在Hadoop中执行的任务有时候需要把多个Map/Reduce作业连接到一起,这样才能够达到目的。[1]在Hadoop生态圈中,有一种相对比较新的组件叫做Oozie[2],它让我们可以把多个Map/Reduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。本文中,我们会向你介绍Oozie以及使用它的一些方式。
什么是Oozie?
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
- 工作流定义
- 当前运行的工作流实例,包括实例的状态和变量
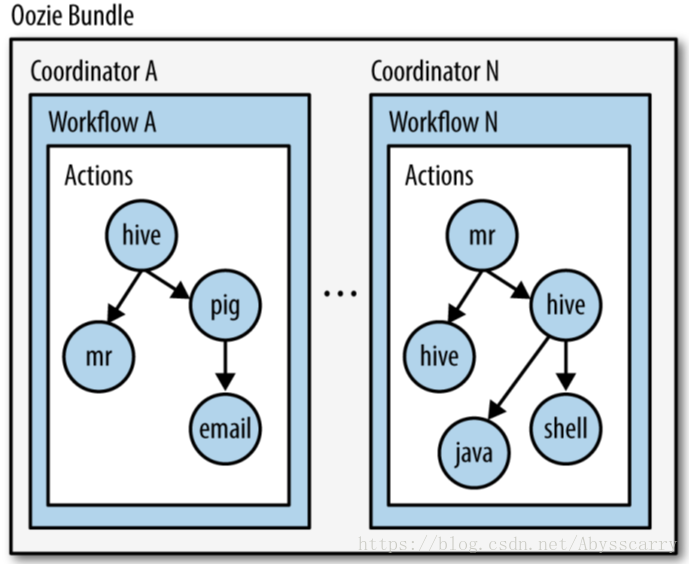
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
安装Oozie
我们可以把Oozie安装在现存的Hadoop系统中,安装方式包括tarball、RPM和Debian包等。我们的Hadoop部署是Cloudera的CDH3,其中已经包含了Oozie。因此,我们只是使用yum把它拉下来,然后在edge节点[1]上执行安装操作。在Oozie的发布包中有两个组件——Oozie-client和Oozie-server。根据簇集的规模,你可以让这两个组件安装在同一台edge服务器上,也可能安装在不同的计算机上。Oozie服务器中包含了用于触发和控制作业的组件,而客户端中包含了让用户可以触发Oozie操作并与Oozie服务器通信的组件。
想要了解更多关于安装过程的信息,请使用Cloudera发布包,并访问Cloudera站点[2]。
注: 除了包括安装过程的内容之外,它还建议把下面的shell变量OOZIE_URL根据需要添加到.login、.kshrc或者shell的启动文件中:
export OOZIE_URL=http://localhost:11000/oozie简单示例
为了向你展示Oozie的使用方法,让我们创建一个简单的示例。我们拥有两个Map/Reduce作业[3]——一个会获取最初的数据,另一个会合并指定类型的数据。实际的获取操作需要执行最初的获取操作,然后把两种类型的数据——Lidar和Multicam——合并。为了让这个过程自动化,我们需要创建一个简单的Oozie工作流(代码1)。
<!--
Copyright (c) 2011 NAVTEQ! Inc. All rights reserved.
