(h+)C(d2∣h+)、...、C(h+)C(dn∣h+) 和 C ( d 1 ∣ h − ) C ( h − ) 、 C ( d 2 ∣ h − ) C ( h − ) 、 . . . 、 C ( d n ∣ h − ) C ( h − ) \frac{C(d_1|h_-)}{C(h_-)}、\frac{C(d_2|h_-)}{C(h_-)}、...、\frac{C(d_n|h_-)}{C(h_-)} C(h−)C(d1∣h−)、C(h−)C(d2∣h−)、...、C(h−)C(dn∣h−),并把它们分别存在了两个列表中(p_spam_vec 和 p_ham_vec)
以计算 C ( d 1 ∣ h + ) C ( h + ) 、 C ( d 2 ∣ h + ) C ( h + ) 、 . . . 、 C ( d n ∣ h + ) C ( h + ) \frac{C(d_1|h_+)}{C(h_+)}、\frac{C(d_2|h_+)}{C(h_+)}、...、\frac{C(d_n|h_+)}{C(h_+)} C(h+)C(d1∣h+)、C(h+)C(d2∣h+)、...、C(h+)C(dn∣h+) 为例,在计算它们的过程中用到了两个辅助变量 p_spam_molecule 和 p_spam_denominator,分别代表 C ( d n ∣ h + ) C ( h + ) \frac{C(d_n|h_+)}{C(h_+)} C(h+)C(dn∣h+) 的分子和分母。
但是按照上面的公式,有一些时候会出问题。下面进行问题说明和解决方案的阐述:
问题一:假设某个单词没有出现在垃圾邮件中,意味着 C ( d n ∣ h + ) = 0 C(d_n|h_+)=0 C(dn∣h+)=0,即 P ( d n ∣ h + ) = 0 P(d_n|h_+)=0 P(dn∣h+)=0。又因为 P ( D ∣ h + ) = P ( d 1 ∣ h + ) × P ( d 2 ∣ h + ) × . . . × P ( d n ∣ h + ) P(D|h_+) = P(d_1|h_+)×P(d_2|h_+)×...×P(d_n|h_+) P(D∣h+)=P(d1∣h+)×P(d2∣h+)×...×P(dn∣h+) 是连乘的,所以只要一个元素为0,那么最终 P ( D ∣ h + ) P(D|h_+) P(D∣h+) 就为0。
问题二:假设训练集中没有垃圾邮件,意味着 C ( h + ) = 0 C(h_+)=0 C(h+)=0,即公式 P ( d n ∣ h + ) = C ( d n ∣ h + ) C ( h + ) P(d_n|h_+)=\frac{C(d_n|h_+)}{C(h_+)} P(dn∣h+)=C(h+)C(dn∣h+) 的分母为0,此时作除法是会引发异常的
为了解决上述两个问题,我们在下面的代码中做了平滑处理,又叫做拉普拉斯平滑。
针对问题一:我们假设 C ( d n ∣ h + ) C(d_n|h_+) C(dn∣h+) 至少为 1,所以下面代码中用了 np.ones() 函数对分子进行初始化,而不是用 np.zeros()
针对问题二:我们假设 C ( h + ) C(h_+) C(h+) 至少为 m(m通常为该分类任务中的类别数量,例如在垃圾邮件分类中,只有垃圾和正常两种邮件,所以m为2)
以此类推,对于 C ( d n ∣ h − ) C(d_n|h_-) C(dn∣h−) 和 C ( h − ) C(h_-) C(h−) 也是一样。
# 用朴素贝叶斯算法进行计算
def naive_bayes(train_matrix, train_class):# 样本个数train_data_size = len(train_class)# 语料库大小vocabulary_size = len(train_matrix[0])# 计算垃圾邮件的概率值p_spam = sum(train_class) / train_data_size# 初始化分子,做了一个平滑处理(拉普拉斯平滑)p_ham_molecule = np.ones(vocabulary_size)p_spam_molecule = np.ones(vocabulary_size)# 初始化分母(通常初始化为类别个数,在垃圾邮件分类中,只有垃圾和正常两种邮件,所以类别数为2)p_ham_denominator = 2p_spam_denominator = 2# 循环计算分子和分母for i in range(train_data_size):if train_class[i] == 1:p_spam_molecule += train_matrix[i]p_spam_denominator += sum(train_matrix[i])else:p_ham_molecule += train_matrix[i]p_ham_denominator += sum(train_matrix[i])# 计算概率p_ham_vec = p_ham_molecule / p_ham_denominatorp_spam_vec = p_spam_molecule / p_spam_denominator# 返回return p_ham_vec, p_spam_vec, p_spam
