利用shell脚本通过crontab进行定时执行,这样实现的话比较简单,但是随着多个job复杂度的提升,无论是协调工作还是任务监控都变得麻烦,我们选择使用oozie来对工作流进行调度监控。
1. Oozie的特点
- Oozie是管理hadoop作业的调度系统
- Oozie的工作流作业是一系列动作的有向无环图(DAG)
- Oozie协调作业是通过时间(频率)和有效数据触发当前的Oozie工作流程
- Oozie支持各种hadoop作业,例如:java map-reduce、Streaming map-reduce、pig、hive、sqoop和distcp等等,也支持系统特定的作业,例如java程序和shell脚本。
- Oozie是一个可伸缩,可靠和可拓展的系统
2. 为什么选择Oozie
在没有工作流调度系统之前,公司里面的任务都是通过 crontab 来定义的,时间长了后会发现很多问题:
1.大量的crontab任务需要管理
2.任务没有按时执行,各种原因失败,需要重试
3.多服务器环境下,crontab分散在很多集群上,光是查看log就很花时间
于是,出现了一些管理crontab任务的调度系统,如 CronHub、CronWeb 等。
而在大数据领域,现在市面上常用的工作流调度工具有Oozie, Azkaban,Cascading,Hamake等,
我们往往把 Oozie和Azkaban来做对比:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
- 工作流定义: Oozie是通过xml定义的而Azkaban为properties来定义。
- 部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
- 任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
- 操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
- 权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
- 运行环境: Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
- 记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
- 出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行
3. Oozie-Azkaban详细对比
对市面上最流行的两种调度器,给出以下详细对比。知名度比较高的应该是Apache Oozie,但是其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
从功能上来对比
两者均可以调度linux命令、mapreduce、spark、pig、java、hive、java程序、脚本工作流任务
两者均可以定时执行工作流任务
从工作流定义上来对比
1、Azkaban使用Properties文件定义工作流
2、Oozie使用XML文件定义工作流
从工作流传参上来对比
1、Azkaban支持直接传参,例如${input}
2、Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
从定时执行上来对比
1、Azkaban的定时执行任务是基于时间的
2、Oozie的定时执行任务基于时间和输入数据
从资源管理上来对比
1、Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
2、Oozie暂无严格的权限控制
从工作流执行上来对比
1、Azkaban有三种运行模式:
1.1、solo server mode:最简单的模式,数据库内置的H2数据库,管理服务器和执行服务器都在一个进程中运行,任务量不大项目可以采用此模式。
1.2、 two server mode:数据库为mysql,管理服务器和执行服务器在不同进程,这种模式下,管理服务器和执行服务器互不影响
1.3 、multiple executor mode:该模式下,执行服务器和管理服务器在不同主机上,且执行服务器可以有多个
我这次采用第二种模式,管理服务器、执行服务器分进程,但在同一台主机上。
2、Oozie作为工作流服务器运行,支持多用户和多工作流
从工作流管理上来对比
1、Azkaban支持浏览器以及ajax方式操作工作流
2、Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
另一版本区别:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
工作流定义:Oozie是通过xml定义的而Azkaban为properties来定义。
部署过程: Oozie的部署太虐心了。有点难。同时它是从Yarn上拉任务日志。
Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
操作工作流:Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,入用户对工作流读写执行操作。
Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
记录workflow的状态:Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
出现失败的情况:Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行。
4. 主要概念
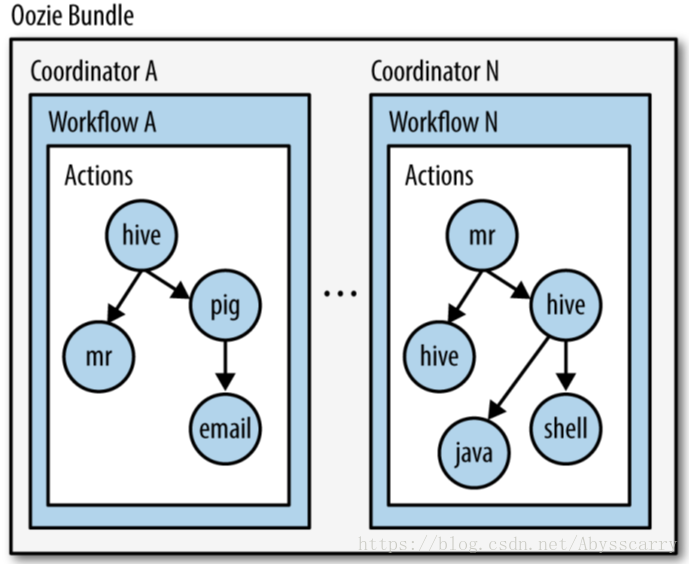
我们在官网介绍中就注意到了,Oozie主要有三个主要概念,分别是 workflow,coordinator,bundle。