NGMB IPS ingestor Oozie Script
-->
<workflow-app xmlns='uri:oozie:workflow:0.1' name='NGMB-IPS-ingestion'><start to='ingestor'/><action name='ingestor'><java><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.job.queue.name</name><value>default</value></property></configuration><main-class>com.navteq.assetmgmt.MapReduce.ips.IPSLoader</main-class><java-opts>-Xmx2048m</java-opts><arg>${driveID}</arg></java><ok to="merging"/><error to="fail"/></action><fork name="merging"><path start="mergeLidar"/><path start="mergeSignage"/></fork><action name='mergeLidar'><java><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.job.queue.name</name><value>default</value></property></configuration><main-class>com.navteq.assetmgmt.hdfs.merge.MergerLoader</main-class><java-opts>-Xmx2048m</java-opts><arg>-drive</arg><arg>${driveID}</arg><arg>-type</arg><arg>Lidar</arg><arg>-chunk</arg><arg>${lidarChunk}</arg></java><ok to="completed"/><error to="fail"/></action><action name='mergeSignage'><java><job-tracker>${jobTracker}</job-tracker><name-node>${nameNode}</name-node><configuration><property><name>mapred.job.queue.name</name><value>default</value></property></configuration><main-class>com.navteq.assetmgmt.hdfs.merge.MergerLoader</main-class><java-opts>-Xmx2048m</java-opts><arg>-drive</arg><arg>${driveID}</arg><arg>-type</arg><arg>MultiCam</arg><arg>-chunk</arg><arg>${signageChunk}</arg></java><ok to="completed"/><error to="fail"/></action><join name="completed" to="end"/><kill name="fail"><message>Java failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message></kill><end name='end'/>
</workflow-app> 代码1: 简单的Oozie工作流
这个工作流定义了三个动作:ingestor、mergeLidar和mergeSignage。并把每个动作都实现为Map/Reduce[4]作业。这个工作流从start节点开始,然后把控制权交给Ingestor动作。一旦ingestor步骤完成,就会触发fork控制节点 [4],它会并行地开始执行mergeLidar和mergeSignage[5]。这两个动作完成之后,就会触发join控制节点[6]。join节点成功完成之后,控制权就会传递给end节点,它会结束这个过程。
创建工作流之后,我们需要正确地对其进行部署。典型的Oozie部署是一个HDFS目录,其中包含workflow.xml(代码1)、config-default.xml和lib子目录,其中包含有工作流操作所要使用的类的jar文件。
| Name | Type | Size | Replication | Block Size | Modification Time | Permission | Owner | Group |
|---|---|---|---|---|---|---|---|---|
| config-default.xml | file | 0.95 KB | 3 | 64 MB | 2011-06-06 10:38 | rw-r--r-- | blubline | supergroup |
| lib | dir | 2011-06-17 13:37 | rwxr-xr-x | blubline | supergroup | |||