5.6 贝叶斯公式的对数变换 + 邮件类别预测
回顾上面介绍过的公式:
P ( h + ∣ D ) = P ( h + ) × P ( D ∣ h + ) P ( h − ∣ D ) = P ( h − ) × P ( D ∣ h − ) P(h_+|D)=P(h_+)×P(D|h_+) \\ P(h_-|D)=P(h_-)×P(D|h_-) P(h+∣D)=P(h+)×P(D∣h+)P(h−∣D)=P(h−)×P(D∣h−)
根据上一节的函数,我们已经能够求得 P ( h + ) 、 P ( D ∣ h + ) 、 P ( h − ) 、 P ( D ∣ h − ) P(h_+)、P(D|h_+)、P(h_-)、P(D|h_-) P(h+)、P(D∣h+)、P(h−)、P(D∣h−)了。但是 P ( D ∣ h + ) = P ( d 1 ∣ h + ) × P ( d 2 ∣ h + ) × . . . × P ( d n ∣ h + ) P(D|h_+) = P(d_1|h_+)×P(d_2|h_+)×...×P(d_n|h_+) P(D∣h+)=P(d1∣h+)×P(d2∣h+)×...×P(dn∣h+) 是连乘的,且每一项都是在 [0,1] 区间内的,这也就意味着经过连乘之后, P ( D ∣ h + ) P(D|h_+) P(D∣h+) 和 P ( D ∣ h − ) P(D|h_-) P(D∣h−) 的值往往非常小。这是不利于它们之间大小比较的。
所以我们通常采用取对数(通常是取自然对数 ln \ln ln)的方式,将它们“放大”。下面是自然对数的图像:

取自然对数之后,公式变为:
ln ( P ( h + ∣ D ) ) = ln ( P ( h + ) × P ( D ∣ h + ) ) = ln ( P ( h + ) ) + ln ( P ( D ∣ h + ) ) ln ( P ( h − ∣ D ) ) = ln ( P ( h − ) × P ( D ∣ h − ) ) = ln ( P ( h − ) ) + ln ( P ( D ∣ h − ) ) \ln(P(h_+|D))=\ln(P(h_+)×P(D|h_+))=\ln(P(h_+))+\ln(P(D|h_+)) \\ \ln(P(h_-|D))=\ln(P(h_-)×P(D|h_-))=\ln(P(h_-))+\ln(P(D|h_-)) ln(P(h+∣D))=ln(P(h+)×P(D∣h+))=ln(P(h+))+ln(P(D∣h+))ln(P(h−∣D))=ln(P(h−)×P(D∣h−))=ln(P(h−))+ln(P(D∣h−))
其中:
ln ( P ( D ∣ h + ) ) = ln ( P ( d 1 ∣ h + ) × P ( d 2 ∣ h + ) × . . . × P ( d n ∣ h + ) ) = ln ( P ( d 1 ∣ h + ) ) + ln ( P ( d 2 ∣ h + ) ) + . . . + ln ( P ( d n ∣ h + ) ) ln ( P ( D ∣ h − ) ) = ln ( P ( d 1 ∣ h − ) × P ( d 2 ∣ h − ) × . . . × P ( d n ∣ h − ) ) = ln ( P ( d 1 ∣ h − ) ) + ln ( P ( d 2 ∣ h − ) ) + . . . + ln ( P ( d n ∣ h − ) ) \ln(P(D|h_+))=\ln(P(d_1|h_+)×P(d_2|h_+)×...×P(d_n|h_+))=\ln(P(d_1|h_+))+\ln(P(d_2|h_+))+...+\ln(P(d_n|h_+)) \\ \ln(P(D|h_-))=\ln(P(d_1|h_-)×P(d_2|h_-)×...×P(d_n|h_-))=\ln(P(d_1|h_-))+\ln(P(d_2|h_-))+...+\ln(P(d_n|h_-)) ln(P(D∣h+))=ln(P(d1∣h+)×P(d2∣h+)×...×P(dn∣h+))=ln(P(d1∣h+))+ln(P(d2∣h+))+...+ln(P(dn∣h+))ln(P(D∣h−))=ln(P(d1∣h−)×P(d2∣h−)×...×P(dn∣h−))=ln(P(d1∣h−))+ln(P(d2∣h−))+...+ln(P(dn∣h−))
综上可得:
ln ( P ( h + ∣ D ) ) = ln ( P ( h + ) ) + [ ln ( P ( d 1 ∣ h + ) ) + ln ( P ( d 2 ∣ h + ) ) + . . . + ln ( P ( d n ∣ h + ) ) ] ln ( P ( h − ∣ D ) ) = ln ( P ( h − ) ) + [ ln ( P ( d 1 ∣ h − ) ) + ln ( P ( d 2 ∣ h − ) ) + . . . + ln ( P ( d n ∣ h − ) ) ] \ln(P(h_+|D))=\ln(P(h_+))+[\ln(P(d_1|h_+))+\ln(P(d_2|h_+))+...+\ln(P(d_n|h_+))] \\ \ln(P(h_-|D))=\ln(P(h_-))+[\ln(P(d_1|h_-))+\ln(P(d_2|h_-))+...+\ln(P(d_n|h_-))] ln(P(h+∣D))=ln(P(h+))+[ln(P(d1∣h+))+ln(P(d2∣h+))+...+ln(P(dn∣h+))]ln(P(h−∣D))=ln(P(h−))+[ln(P(d1∣h−))+ln(P(d2∣h−))+...+ln(P(dn∣h−))]
# 预测,返回预测的类别
def predict(vec, p_ham_vec, p_spam_vec, p_spam):# 由于计算出来的概率通常很接近0,所以我们通常取对数将它“放大”,这也基于我们在做贝叶斯的时候,不需要知道他们确切的概率,只需要比较他们概率大小即可p_spam = np.log(p_spam) + sum(vec * np.log(p_spam_vec))p_ham = np.log(1 - p_spam) + sum(vec * np.log(p_ham_vec))return 1 if p_spam >= p_ham else 0
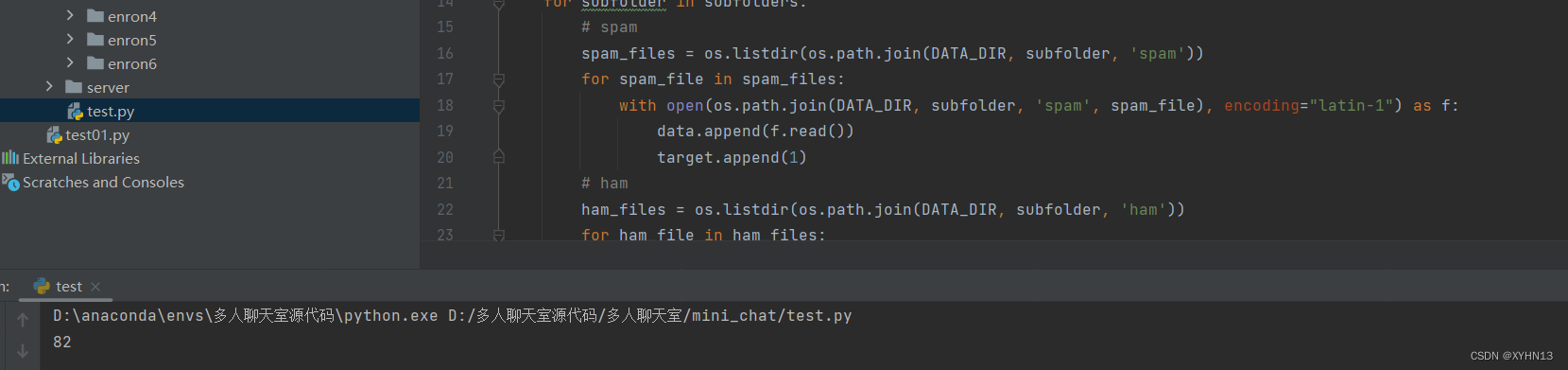
5.7 完整代码 + 运行输出
完整代码
import numpy as np
import re
import random# 数据预处理操作(词的切分、词转化为小写)
def text_parse(input_str):word_list = re.split(r"\W+", input_str)return [word.lower() for word in word_list if len(word_list) > 2 and len(word) > 0]# 获取数据
def read_data():doc_list = []class_list = []with open("./data/SMS.txt", "r", encoding="utf-8") as file:datas = file.read()# print(data)datas = datas.split("\n")for data in datas:# label = ham 代表 正常邮件 , label = spam 代表垃圾邮件label, text = data.split("\t")doc_list.append(text_parse(text))# 0:正常邮件,1:垃圾邮件class_list.append(0 if label == "ham" else 1)return doc_list, class_list# 构建语料表
def create_vocabulary_list(doc_list):vocabulary_set = set([])for document in doc_list:vocabulary_set = vocabulary_set | set(document)return list(vocabulary_set)# 将一篇邮件转化为 类似 One-Hot 的向量,长度和 vocabulary_list 一样,为 1 的位置代表该单词在该邮件中出现了
def set_of_word2vector(vocabulary_list, document):vec = [0 for _ in range(len(vocabulary_list))]for word in document:index = vocabulary_list.index(word)if index >= 0:vec[index] = 1return vec# 用朴素贝叶斯算法进行计算