其中:
Workflow:工作流,由我们需要处理的每个工作组成,进行需求的流式处理。
Coordinator:协调器,可以理解为工作流的协调器,可以将多个工作流协调成一个工作流来进行处理。
Bundle:捆,束。将一堆的coordinator进行汇总处理。
简单来说,workflow是对要进行的顺序化工作的抽象,coordinator是对要进行的顺序化的workflow的抽象,bundle是对一堆coordiantor的抽象。层级关系层层包裹。
Oozie本质是通过 launcher job 运行某个具体的Action。launcher job是一个MR作业,而且并不知道它将在集群的哪台机器上执行这个MR作业。
5. Job组成
一个oozie 的 job 一般由以下文件组成:
job.properties :记录了job的属性
workflow.xml :使用hPDL 定义任务的流程和分支
lib目录:用来执行具体的任务
5.1 Job.properties
| KEY | 含义 |
|---|---|
| nameNode | HDFS地址 |
| jobTracker | jobTracker(ResourceManager)地址 |
| queueName | Oozie队列(默认填写default) |
| examplesRoot | 全局目录(默认填写examples) |
| oozie.usr.system.libpath | 是否加载用户lib目录(true/false) |
| oozie.libpath | 用户lib库所在的位置 |
| oozie.wf.application.path | Oozie流程所在hdfs地址(workflow.xml所在的地址) |
| user.name | 当前用户 |
| oozie.coord.application.path | Coordinator.xml地址(没有可以不写) |
| oozie.bundle.application.path | Bundle.xml地址(没有可以不写) |
5.2 workflow.xml
这个文件是定义任务的整体流程的文件,官网wordcount例子如下:

<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1"><start to='wordcount'/><action name='wordcount'><map-reduce><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.mapper.class</name><value>org.myorg.WordCount.Map</value></property><property><name>mapred.reducer.class</name><value>org.myorg.WordCount.Reduce</value></property><property><name>mapred.input.dir</name><value>${inputDir}</value></property><property><name>mapred.output.dir</name><value>${outputDir}</value></property></configuration></map-reduce><ok to='end'/><error to='kill'/></action><kill name='kill'><message>Something went wrong: ${wf:errorCode('wordcount')}</message></kill/><end name='end'/>
</workflow-app>
**[控制流节点]:主要包括start、end、fork、join等,其中fork、join成对出现,在fork展开。分支,最后在join结点汇聚
** start
** kill
** end
**[动作节点]:包括Hadoop任务、SSH、HTTP、EMAIL、OOZIE子任务
** ok --> end
** error --> kill
** 定义具体需要执行的job任务
** MapReduce、shell、hive
注意:
文件需要被放在HDFS上才能被oozie调度,如果在启动需要调动MR任务,jar包同样需要在hdfs上
Lib目录:
在workflow工作流定义的同级目录下,需要有一个lib目录,在lib目录中存在java节点MapReduce使用的jar包。
需要注意的是,oozie并不是使用指定jar包的名称来启动任务的,而是通过制定主类来启动任务的。在lib包中绝对不能存在某个jar包的不同版本,不能够出现多个相同主类。
6. Workflow介绍

