一、朴素贝叶斯实现垃圾邮件分类的原理
什么是朴素贝叶斯算法:用贝叶斯定理来预测一个未知类别的样本属于各个类别的可能性,选择可能性最大的一个类别作为该样本的最终类别。
用这个算法处理垃圾邮件就可以理解为:用贝叶斯定理来预测一封由若干个单词组成的不知道是否为垃圾邮件的邮件,它是垃圾邮件或是正常邮件的可能性,如果算法预测出垃圾邮件的可能性更高,那这封邮件就是垃圾邮件,反之为正常邮件。
二、贝叶斯定理
贝叶斯定理告诉我们如何交换条件概率中的条件与结果,即如果已知 P(X|Y),要求 P(Y|X):
P(Y∣X)=P(X∣Y)P(Y)/P(X)
P(Y):先验概率。P(Y∣X):后验概率。P(X∣Y) :条件概率,又叫似然概率,一般是通过历史数据统计得到。
三、 朴素贝叶斯分类

朴素贝叶斯分类通过训练集学习联合概率分布,其实就是学习先验概率分布和条件概率分布。
其中先验概率分布为:
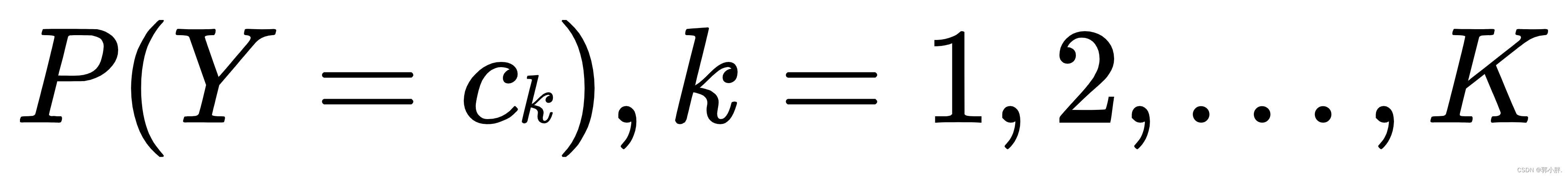
条件概率分布为:
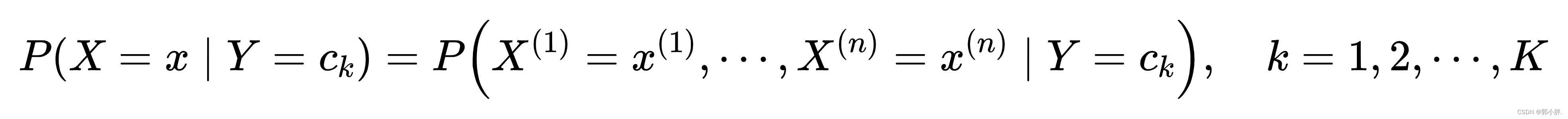
于是可以通过条件概率公式得出联合概率分布 ,
朴素贝叶斯算法对条件概率做了条件独立性的假设。由于这是一个较强的假设,朴素贝叶斯算法也由此得名。具体地,条件独立性假设是:
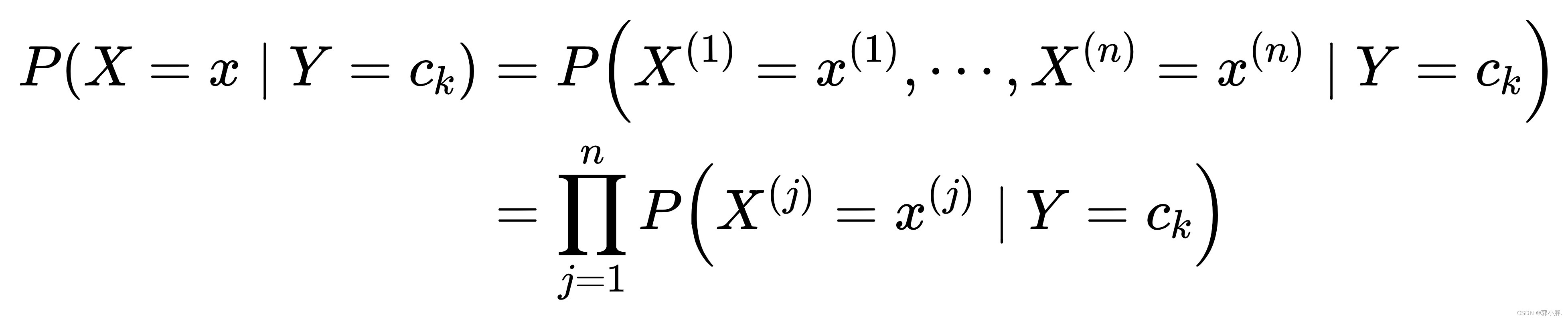
后验概率根据贝叶斯定理进行计算:
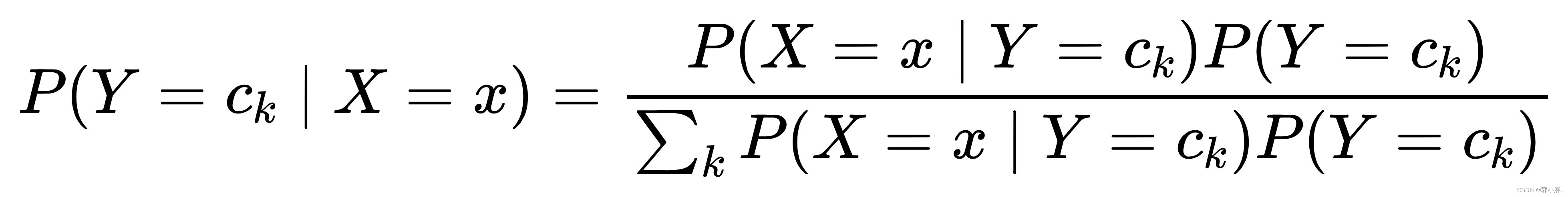
再将条件独立性假设代入上面的式子,得到了朴素贝叶斯分类的基本公式:
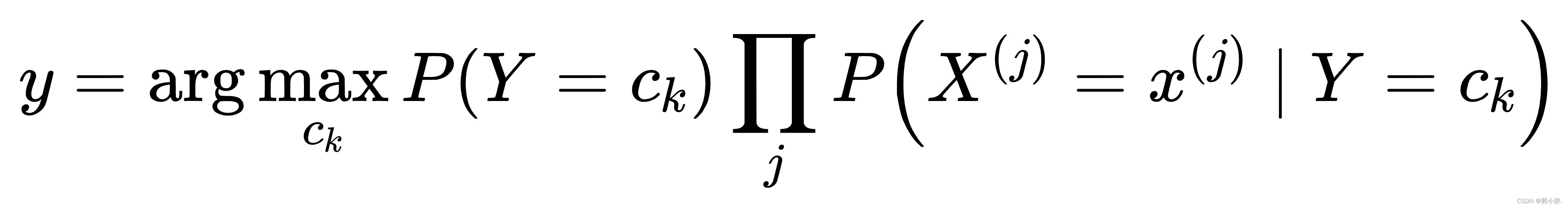
拉普拉斯修正
在用朴素贝叶斯分类判断文本类别的时候,要计算多个概率的乘积。如果样本中的某些单词不在词汇表中出现,则连乘后概率为0,无法进行判断。因此我们在计算概率的时要用拉普拉斯修正,公式如下:
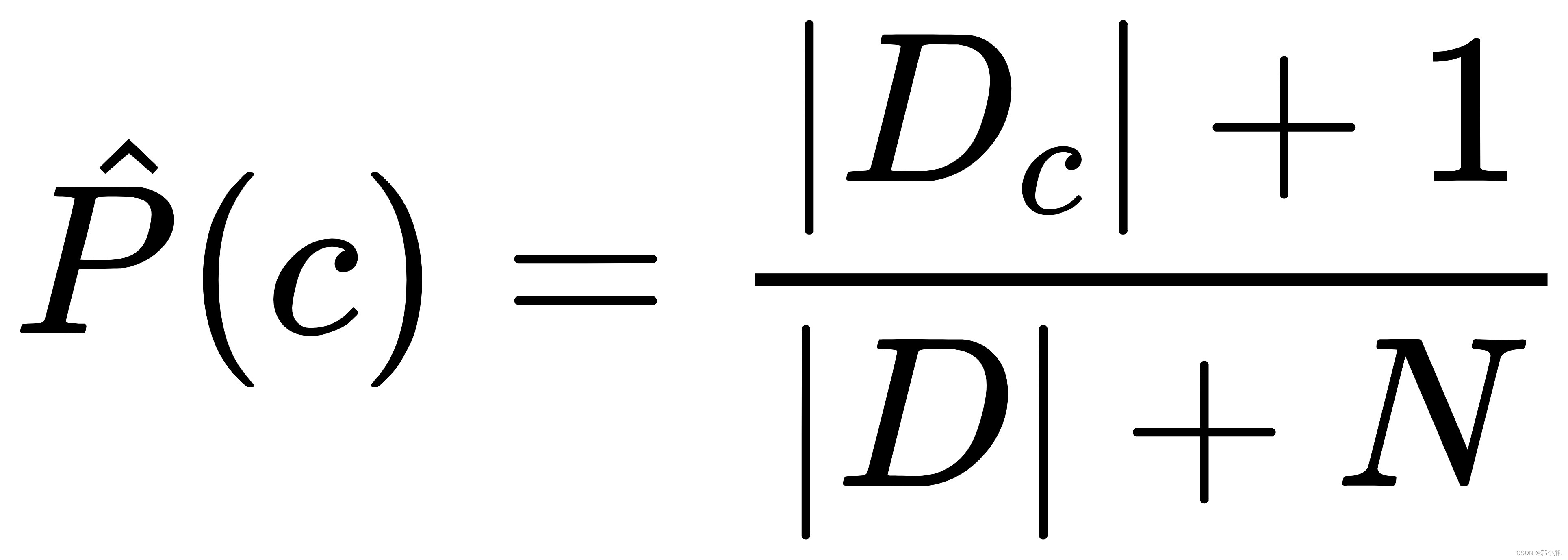
四、实现垃圾邮件过滤
实现垃圾邮件过滤的步骤
收集数据:提供文本文件。
预处理数据:将文本文件解析成词条向量。
分析数据:检查词条确保解析的正确性。
训练:计算不同的独立特征的条件概率。
测试,计算错误率:计算错误率。
邮件数据集
ham_email文件夹下包含二十条正常邮件信息,spam_email文件夹下面包含二十条垃圾文件信息 。
加载数据集
def createVocabList(dataSet):vocabSet = set([]) # set集合元素不重复for document in dataSet:vocabSet = vocabSet | set(document) # 取并集return list(vocabSet)数据预处理
def setOfWords2Vec(vocabList, inputSet):returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量for word in inputSet: if word in vocabList: # 如果词条存在于词汇表中,则置1returnVec[vocabList.index(word)] = 1else:print("the word: %s is not in my Vocabulary!" % word)return returnVec # 返回文档向量