| workflow.xml | file | 2.55 KB | 3 | 64 MB | 2011-06-08 11:33 | rw-r--r-- | blubline | supergroup |
| job.properties | file | 0.35 KB | 3 | 64 MB | 2011-06-08 11:33 | rw-r--r-- | blubline | supergroup |
表1: Oozie部署 注:(Hadoop 2.0 后Block Size是128 MB)
config-default.xml文件是可选的,通常其中会包含对于所有工作流实例通用的工作流参数。代码2中显示的是config-default.xml的简单示例。
<configuration><property><name>jobTracker</name><value>sachicn003:2010</value></property><property><name>nameNode</name><value>hdfs://sachicn001:8020</value></property><property><name>queueName</name><value>default</value></property>
</configuration>代码2: Config-default.xml
完成了工作流的部署之后,我们可以使用Oozie提供的命令行工具[5],它可以用于提交、启动和操作工作流。这个工具一般会运行在Hadoop簇集[7]的edge节点上,并需要一个作业属性文件job.properties(参见配置工作流属性),见代码3。
oozie.wf.application.path=hdfs://sachicn001:8020/user/blublins/workflows/IPSIngestion
jobTracker=sachicn003:2010
nameNode=hdfs://sachicn001:8020代码3: 作业属性文件(job.properties)
有了作业属性,我们就可以使用代码4中的命令来运行Oozie工作流。
oozie job –oozie http://sachidn002.hq.navteq.com:11000/oozie/ -D driveID=729-pp00002-2011-02-08-09-59-34 -D lidarChunk=4 -D signageChunk=20 -config job.properties –run
列表4: 运行工作流命令
配置工作流属性
在config-default.xml、作业属性文件和作业参数中有一些重叠,它们可以作为命令行调用的一部分传递给Oozie。尽管文档中没有清晰地指出何时使用哪个,但总体上的建议如下:
- 使用config-default.xml定义对于指定工作流从未改变过的参数。
- 对于给定的工作流部署通用的参数,建议使用作业属性。
- 对于指定的工作流调用特定的参数使用命令行参数。
Oozie处理这三种参数的方式如下:
- 使用所有命令行调用的参数
- 如果那里有任何无法解析的参数,那么就是用作业配置来解析
- 一旦所有其它方式都无法处理,那么就试着使用config-default.xm。
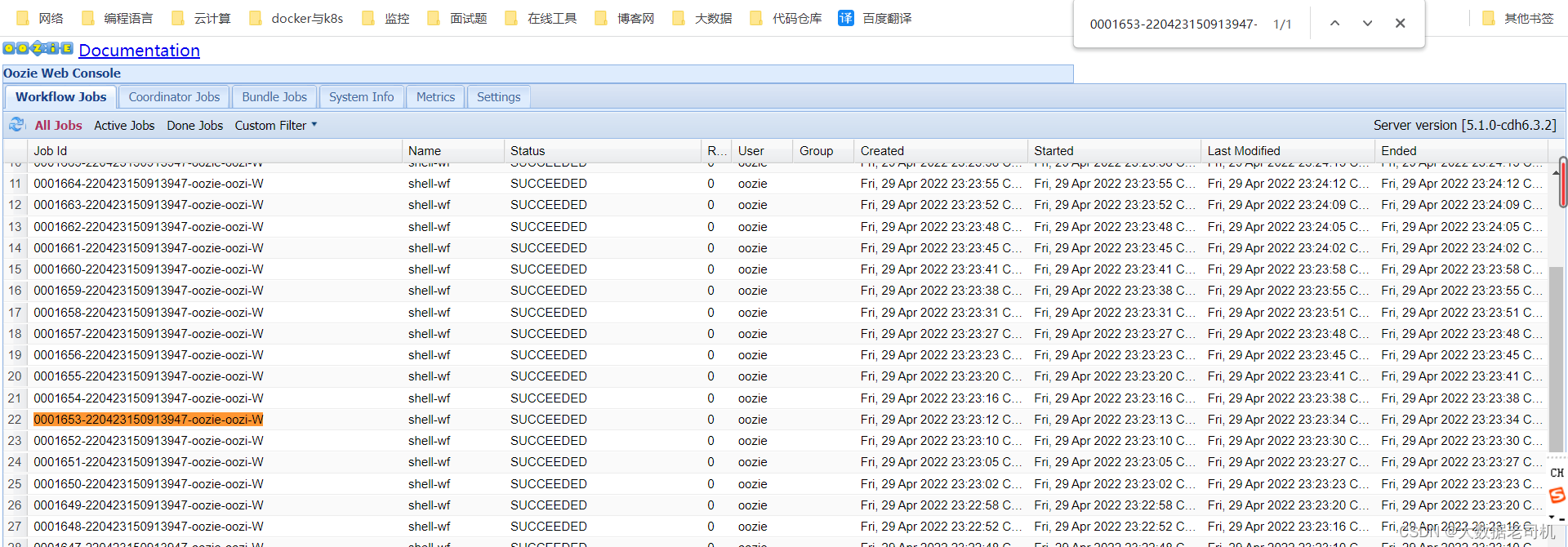
我们可以使用Oozie控制台(图2)来观察工作流执行的进程和结果。
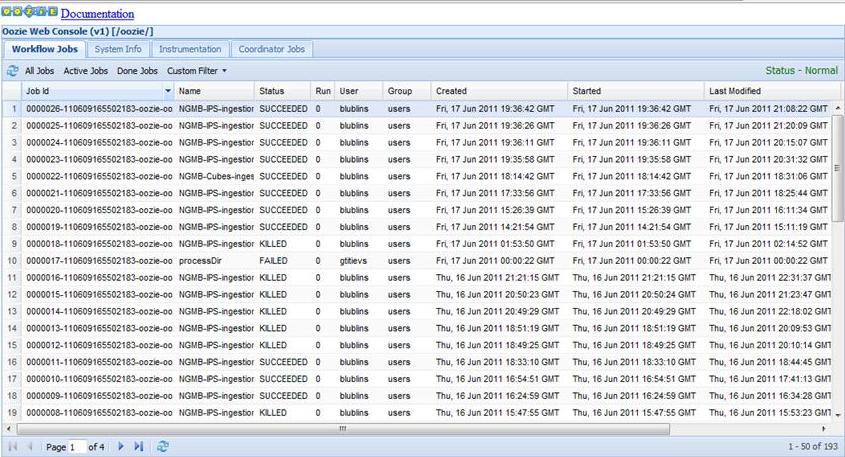
图2: Oozie控制台
我们还可以使用Oozie控制台来获得操作执行的细节,比方说作业的日志[8](图3)。
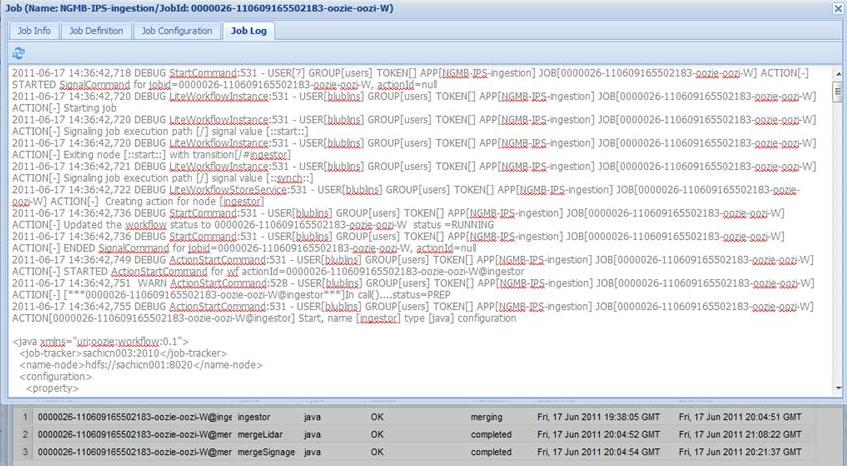
图3: Oozie控制台——作业日志
编程方式的工作流调用
尽管上面所述的命令行界面能够很好地用于手动调用Oozie,但有时使用编程的方式调用Oozie更具有优势。当Oozie工作流是特定的应用程序或者大型企业过程的一部分,这就会很有用。我们可以使用Oozie Web Services APIs [6]或者Oozie Java client APIs [7]来实现这种编程方式的调用。代码5中展现的就是很简单的Oozie Java客户端的例子,它会触发上面描述的过程。
package com.navteq.assetmgmt.oozie;import java.util.LinkedList;
import java.util.List;
import java.util.Properties;import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.OozieClientException;
import org.apache.oozie.client.WorkflowJob;