workflow 是一组 actions 集合(例如Hadoop map/reduce作业,pig作业),它被安排在一个控制依赖项DAG(Direct Acyclic Graph)中。“控制依赖”从一个action到另一个action意味着第二个action不能运行,直到第一个action完成。
Oozie Workflow 定义是用 hPDL 编写的(类似于JBOSS JBPM jPDL的XML过程定义语言)。
Oozie Workflow actions在远程系统(如Hadoop、Pig)中启动工作。在action完成时,远程系统回调 Oozie通知action完成,此时Oozie将继续在workflow中进行下一步操作。
Oozie Workflow 包含控制流节点(control flow nodes)和动作节点(action nodes).
控制流节点定义workflow的开始和结束(start、end 和 fail 节点),并提供一种机制来控制workflow执行路径(decision、fork和join节点)。
action 节点是workflow触发计算/处理任务执行的机制。Oozie为不同类型的操作提供了支持:Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、电子邮件和Oozie子工作流。Oozie可以扩展来支持其他类型的操作。
Oozie Workflow 可以被参数化(在工作流定义中使用诸如$inputDir之类的变量)。在提交workflow作业值时,必须提供参数。如果适当地参数化(即使用不同的输出目录),几个相同的workflow作业可以并发。
7. Coordinator介绍

用户通常在grid上运行map-reduce、hadoop流、hdfs或pig作业。这些作业中的多个可以组合起来形成一个workflow 作业。Hadoop workflow 系统定义了一个workflow 系统来运行这样的工作。
通常,workflow 作业是基于常规的时间间隔(time intervals)和数据可用性(data availability)运行的。在某些情况下,它们可以由外部事件触发。
表示触发workflow 作业的条件可以被建模为必须满足的谓词(predicate )。workflow 作业是在谓词满足之后开始的。谓词可以引用数据、时间和/或外部事件。在将来,可以扩展模型来支持额外的事件类型。
还需要连接定期运行的workflow 作业,但在不同的时间间隔内。多个后续运行的workflow 的输出成为下一个workflow 的输入。例如,每15分钟运行一次的workflow 的4次运行的输出,就变成了每隔60分钟运行一次的workflow 的输入。将这些workflow 链接在一起会导致它被称为数据应用程序管道。
Oozie Coordinator 系统允许用户定义和执行周期性和相互依赖的workflow 作业(数据应用程序管道)。
8. Bundle介绍

Bundle 是一个更高级的oozie抽象,它将批处理一组Coordinator应用程序。
用户将能够在bundle级别启动/停止/暂停/恢复/重新运行,从而获得更好、更容易的操作控制。
更具体地说,oozie Bundle系统允许用户定义和执行一堆通常称为数据管道的Coordinator应用程序。在Bundle中,Coordinator应用程序之间没有显式的依赖关系。然而,用户可以使用Coordinator应用程序的数据依赖来创建隐式数据应用程序管道。
9. 案例演示
配置文件1:coordinator.xml