朴素贝叶斯函数训练
def trainNB0(trainMatrix, trainCategory):numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory) / float(numTrainDocs) # 文档属于垃圾邮件类的概率p0Num = np.ones(numWords)p1Num = np.ones(numWords) # 词条出现数初始为1,拉普拉斯平滑p0Denom = 2.0p1Denom = 2.0 # 分母初始为2 ,拉普拉斯平滑for i in range(numTrainDocs):if trainCategory[i] == 1: # 统计属于侮辱类的条件概率所需的数据p1Num += trainMatrix[i]p1Denom += sum(trainMatrix[i])else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···p0Num += trainMatrix[i]p0Denom += sum(trainMatrix[i])p1Vect = np.log(p1Num / p1Denom)p0Vect = np.log(p0Num / p0Denom) return p0Vect, p1Vect, pAbusive # 返回属于正常邮件类的条件概率数组,属于侮辱垃圾邮件类的条件概率数组,文档属于垃圾邮件类的概率
分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)if p1 > p0:return 1else:return 0
测试朴素贝叶斯分类器,交叉验证
def spamTest():docList = []classList = []fullText = []for i in range(1, 21): # 遍历20个txt文件wordList = textParse(open('email/spam_email/%d.txt' % i, 'r').read()) docList.append(wordList)fullText.append(wordList)classList.append(1) # 标记垃圾邮件,1表示垃圾文件wordList = textParse(open('email/ham_email/%d.txt' % i, 'r').read()) docList.append(wordList)fullText.append(wordList)classList.append(0) # 标记正常邮件,0表示正常文件vocabList = createVocabList(docList) trainingSet = list(range(40))testSet = [] for i in range(6): # 从40个邮件中,随机挑选出34个作为训练集,6个做测试集randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del (trainingSet[randIndex]) trainMat = []trainClasses = [] # 创建训练集矩阵和训练集类别标签系向量for docIndex in trainingSet: # 遍历训练集trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) # 训练朴素贝叶斯模型errorCount = 0 # 错误分类计数for docIndex in testSet: # 遍历测试集wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误errorCount += 1 # 错误计数加1print("分类错误的测试集:", docList[docIndex])print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
运行结果

全部代码
# -*- coding: UTF-8 -*-
import numpy as np
import re
import randomdef createVocabList(dataSet):vocabSet = set([]) for document in dataSet:vocabSet = vocabSet | set(document) # 取并集return list(vocabSet)def setOfWords2Vec(vocabList, inputSet):returnVec = [0] * len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1else:print("the word: %s is not in my Vocabulary!" % word)return returnVec # 返回文档向量def bagOfWords2VecMN(vocabList, inputSet):returnVec = [0] * len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] += 1return returnVec # 返回词袋模型def trainNB0(trainMatrix, trainCategory):numTrainDocs = len(trainMatrix) # 计算训练的文档数目numWords = len(trainMatrix[0]) # 计算每篇文档的词条数pAbusive = sum(trainCategory) / float(numTrainDocs) # 文档属于垃圾邮件类的概率p0Num = np.ones(numWords)p1Num = np.ones(numWords) # 创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑p0Denom = 2.0p1Denom = 2.0 # 分母初始化为2 ,拉普拉斯平滑for i in range(numTrainDocs):if trainCategory[i] == 1: p1Num += trainMatrix[i]p1Denom += sum(trainMatrix[i])else: p0Num += trainMatrix[i]p0Denom += sum(trainMatrix[i])p1Vect = np.log(p1Num / p1Denom)p0Vect = np.log(p0Num / p0Denom) return p0Vect, p1Vect, pAbusive def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):p1 = sum(vec2Classify * p1Vec) + np.log(pClass1)p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)if p1 > p0:return 1else:return 0def textParse(bigString): # 将字符串转换为字符列表listOfTokens = re.split(r'\W*', bigString) # 将特殊符号作为切分标志进行字符串切分,即非字母、非数字return [tok.lower() for tok in listOfTokens if len(tok) > 2] # 除了单个字母,例如大写的I,其它单词变成小写def spamTest():docList = []classList = []fullText = []for i in range(1, 21): wordList = textParse(open('email/spam_email/%d.txt' % i, 'r').read()) docList.append(wordList)fullText.append(wordList)classList.append(1) # 标记垃圾邮件,1表示垃圾文件wordList = textParse(open('email/ham_email/%d.txt' % i, 'r').read()) docList.append(wordList)fullText.append(wordList)classList.append(0) # 标记正常邮件,0表示正常文件vocabList = createVocabList(docList) trainingSet = list(range(40))testSet = [] for i in range(6): # 从40个邮件中,随机挑选出34个作为训练集,6个做测试集randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del (trainingSet[randIndex]) trainMat = []trainClasses = [] for docIndex in trainingSet: trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) errorCount = 0 # 错误分类计数for docIndex in testSet: # 遍历测试集wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误errorCount += 1 # 错误计数加1print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))if __name__ == '__main__':spamTest()