import org.apache.oozie.client.WorkflowJob.Status;public class WorkflowClient {private static String OOZIE_URL = "http://sachidn002.hq.navteq.com:11000/oozie/";private static String JOB_PATH = "hdfs://sachicn001:8020/user/blublins/workflows/IPSIngestion";private static String JOB_Tracker = "sachicn003:2010";private static String NAMENode = "hdfs://sachicn001:8020";OozieClient wc = null;public WorkflowClient(String url){wc = new OozieClient(url);}public String startJob(String wfDefinition, List<WorkflowParameter> wfParameters)throws OozieClientException{// create a workflow job configuration and set the workflow application pathProperties conf = wc.createConfiguration();conf.setProperty(OozieClient.APP_PATH, wfDefinition);// setting workflow parametersconf.setProperty("jobTracker", JOB_Tracker);conf.setProperty("nameNode", NAMENode);if((wfParameters != null) && (wfParameters.size() > 0)){for(WorkflowParameter parameter : wfParameters) {conf.setProperty(parameter.getName(), parameter.getValue());}}// submit and start the workflow jobreturn wc.run(conf);}public Status getJobStatus(String jobID) throws OozieClientException{WorkflowJob job = wc.getJobInfo(jobID);return job.getStatus();}public static void main(String[] args) throws OozieClientException, InterruptedException{// Create clientWorkflowClient client = new WorkflowClient(OOZIE_URL);// Create parametersList<WorkflowParameter> wfParameters = new LinkedList<WorkflowParameter>();WorkflowParameter drive = new WorkflowParameter("driveID","729-pp00004-2010-09-01-09-46");WorkflowParameter lidar = new WorkflowParameter("lidarChunk","4");WorkflowParameter signage = new WorkflowParameter("signageChunk","4");wfParameters.add(drive);wfParameters.add(lidar);wfParameters.add(signage);// Start OozingString jobId = client.startJob(JOB_PATH, wfParameters);Status status = client.getJobStatus(jobId);if(status == Status.RUNNING) {System.out.println("Workflow job running");}else {System.out.println("Problem starting Workflow job");}}
}代码5: 简单的Oozie Java客户端
在此,我们首先使用Oozie服务器URL对工作流客户端进行初始化。初始化过程完成之后,我们就可以使用客户端提交并启动作业(startJob方法),获得正在运行的作业的状态(getStatus方法),以及进行其他操作。
构建java动作,向工作流传递参数
在之前的示例中,我们已经展示了如何使用标签向Java节点传递参数。由于Java节点是向Oozie引入自定义计算的主要方法,因此能够从Java节点向Oozie传递数据也同样重要。
根据Java节点的文档[3],我们可以使用“capture-output””元素把Java节点生成的值传递回给Oozie上下文。然后,工作流的其它步骤可以通过EL-functions访问这些值。返回值需要以Java属性格式文件写出来。我们可以通过“JavaMainMapper.OOZIE_JAVA_MAIN_CAPTURE_OUTPUT_FILE”常量从System属性中获得这些属性文件的名称。代码6是一个简单示例,演示了如何完成这项操作。
package com.navteq.oozie;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.Calendar;
import java.util.GregorianCalendar;