配置文件2:workflow.xml

配置文件3:job.properties

[补充]crontab执行时间计算:
各个字符代表的含义。0代表从0分开始,*代表任意字符,/代表递增。
crontab执行时间计算
Cron表达式生成器

将配置文件和jar包按照配置文件中配置的路径上传到HDFS的对应目录
注:严格注意目录位置

9.1 测试-步骤:
#在HDFS上建立如下文件夹
hdfs dfs -mkdir -p /apps/tags/models/Tag_001/lib
#将文件上传到HDFS
hdfs dfs -put job.properties /apps/tags/models/Tag_001/
hdfs dfs -put coordinator.xml /apps/tags/models/Tag_001/
hdfs dfs -put workflow.xml /apps/tags/models/Tag_001/
hdfs dfs -put model29.jar /apps/tags/models/Tag_001/lib
9.2 Oozie命令
在服务器中cd oozie_test/查看
coordinator.xml\job.properties\model29.jar\workflow.xml
#运行oozie coordinator.xml
#校验配置文件
oozie validate -oozie http://bd001:11000/oozie /root/oozie_test/coordinator.xml
#运行job(配置文件在/root/oozie_test/job.properties,需要查看服务器是否有改文件)
oozie job -oozie http://bd001:11000/oozie -config /root/oozie_test/job.properties -run
#查看信息
oozie job -oozie http://bd001:11000/oozie -info 0000029-191027171933033-oozie-root-C
#查看日志
oozie job -oozie http://bd001:11000/oozie -log 0000064-190923225831711-oozie-root-C
#Kill任务
oozie job -oozie http://bd001:11000/oozie -kill 0000064-190923225831711-oozie-root-C
#查看所有普通任务
oozie jobs -oozie http://bd001:11000/oozie
#查看定时任务
oozie jobs -jobtype coordinator -oozie http://bd001:11000/oozie
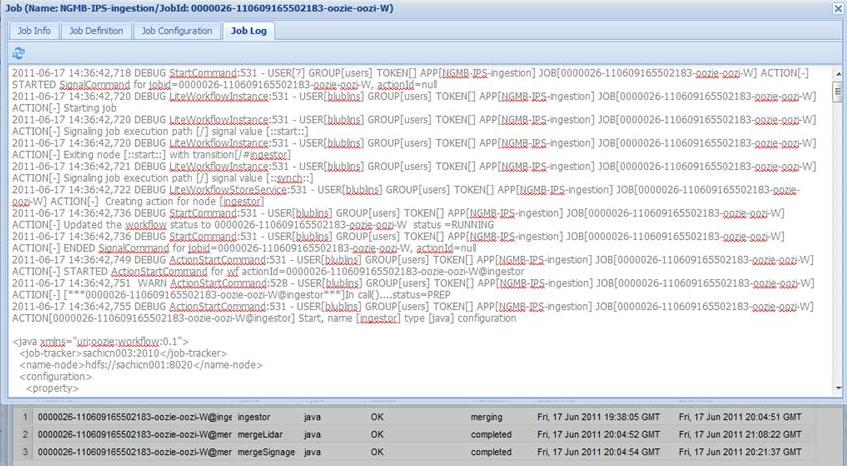
结果截图:

Web:http://bd001:11000/oozie/部分查看
思考:上述通过命令调度,在项目中整合oozieAPI整合SpringBoot完成调度
10. Oozie工具类代码开发
导入Oozie相关配置文件,放入resources文件夹
以下文件是up.conf
model: {user: "root"app: "tags"path: {jars: "/temp/jars"model-base: "/apps/tags_new/models"}
}
hadoop: {name-node: "hdfs://bd001:8020"resource-manager: "bd001:8032"
}
mysql: {url: "jdbc:mysql://bd001:3306/tags_new?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"driver: "com.mysql.jdbc.Driver"tag-table: "tbl_basic_tag"model-table: "tbl_model"
}
oozie: {url: "http://bd001:11000/oozie"params: {"user.name": ${model.user}"nameNode": ${hadoop.name-node}"jobTracker": ${hadoop.resource-manager}"appName": ${model.app}"master": "yarn""mode": "cluster""queueName": "default""oozie.use.system.libpath": "true""oozie.libpath": "${nameNode}/user/root/share/lib/lib_20190802113508/spark2""sparkOptions": " --driver-memory 512m --executor-memory 512m --num-executors 1 --executor-cores 1 --conf spark.yarn.historyServer.address=http://bd001:18081 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://bd001:8020/apps/spark2/spark2-history/ --conf spark.yarn.jars=hdfs://bd001:8020/apps/archive/sparklib/spark-libs.jar""freq": "0/10 * * * *"}
}
10.1 编写Oozie配置类
ConfigHolder.scala
package com.erainm.up.commonimport com.typesafe.config.ConfigFactory
import pureconfig.ConfigSource
case class Config
(model: Model,hadoop: Hadoop,mysql: MySQL,oozie: Oozie
)case class Model
(user: String,app: String,path: Path
)case class Path
(jars: String,modelBase: String
)case class Hadoop
(nameNode: String,resourceManager: String
)case class MySQL
(url: String,driver: String,tagTable: String,modelTable: String
)case class Oozie
(url: String,params: Map[String, String]
)object ConfigHolder {import pureconfig._import pureconfig.generic.auto._private val configTool = ConfigFactory.load("up")val config: Config = ConfigSource.fromConfig(configTool).load[Config].right.getval model: Model = config.modelval hadoop: Hadoop = config.hadoopval oozie: Oozie = config.oozieval mysql: MySQL = config.mysql
}
10.2 编写Oozie工具类
OozieUtils.scala 编写
package com.erainm.up.commonimport java.util.Properties
import org.apache.commons.lang3.StringUtils
import org.apache.oozie.client.OozieClientobject OozieUtils {val classLoader: ClassLoader = getClass.getClassLoader/*** Properties 包含各种配置* OozieParam 外部传进来的参数* 作用: 生成配置, 有些配置无法写死, 所以外部传入*/def genProperties(param: OozieParam): Properties = {val properties = new Properties()val params: Map[String, String] = ConfigHolder.oozie.paramsfor (entry <- params) {properties.setProperty(entry._1, entry._2)}val appPath = ConfigHolder.hadoop.nameNode + genAppPath(param.modelId)properties.setProperty("appPath", appPath)properties.setProperty("mainClass", param.mainClass)properties.setProperty("jarPath", param.jarPath) // 要处理if (StringUtils.isNotBlank(param.sparkOptions)) properties.setProperty("sparkOptions", param.sparkOptions)properties.setProperty("start", param.start)properties.setProperty("end", param.end)properties.setProperty(OozieClient.COORDINATOR_APP_PATH, appPath)properties}/*** 上传配置* @param modelId 因为要上传到 家目录, 所以要传入 id 生成家目录*/def uploadConfig(modelId: Long): Unit = {val workflowFile = classLoader.getResource("oozie/workflow.xml").getPathval coordinatorFile = classLoader.getResource("oozie/coordinator.xml").getPathval path = genAppPath(modelId)HDFSUtils.getInstance().mkdir(path)HDFSUtils.getInstance().copyFromFile(workflowFile, path + "/workflow.xml")HDFSUtils.getInstance().copyFromFile(coordinatorFile, path + "/coordinator.xml")}def genAppPath(modelId: Long): String = {ConfigHolder.model.path.modelBase + "/tags_" + modelId}def store(modelId: Long, prop: Properties): Unit = {val appPath = genAppPath(modelId)prop.store(HDFSUtils.getInstance().createFile(appPath + "/job.properties"), "")}def start(prop: Properties): Unit = {val oozie = new OozieClient(ConfigHolder.oozie.url)println(prop)val jobId = oozie.run(prop)println(jobId)}/*** 调用方式展示*/def main(args: Array[String]): Unit = {val param = OozieParam(19,"com.erainm.up29.TestTag","hdfs://bd001:8020/apps/tags/models/Tag_001/lib/model29.jar","","2019-09-24T06:15+0800","2030-09-30T06:15+0800")val prop = genProperties(param)println(prop)uploadConfig(param.modelId)store(param.modelId, prop)start(prop)}
}case class OozieParam
(modelId: Long,mainClass: String,jarPath: String,sparkOptions: String,start: String,end: String
)
10.3 编写Oozie测试类
package com.erainm.up.commonimport java.util.Properties
import org.apache.oozie.client.OozieClient
object OozieTest {def upload (): Unit = {}def genProperties(): Unit = {}def main(args: Array[String]): Unit = {// 1. 上传文件到 HDFS 中, workflow.xml, coordinator.xml, jarval path = getClass.getResource("oozie/workflow.xml").getPathHDFSUtils.getInstance().copyFromFile(path, "/apps/tags_new/models/tags_modelid")// 2. 创建配置// 2.1. 读取配置, 这些配置可能不变, 写死的val prop = new Properties()prop.load(getClass.getResource("oozie/job.properties").openStream())// 2.2. 有一些参数, 必须要不同的模型计算, 有不同的值// prop.setProperty(...)// 3. 运行 Oozie 任务, oozie -oozie ... -config job.properties -runval client = new OozieClient("http://bd001:11000/oozie")// run -> submit + startclient.run(prop)}
}
注意:有时候oozie调度会因为windows和服务器时间不一致,使用 date -s "2020-09-08 11:07:00"修改
11. Oozie整合SpringBoot编写任务调度【测试】
首先观察如下界面