def naive_bayes(train_matrix, train_class):# 样本个数train_data_size = len(train_class)# 语料库大小vocabulary_size = len(train_matrix[0])# 计算垃圾邮件的概率值p_spam = sum(train_class) / train_data_size# 初始化分子,做了一个平滑处理(拉普拉斯平滑)p_ham_molecule = np.ones(vocabulary_size)p_spam_molecule = np.ones(vocabulary_size)# 初始化分母(通常初始化为类别个数,在垃圾邮件分类中,只有垃圾和正常两种邮件,所以类别数为2)p_ham_denominator = 2p_spam_denominator = 2# 循环计算分子和分母for i in range(train_data_size):if train_class[i] == 1:p_spam_molecule += train_matrix[i]p_spam_denominator += sum(train_matrix[i])else:p_ham_molecule += train_matrix[i]p_ham_denominator += sum(train_matrix[i])# 计算概率p_ham_vec = p_ham_molecule / p_ham_denominatorp_spam_vec = p_spam_molecule / p_spam_denominator# 返回return p_ham_vec, p_spam_vec, p_spam# 预测,返回预测的类别
def predict(vec, p_ham_vec, p_spam_vec, p_spam):# 由于计算出来的概率通常很接近0,所以我们通常取对数将它“放大”,这也基于我们在做贝叶斯的时候,不需要知道他们确切的概率,只需要比较他们概率大小即可p_spam = np.log(p_spam) + sum(vec * np.log(p_spam_vec))p_ham = np.log(1 - p_spam) + sum(vec * np.log(p_ham_vec))return 1 if p_spam >= p_ham else 0if __name__ == '__main__':# 读取数据doc_list, class_list = read_data()print(f"A total of {len(class_list)} email data were read, including {sum(class_list)} spam")# 构建语料表vocabulary_list = create_vocabulary_list(doc_list)# 划分训练集和测试集test_ratio = 0.3train_index_set = [i for i in range(len(doc_list))]test_index_set = []for _ in range(int(len(doc_list) * test_ratio)):index = random.randint(0, len(train_index_set) - 1)test_index_set.append(train_index_set[index])del train_index_set[index]print(f"test_ratio: {test_ratio} , train_data_size: {len(train_index_set)} , test_data_size: {len(test_index_set)}")# 将邮件转化为向量train_matrix = []train_class = []for train_index in train_index_set:train_matrix.append(set_of_word2vector(vocabulary_list, doc_list[train_index]))train_class.append(class_list[train_index])# 用朴素贝叶斯算法进行计算p_ham_vec, p_spam_vec, p_spam = naive_bayes(np.array(train_matrix), np.array(train_class))# 测试部分# 记录预测正确的数量acc_cnt = 0for test_index in test_index_set:vec = set_of_word2vector(vocabulary_list, doc_list[test_index])predict_class = predict(vec, p_ham_vec, p_spam_vec, p_spam)if predict_class == class_list[test_index]:acc_cnt += 1print(f"test accuracy: {acc_cnt / len(test_index_set)}")
运行输出
A total of 5574 email data were read, including 747 spam
test_ratio: 0.3 , train_data_size: 3902 , test_data_size: 1672
test accuracy: 0.9826555023923444