import java.util.Properties;public class GenerateLookupDirs {/*** @param args*/public static final long dayMillis = 1000 * 60 * 60 * 24;private static final String OOZIE_ACTION_OUTPUT_PROPERTIES = "oozie.action.output.properties";public static void main(String[] args) throws Exception {Calendar curDate = new GregorianCalendar();int year, month, date;String propKey, propVal;String oozieProp = System.getProperty(OOZIE_ACTION_OUTPUT_PROPERTIES);if (oozieProp != null) {File propFile = new File(oozieProp);Properties props = new Properties();for (int i = 0; I < 8; ++i) {year = curDate.get(Calendar.YEAR);month = curDate.get(Calendar.MONTH) + 1;date = curDate.get(Calendar.DATE);propKey = "dir"+i;propVal = year + "-" +(month < 10 ? "0" + month : month) + "-" +(date < 10 ? "0" + date : date);props.setProperty(propKey, propVal);curDate.setTimeInMillis(curDate.getTimeInMillis() - dayMillis);}OutputStream os = new FileOutputStream(propFile);props.store(os, "");os.close();} else {throw new RuntimeException(OOZIE_ACTION_OUTPUT_PROPERTIES + " System property not defined");}}
}代码6: 向Oozie传递参数
在这个示例中,我们假设在HDFS中有针对每个日期的目录。这样,这个类首先会获得当前日期,然后再获得离现在最近的7个日期(包括今天),然后把目录名称传递回给Oozie。具体的示例请看下一篇《跟着示例学Oozie》。
结论
在本文我们介绍了Oozie,它是针对Hadoop的工作流引擎,并且提供了使用它的简单示例。在下一篇文章中,我们会看到更复杂的例子,让我们可以更进一步讨论Oozie的特性。
致谢
非常感谢我们在Navteq的同事Gregory Titievsky,他为我们提供了一些例子。
关于作者
Boris Lublinsky是NAVTEQ公司的首席架构师,在这家公司中他的工作是为大型数据管理和处理、SOA以及实现各种NAVTEQ的项目定义架构的愿景。 他还是InfoQ的SOA编辑,以及OASIS的SOA RA工作组的参与者。Boris是一位作者,还经常发表演讲,他最新的一本书是《Applied SOA》。
Michael Segel在过去二十多年间一直与客户写作,识别并解决他们的业务问题。 Michael已经作为多种角色、在多个行业中工作过。他是一位独立顾问,总是期望能够解决所有有挑战的问题。Michael拥有俄亥俄州立大学的软件工程学位。
参考信息
[1]edge节点是安装有Hadoop库的计算机,但不是真正簇集中的一部分。它是为能够连接到簇集中的应用程序所用的,并且会部署辅助服务以及能够直接访问簇集的最终用户应用程序。
[2]请参看Oozie安装的链接。注:CDH3的安装连接已找不到,这里的是CDH5的链接
[3]这些作业的细节和本文无关,所以在其中没有描述。
[4]Map/Reduce作业能够以两种不同的方式在Oozie中实现——第一种是作为真正的Map/Reduce动作[2],其中你会指定Mapper和Reducer类以及它们的配置信息;第二种是作为Java动作[3],其中你会使用Hadoop API来指定启动Map/Reduce作业的类。因为我们所有的Java主函数都是使用Hadoop API,并且还实现了一些额外的功能,所以我们选择了第二种方法。
[5] Oozie确保两个动作会并行地提交给作业跟踪程序。在执行过程中实际的并行机制并不在Oozie的控制之内,并且依赖于作业的需求、簇集的能力以及Map/Reduce部署所使用的调度程序。
[6]join动作的功能是要同步fork动作启动的多个并行执行的线程。如果fork启动的所有执行的线程都能够成功完成,那么join动作就会等待它们全部完成。如果有至少一个线程执行失败,kill节点会“杀掉”剩余运行的线程。
[7] 这个节点不需要是安装了Oozie的计算机。
[8] Oozie的作业日志会包含工作流执行的细节,想要查看动作执行的细节,我们需要切换到Hadoop的Map/Reduce管理页面。
查看英文原文:Introduction to Oozie