浏览器查看返回的state信息
http://localhost:8081/tags/71/model
查看tbl_basic_tag完成对应71为id对应的name

注意:
Modelpo是用来操作数据库的
Modeldto是用来和前段交互的
这样区分是用来隐藏数据库表结构
防止黑客进行数据库攻击
而ModelRepo是dao用来把po保存到数据库的
11.1 编写Controller控制层代码
//http://localhost:8081/tags/71/model
//1-使用tagService更新状态
//2-返回HttpResult
@PostMapping("tags/{id}/model")public HttpResult changeModelState(@PathVariable Long id, @RequestBody ModelDto modelDto){service.updateModelState(id, modelDto.getState());return new HttpResult(Codes.SUCCESS, "执行成功", null);}
11.2 编写Service服务层代码
//首先根据modelRepo使用id查找对应的信息
//启动任务
//调用engine类中的封装好的方法启动任务
//modelPo调用setName
//停止任务
//调用engine类中的封装好的方法停止任务
//modelPo更新状态,传过来是几修改为几,modelRepo保存oozie的在有关四级标签配置modelPo状态
@Overridepublic void updateModelState(Long id, Integer state) {ModelPo modelPo = modelRepo.findByTagId(id);if (state == ModelPo.STATE_ENABLE) {//启动流程engine.startModel(convert(modelPo));
//modelPo调用setNamemodelPo.setName(jobid);}if (state == ModelPo.STATE_DISABLE) {//关闭流程engine.stopModel(convert(modelPo));}//更新状态信息modelPo.setState(state);modelRepo.save(modelPo);}
11.3 编写引擎Service层代码
//1-new OozieParam的基本配置
//2-使用OozieUtils根据参数生成配置文件Properties对象
//3-通过标签Id(model)上传配置到HDFS(如coordinator.xml/workflow.xml)
//4-保留一份Properties方便后续如果出错可以查看
//5-运行任务
//6-返回JobId
@Overridepublic void startModel(ModelDto model) {// 设置动态的参数, 例如如何调度, 主类名, jar 的位置OozieParam param = new OozieParam(model.getId(),model.getMainClass(),model.getPath(),model.getArgs(),ModelDto.Schedule.formatTime(model.getSchedule().getStartTime()),ModelDto.Schedule.formatTime(model.getSchedule().getEndTime()));// 生成配置Properties properties = OozieUtils.genProperties(param);// 上传各种配置, workflow.xml, coordinator.xmlOozieUtils.uploadConfig(model.getId());// 因为如果不保留一份 job.properties 的文件, 无法调试错误OozieUtils.store(model.getId(), properties);// 运行 Oozie 任务OozieUtils.start(properties);}@Overridepublic void stopModel(ModelDto model) {}
11.4 测试
根据数据库查看状态信息:
model_main应该从oozie的properties配置中获取
注意:这里根据自己服务器标签可以自主选择,这里选择#蘑菇街女装#消费偏好,对应的tbl_model的tag_id=95

查看任务状态
oozie job -oozie http://bd001:11000/oozie -info 0000007-191209104842815-oozie-root-C
注意:任务id从控制台或者数据库查看


停止后可以在重启,观察数据库表变化


从而完成Oozie和SpringBoot整合。
总结:
- Oozie支持基于Hadoop的任务调度,稳定成熟,无缝集成Hadoop
- Oozie支持任务状态的监控和持久化保存,支持失败流程控制
- Oozie支持命令行调度,还支持Rest-API调用
当然Oozie也有一些缺点:界面丑陋,xml文件编写复杂,功能太多,有的用不上较冗余,
注意:Oozie整合Spark的jar有的需要重新编译